基于TensorFlow的CNN卷积网络模型花卉分类GUI版(2)
一、项目描述
10类花的图片1100张,按{牡丹,月季,百合,菊花,荷花,紫荆花,梅花,…}标注,其中1000张作为训练样本,100张作为测试样本,设计一个CNN卷积神经网络花卉分类器进行花卉的分类,完成模型学习训练后,进行分类测试,并做误差分析,检查模型的泛化性。
文件目录参考上篇
基于TensorFlow的CNN卷积网络模型花卉分类(1)
二、项目界面
- 花卉识别器界面
- 点击“CNN卷积”,读取当前路径下的花卉库
- CNN训练完成,点击图片进行识别;

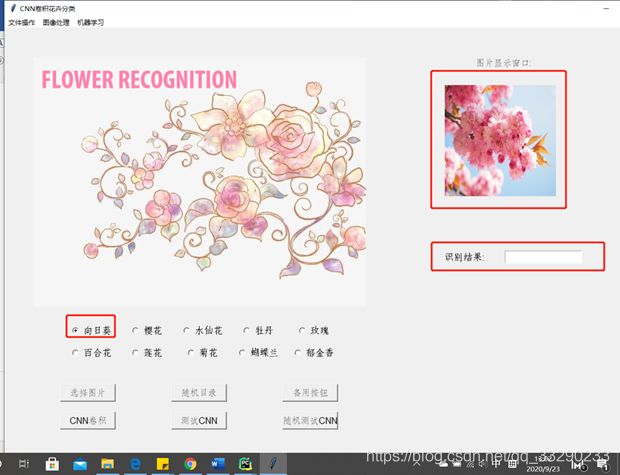

- 点击“测试CNN”按钮进行识别;

- 可选择一个目录,随机从中选一个图片进行识别;
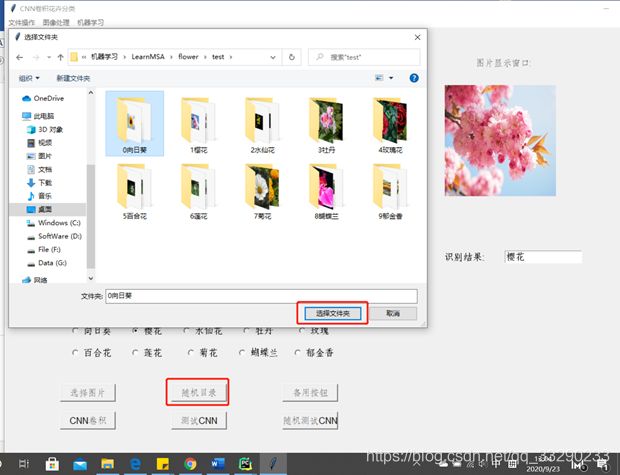
- 点击“随机测试CNN”按钮

- 识别效果的检验与分析


三、核心代码
from skimage import io, transform
from PIL import Image,ImageTk
import tkinter as tk
import cv2
import os
import glob
import tensorflow as tf
import tkinter.filedialog as file
import numpy as np
import time
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
root = tk.Tk()
ww = 600
wh = 500
TargetVector = []
TagFlag = False
TrainFlag = False
FinishFlag = False
ResultStr = tk.StringVar()
# 测试数据路径
DirPath = ""
#图片地址
ImgPath = ""
# 数据集地址
data_path='./flower/train/'
#模型保存地址
model_path='./flower/model/model.ckpt'
model_dir='./flower/model/'
#设置图像处理后的大小
#分别是长*宽*高(RGB彩色图)
w=100
h=100
c=3
data = []
label = []
GI = []
flower_dict = {0:'向日葵',1:'樱花',2:'水仙花',3:'牡丹',4:'玫瑰',5:'百合花',6:'莲花',7:'菊花', 8:'蝴蝶兰', 9:'郁金香'}
#tk界面
root.title("CNN卷积花卉分类")
root.geometry('1200x800') #设定主窗口大小(长 * 宽)
root.resizable(width=True, height=True) #是否可以调整窗口
#创建框架左区放主图,relief边框样式
frma1 = tk.Frame(root, width = ww+50, height = wh+50, relief = tk.GROOVE)
frma1.place(relx=0, rely=0) #框架定位
I1 = cv2.imread("flower/Cover.png") #cv2.imread(filepath,flags)读入一副图片
I2 = cv2.resize(I1, (ww, wh)) #重新设置图像大小
#cv2.imwrite("image/logo.png", I2) #函数cv2.imwrite(file,img,num)保存一个图像
image_file = tk.PhotoImage(file="flower/Cover.png")
L1 = tk.Label(frma1, image=image_file) #在框架1创建一个标签用以显示logo图片并放置
