a100高性能服务器,滴滴云 A100 GPU 裸金属服务器(BMS)最佳实践
2020 年 5 月 14日,NVIDIA 创始人兼首席执行官黄仁勋在 NVIDIA GTC 2020 主题演讲中介绍了基于最新 Ampere 架构的 NVIDIA A100 GPU。NVIDIA A100 Tensor Core GPU 基于最新的 Ampere 架构,相比上一代 NVIDIA Tesla V100 GPU 增加了了许多新特性,在 HPC,AI 和数据分析领域都有更好的表现。
北京时间 9 月 1 日,滴滴云发布基于 NVIDIA Tesla A100 GPU 的云服务器产品,据悉滴滴云是该型GPU云服务器产品的国内首发云厂商。
滴滴云基于 A100 GPU 的产品包括裸金属服务器(BMS)、透传性 GPU 云服务器和 vGPU 云服务器产品,可用于深度学习训练/推理、视频处理、科学计算、图形图像处理等场景。目前基于 A100 GPU 的裸金属服务器产品开放测试,欢迎企业用户垂询。
A100 搭载了革命性的多实例 GPU(Multi-instance GPU 或 MIG)虚拟化与 GPU 切割能力,对云服务供应商(CSPs)更加友好。当配置为 MIG 运行状态时,A100 可以通过分出最多 7 个核心来帮助供应商提高 GPU 服务器的利用率,无需额外投入。A100 稳定的故障分离也能够让供应商安全的分割GPU。
A100 带有性能强劲的第三代 Tensor Core,支持更为丰富的 DL 和 HPC 数据类型,同时具有比 V100 更高的计算吞吐。 A100 新的稀疏(Sparsity)特性能够进一步让计算吞吐翻倍。新的 TensorFloat-32 (TF32) 核心运算单元让 A100 在 DL 框架和 HPC 中轻松加速以 FP32 作为输入/输出数据的运算,比 V100 FP32 FMA 操作快10倍,稀疏优化(sparse)下可以达到 20 倍。在 FP16/FP32 的混合精度下也能达到 V100 的 2.5 倍,稀疏优化后达 5 倍。新的 Bfloat16(BF16)/FP32 混合精度 Tensor Core 运算单元和 FP16/FP32 混合精度以相同的频率运行。Tensor Core 对 INT8,INT4 和 INT1 的加速为 DL 推理提供了全面支持,A100 sparse INT8 比 V100 INT8 快 20 倍。在 HPC 中,A100 Tensor 核心的 IEEE 兼容 FP64 处理让它的表现是 V100的 2.5 倍。
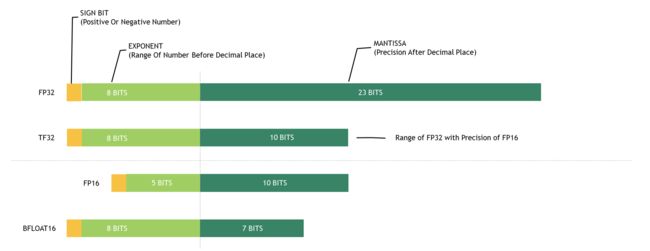
下图为 A100 GPU 支持的各种浮点数据类型位宽表示。
A100 硬件参数与前代 GPU 对比GPU 型号GV100TU102TU102GA100
GPU 工艺TSMC 12nmTSMC 12nmTSMC 12nmTSMC 7nm
CUDA 架构Volta(SM_70)Turing (SM_75)Turing (SM_75)Ampere(SM_80)
SM 数目806872108
SP 数目51204352 (=68 * 64)4608 (=72 * 64)6912 (=108 * 64)
GPU 时钟频率1.53 GHz1.545 GHz*1.77 GHz1.41 GHz
ROPs1288896160
TMUs320272288432
Tensor Cores640544576432
RT CoresN/A6872N/A
显存容量32 GB HBM211 GB GDDR624 GB GDDR640 GB HBM2E
显存位宽4096 bits352 bits384 bits5120 bits
显存频率0.876 GHz(x2)1.75 GHz(x8)1.75 GHz(x8)1.215 GHz(x2)
