Medical Dialogue Response Generation with Pivotal Information Recalling翻译
摘要
医学对话生成是一项重要但具有挑战性的任务。以前的大多数工作都依赖于注意力机制和大规模预训练的语言模型。但是,由于医疗实体以及它们之间的复杂关系通常散布在多种语句中,这些方法通常无法从长对话历史中获取这些关键信息,从而产生准确和信息丰富的响应。为了减轻此问题,我们提出了一个具有Pivotal Information Recalling (MedPIR)的医疗响应生成模型,该模型建立在两个组件上,即基于知识的对话图编码器和召回增强生成器。基于知识的对话图编码器通过利用语句中实体之间的知识关系,以及图注意力网络来构建对话图。然后,召回增强生成器通过在生成实际响应之前生成对话的摘要来增强这些关键信息的使用。在两个大型医疗对话数据集上的实验结果表明,MedPIR在BLEU分数和医疗实体F1度量中的表现都优于强基线。
1.介绍

医疗对话系统(MDS)由于其较高的实用价值而受到了很多关注。以前的工作通常将对话历史建模为文本序列,并采用基于大规模文本预训练的编码器和解码器来构建序列到序列(Seq2Seq)模型。
为了全面理解患者,医疗对话总是相对较长,并且这些语句中散布着丰富的医学术语。一些工作将外部医学知识引入Seq2Seq模型,并表明它可以改善性能。但是这些工作无法充分利用不同语句之间的复杂医学关系,这对于生成下一个响应很重要。如图1所示,实体tenesmus和enteritis表明了语句#1和语句#4之间的症状疾病关系。由于忽略了语句之间的医学关系,强基线模型BERT-GPT-Entity在生成的响应中忽略了关键实体colitis。我们的MedPIR能从enteritis中得出colitis,并产生更准确的响应。
MDS的关键是如何从长对话历史中获取关键信息。以前的工作在很大程度上依靠交叉注意力机制来使用对话历史,这无法定位长序列中的关键信息。这个问题可能是由于交叉注意力机制在召回关键信息时没用使用显式的监督信号进行训练。最近的工作提出从对话历史中提取医学关键短语和句子,并通过交叉注意力机制将其整合到响应生成中。但是,这些工作忽略了利用不同话语之间的医学关系,并且在响应生成期间无法完全利用对话历史的关键信息。
上述调查表明,对多种话语之间的复杂医学关系进行建模是很重要的,这能够在响应生成过程中明确指导解码器充分利用关键信息。在这项工作中,我们提出了一个具有关键信息召回(MedPIR)的医疗响应生成模型,在该模型中,我们强迫生成器在生成期间召回关键信息。它主要包含基于知识对话图编码器和召回增强生成器。
基于知识的对话图编码器利用散布在不同语句中的医学实体及其知识关系来构建对话图,并将基于图注意力网络获得的表示带入到生成器。因此,基于知识的对话图编码器可以促使生成器从全局对话结构的角度使用分布在多种语句中的关键医学信息。召回增强生成器旨在从长对话历史中显式生成关键信息。然后,关键信息序列用作响应的前缀,以提示生成更多的关键响应。通过这种方式,召回生成器强制执行显式的交叉注意力机制,以充分利用编码器中的关键信息。此外,召回增强生成器还通过解码器内的自注意力机制强化了响应和关键信息的交互能力。此外,我们还从医学知识图CMeKG中检索了相关知识,并使用基于医学对话数据预训练的模型获得对医学知识的深入了解。
我们的贡献可以总结如下:
(1)我们提出了一个具有关键信息召回(MedPIR)的MDS模型。 它可以通过基于知识的对话图编码器充分利用语句之间的复杂医学关系,并从长对话历史中召回关键信息,以在召回增强生成器中产生准确的响应。
(2)我们对大规模医学对话数据集MedDG和MedDialog进行了广泛的实验。实验结果表明,我们提出的模型优于以前的强基线VRBot和BERT-GPT-Entity。
2.相关工作
