论文笔记之Distributed Representations of Words and Phrases and their Compositionality
这篇文章是用于解决skip-gram和CBOW两种模型在计算softmax时因为语料库V太大导致计算复杂度偏高的问题。为了降低复杂度,提高运算效率,论文作者提出了层次softmax以及负采样的方式去解决(负采样会比层次softmax用的更多些)。此外,作者还提出了一种重采样方式去使得采样更偏重一些含重要信息的词。
参考:
①B站视频
②论文
③Word2vec的两种原模型
④Word2vec 中的数学原理详解
⑤Word2Vec-知其然知其所以然
Distributed Representations of Words and Phrases and their Compositionality
- 1 Hierarchical Softmax
-
- 1.1 Skip-gram HS构建
- 1.2 CBOW HS的构建
- 2 Negative Sampling
-
- 2.1 Skip-gram中的NS
- 2.2 CBOW中的NS
- 3 Subsampling of Frequent Words
- 4 实战演练
-
- 4.1 PTB数据集
- 4.2 模型训练
- 5 Conclusion
文章介绍了2种可以简化skip-gram和CBOW两种模型中softmax部分的计算复杂度,即Hierarchical Softmax(HS)和Negative Sampling(NS)。这两种技巧均可用于上述2种模型,故HS和NS的目标就是改变softmax的表达式:
p ( o ∣ c ) = e x p ( u o T v c ) ∑ w = 1 V e x p ( u w T v c ) (1) p(o|c) = \frac{exp(u_o^Tv_c)}{\sum^V_{w=1}exp(u^T_wv_c)}\tag{1} p(o∣c)=∑w=1Vexp(uwTvc)exp(uoTvc)(1)
从式(1)中可以看出,计算一次概率需要经过 V V V(语料库大小)次的指数运算,那么自然HS和NS就要想办法在保证求出概率 p ( o ∣ c ) p(o|c) p(o∣c)的情况下,减小 u w T v c u^T_wv_c uwTvc的运算次数。因此原skip-gram以及CBOW的softmax需要做出改进。
1 Hierarchical Softmax
层次softmax的核心思想就是通过引出二叉树结构(Huffmax 二叉树)将求softmax的计算转为求sigmoid的计算,从而将计算复杂度从 V V V降到 l o g 2 V log_2V log2V以下,即从原来的需要求 V V V次关于 u w T v c u_w^Tv_c uwTvc的指数运算降低到求小于 l o g 2 V log_2V log2V次的sigmoid运算( s i g m o i d : σ ( x ) = 1 1 + e − x sigmoid: \sigma(x) = \frac{1}{1+e^{-x}} sigmoid:σ(x)=1+e−x1)。
为了便于理解,我们中间加入满二叉树过程而不是直接到Huffman树过程。

上图是一个满二叉树(V=8),可以看到,每次计算一个词 a a a的概率需要进行 l o g 2 V = 3 log_2V=3 log2V=3次的二分类过程,也就是说需要进行3次的sigmoid计算。
那么满二叉树达到了 l o g 2 V log_2V log2V的优化程度,那么有没有更快的方式呢?——引入Huffman树。

哈夫曼树是带权重路径最短二叉树,它基于将权值小的节点放的位子深(越小越接近叶子节点),权值大的节点放的位子浅(越大越靠近根节点)的原则来实现比满二叉树更小的路径和。
Note:
- 在层次softmax的CBOW和skip-gram模型中,你无法采用 W + W ∗ 2 \frac{W+W^*}{2} 2W+W∗的形式来做,因为在skip-gram模型中,只有一组完整的中心词向量矩阵 W W W,而中心词向量矩阵是由 θ \theta θ组成的,其维度势必小于 V V V,故 W W W和 W ∗ W^* W∗是size不同的两个矩阵。同理,在CBOW模型中,只有一组完整的周围词向量矩阵 W W W,而 W ∗ W^* W∗的size是比 W W W要小的,故不能相加。
- 对于HS,有的词概率计算用的sigmoid次数可能小于 l o g 2 V log_2V log2V,有的可能要大于 l o g 2 V log_2V log2V,平均下来是 l o g 2 V log_2V log2V。
1.1 Skip-gram HS构建
Skip-gram中哈夫曼树的构建:
- 输出层是一课Huffman树。
- 叶子节点是语料库中的词。
- 将某个词出现的频率作为叶子节点的权值,频率越大的层数越浅,频率越小的层数越深。