显存带宽897 GB/s616 GB/s**672 GB/s1555 GB/s
功耗250 W250 W260 W400 W
A100 与前代 GPU CUDA Core/Tensor Core 计算能力对比(单位:每时钟周期每 SM 乘累加次数):
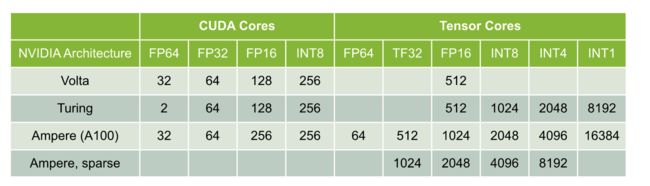
根据上述表格中的数字可以计算出 A100 峰值计算能力:
计算类型峰值吞吐(TFLOPS/TOPS)FP64, CUDA Core9.746(= 108 x 32 x 1410MHz x 2)
FP64, Tensor Core19.49(= 108 x 64 x 1410MHz x 2)
FP32, CUDA Core19.49(= 108 x 64 x 1410MHz x 2)
TF32, Tensor Core155.9(= 108 x 512 x 1410MHz x 2)
TF32, Tensor Core, Sparse311.87(= 108 x 1024 x 1410MHz x 2)
FP16, CUDA Core77.96(= 108 x 256 x 1410MHz x 2)
FP16, Tensor Core311.87(= 108 x 1024 x 1410MHz x 2)
FP16, Tensor Core, Sparse623.74(= 108 x 2048 x 1410MHz x 2)
INT8, CUDA Core77.96(= 108 x 256 x 1410MHz x 2)
INT8, Tensor Core623.74(= 108 x 2048 x 1410MHz x 2)
INT8, Tensor Core, Sparse1247.5(= 108 x 4096 x 1410MHz x 2)
INT4, Tensor Core1247.5(= 108 x 4096 x 1410MHz x 2)
INT4, Tensor Core, Sparse2495(= 108 x 8192 x 1410MHz x 2)
INT1, Tensor Core4990(= 108 x 16384 x 1410MHz x 2)
2、软件环境
为了发挥出 A100 的计算能力,用户需要升级软件环境。下表为推荐版本:软件名推荐版本说明GPU 驱动450.xx滴滴云内网链接:https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/DRV/NVIDIA-Linux-x86_64-450.57.run
CUDA Toolkit11.0+滴滴云内网链接:https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/CUDA/cuda_11.0.1_450.36.06_linux.run
cuDNN8.0+滴滴云内网链接:https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/CUDNN/cudnn-11.0-linux-x64-v8.0.0.180.tgz
Tensor RT7.1+滴滴云内网链接:https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/TENSORRT/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-11.0.cudnn8.0.tar.gz
NGC20.06+滴滴云内网链接:
docker pull hub.didiyun.com/ngc/tensorflow:20.06-tf1-py3
docker pull hub.didiyun.com/ngc/tensorflow:20.06-tf2-py3