L1.place(x=50, y=50)
#设置一个框架右区放置读入的图片
InputFrame = tk.Frame(root, height=200, width=200, relief=tk.SUNKEN)
InputFrame.pack_propagate(0)
InputFrame.place(x=750, y=100)
LabImg = tk.Label(InputFrame, image=None)
#滚动文本框(宽,高(这里的高应该是以行数为单位),字体样式)
#========函数区开始===========
def picshow():
global ImgPath,LabImg
width = 200
im = Image.open(ImgPath)
print(ImgPath)
print(im)
# (x, y) = im.size
# x_s = width
# y_s = int(y * x_s / x)
img_deal = im.resize((width, width), Image.ANTIALIAS) #等比例放大
img = ImageTk.PhotoImage(img_deal)
LabImg = tk.Label(InputFrame, image=img)
LabImg.grid(row=1, column=0, columnspan=2, padx=40)
root.mainloop()
return
#打开图片
def OpenPic():
global LabImg, ImgPath
#选择打开什么文件,打开文件显示最初的目录,返回文件名
ImgPath = file.askopenfilename(title='打开文件名字', initialdir="J:\pyproject",
filetypes=[('jpg图像', '*.jpg')])
if len(ImgPath) == 0:
return
else:
print(ImgPath)
picshow()
return
#读取数据
def read_img(path):
# os.listdir(path)表示在path路径下的所有文件和和文件夹列表
# 用cate记录十种花的文件路径
cate=[path+x for x in os.listdir(path) if os.path.isdir(path+x)] # 创建层级列表cate,用于对数据存放目录下面的数据文件夹进行遍历,os.path.isdir用于判断文件是否是目录,然后对是目录文件的文件进行遍历
imgs=[] #存放所有的图片 # 创建保存图像的空列表
labels=[] #图片的类别标签 # 创建用于保存图像标签的空列表
for idx,folder in enumerate(cate):
# enumerate函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和下标,一般用在for循环当中
for im in glob.glob(folder+'/*.jpg'): # 利用glob.glob函数搜索每个层级文件下面符合特定格式“/*.jpg”进行遍历
try:
print('reading the images:%s'%(im)) # 遍历图像的同时,打印每张图片的“路径+名称”信息
img=io.imread(im) # 利用io.imread函数读取每一张被遍历的图像并将其赋值给img
try: #对异常图片进行处理
if img.shape[2] == 3:
img = transform.resize(img, (w, h))
imgs.append(img)
labels.append(idx)
except:
continue
except:
print("Cannot open image!")
