深度学习caffe框架(2): layer定义
caffe的代码层次
首先让我们回顾一下caffe的代码层次: blob,layer, net和solver.
其中blob是数据结构, layer是网络的层, net是将layer搭建成的网络,solver是网络BP时候的求解算法. 本节主要介绍caffe的layer基本结构, 种类, 以及不同类型的layer如何定义.
layer的基本结构和种类
Caffe的layer的基本结构:
Layer{
name: "xx" # 名称
type: "xx" # 类型
top: "xx" # 输出
bottom: "xx" # 输入
some_param { # 其他参数定义等
...
}
}
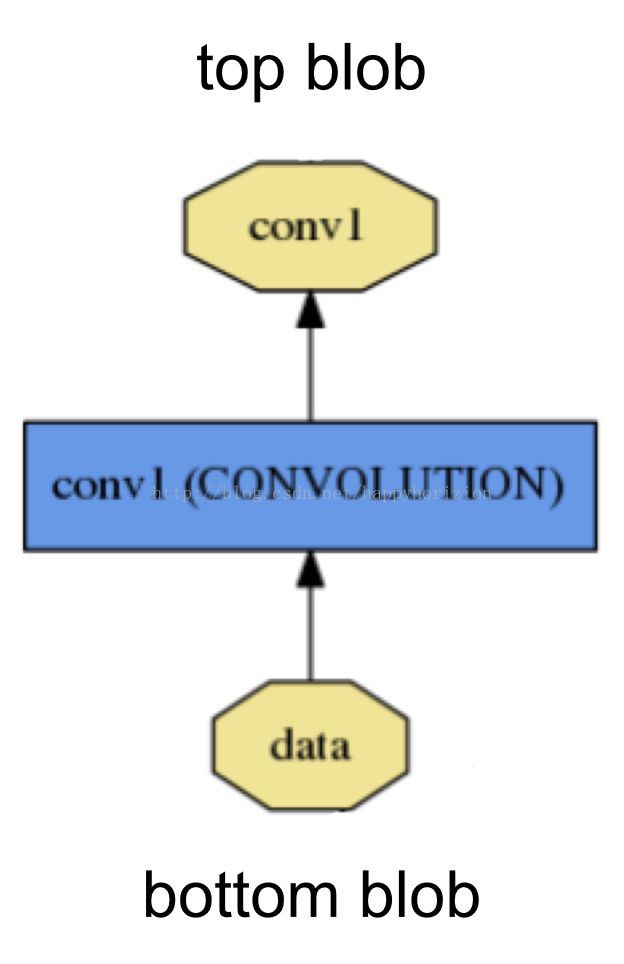
从一个典型的卷积神经网络模型结构出发, 首先需要数据输入层,然后是图像的预处理,例如图像切割slice, 卷积层Convolution, 在caffe中,激活函数等数据运算也用layer的方式定义. 总的来说,caffe的layer种类如下:
- 数据输入层:
- 视觉层(Vision Layers): 包括Convolution, Pooling, Local Response Normalization (LRN), im2col等
- 损失层: softmax-loss层, Euclidean层.
- 循环层: RNN, LSTM层等.
- 工具层(Utility layer): 例如reshape层, concat层等
- 普通层(Common layer): dropout层, 全连接层, embed层.
数据输入层:
一个常见的数据输入层定义如下. 输入数据定义为lmdb数据库格式.
layer {
name: "data"
type: "CPMData"
top: "data"
top: "label"
data_param {
source: "/home/zhecao/COCO_kpt/lmdb_trainVal" # lmdb数据文件路径
batch_size: 10
backend: LMDB
}
cpm_transform_param { # 图片预处理
stride: 8
max_rotate_degree: 40 # 旋转
visualize: false
crop_size_x: 368
crop_size_y: 368
scale_prob: 1
scale_min: 0.5 # 缩放比例
scale_max: 1.1 # 缩放比例
target_dist: 0.6
center_perterb_max: 40
do_clahe: false
num_parts: 56
np_in_lmdb: 17
}
}
详细的数据数据层定义见:http://www.cnblogs.com/denny402/p/5070928.html
视觉层
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层
卷积层
卷积层是卷积神经网络的核心层. 卷积层的定义:
layer {
name: "conv1_1"
type: "Convolution"
bottom: "image" # 输入
top: "conv1_1" # 输出
param {
lr_mult: 1.0 #权值学习率的系数,
decay_mult: 1 # 学习率的衰减系数
}
param {
lr_mult: 2.0 # 偏置的系数
decay_mult: 0 # 偏置的衰减系数
}
convolution_param {
num_output: 64 #卷积核(filter)的个数
pad: 1 # 步长
kernel_size: 3 # 卷积核大小
weight_filler { # 卷积核权值的初始化, 默认是常值0, 或者gaussian/ xavier
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
pad: 进行边缘扩充。默认为0, 也就是不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,保证在卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
输入:n*c0*w0*h0
输出:n*c1*w1*h1
其中,c1就是参数中的num_output,生成的特征图个数
w1=(w0+2*pad-kernel_size)/stride+1;
h1=(h0+2*pad-kernel_size)/stride+1;
如果设置stride为1,前后两次卷积部分存在重叠。如果设置pad=(kernel_size-1)/2,则运算后,宽度和高度不变.
