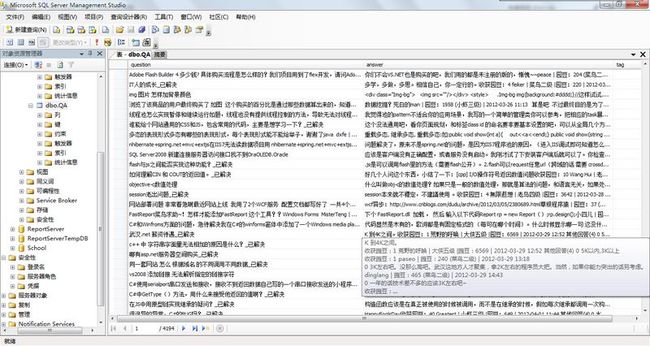
Pipeline集成运行测试情况
Pipeline集成运行测试报告
开发团队:TeamSHIT
1 测试数据集
为了检验Pipeline Alpha版的开发效果,测试其集成运行情况,我们团队和两个负责开发Crawler的小组协商,制定了一份测试数据集,涵盖问答类网页、文献检索类网页、科普类网页、中英文网页,基本满足Pipeline的测试需求。
该数据集具体包括1个百度知道问答网页、3个计算机领域的文献检索网页、4个百度百科科普网页、4个博客园博问问答网页以及5个伯克利大学相关网页。
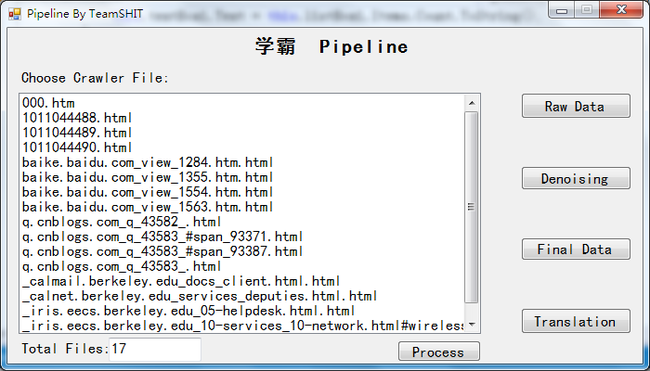
Figure 1 Pipeline的主界面以及测试数据集
2 测试情况
本次测试共发现bug4个,其中解决两个,另两个问题Alpha没有在根本上解决,留到Beta版本解决。
3 功能测试
3.1 爬虫文件夹设置问题
测试集:数据存放的文件夹
负责去噪的连昭鹏同学在设计时把爬虫爬取的文件夹存放在F盘根目录下,Pipeline引用这个绝对路径实现对文件的操作(bug1),但是我觉得这不利于项目集成,而且过多地对用户提要求也不是一种可取的软件开发态度。因此我把这个文件夹放在Pipeline项目工程文件夹里,用相对路径实现对内部文件的操作。
3.2 网页编码问题
测试集:各类网页各1份。测试效果如下:
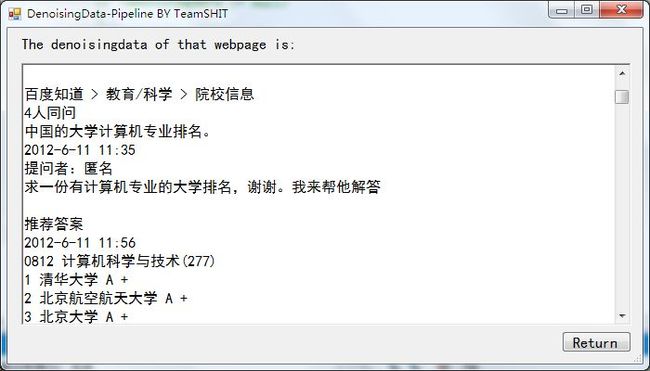
Figure 2 百度知道网页的去噪结果
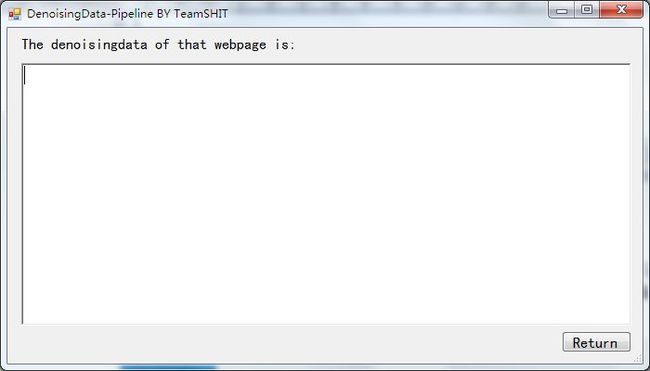
Figure 3 文献检索网页的去噪结果