docker pull hub.didiyun.com/ngc/mxnet:20.06-py3
docker pull hub.didiyun.com/ngc/pytorch:20.06-py3
下面为 NVIDIA GPU 驱动、CUDA Toolkit、cuDNN的安装方法。
2.1 手动安装 GPU 驱动apt install -y gcc g++ build-essential linux-headers-$(uname -r)
wget https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/DRV/NVIDIA-Linux-x86_64-450.57.run
chmod 755 NVIDIA-Linux-x86_64-450.57.run
./NVIDIA-Linux-x86_64-450.57.run
nvidia-persistenced
2.2 手动安装 CUDA Toolkit
wget https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/CUDA/cuda_11.0.1_450.36.06_linux.run
chmod 755 cuda_11.0.1_450.36.06_linux.run
./cuda_11.0.1_450.36.06_linux.run
注意上一步已经安装了 GPU 驱动,这一步安装时可跳过驱动安装。
2.3 手动安装 cuDNN
wget https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/CUDNN/cudnn-11.0-linux-x64-v8.0.0.180.tgz
tar zxvf cudnn-11.0-linux-x64-v8.0.0.180.tgz -C /usr/local/
2.4 手动安装 TensorRTwget https://zyk.s3-internal.didiyunapi.com/public_software/NVIDIA/TENSORRT/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-11.0.cudnn8.0.tar.gz
tar zxvf TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-11.0.cudnn8.0.tar.gz
说明:如果用户选择 NGC 镜像,则无需手动安装 CUDA Toolkit、cuDNN、TensorRT,这些已包含于 NGC 镜像中。
2.5 NGC 环境初始化
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
apt update
apt install -y docker-ce docker-ce-cli containerd.io
docker version
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt update
apt install -y nvidia-docker2
systemctl daemon-reload
systemctl restart docker
nvidia-docker
docker login --username=public --password=ddy_public hub.didiyun.com
docker pull hub.didiyun.com/ngc/pytorch:20.06-py3
docker pull hub.didiyun.com/ngc/mxnet:20.06-py3
