【学习周报】强化学习在视频字幕中的应用调查
学习内容:
- Video Captioning via Hierarchical Reinforcement Learning(CVPR2018)
- Reconstruct and Represent Video Contents for Captioning via Reinforcement Learning(IEEE2020)
- Adversarial Reinforcement Learning With Object-Scene Relational Graph for Video Captioning(IEEE2022)
学习时间:
- 12.5 ~ 12.10
学习笔记:
(一) Video Captioning via Hierarchical Reinforcement Learning(CVPR2018)

摘要
已有工作(如sequence-to-sequence model)在描述具有多个细粒度动作的视频时表现一般,为了解决这个问题,本文提出了一种分层强化学习视频字幕框架(hierarchical reinforcement learning framework)。
介绍
该框架在high-level设计了Manager Module来学习sub-goals;在low-level设计了Worker Module来识别视频中的动作,以此完成来自Manager分配的sub-goal,除此之外还设计了Internal Critic来判断Worker的任务是否完成。
在具体过程中,该模型通过利用environment以及已完成的sub-goals,驱使Manager发放新的sub-goal给Worker,然后Worker以该目标为指导,逐个地生成单词来形成内容片段,同时Internal critic来对Worker的工作进度进行评估。HRL框架概述如图1-1所示。
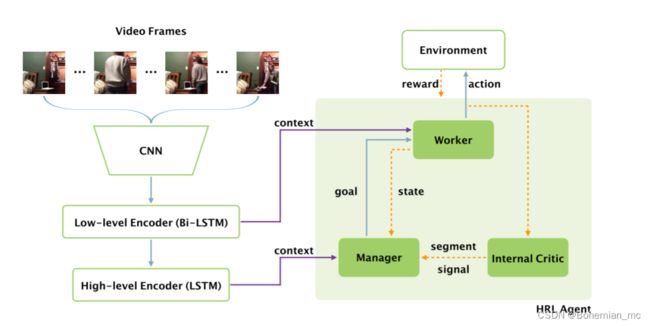
具体流程
在编码阶段,首先使用预训练的CNN模型提取视频帧特征 v = v i v={v_i} v=vi,然后帧特征通过一个low-level Bi-LSTM encoder 获取low-level encoder output h E w = [ h i E w ] h^{E_w}=[h_i^{E_w}] hEw=[hiEw],以及一个high-level LSTM encoder 获取high-level encoder output h E m = [ h i E m ] h^{E_m}=[h_i^{E_m}] hEm=[hiEm], 在解码阶段,HRL agent扮演decoder的角色输出语言描述。
HRL agent由三部分组成:low-level worker,high-level manager,internal critic。
Manager在较低的时间分辨率给worker发出目标,然后worker通过遵循该目标在每个时间步骤生成单词。
换句话说,manager要求工作者生成一个语义片段(semantic segment),worker在接下来的几个时间步中生成相应的单词,以完成这项工作。internal critic确定worker的工作是否已经完成,并向manager发送二进制信号,以帮助manager为worker更新目标。
当遇到结束令牌“EOS”时,整个流程终止。
奖励函数
相关研究工作表明以CIDEr作为奖励因子表现最好(与BLEU、METEOR等评价指标相比),并且能够改善模型在其他评价方法中的表现,因此本文也使用CIDEr分数计算奖励。
然而本文并不是直接地使用整个字幕的最终CIDEr分数作为奖励,而是将CIDEr分数作为一种即时奖励,定义 f ( x ) = C I D E r ( s e n t + x ) − C I D E r ( s e n t ) f(x)=CIDEr(sent+x)-CIDEr(sent) f(x)=CIDEr(sent+x)−CIDEr(sent),其中 s e n t sent sent是之前生成的字幕。
因此,Worker的discounted return为:

Manager的discounted return为:
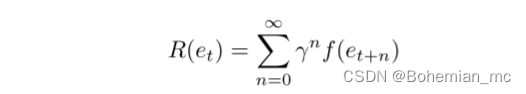
需要注意的是,该方法并不局限于CIDEr分数,因此其他的评估方法(BLEU等)也可以作为奖励因子应用于HRL框架。
MSRVTT数据集上的实验结果