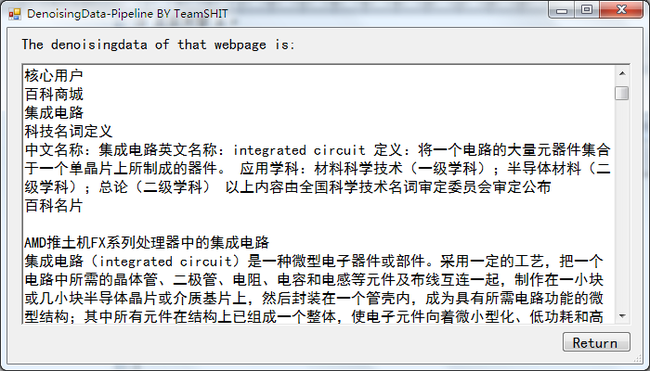
Figure 4 百度百科网页的去噪结果
Figure 5 博客园博问的去噪结果

Figure 6 Berkeley相关网页的去噪结果
可以看到部分网页的去噪效果良好,部分网页的去噪结果直接为空。于是我查看了一下博客园网页的Raw Data,发现它的中文部分出现的都是乱码,出现同样问题的文献检索网页的Raw Data也是同样问题。
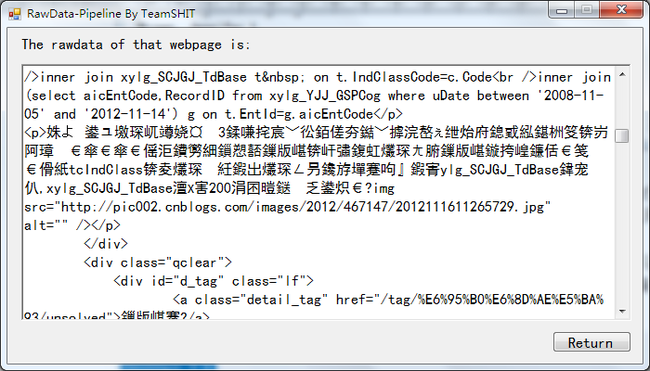
Figure 7 博客园博问网页的Raw Data
出现乱码问题是因为在一开始设计时,我们对网页的处理方法是按C#默认的编码方式读写源文件,而网页的普遍编码方式不唯一,因此指定一种编码只能正确处理一部分网页,另一部分的结果变成乱码(bug2)。
解决方法:我们一开始想实现一个编码转换,但是有组员发现如果编码不匹配则Denoising的值一定为空这个特点,我们可以依次按不同的编码分析源文件,如果得到的结果为空则换一种编码分析。目前分析的编码有ANSI、UTF-8,这两种编码已经能正确处理数据集里的五种网页类型,现在的绝大部分网页用上述两种编码也都能解析。
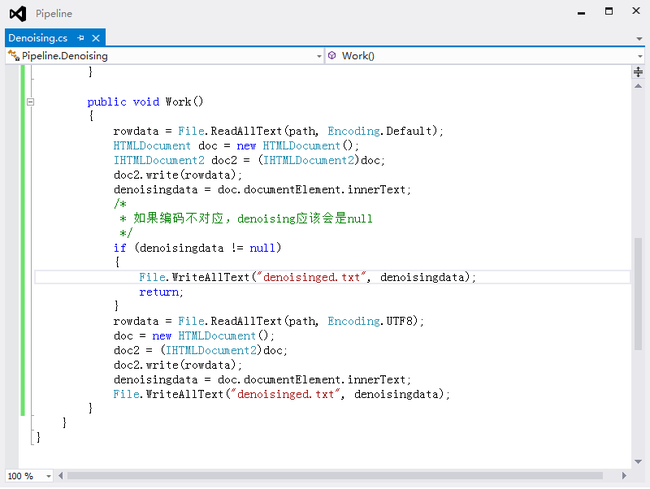 Figure 8 考虑两种编码方式
Figure 8 考虑两种编码方式
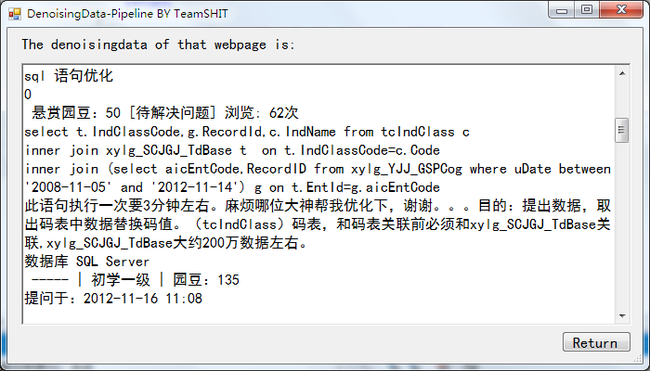
Figure 9 正确的博客园博问去噪结果
3.3 信息抽取问题