docker pull hub.didiyun.com/ngc/tensorflow:20.06-tf1-py3
docker pull hub.didiyun.com/ngc/tensorflow:20.06-tf2-py3
docker images
3、硬件基础测试
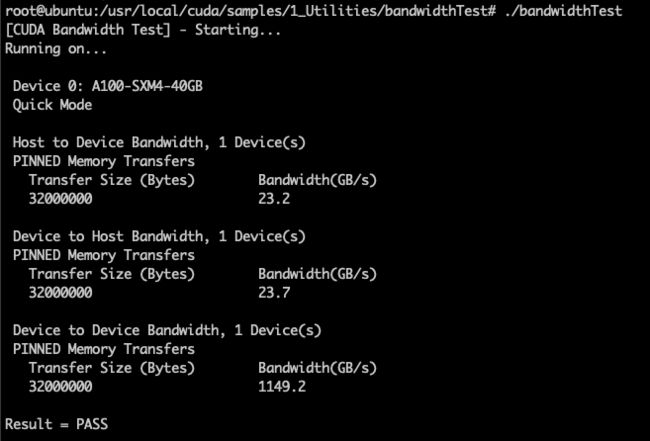
PCIe 带宽测试:cd /usr/local/cuda/samples/1_Utilities/bandwidthTest/
make
./bandwidthTest
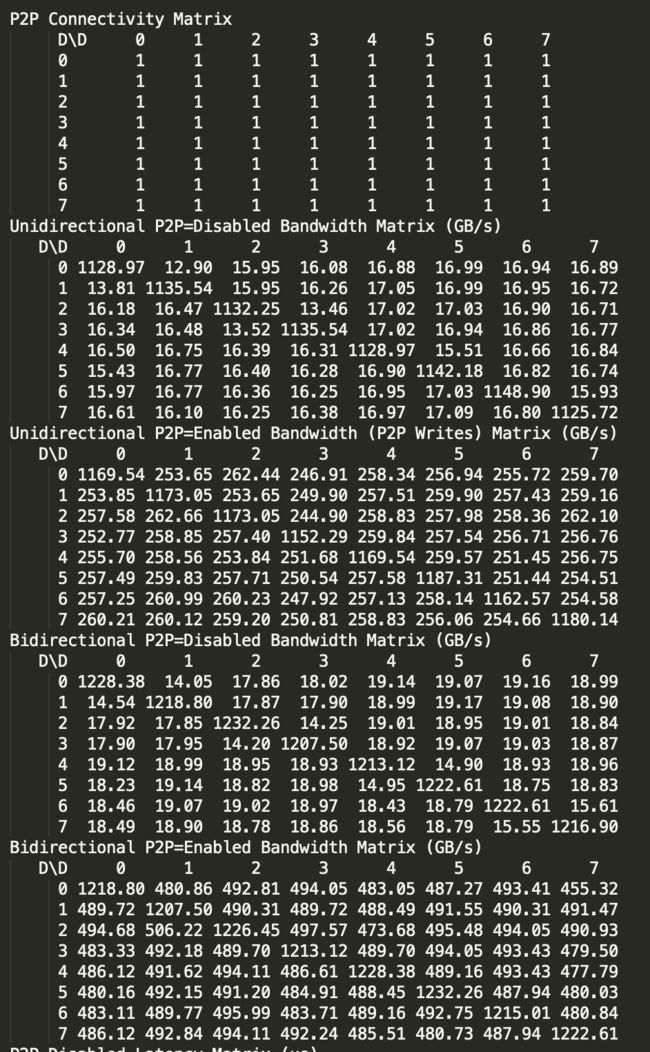
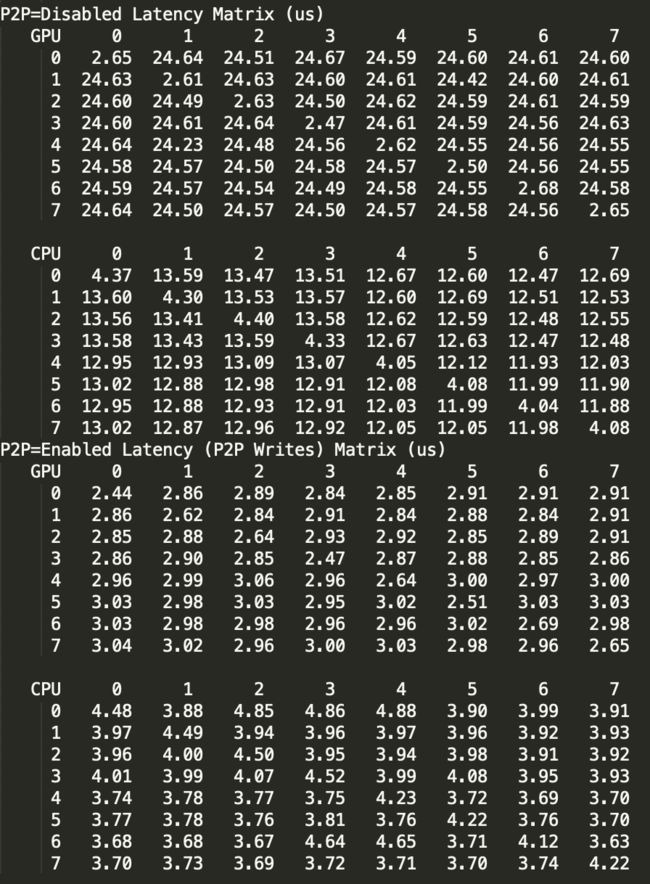
多卡 P2P 通信带宽/延迟测试:cd /usr/local/cuda/samples/1_Utilities/p2pBandwidthLatencyTest/
make
./p2pBandwidthLatencyTest
4、矩阵乘(GEMM)性能评测
这里使用 NVIDIA 开源的 CUTLASS 作为评测工具。运行步骤如下:
git clone https://github.com/NVIDIA/cutlass
mkdir build
cd build/
export CUDACXX=/usr/local/cuda/bin/nvcc
cmake .. -DCUTLASS_NVCC_ARCHS=80
make cutlass_profiler -j12
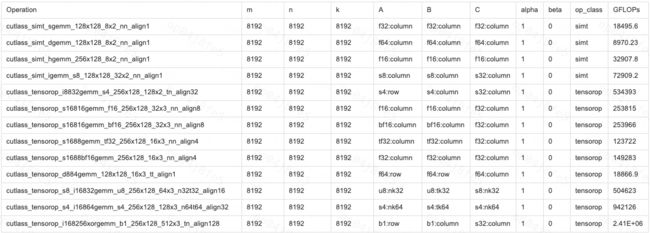
./tools/profiler/cutlass_profiler --op_class=simt --m=8192 --n=8192 --k=8192
./tools/profiler/cutlass_profiler --op_class=tensorop --m=8192 --n=8192 --k=8192
运行结束后,会打印结果,由于内容较多,下图只挑选了我们关心的几项:
5、AI 训练性能评测
A100 强大算力非常适合 AI 训练场景。为了定量评估 A100 的训练性能,我们基于 NGC 镜像内置的 ResNet 101 图像分类代码进行测试。
nvidia-docker run -ti --shm-size=64G --ulimit memlock=-1 --ulimit stack=67108864 -v /data:/data hub.didiyun.com/ngc/mxnet:20.06-py3
cd /opt/mxnet/example/image-classification/
python train_imagenet.py --benchmark 1 --gpus 0 --network resnet --num-layers 101 --batch-size 256
运行结果如下:
INFO:root:Epoch[0] Batch [240-260] Speed: 430.06 samples/sec lr:0.001039 accuracy=1.000000
INFO:root:Epoch[0] Batch [260-280] Speed: 429.93 samples/sec lr:0.001119 accuracy=1.000000
INFO:root:Epoch[0] Batch [280-300] Speed: 430.00 samples/sec lr:0.001199 accuracy=1.000000
INFO:root:Epoch[0] Batch [300-320] Speed: 429.96 samples/sec lr:0.001279 accuracy=1.000000