Medical Dialogue System (MDS)。以前的MDS主要采用序列到序列框架。它由编码对话历史的上下文编码器和生成响应的解码器组成。由于医学对话通常很长并且包含专业的医学信息,因此注意力机制很难捕获对话历史中的关键信息。为了识别医学对话中的关键信息,Du et al. 和Zhang et al. 从对话历史中提取患者的症状和医疗状况。最近,Li et al. 提出了通过关键短语总结诊断历史来加强变分医学对话生成模型。但是,这些方法仅通过短语提取关键信息,并且无法完全使用散布在对话历史中的复杂关键信息。与以前的工作不同,我们构建了医学对话图,该图利用了话语之间的医学关系,并在生成实际响应之前训练模型来生成关键信息,以便该模型可以学会专注于关键信息。
Dialogue Graph Construction。为了建模对话中语句之间的关系,Chen et al.,Sun et al.,Xu et al. 提出根据对话状态转移来构建对话结构图。Feng et al. 提出通过建模不同的语句关系来建模会议的对话结构。但是,他们没有利用外部知识库,这对于生成医学对话响应至关重要。相比之下,我们通过将CMeKG中的外部医学知识纳入了基于知识的对话图。
Knowledge-grounded Dialogue Generation。最近的工作提出,通过从类似ConceptNet等常识图中检索相关知识,并将目标事实纳入生成中,以提高对话建模的性能。Dinan et al.,Kim et al.,Lian et al,Zhao et al. 通过从非结构化文档中检索来促进基于知识的对话生成。Li et al. 和Lin et al. 通过复制机制使用医学知识图来指导响应生成,但他们没有使用医学知识图去建模对话结构。在这项工作中,外部知识被用于去构建对话图,并且还用知识编码器进行编码。
3.方法
医学对话的关键信息通常会散布在整个长对话历史中,因此传统的MDS模型很难从对话历史上获取关键信息。在本节中,我们首先在第3.1节中描述基本的医学响应生成模型。然后,我们引入了两种技术,以提高对话中关键信息的召回,即基于知识的对话图编码器(第3.2节)和召回增强生成器(第3.3节)。最后,我们在第3.4节中介绍提出的训练方法。
3.1 Base Model
对话响应生成中的大多数工作都采用序列到序列结构来建模对话历史并利用外部医学知识来产生响应。对于我们的基础模型来说,我们采用与Chen et al.类似的方法,并使用BERT-GPT作为我们编码器和生成器的backbone。给定医生和患者之间的对话历史 X = ( X 1 , X 2 , . . . , X M ) X=(X_1,X_2,...,X_M) X=(X1,X2,...,XM),其中 X i = ( x i , 1 , x i , 2 , . . . , x i , ∣ X i ∣ ) X_i=(x_{i,1},x_{i,2},...,x_{i,|X_i|}) Xi=(xi,1,xi,2,...,xi,∣Xi∣)是对话历史中的第 i i i个语句,上下文编码器编码拼接后的语句以获取编码上下文 H c t x H_{ctx} Hctx。
我们还采用和以前工作相同的方法来检索外部知识,并使用知识编码器来获取编码后的知识 H k H_k Hk(更多详细信息在第4.1.4节中详细介绍)。基础模型基于 H c t x H_{ctx} Hctx和 H k H_k Hk来生成响应 Y = ( y 1 , y 2 , . . . , y ∣ Y ∣ ) Y=(y_1,y_2,...,y_{|Y|}) Y=(y1,y2,...,y∣Y∣)。
3.2 Knowledge-aware Dialogue Graph Encoder
由于基础对话模型仅将医学对话历史视为一系列语句,因此很难对不同话语之间的多种医学因果关系进行建模,这意味着很难将关键医学信息带入到下一个响应中。为了解决这个问题,我们提出了基于知识的对话图编码器(KDGE),然后用图注意力网络编码图。