李斌是借助正则表达式匹配实现信息抽取。这种方法对于文本组织形式比较单一的网页效果不错,因为我们可以抽象出一种比较固定的格式完成匹配。然而事实上我们处理的网页类型比较丰富,使用正则表达式必须分析每一种网页才能完成信息抽取,这对于以后系统的扩充性是极为不利的(bug3)。
在Alpha版本中,由于正则表达式实现简单且在处理某一类网页时的效果不错,我们还是选择了用它做信息抽取工作,选定的网页源为博客园的博问。

Figure 10 博问的文本组织形式
可以看到,在一个博问中,问题部分的内容在“[待解决问题]”和“提问于XXXX”之间,而回答部分的内容紧接着“所有回答”。
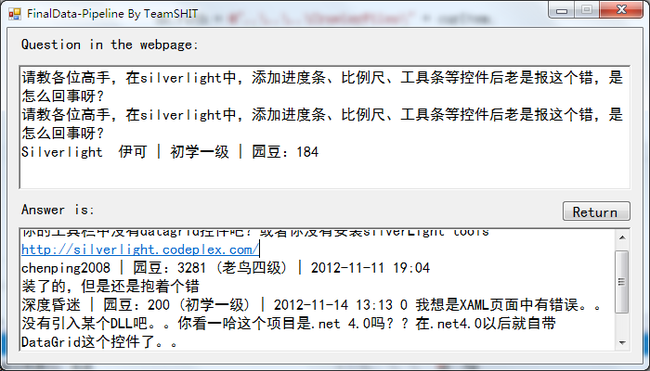
Figure 11 提取的QA对
针对扩充性这个问题,我们并没有提出一种更好的信息抽取方法解决这个bug,这个问题争取在下一个版本中解决它。
3.4 Final Data存储问题
与数据库的连接部分由隋宇豪负责。数据库使用SQL Server 2008,数据存储功能已实现。

Figure 12 Essay表
所存在的较大问题是每次存入一行数据都要开关一次数据库,对于长时间连续存入的情况,效率显得低下(bug4)。
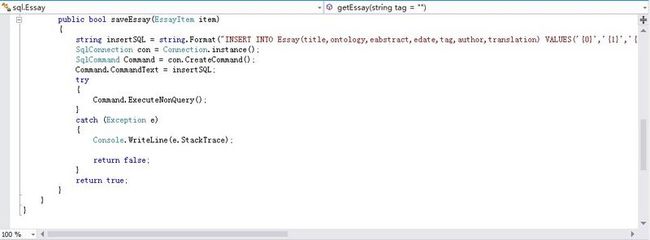
Figure 13 每次存入一行数据都要调用Connection
第二,数据格式经过几次修改,但还是存在不完善的地方。比如Essay表中只有摘要列,虽然因为版权等一些问题不太合适将整个论文保存下来,但是可以考虑在表中加入链接列,用来给出论文的一个URL。
第三,算法没有判断数据库内是否存在相同数据。
我们会再详细讨论出现的各种问题,并罗列出来,并争取将其在BETA版中一一改进。
4 信息数据库
任务:10K webpages In DB。
截至到截图时共4194个QA对。