# 利用np.asarray函数对生成的imgs和labels列表数据进行转化,之后转化成数组数据(imgs转成浮点数型,labels转成整数型)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
#打乱数据
def shuffleData():
global data, label
num_example = data.shape[0] # 表示矩阵的行数
arr = np.arange(num_example) # 生成0到num_example个数
np.random.shuffle(arr) # 随机打乱arr数组
data = data[arr] # 将data以arr索引重新组合
label = label[arr] # 将label以arr索引重新组合
# 将所有数据分为训练集和验证集
ratio = 0.8 # 设置训练集比例
s = np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
x_val = data[s:]
y_val = label[s:]
return x_train,y_train,x_val,y_val
# -----------------构建网络----------------------
#6.建立训练模型
def inference(input_tensor,train,regularizer):
# -----------------------第一层----------------------------
with tf.variable_scope('layer1-conv1'):
# 初始化权重conv1_weights为可保存变量,大小为5x5,3个通道(RGB),数量为32个
conv1_weight=tf.get_variable('weight',[5,5,3,32],initializer=tf.truncated_normal_initializer(stddev=0.1))
# 初始化偏置conv1_biases,数量为32个
conv1_bias=tf.get_variable('bias',[32],initializer=tf.constant_initializer(0.0))
# conv1_weights为权重,strides=[1, 1, 1, 1]表示左右上下滑动步长为1,padding='SAME'表示输入和输出大小一样,即补0
conv1=tf.nn.conv2d(input_tensor,conv1_weight,strides=[1,1,1,1],padding='SAME')
# 激励计算,调用tensorflow的relu函数
relu1=tf.nn.relu(tf.nn.bias_add(conv1,conv1_bias))
with tf.name_scope('layer2-pool1'):
# 池化计算,调用tensorflow的max_pool函数,strides=[1,2,2,1],表示池化边界,2个对一个生成,padding="VALID"表示不操作。
pool1=tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='VALID')
# -----------------------第二层----------------------------
with tf.variable_scope('layer3-conv2'):
conv2_weight=tf.get_variable('weight',[5,5,32,64],initializer=tf.truncated_normal_initializer(stddev=.1))
conv2_bias=tf.get_variable('bias',[64],initializer=tf.constant_initializer(0.0))
conv2=tf.nn.conv2d(pool1,conv2_weight,strides=[1,1,1,1],padding='SAME')
relu2=tf.nn.relu(tf.nn.bias_add(conv2,conv2_bias))
with tf.variable_scope('layer4-pool2'):
pool2=tf.nn.max_pool(relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='VALID')
# -----------------------第三层---------------------------
with tf.variable_scope('layer5-conv3'):
conv3_weight=tf.get_variable('weight',[3,3,64,128],initializer=tf.truncated_normal_initializer(stddev=.1))
conv3_bias=tf.get_variable('bias',[128],initializer=tf.constant_initializer(0.0))
conv3=tf.nn.conv2d(pool2,conv3_weight,strides=[1,1,1,1],padding='SAME')
relu3=tf.nn.relu(tf.nn.bias_add(conv3,conv3_bias))
with tf.variable_scope('layer6-pool3'):
pool3 = tf.nn.max_pool(relu3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# -----------------------第四层----------------------------
with tf.variable_scope('layer7-conv4'):
#定义第二个卷积层,原理和第一层相同
conv4_weight=tf.get_variable('weight',[3,3,128,128],initializer=tf.truncated_normal_initializer(stddev=.1))
conv4_bias=tf.get_variable('bias',[128],initializer=tf.constant_initializer(0.0))
conv4=tf.nn.conv2d(pool3,conv4_weight,strides=[1,1,1,1],padding='SAME')
relu4=tf.nn.relu(tf.nn.bias_add(conv4,conv4_bias))
with tf.variable_scope('layer8-pool4'):
pool4 = tf.nn.max_pool(relu4, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
#第八层输出的是矩阵:【6,6,128】,把矩阵变成向量,每张图片排列成6*6*128 的向量
nodes=6*6*128
reshape=tf.reshape(pool4,[-1,nodes])
print('shape of reshape is :',reshape.shape)
# 使用变形函数转化结构
# -----------------------第五层---------------------------
with tf.variable_scope('layer9-FC1'):