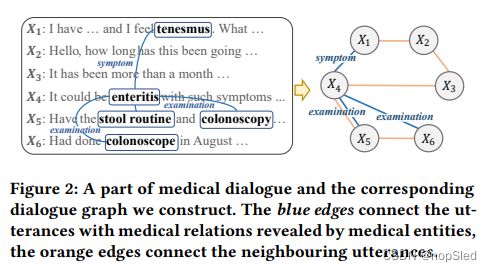
首先,我们将对话历史序列转换为图。每个语句都被看作一个顶点,顶点之间有两种类型的边。一种类型的边用于连接相邻语句,这种边表示了正常的时间关系。另一种类型的边是基于知识的边,它将分散的语句通过医学关系联系起来。这些基于知识的边将来自外部医学知识图的医学知识纳入到对话中,从而使模型能够表示语句复杂的医学关系。更具体地说,我们首先从每个语句中提取医学实体,然后从外部知识图中查找它们之间的关系。如果两种语句中的医学实体之间存在关系,那么我们就在两个语句之间增加基于知识的边。图2显示了此操作过程的示例。在图的左侧,加粗单词是散布在话语中的实体,蓝线将实体通过某些关系联系起来,图的右侧代表构建的基于知识的对话图。
使用构建的基于知识的对话图 G G G,然后我们应用由Busbridge et al.提出的关系图注意力网络(RGAT),以在对话中编码这些关键关系信息。对于 G G G中的每个顶点 v i v_i vi,我们使用基于transformer的编码器来编码其相应的语句,并计算字符表示的均值作为句子嵌入。然后,将语句嵌入与说话人嵌入拼接以形成 v i v_i vi的初始节点嵌入。最后,RGAT用于计算顶点更新后的编码:
( v 1 , . . . , v M ) = R G A T ( ( v 1 0 , . . . , v M 0 ) , G ) . (1) (v_1,...,v_M)=RGAT((v^0_1,...,v^0_M),G).\tag{1} (v1,...,vM)=RGAT((v10,...,vM0),G).(1)
为了进行对话召回,我们将上下文编码视为初始历史表示,并将召回得分 a v i a_{v_i} avi定义为语句 X i X_i Xi在召回中的重要性:
a v i = σ ( ( W v q h c t x ) T ( W v k v i ) ) , (2) a_{v_i}=\sigma((W^q_vh_{ctx})^T(W^k_vv_i)),\tag{2} avi=σ((Wvqhctx)T(Wvkvi)),(2)
其中 h c t x h_{ctx} hctx是对 H c t x H_{ctx} Hctx进行平均池化得到, W v q W^q_v Wvq和 W v k W^k_v Wvk是可训练的参数,Font metrics not found for font: .表示sigmoid函数。然后,通过编码 h i h_i hi和顶点编码 v i v_i vi相加后加权作为 X i X_i Xi的最终编码:
h s t c , i = a v i ( h i + v i ) . (3) h_{stc,i}=a_{v_i}(h_i+v_i).\tag{3} hstc,i=avi(hi+vi).(3)
{ h s t c , i } i = 1 M \{h_{stc,i}\}^M_{i=1} {hstc,i}i=1M的拼接是最终的结构编码,表示为 H s t c H_{stc} Hstc。
3.3 Recall-Enhanced Generator
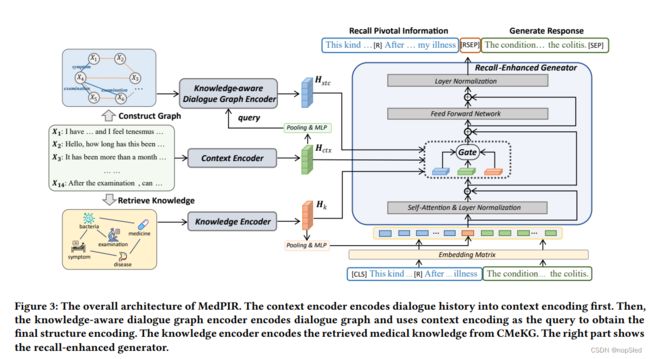
在基础模型中,生成器首先对生成序列使用单向自注意力,以获得每个解码时刻的解码状态,然后通过交叉注意力机制使用 H c t x H_{ctx} Hctx和 H k H_k Hk。当这种对话模型仅用来训练以生成响应时,其注意力机制通常会被长对话历史所淹没,并且无法专注于关键信息。我们提出Recall-Enhanced Generator (REG),以在生成响应之前来显式生成关键信息 R \mathcal R R。 R \mathcal R R是一个简短的摘要,其包含了对话历史中的关键医学信息。生产 R \mathcal R R后,它将继续生成实际响应,如下所示:
y t = R E G ( H c t x , H k , H s t c , [ R ; y < t ] ) , (4) y_t=REG(H_{ctx},H_k,H_{stc},[\mathcal R;y_{\lt t}]),\tag{4} yt=REG(Hctx,Hk,Hstc,[R;y<t]),(4)
在训练时, R \mathcal R R通过使用医学预训练模型PCL-MedBERT自动构建(在第3.4节中介绍的更多详细信息),然后作为监督信号训练模型以召回关键信息。在测试时,MedPIR将首先产生召回的信息,然后生成响应。该方法有两个主要优点:1)合格的预生成召回 R \mathcal R R为生成器提供了访问关键历史信息的快捷方式;2)召回增强交叉注意力机制能捕获编码器提供的关键信息。
如图3的右半部分所示,字符首先通过嵌入矩阵转换为嵌入,以作为生成器的初始隐藏状态输入。然后,REG依次生成召回的关键信息 R \mathcal R R,一个分隔符,最后生成目标响应 Y Y Y。请注意,我们使用的知识编码的平均池化作为分隔符的嵌入,以在生成过程中驱动知识融合,如图3右下部分所示。
更具体地说,REG由多层解码器块组成。令 h t l − 1 h^{l-1}_t htl−1表示第 ( l − 1 ) (l-1) (l−1)层在第 t t t步的输出。第 l l l层的计算过程可以表达为:
h S , t l = L a y e r N o r m ( S A ( h t l − 1 ) + h t l − 1 ) , (5) h^l_{S,t}=LayerNorm\bigg(SA(h^{l-1}_t)+h^{l-1}_t\bigg),\tag{5} hS,tl=LayerNorm(SA(htl−1)+htl−1),(5)
h F , t l = F u s i o n ( H c t x , H s t c , H k ) + h S , t l , (6) h^l_{F,t}=Fusion(H_{ctx},H_{stc},H_k)+h^l_{S,t},\tag{6} hF,tl=Fusion(Hctx,Hstc,Hk)+hS,tl,(6)
h t l = L a y e r N o r m ( F F N ( h F , t l ) + h F , t l ) , (7) h^l_t=LayerNorm\bigg(FFN(h^l_{F,t})+h^l_{F,t}\bigg),\tag{7} htl=LayerNorm(FFN(hF,tl)+hF,tl),(7)
其中,SA表示解码器中的单向自注意力,而FFN是一个前馈网络。
为了整合来自不同类型编码器的信息,我们引入了 F u s i o n ( ⋅ ) Fusion(·) Fusion(⋅)操作,该操作是一种结合了上下文编码 H c t x H_{ctx} Hctx,结构编码 H s t c H_{stc} Hstc和知识编码 H k H_k Hk的门控机制。它首先通过将 h S , t l h^l_{S,t} hS,tl作为query分别和 H c t x H_{ctx} Hctx, H s t c H_{stc} Hstc和 H k H_k Hk执行交叉注意力(CA)来聚集多方面的编码信息,然后使用门控分数对编码信息进行加权求和:
F u s i o n ( ⋅ ) = g c t x l C A l ( H c t x , h S , t l ) + g k l C A l ( H k , h S , t l ) + g s t c l C A l ( H s t c , h S , t l ) , (8) Fusion(\cdot)=g^l_{ctx}CA^l(H_{ctx},h^l_{S,t})+g^l_kCA^l(H_k,h^l_{S,t})+g^l_{stc}CA^l(H_{stc},h^l_{S,t}),\tag{8} Fusion(⋅)=gctxlCAl(Hctx,hS,tl)+gklCAl(Hk,hS,tl)+gstclCAl(Hstc,hS,tl),(8)
