【机器学习】集成学习 (Ensemble Learning) (二) —— Bagging 与 Random Forest

相关文章
【机器学习】集成学习 (Ensemble Learning) (一) —— 导引
【机器学习】集成学习 (Ensemble Learning) (三) —— Boosting 与 Adaboost + GBDT
【机器学习】集成学习 (Ensemble Learning) (四) —— Stacking 与 Blending
目录
2.1 自助聚合法 / 自举汇聚法 (Bagging)
2.1.1 自助采样法 (Bootstrap Sampling / Bootstrapping)
2.1.2 随机森林 (Random Forest)
2.1 自助聚合法 / 自举汇聚法 (Bagging)
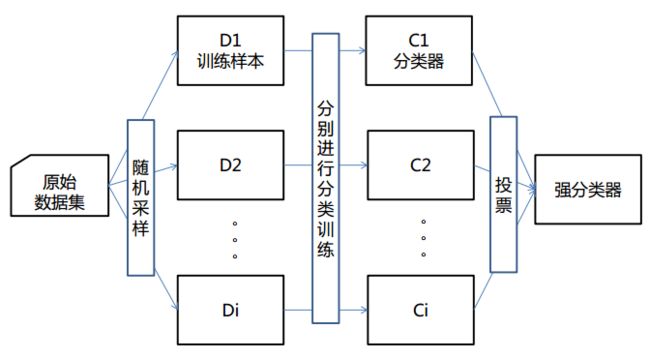
在并行化的方法中,分别拟合不同的学习器,因此可同时训练它们。其中最著名的是 自助聚合法 (Bagging),旨在习得比单一弱学习器更强的集成模型。

Bagging 流派的各算法中,总强调保证各弱学习器训练效果间的随机性/差异性,为什么呢?
例如,把集成学习比作一次考试,A 同学在参考了周边的 B、C、D 同学答案的基础上判断,若 B、C、D 的答案都一样,那么 A 同学在综合 3 人答案后不会对最终结果带来任何提升,仍是 B、C、D 的正确;而只有当 3 人擅长的考点不同、得出的答案也不尽相同时,A 综合后才可能带来提升。
更具体地,设其中一题, B、C、D 答对的概率分别为 Pb、Pc、Pd,若三人答案的正确与否是独立事件,那么 A 本着少数服从多数的原则,得到正确答案的概率为 Pa = PbPc(1-Pd) + (1-Pb)PcPd + Pb(1-Pc)Pd + PbPcPd;反之,若 B、C、D 答案的正确与否是相关联的事件,即同时正确或错误,那么 A 最终的正确率不会改变。
因而,Bagging 流派 要求各弱学习器间的算法尽可能具有随机性,且要求准确率至少不低于50%,否则会对集成效果带来负面影响。

Bagging 流派 倾向于 降低方差 (variance) 而非 降低偏差 (bias)。然而,衡量机器学习模型效果时,往往需同时考虑偏差和方差两方面因素:偏差大 意味着模型训练效果距离理想目标还有很大差距,常常效果很差,模型 欠拟合;方差大意味着模型训练效果时好时坏,虽有时很好,但不够稳定,模型 过拟合。为此,当我们说 Bagging 集成学习相较于单个弱学习器效果有所提升,指的是 偏差不变,方差降低,这可由以下两公式大致表示(但不是具体刻画):
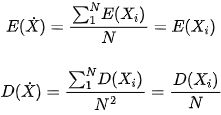
当然,实际中的 Bagging 算法当然是会降低偏差,只是统计意义下的均值与弱学习器效果相当,至于具体如何降低偏差,那就需要具体问题具体调参了!
此外,Bagging 流派由于是并行训练多个同质弱学习器模型,而后组合/聚合各个弱学习器模型的效果综合决策,那么 组合决策方式 其实也是一个值得探讨的问题。简言之,包括majority/hard voting 和 soft voting 两种 投票法 (voting),以二分类问题为例,hard voting 直接统计所有弱学习器的结果,然后取其中结果最多的一类作为最终结果,相当于 “少数服从多数”,但硬投票有个缺点就是 不能预测概率。而软投票返回的结果是一组概率的加权平均数。soft voting 又称 加权平均概率投票,其统计各弱学习器的分类概率,并分别计算所有弱学习器中两类的概率之和,以概率之和较大者作为最终结果。
关于投票法

Bagging 算法

2.1.1 自助采样法 (Bootstrap Sampling / Bootstrapping)