fc1_weight=tf.get_variable('weight',[nodes,1024],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer!=None:tf.add_to_collection('losses',regularizer(fc1_weight))
#
fc1_biases=tf.get_variable('bias',[1024],initializer=tf.constant_initializer(0.1))
fc1=tf.nn.relu(tf.matmul(reshape,fc1_weight)+fc1_biases)
if train:fc1=tf.nn.dropout(fc1,0.5)
# -----------------------第六层----------------------------
with tf.variable_scope('layer10-FC2'):
fc2_weight = tf.get_variable('weight', [1024, 512], initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weight))
fc2_biases = tf.get_variable('bias', [512], initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weight) + fc2_biases)
if train: fc2 = tf.nn.dropout(fc2, 0.5)
# -----------------------第七层----------------------------
with tf.variable_scope('layer11-FC3'):
fc3_weight = tf.get_variable('weight', [512, 10], initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc3_weight))
# fc3_biases = tf.get_variable('bias', [5], initializer=tf.constant_initializer(0.1))
fc3_biases = tf.get_variable('bias', [10], initializer=tf.constant_initializer(0.1))
logits = tf.matmul(fc2, fc3_weight) + fc3_biases
# 返回最后的计算结果
return logits
# ---------------------------网络结束---------------------------
def GetLoss(x,y_):
#设置正则化参数为0.0001
regularizer=tf.contrib.layers.l2_regularizer(0.001)
#将上述构建网络结构引入
logits=inference(x,False,regularizer)
print('shape of logits:',logits.shape)
# (小处理)将logits乘以1赋值给logits_eval,定义name,方便在后续调用模型时通过tensor名字调用输出tensor
b=tf.constant(value=1,dtype=tf.float32)
logits_eval=tf.multiply(logits,b,name='logits_eval') #常数和矩阵想成
#设置损失函数,作为模型训练优化的参考标准,loss越小,模型越优
loss=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,labels=y_)
#设置整体学习率为α为0.001
optimizer=tf.train.AdamOptimizer(learning_rate=0.001)
#设置预测精度
train_op=optimizer.minimize(loss)
correct_prediction=tf.equal(tf.cast(tf.argmax(logits,1),tf.int32),y_)
#这边返回的是布尔值 true
acc=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#计算准确率
return loss, acc, train_op
#7训练和测试
#定义一个函数,按照批次取数据
def minibatches(inputs=None,targets=None,batch_size=None,shuffle=False):
assert len(inputs)==len(targets)
if shuffle:
indices=np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0,len(inputs)-batch_size+1,batch_size):
if shuffle:
excerpt=indices[start_idx:start_idx+batch_size]
else:
excerpt=slice(start_idx,start_idx+batch_size)
yield inputs[excerpt],targets[excerpt]
#保存模型
def SaveModel(x_train, y_train, x_val, y_val, train_op, loss, acc, x, y_):
n_epoch = 10
batch_size = 64
saver = tf.train.Saver()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(n_epoch):
print('epoch:', epoch + 1)
start_time = time.time()
# training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True):
_, err, ac = sess.run([train_op, loss, acc], feed_dict={x: x_train_a, y_: y_train_a})
train_loss += err
train_acc += ac
n_batch += 1
print('train loss:%f' % (np.sum(train_loss) / n_batch))
# 评估
val_loss, val_acc, n_batch = 0, 0, 0
for x_vale_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):
err, ac = sess.run([loss, acc], feed_dict={x: x_vale_a, y_: y_val_a})
val_loss += err
val_acc += ac
n_batch += 1
print('validation loss : %f' % (np.sum(val_loss) / n_batch))
print('validation acc: %f' % (np.sum(val_acc) / n_batch))
print('epoch time:%f' % (time.time() - start_time))