算法流程

(二) Reconstruct and Represent Video Contents for Captioning via Reinforcement Learning(IEEE2020)
![]()
摘要
不同于以往的视频字幕工作,它们主要利用视频内容的线索来进行语言描述,本文提出了一种新的encoder-decoder-reconstructor架构(重构网络RecNet),利用视频字幕的前向(video to sentence)流和后向(sentence to video)流。
具体来说,编码器-解码器组件利用正向流基于编码器的语义特征产生句子描述。随后提出了两种类型的重构器(reconstructor),利用解码器生成的隐藏状态序列,分别从局部(local)和全局(global)角度利用反向流再现视频特征。
此外,为了对视频特征进行全面的重构,提出将两类重构器融合在一起。由编码器-解码器组件的生成损失(generation loss)和由重构器引入的重构损失(reconstruction loss)被联合地投射到以端到端方式训练的RecNet中。此外,通过强化学习基于CIDEr优化对RecNet进行微调,显著提高了字幕显示性能。
介绍
图 2-1 表示了所提出的RecNet网络架构。其中encoder-decoder依据forward流,在decoder中生成与encoder输入的视频帧特征对应的字幕;reconstructor则利用backward流,以decoder的隐藏状态序列作为输入再现输入视频的视觉特征(visual features)。

图 2-2 表示了重构器(reconstructor)再现视频序列结构的过程。在此过程中,重构器通过选择性地调整注意力权重来处理decoder的隐藏状态,并逐帧再现视频特征(局部表示)。最后通过均值池对特征表示序列进行合并,从而产生视频的全局表示。
强化学习策略
为了直接优化评估指标而不是交叉熵损失,我们将视频内容和词语视为“environment”,将编解码器模型视为与环境交互的“agent”,在每个时间步 t t t,策略 π θ π_θ πθ 采取“action”预测一个单词,然后更新“state”,state为LSTM的隐藏状态和单元状态。当生成句子时,计算评估分数并将其视为“reward”(此处CIDEr分数被视为reward)。通过最小化负期望回报来优化该策略:
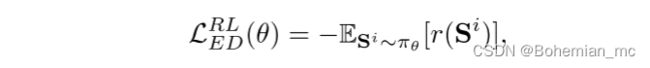
中间过程在此先不研究,直接给出最终的奖励梯度函数:

如果一个样本有一个奖励r (S)高于基线b,此时梯度值为负,那么会通过增加相应的词的概率鼓励来这种分布。同理,低回报的样本分布是模型所抵触的。
在数据集上的表现
1.MSRVTT
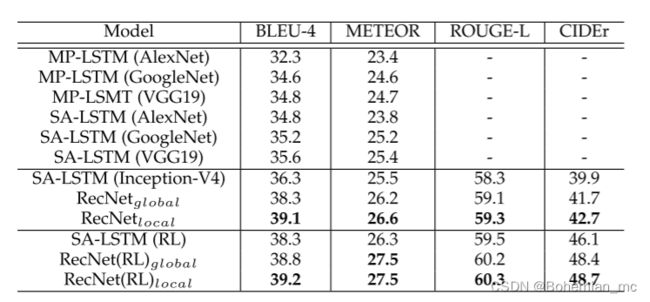
2.MSVD
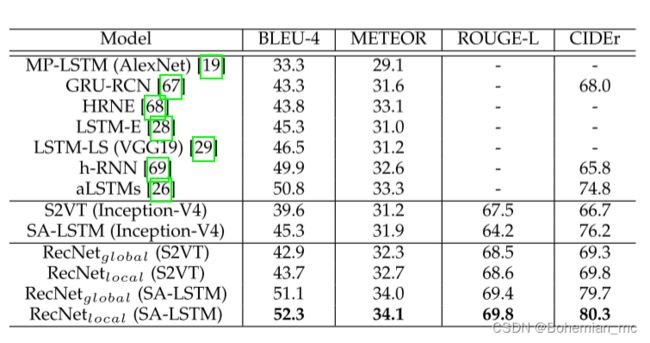
3.ActivityNet
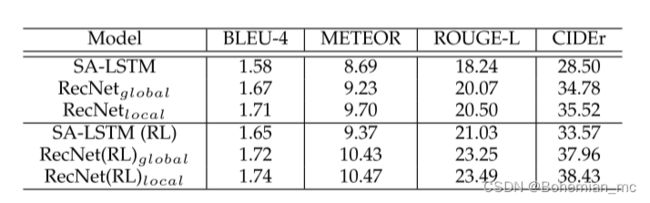
总结
本文提出了一种新的视频字幕编解码重构体系结构RecNet,它利用了自然语言描述和视频内容之间的双向线索。具体来说,为了解决从描述到视频的后向信息,设计了两种类型的重建器来分别再现输入视频的全局和局部结构。本文还提出了一种融合两类重构器的结构,并与分别再现全局和局部结构的模型进行了比较。前向似然损失和后向重构损失联合建模以训练所提出的网络。此外,采用REINFORCE算法直接优化CIDEr评分,并将基于奖励的损失与传统的重建损失融合,进一步提高字幕效果。在基准数据集上的大量实验结果表明,与现有的视频字幕编解码器模型相比,所提出的RecNet在视频字幕的典型度量方面具有优势。
(三) Adversarial Reinforcement Learning With Object-Scene Relational Graph for Video Captioning(IEEE2022)
摘要
现有的视频字幕方法通常忽略了视频中重要的细粒度语义属性、视频的多样性以及帧与帧、对象与对象之间的关联和运动状态。因此,它们不能适应小样本数据集。针对上述问题,提出了一种新的视频字幕模型和一种对抗式强化学习策略。
首先,设计了一个object-scene关系图模型,该模型基于object detector(对象检测器)和scene
segmenter(场景分割器)来表示关联特征(association features)。
其次,设计了trajectory-based特征表示模型,该模型取代以往数据驱动的方法来提取动作和属性信息,以分析对象在时域中的运动并在小规模数据集上建立视觉内容和语言之间的连接。
最后,设计了adversarial reinforcement learning strategy(对抗强化学习策略)以及multi- branch discriminator(多分支鉴别器)来学习视觉内容与相应单词之间的关系,以此来讲丰富的语言知识融入到模型当中。
介绍
图 3-1 为所提出的模型框架图。该模型由三部分组成,分别是:
- 特征增强器和编码器
- 描述生成器
- 多分支鉴别器