INFO:root:Epoch[0] Batch [320-340] Speed: 430.20 samples/sec lr:0.001359 accuracy=1.000000
INFO:root:Epoch[0] Batch [340-360] Speed: 430.21 samples/sec lr:0.001439 accuracy=1.000000
INFO:root:Epoch[0] Batch [360-380] Speed: 431.00 samples/sec lr:0.001518 accuracy=1.000000
INFO:root:Epoch[0] Batch [380-400] Speed: 429.90 samples/sec lr:0.001598 accuracy=1.000000
上述测试只用了一张卡,我们尝试 8 卡训练:
python train_imagenet.py --benchmark 1 --gpus 0,1,2,3,4,5,6,7 --network resnet --num-layers 101 --batch-size 2048
运行结果如下:
INFO:root:Epoch[0] Batch [440-460] Speed: 3385.54 samples/sec lr:0.014696 accuracy=0.253589
INFO:root:Epoch[0] Batch [460-480] Speed: 3383.47 samples/sec lr:0.015335 accuracy=0.421460
INFO:root:Epoch[0] Batch [480-500] Speed: 3386.62 samples/sec lr:0.015974 accuracy=0.559961
INFO:root:Epoch[0] Batch [500-520] Speed: 3386.76 samples/sec lr:0.016613 accuracy=0.655444
INFO:root:Epoch[0] Batch [520-540] Speed: 3384.64 samples/sec lr:0.017252 accuracy=0.731396
INFO:root:Epoch[0] Batch [540-560] Speed: 3383.85 samples/sec lr:0.017891 accuracy=0.806445
INFO:root:Epoch[0] Batch [560-580] Speed: 3384.85 samples/sec lr:0.018530 accuracy=0.872095
INFO:root:Epoch[0] Batch [580-600] Speed: 3385.41 samples/sec lr:0.019169 accuracy=0.927905
8 卡训练速度相比单卡加速比约 7.87 倍,接近线性加速。
在另一个终端运行 nvidia-smi 可以显示 GPU 利用情况:
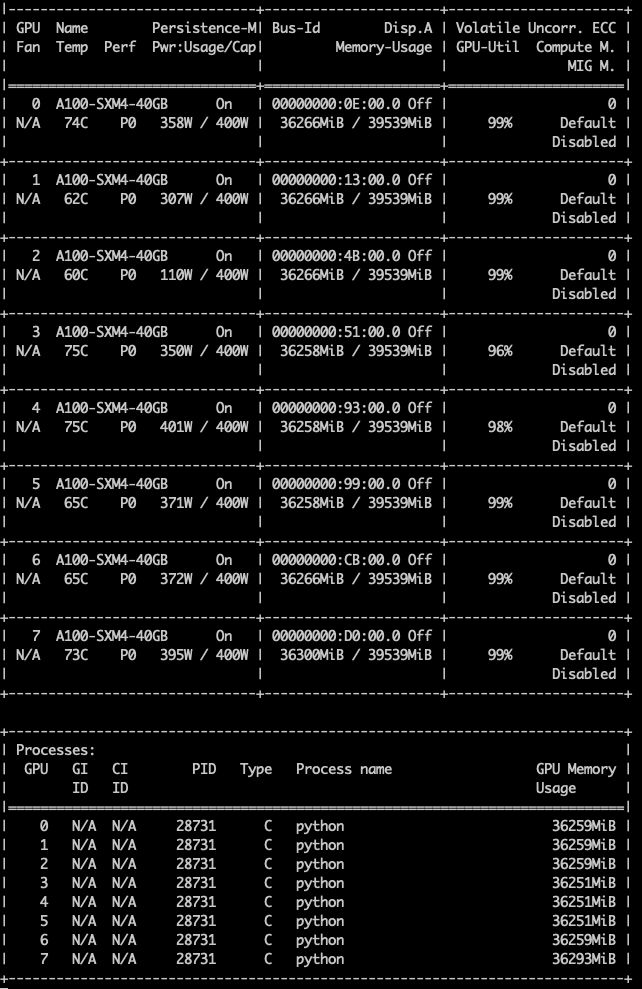
可见每卡显存占用约 36 GB,计算资源占用都在 99% 左右,硬件效率得到充分发挥。
和 RTX 2080Ti 对比结果
A1002080TiA100/2080Ti 加速比1 卡430.2170.712.52X
8 卡33841102.643.07X
多卡线性加速比7.87X6.46X——
说明:A100 多卡情况下 NVLink 表现更为优异,接近线性加速;2080Ti 则依赖 PCIe 进行通信,不支持 P2P,多卡扩展性较差。
6、AI 推理性能评测
先根据 2.4 节手动安装 Tensor RT,之后进入例程所在目录,编译:cd /work/TensorRT-7.1.3.4/samples/