池化层
池化层有效减少了网络参数, 同时尽可能保持了位置信息.
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX # 池化类型
kernel_size: 3 # 池化核的大小
stride: 2 # 步长
}
}
这里pad还是默认为0,不进行扩充.
输入:n*c*w0*h0
输出:n*c*w1*h1
和卷积层的区别就是其中的c保持不变
w1=(w0+2*pad-kernel_size)/stride+1;
h1=(h0+2*pad-kernel_size)/stride+1;
如果设置stride为2,前后两次卷积部分不重叠。100*100的特征图池化后,变成50*50.
3.局部响应归一化层(Local Response Normalization, LRN)
对于每一个输入, 去除以
得到归一化后的输出
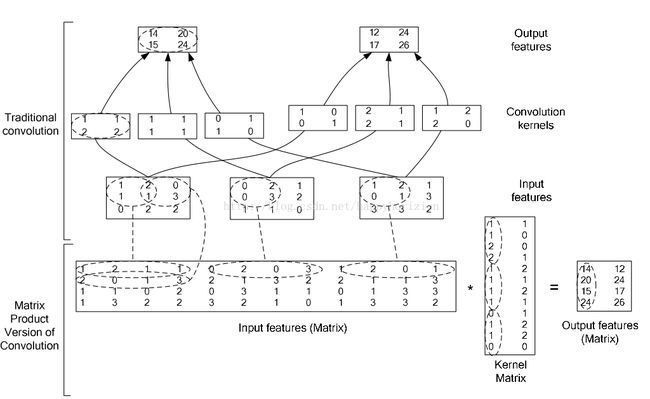
4.Im2col层.
将输入的image的各个区域(小矩阵)拉成向量,然后依次排列形成新的大矩阵.
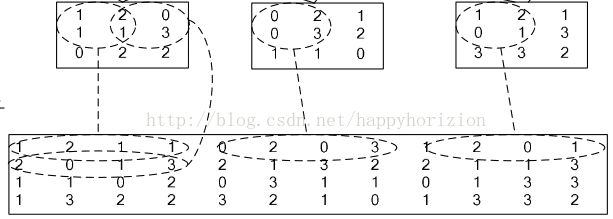
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
LRN和im2col层的详细情况见:http://www.cnblogs.com/denny402/p/5071126.html
激活层
在激活层,是对输入做元素级的激活操作(函数变换), 输入和输出的维度是一致的.常用的激活函数有sigmoid, relu和tanh等.
典型的激活层定义:
layer {
name: "XX"
bottom: "in_data"
top: "out_data"
type: "Sigmoid" # 也可以是"ReLU"或者"TanH"
}
以ReLU层为例, 非线性变化层 max(0,x),一般与CONVOLUTION层成对出现
:
layer {
name: "relu1"
type: "ReLU" # 激活函数类型
bottom: "ip1"
top: "ip1"
}
其他层
全连接层(inner product)
- weight_filler: 权值初始化。 默认为“constant",值全为0,很多时候我们用"xavier"算法来进行初始化,也可以设置为”gaussian"
- bias_filler: 偏置项的初始化。一般设置为"constant",值全为0。
- bias_term: 是否开启偏置项,默认为true, 开启
全连接层的定义为:
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500 # 输出参数个数
weight_filler { # 权重的初始化
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
Dropout层
防止过拟合.只需要定义dropout比率就可以了.
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7-conv"
top: "fc7-conv"
dropout_param {
dropout_ratio: 0.5
}
}
Softmax-loss层:
如果我们最终目的就是得到各个类别的概率似然值,这个时候就只需要一个 Softmax层,而不一定要进行softmax-Loss 操作;如果输出结果理论上的概率分布已知,然后要做最大似然估计,此时最后需要一个softmax-Loss层.
从Softmax-loss的计算公式可以看出, softmax-loss实际上定义的是交叉熵:
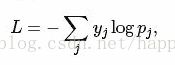
softmax-loss层的定义:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
}
Softmax和softmax-loss的比较:http://freemind.pluskid.org/machine-learning/softmax-vs-softmax-loss-numerical-stability/
还有如reshape层等,参考:
caffe官网: http://caffe.berkeleyvision.org/tutorial/layers.html