具体流程
对于给定的视频帧序列,提取L个帧作为关键帧,使用预训练的 Mask Track-RCNN 探测和跟踪关键帧中的对象,然后使用训练好的2DCNNs提取属性特征(attribute feature) F = f i F=f_i F=fi,再借助运动信息表示模型(motion information expression module,MIR),提取动作特征(motion feature) M = m i M={m_i} M=mi。
设计了一种新的object-scene relational graph(对象-场景关系图)来充分表达对象之间以及对象与环境之间的时空关系。为了解决序列对齐问题,在图卷积中加入控制门和自环结构,通过控制特征信息在递归图卷积网络中的传递,不断增强视频序列和文本序列之间的相关性。
在获得了足够的视频特征之后,使用一种带有时空注意力模型的特征增强分级解码器(feature-enhanced hierarchical decoder)逐步地生成语言描述。
基于对抗式强化学习的训练策略
在数据集上的表现
1.MSR-VTT
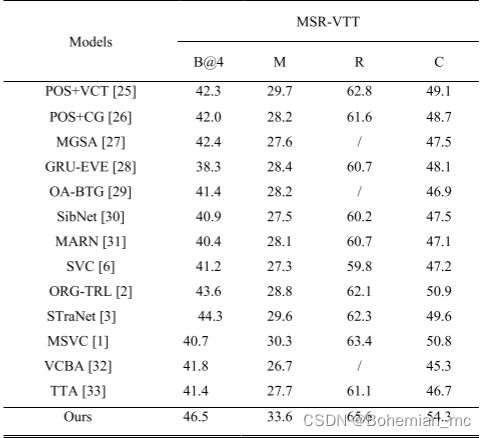
2.MSVD

结论
- 本文设计的object-scene graph(对象-场景图)模型,由于加入了先验的语义信息,进而使得编码后的特征包含了更多的语义信息。
- 用对象特征表示模型代替了旧的以数据为驱动的方法。
- 训练策略采用强化学习和对抗学习策略相结合,设计了一种多分支鉴别器有效地提高了模型的学习能力。
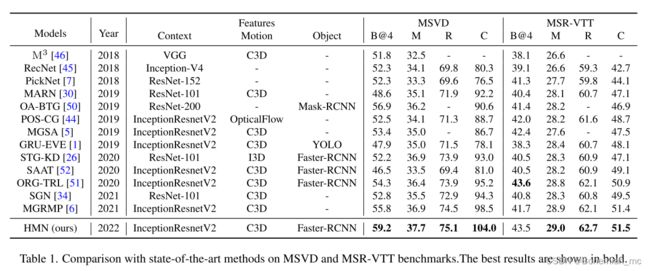
HMN模型在MSVD和MSR-VTT数据集上的表现(与上面几种模型对比)