make
cd ..
export LD_LIBRARY_PATH=$(pwd)/lib:$LD_LIBRARY_PATH
./bin/trtexec --deploy={resnet18.prototxt, resnet50.prototxt, vgg16.prototxt} --output=prob --warmUp=10 --batch={1,2,4,8,16,32,64,128,256,512} --workspace=1024 {--useCudaGraph} {--noTF32} {--fp16} {--int8}
利用该工具,对 ResNet-18、ResNet-50 和 VGG-16 三个模型,在不同精度(FP32、TF32、FP16、INT8)、不同 Batch Size 情况下评测其吞吐和延迟情况,结果见下表:
Throughput(fps)
ResNet-18Batch\PrecisionFP32TF32FP32(cudagraph)TF32(cudagraph)FP16INT8
1785.721363.86835.391455.063110.104102.16
21252.802475.301438.272607.655919.077454.90
42361.483781.432581.814584.2210415.7713374.71
83253.705572.313423.516435.2116516.1321881.78
164027.049422.854285.529674.9823011.2532141.23
325153.4212207.505417.7712391.0026282.7245495.32
645587.3213205.085873.0113778.6728827.6649484.66
1285985.4514647.276129.5914948.4930606.4159775.10
2565182.3112188.565474.8912225.5231561.7667693.71
5125308.9312366.765335.4412484.7030923.2974240.77
ResNet-50
Batch\PrecisionFP32TF32FP32(cudagraph)TF32(cudagraph)FP16INT8
1421.0951844556.1271307479.8855953594.37836941569.9499032017.735899
2697.78557751020.970739735.91639991089.9123172976.7441863570.274608
41133.5651471736.8800421234.5717121852.1862745215.3414486220.201348
81273.2244092444.4648151299.0513682550.5974778198.14926810170.08191
161883.4386883613.5490021946.8249113696.47333310556.7358614766.95893
322253.0609955148.2536162374.4509085532.10174912028.2664318701.20155
6425005977.4537912563.8971246147.34415513069.9466821656.30097
1282625.2802186502.2808782672.3119266626.73369313963.3266324196.41439
2562264.3445345641.0527612621.9460995767.27253113943.8867526446.63616