其中门控分数 g c t x g_{ctx} gctx, g s t c g_{stc} gstc和 g k g_k gk是通过具有sigmoid函数的线性层获得的:
g l = σ ( W l C A l ( H , h S , t l ) ) . (9) g^l=\sigma\bigg(W^lCA^l(H,h^l_{S,t})\bigg).\tag{9} gl=σ(WlCAl(H,hS,tl)).(9)
然后,三个门控分数通过softmax函数进行归一化,以货的等式(8)中的最终门控分数。
在最后一层,使用一个输出投影层以获得最终生成的词汇分布 p t p_t pt:
p t = s o f t m a x ( W v h t L + b v ) . (10) p_t=softmax(W_vh^L_t+b_v).\tag{10} pt=softmax(WvhtL+bv).(10)
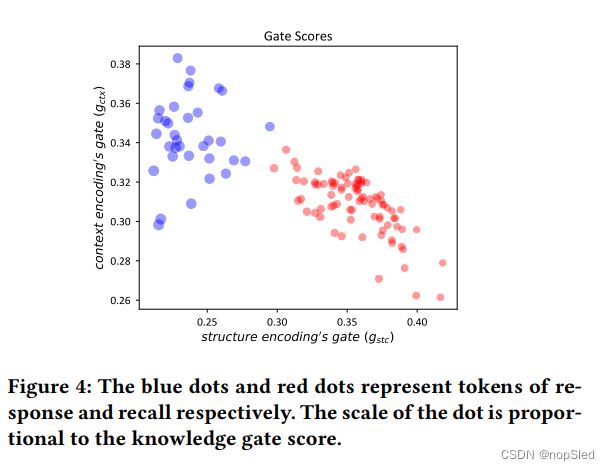
在召回关键信息和生成响应的同时,基于门的融合网络动态控制上下文编码,结构编码和知识编码的流入。从KDGE获得的结构编码为上下文编码提供了互补信息,从而促进REG召回关键信息。如图4所示,通过可视化门控分数可以证明这种行为。
3.4 训练
3.4.1 Recall Supervision Signals
理想的召回序列 R \mathcal R R是当前对话的摘要。但是在大多数情况下,医学对话摘要并没有标注数据。为了解决这个问题,我们引入了PCL-MedBERT,以选择与目标响应最相关的话语,从而作为训练目标。首先,PCL-MedBERT分别将 X i X_i Xi和 Y Y Y分别编码为 h i r h^r_i hir和 h y r h^r_y hyr,我们使用它们之间的余弦相似度来评分 X i X_i Xi:
s i m ( X i , Y ) = h i r ⋅ h y r ∣ ∣ h i r ∣ ∣ ∣ ∣ h y r ∣ ∣ . (11) sim(X_i,Y)=\frac{h^r_i\cdot h^r_y}{||h^r_i||||h^r_y||}.\tag{11} sim(Xi,Y)=∣∣hir∣∣∣∣hyr∣∣hir⋅hyr.(11)
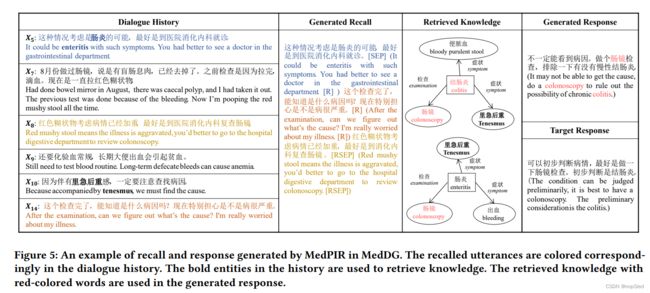
然后,我们选择具有最高相似得分的 k k k个语句,表示为 X r = ( X 1 r . . . X k r ) X^r=(X^r_1...X^r_k) Xr=(X1r...Xkr)。 X r X^r Xr的拼接被用作训练召回生成的目标。尽管这是一种远程监督的方法,但PCL-MedBERT提取的语句通常包含关键信息,能生成信息丰富的响应(有关提取和生成的召回序列的示例,请参见图5)。为了进一步促进该模型在推理时生成合格的 R \mathcal R R,我们还通过二进制交叉熵损失有监督训练召回得分 a v i a_{v_i} avi(等式(2)得到),以识别关键语句:
L r = ∑ i = 1 M − r i l o g a v i − ( 1 − r i ) l o g ( 1 − a v i ) , (12) \mathcal L_r=\sum^M_{i=1}-r_ilog~a_{v_i}-(1-r_i)log(1-a_{v_i}),\tag{12} Lr=i=1∑M−rilog avi−(1−ri)log(1−avi),(12)
其中 ∈ { 0 , 1 } _∈\{0,1\} ri∈{0,1}表示该语句是否在 X r X^r Xr中。 a v i a_{v_i} avi越高,召回的 X i X_i Xi越重要。
3.4.2 Overall Training Objective