自助采样法是一种从给定训练集中有放回的均匀抽样,是 Bagging 的关键步骤。更具体地,给定包含 n 个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中。这样,经过 n 次随机采样操作,可以得到含 n 个样本的自助采样集,初始训练集中有的样本再采样集里多次出现,有的则从未出现。例如,假设选择了 t 个弱学习器,那么久需要通过自助采样法抽样出 t 个大小为 n 的自助采样集作为各学习器的数据集。
在某些假设条件下,这些样本具有非常好的统计特性:在一级近似中,它们可被视为是直接从真实的底层(并且往往是未知的)数据分布中抽取出来的,并且彼此之间相互独立。因此,它们被认为是真实数据分布的代表性和独立样本(几乎是独立同分布的样本)。
为使这种近似成立,必须验证两个方面的假设:
- 初始数据集大小 n 应足够大,以捕获底层分布的大部分复杂性。从而,从数据集中抽样即为从真实分布中抽样的良好近似(代表性)。
- 与自助样本大小 t 相比,初始数据集规模大小 n 应足够大,从而,样本间就不会有太大的相关性(独立性)。
注意,接下来可能还会提到自助样本的这些特性(代表性和独立性),但这总归只是一种 近似。
例如,自助样本常用于评估统计估计量的方差或置信区间。根据定义,统计估计量是某些观测值的函数。因此,随机变量的方差是根据这些观测值计算得到的。为评估这种估计量的方差,需要对从感兴趣分布中抽取出来的几个独立样本进行估计。在大多数情况下,相较于实际可用的数据量而言,考虑真正独立的样本所需要的数据量可能太大了。然而,可以使用自助法生成一些自助样本,它们可被视为最具代表性以及最具独立性(几乎是独立同分布的样本)的样本。这些自助样本使我们可以通过估计每个样本的值,近似得到估计量的方差。

- Bootstrapping 方法允许模型或算法更好地理解存在于其中的偏差、方差和特征。允许重采样包含不同的偏向,然后将其作为一个整体进行包含。如上图所示,每个样本群有不同的部分,而且各不相同。这会影响到数据集的整体均值、标准差和其他描述性指标。反过来,它可以发展出更多鲁棒的模型。
- Bootstrapping 同样 适用倾向于过拟合的小数据集。利用 Bootstrapping 的算法可增强鲁棒性,并根据已选的方法论(Boosting 或 Bagging)来处理新数据集。
- Bootstrapping 被使用的原因是它 可以测试解决方案的稳定性。使用多个样本数据集测试多个模型可提高鲁棒性。或许一个样本数据集的平均值比其他数据集大,或者标准差不同。这种方式可以识别出过拟合且未使用不同方差数据集进行测试的模型。
- Bootstrapping 越来越普遍的原因之一是 计算能力的提升。出现比之前更多次数的重排列、重采样。Bagging 和 Boosting 都使用 Bootstrapping。
- Bootstrapping 不提供通用的有限样本保证,它的运用基于很多统计学假设,因此假设的成立与否会影响采样的准确性。
自助采样法给 Bagging 带来的好处
由于每个学习器只用了约 63.2% 的原数据集数据,剩下约 36.8% 的样本则可作验证集来对泛化性能进行 “包外估计”。对于这部分没采集到的数据,常称为 包/袋外数据(Out Of Bag,OOB)。这些数据没有参与训练集模型的拟合,因此可用来检测模型的泛化能力。