5122483.4115875873.7151252781.7167325940.21957915028.9424627950.19188
VGG16
Batch\PrecisionFP32TF32FP32(cudagraph)TF32(cudagraph)FP16INT8
1367.8201507541.6325889376.7599399558.03571431860.1259681455.061869
2468.263445769.2514798479.411666791.70295312897.7695872295.159852
4566.37007751062.92517573.68972851081.4639784115.5481293898.407501
8630.4971471330.012735636.29928341347.679384938.6679185694.314938
16671.75521241423.044426674.71261461432.1774475554.8419137352.839805
32803.56985911521.201749811.41457451536.0835635875.160199204.501001
64843.84180081557.321602936.41315721570.902956193.5683669776.201365
128898.80697421596.42401933.80899231601.8862216264.10034310503.16736
256791.26150571530.834963940.06360121677.8083636341.32687311221.37672
512857.7723051499.193305883.69564281570.2149856389.36968611372.64745
7、MIG 测试
A100 的强大算力对于 AI 推理而言有些过剩,此时可以通过 MIG 技术将 1 张卡切为多份,同时运行多个不同推理任务来提高硬件利用率。
下表为物理卡与不同规格 MIG 实例的硬件参数与计算/IO 性能对比。
MIG 规格物理卡 A100-SXM4-40GBMIG 7g.39gbMIG 4g.20gbMIG 2g.10gbMIG 1g.5gb显存容量40 GB40 GB20 GB10 GB5 GB
SM 数量10898562814
显存带宽1228.38 GB/s1119.5 GB/s619.7 GB/s322.5 GB/s164.2 GB/s
FP32 峰值计算性能19106.8 GFLOPS17307.5 GFLOPS9938.76 GFLOPS4973.4 GFLOPS2487.69 GFLOPS
经测试发现当前 MIG 有如下限制:
1) 目前无法监控每个 MIG instance 的 GPU Util、Mem Util 等指标;
2) 无论规格大小,都不支持 NVLink;
3) GPU 时钟为全局设置,不能只针对某一个 instance 单独设置;
4) 仅支持 Docker,K8S 集成还未支持;
5) 不支持在一个进程中同时使用多个 instance;
在不同规格 MIG 实例上测试 AI 推理性能,结果如下:
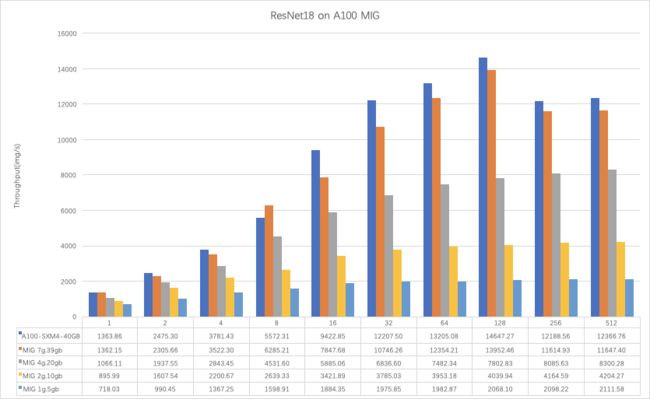


注意:小规格 MIG 实例由于资源较少,运行时可能发生 OOM,需要适当调小模型 Batch Size。
如需测试 MIG 功能,请联系滴滴云工程师协助配置环境。
8、总结
A100 提供了全新的使用体验,性能提升显著,资源粒度更小,部署灵活性更高。
当前仍处于早期试水阶段,NV 一些库和上层 AI 框架还在不断调整中,社区版框架普遍还未很好支持,用起来需要花些时间和精力。