如上图所示,比如说我们要去求"词I"的概率,我们用HS技巧来取代softmax计算,设c为中心词:
p ( I ∣ c ) = σ ( θ 0 T v c ) ⋅ σ ( θ 1 T v c ) ⋅ ( 1 − σ ( θ 2 T v c ) ) = σ ( θ 0 T v c ) ⋅ σ ( θ 1 T v c ) ⋅ σ ( − θ 2 T v c ) (2) p(I|c) = \sigma(\theta_0^Tv_c)\cdot\sigma(\theta_1^Tv_c)\cdot(1-\sigma(\theta_2^Tv_c))\\ = \sigma(\theta_0^Tv_c)\cdot\sigma(\theta_1^Tv_c)\cdot\sigma(-\theta_2^Tv_c)\tag{2} p(I∣c)=σ(θ0Tvc)⋅σ(θ1Tvc)⋅(1−σ(θ2Tvc))=σ(θ0Tvc)⋅σ(θ1Tvc)⋅σ(−θ2Tvc)(2)
- θ \theta θ参数的个数一定是小于 V V V的,其没有具体意义,实在要一个意义的话,可以理解为该节点以下整一簇的上下文词向量。
- θ \theta θ的个数大约有 l o g 2 V log_2V log2V个,比 V V V要略大。
- 树的高度大约是 O ( log 2 V ) O(\log_2V) O(log2V)。
上图的意思大概就是:从根节点出发,以一半一半的概率走向两个子节点,需要注意的是同一层的两个结点之和为1。然后一半一半的概率继续往下走,当第三次分开走的时候就遇到了我们要求的“词I”,我们把它拿出来做反向传播就行了。具体写成公式如下:
p ( w ∣ w I ) = ∏ j = 1 L ( w ) − 1 σ ( δ ( n ( w , j + 1 ) = = c h ( n ( w , j ) ) ) ⋅ θ n ( w , j ) T v w I ) (3) p(w|w_I) = \prod_{j=1}^{L(w)-1}\sigma(\delta(n(w,j+1)==ch(n(w,j)))\cdot \theta_{n(w,j)}^Tv_{w_I})\tag{3} p(w∣wI)=j=1∏L(w)−1σ(δ(n(w,j+1)==ch(n(w,j)))⋅θn(w,j)TvwI)(3)
Note:
- n ( w , j ) n(w,j) n(w,j)表示词 w w w在树上的第j个节点,比如 n ( w , 1 ) n(w,1) n(w,1)就是根节点。
- δ ( n ( w , j + 1 ) = = c h ( n ( w , j ) ) ) \delta(n(w,j+1)==ch(n(w,j))) δ(n(w,j+1)==ch(n(w,j)))表示当节点 n ( w , j ) n(w,j) n(w,j)的右儿子节点是词 w w w的下一个节点的时候,那么就取正号,否则就取负号。
- 公式(3)中 v w I v_{w_I} vwI表示中心词向量。
1.2 CBOW HS的构建
在CBOW中HS和skip-gram中差不多,只是公式上略微有点变化。因为和skip-gram相反,CBOW要改变中心词向量矩阵 W ∗ W^* W∗,具体如下:
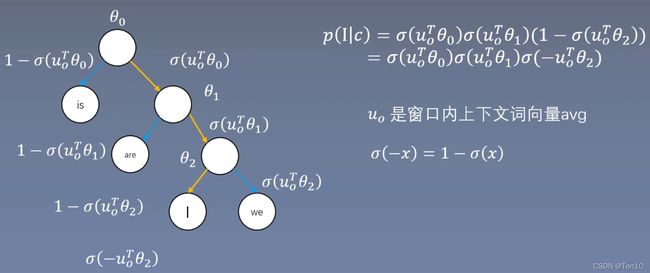
- 如上图所示, θ \theta θ在CBOW中的含义大概是中心词向量,而非skip-gram中的上下文词向量。
对应skip-gram中的公式3,CBOW也要略微进行修改:
p ( w ∣ w I ) = ∏ j = 1 L ( w ) − 1 σ ( δ ( n ( w , j + 1 ) = = c h ( n ( w , j ) ) ) ⋅ u w I T θ n ( w , j ) ) (4) p(w|w_I) = \prod_{j=1}^{L(w)-1}\sigma(\delta(n(w,j+1)==ch(n(w,j)))\cdot u_{w_I}^T \theta_{n(w,j)})\tag{4} p(w∣wI)=j=1∏L(w)−1σ(δ(n(w,j+1)==ch(n(w,j)))⋅uwITθn(w,j))(4)
2 Negative Sampling
负采样的核心思想就是将多分类(V类)问题转为二分类问题。Softmax之所以慢,是因为它涉及一个多分类问题,且和词表大小 V V V相关的。负采样就是舍弃多分类,转为二分类来提升速度。
2.1 Skip-gram中的NS
既然是二分类,正样本由中心词以及窗口内上下文词组成;负样本由中心词和词库中随意采样的样本组成。
先给出负采样的核心公式,即目标函数:
J n e g − s a m p l e ( θ ) = l o g σ ( u o T v c ) + ∑ k = 1 K E k ∼ P ( w ) [ l o g σ ( − u k T v c ) ] (5) J_{neg-sample}(\theta) = log\sigma(u_o^Tv_c) + \sum^K_{k=1}\mathbb{E}_{k\sim P(w)}[log\sigma(-u_k^Tv_c)]\tag{5} Jneg−sample(θ)=logσ(uoTvc)+k=1∑KEk∼P(w)[logσ(−ukTvc)](5)
- v c v_c vc是中心词向量; u o u_o uo是窗口内上下文词向量; u k u_k uk是负采样上下文词向量。
- 我们的目标是最大化式(5),即正样本的 u o T v c u_o^Tv_c uoTvc概率越大越好;负样本 u k T v c u_k^Tv_c ukTvc越小越好。这也是二分类的核心思想:增大正样本概率,减小负样本概率。
- 对于每个词,一次要输出 K + 1 K+1 K+1个概率,一般也不大(3~10),所以会比Hierarchical Softmax需要计算大约 l o g 2 V log_2V log2V个概率或者原模型需要的 V V V个概率要高效很多。
- 我们之所以取期望 E \mathbb{E} E以及采取多个负样本,就是因为负样本是采样得来的,需要多采样几份求平均。
- NS里面还是需要完整的 W W W和 W ∗ W^* W∗,故总的参数比HS要多,但是每次的计算量不多。
2.2 CBOW中的NS
大多数和skip-gram中的NS类似,除了正负样本的定义以及目标函数。
正样本由中心词及其窗口内上下文词的平均组成;负样本窗口内上下文词的平均和随机采样的词组成。
其目标函数为:
J n e g − s a m p l e ( θ ) = l o g σ ( u o T v c ) + ∑ k = 1 K E k ∼ P ( w ) [ l o g σ ( − u o T v k ) ] (6) J_{neg-sample}(\theta) = log\sigma(u_o^Tv_c) + \sum^K_{k=1}\mathbb{E}_{k\sim P(w)}[log\sigma(-u_o^Tv_k)]\tag{6} Jneg−sample(θ)=logσ(uoTvc)+k=1∑KEk∼P(w)[logσ(−uoTvk)](6)
Note:
- u o u_o uo是窗口内上下文词向量; v c v_c vc是正确的中心词向量; v k v_k vk是错误的中心词向量。
如何采样呢?