2.1.2 随机森林 (Random Forest)
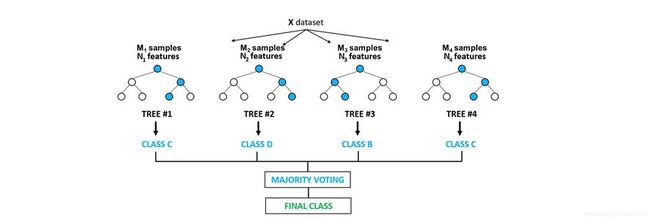
众所周知,决策树算法对数据较敏感,方差比较大,而 Bagging 算法倾向于先增大方差(随机性),最后用投票法或平均值法来减少最后模型的方差,从而实现方差降低的倾向性。而 把 决策树 和 Bagging 结合,就得到了 随机森林 (RF)。
随机森林 作为典型的 Bagging 流派集成学习算法,以多棵决策树作为弱学习器(森林),且采用随机采样方式确保各弱学习器结果的多样性(随机)。
事实上,Bagging 流派集成学习算法可分为 4 类,主要差别源于 采样方式 的不同:
- 仅对 样本维度(行方向)进行 有放回采样,意味着每个弱学习器的 n 个采样样本中可能存在重复,此时对应 Bagging 算法,其中 Bagging = Bootstrap Aggregating。该算法名称与 Bagging 流派的名字重合,因为这是 Bagging 中一种经典的采样方式,因而以其作为流派的名字。当然,Bagging 既是一种算法也是流派名,那就要依狭义还是广义来区分了
- 仅对 样本维度(行方向)进行 无放回采样,意味着每个弱学习器的 n 个采样样本是完全不重复的。由于相当于每执行一次采样,该样本就被舍弃 (pass),所以此时叫 Pasting 算法。
- 前二者的随机性均源自对样本维度(行方向)的随机采样。若在 特征维度(列方向)上随机采样,即每个弱学习器选用所有样本但不同特征进行训练,则算法自然也具随机性,可满足集成要求,此时叫 Subspaces 算法(特征维度的子空间)。
- 兼对 样本维度(行方向)和 特征维度(列方向)采样,则所得到的弱学习器应具有更强的算法随机性,称为 Patches 算法,随机森林 就属于这类。实际上,随机森林才是最为广泛使用的 Bagging 流派集成学习算法
延伸
其实 Bagging 算法无非就是区分到底是行采样、列采样还是行列采样,那为什么会出来 4 种呢?原来是行采样在采样执行过程中又细分了是否有放回。那既然行采样可以区分是否有放回,列采样是否也可区分一下衍生出两种具体算法呢?实际上 不可以,因为特征的有放回意味着特征重复,而重复的特征或者说复制特征参与机器学习训练 不能带来学习效果的改变;但 样本的重复则可以,因为其 能够直接带来算法训练样本的类别平衡性,从而影响训练结果。
设每个样本的特征维度为 M,指定一个常数 m< 总之,样本选取随机性 和 特征选取随机性 的引入对分类性能至关重要,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。 随机森林分类效果(错误率)至少与两个因素有关: 减小特征选择个数 m,树的相关性和分类能力也会相应的降低;增大减小特征选择数 m,树的相关性和分类能力也会随之增大。故关键问题是如何选择最优的特征选择个数 m(或者说是范围),这也是随机森林的一个重要参数,要解决这个问题主要依据计算 袋外错误率 OOB error(Out-Of-Bag Error)。 OOB 估计 此外,随机森林的一个重要的优点是,无需显式交叉验证或分出一个独立的测试集计算误差的一个无偏估计,即在生成过程中就可对误差建立一个无偏估计 —— 通过 OOB 进行自我验证以调整超参数。在构建每棵树时,对训练集使用了不同的 Bootstrap Sample(随机且有放回地抽取),故对每棵树而言(假设对第 k 棵树),约有 36.8% 的训练实例未参与第 k 棵树的生成,此时它们即作为 (第 k 棵树)的 OOB 样本。这样的采样特点允许我们进行 OOB 估计,其计算方式如下 (以样本为单位): Put each case left out in the construction of the kth tree down the kth tree to get a classification. In this way, a test set classification is obtained for each case in about one-third of the trees. At the end of the run, take j to be the class that got most of the votes every time case n was oob. The proportion of times that j is not equal to the true class of n averaged over all cases is the oob error estimate. This has proven to be unbiased in many tests. 其实,OOB 误分率 是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的 k 折交叉验证。与之前的验证方法相比,有了 OOB 数据和 OOB 估计后,既不用将数据集分为两份(验证集和训练集),也不用在确定好超参数以后重新训练模型了。 CART 随机森林使用 CART 作为其弱分类器。CART 又称 分类回归树,当数据集的因变量为连续性数值时,该树算法就是一个回归树,可以用叶节点观察的均值作为预测值;当数据集的因变量为离散型数值时,该树算法就是一个分类树,可以很好的解决分类问题。但需要注意的是,该算法是一个二叉树,即每一个非叶节点只能引伸出两个分支,所以当某个非叶节点是多水平(2个以上)的离散变量时,该变量就有可能被多次使用。同时,若某个非叶节点是连续变量时,决策树也将把他当做离散变量来处理(即在有限的可能值中做划分) 特征选择 特征选择目前比较流行的方法是信息增益、增益率、基尼系数和卡方检验,其中随机森林采用的 CART 决策树是基于基尼系数(GINI)选择特征的。 优点 缺点 应用 参考文献 通俗讲解集成学习算法! 三种集成学习算法原理及核心公式推导 自助(抽样)法 自助采样包含训练集里63.2%的样本? 集成学习(一)模型融合与 Bagging 随机森林算法及其实现(Random Forest) 随机森林原理介绍与适用情况(综述篇)