- 采样的核心思想就是减小频率大的词的采样概率,增加概率小的词的采样概率。之所以这么做,是因为概率小的词往往比较重要,反之概率大的词不太重要,如“the、a、to、的”。
3 Subsampling of Frequent Words
自然语言共识:在语料库中出现频率高的词往往不太重要,所含信息较少,如“a、and、the”;在语料中出现频率低的词往往比较重要,所含信息比较多。
重采样的原因:
- 更多地训练重要的词对,比如训练“Chinese”和“HangZhou”的关系,少训练“Chinese”和“the”之间的关系。
- 高频词很快就训练好了,而低频词需要训练更多的轮次。
重采样方式:
P ( w i ) = m a x ( 0 , 1 − t f ( w i ) ) . P(w_i) = max(0, 1-\sqrt{\frac{t}{f(w_i)}}). P(wi)=max(0,1−f(wi)t).
- 其中 f ( w i ) f(w_i) f(wi)为词 w i w_i wi在数据集中出现的概率。文中选取 t = 1 0 − 5 t=10^{-5} t=10−5,训练集中的词 w i w_i wi会以 P ( w i ) P(w_i) P(wi)的概率删除。
- 词频越大, f ( w i ) f(w_i) f(wi)越大, P ( w i ) P(w_i) P(wi)越大,那么词 w i w_i wi就有更大的概率被删除。
- 实验表明,重采样可以加加速训练,得到更好的词向量。
4 实战演练
实战部分基于Negative Sampling的Skip-gram模型。
Pytorch库
4.1 PTB数据集
语料库:PTB数据集

PTB数据集主要是三个.txt文件:ptb_test.txt、ptb_train.txt、ptb_valid.txt。其中ptb_train.txt文件部分截图如上所示,其每一行都是一句话,便于直接读取。其中句尾符为,生僻词为,数字则用N表示。
训练部分我们将读取ptb_train.txt文件,其中共有887521个单词。
4.2 模型训练

数据预处理:
由于窗口的大小是随机选取的,因此不同中心词对应的上下文词的长度是不一样的,但是负采样值的长度和上下文词是一样的,这样就导致了训练过程中数据不对齐,我们可以采用补0的形式,然后用掩码去解决0带来的影响,让补0部分不参与训练。
其中前向推断如下:

中心词:(batch,1)
上下文词+负采样值:(batch,S)
Embding层:(词表大小N,D)——调用nn.Embding类
中心词向量:(batch,1, D)
周围词向量矩阵:(batch, S,D)
Label和来自中心词向量和周围词向量的乘积做二分类交叉熵Loss。
Note:
- 在batch个中心词向量中,每一个中心词对应一个长度为S的,由周围词和负采样值以及掩码组成,因此这就相当于一个中心词对应窗口内的周围词都做了运算。
- 这里和之前写的那篇Word2Vec笔记中不一样的一点是,并没有从索引到one-hot,再用矩阵乘法输出中心词向量,而是直接将索引通过Embding层挑选出指定索引对应的中心词向量。
- 最后我们所想要的就是上图绿色Embding层的weight参数。
5 Conclusion

从模型复杂度理论对比以及实验来看:
- CBOW和skip-gram都比NNLM或者RNNLM要快。
- CBOW要比skip-gram计算要快一些。
- 当 K K K不超过14时候,负采样要比层次softmax要高效。