print('-------------------------------------------')
# 8.保存模型
saver.save(sess, model_path) # 把运算后的模型保存
sess.close()
#开始训练cnn
def BeginTrain():
global data, label, data_path
data, label = read_img(data_path)
print('shape of data=', data.shape) # 查看样本数组大小
print('shape od labels=', label.shape) # 查看标签数组大小
x_train,y_train,x_val,y_val = shuffleData() #打乱顺序
# 占位符设置输入参数的大小和格式
# 插入一个张量的占位符,这个张量总是被喂入图片数据。相当于一个形参。
x = tf.placeholder(tf.float32, shape=[None, w, h, c, ], name='x') # 用于传递样本数据
y_ = tf.placeholder(tf.int32, shape=[None, ], name='Y_') # 用于传递标签
print('x:', x.shape)
print('y:', y_.shape)
loss,acc,train_op = GetLoss(x,y_)
SaveModel(x_train,y_train, x_val, y_val, train_op, loss, acc, x, y_)
#选择测试的路径
def SelectDir():
global DirPath
# 输入参数:path,测试图片的路径
# 返回参数:image,从测试图片中随机抽取一张图片
DirPath = file.askdirectory()
print(DirPath)
#从指定的路径随机选择一张图片进行识别
def random_get_image():
global ImgPath, DirPath
allPic = []
for pic in os.listdir(DirPath):
if pic.endswith("jpg") or pic.endswith("png"):
allPic.append(pic)
print(pic)
n = len(allPic)
ind = np.random.randint(0, n)
img_dir = allPic[ind] # 随机选择测试的图片
ImgPath = DirPath + '/' + img_dir
img = io.imread(ImgPath)
img = transform.resize(img, (w, h))
return np.array(img)
#获取一张图片
def read_one_image():
global ImgPath
img = io.imread(ImgPath)
img = transform.resize(img,(w,h))
return np.asarray(img)
#测试识别花朵
def TestCnn():
global flower_dict, ResultStr
with tf.Session() as sess:
data = []
img = read_one_image()
data.append(img)
saver = tf.train.import_meta_graph(model_dir + 'model.ckpt.meta')
saver.restore(sess, tf.train.latest_checkpoint(model_dir))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x: data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess.run(logits, feed_dict)
# 打印出预测矩阵
# print(classification_result)
# 打印出预测矩阵每一行最大值的索引
# print(tf.argmax(classification_result,1).eval())
# 根据索引通过字典对应花的分类
output = []
output = tf.argmax(classification_result, 1).eval()
for i in range(len(output)):
print("第", i + 1, "朵花预测:" + flower_dict[output[i]])
ResultStr.set(flower_dict[output[i]])
SetTargt()
def DirTestCnn():
global flower_dict, ResultStr
with tf.Session() as sess:
data = []
img = random_get_image()
data.append(img)
saver = tf.train.import_meta_graph(model_dir + 'model.ckpt.meta')
saver.restore(sess, tf.train.latest_checkpoint(model_dir))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x: data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess.run(logits, feed_dict)
# 打印出预测矩阵
# print(classification_result)
# 打印出预测矩阵每一行最大值的索引
# print(tf.argmax(classification_result,1).eval())
# 根据索引通过字典对应花的分类
output = []
output = tf.argmax(classification_result, 1).eval()
for i in range(len(output)):
print("第", i + 1, "朵花预测:" + flower_dict[output[i]])
ResultStr.set(flower_dict[output[i]])
SetTargt()
picshow()
#回调函数
def CallBack():
return
#创建一个菜单栏,相当于容器,在窗口的上方
menubar = tk.Menu(root)
#文件子菜单,点击这些单元, 就会触发CallBack的功能
fmenu = tk.Menu(menubar)
fmenu.add_command(label="新建", command=CallBack)
fmenu.add_command(label="打开", command=CallBack)
fmenu.add_command(label="保存", command=CallBack)
fmenu.add_command(label="另存为", command=CallBack)
#图像处理子菜单
imenu = tk.Menu(menubar)
imenu.add_command(label="FFT变换", command=CallBack)
imenu.add_command(label="DOT变换", command=CallBack)
imenu.add_command(label="边缘检测", command=CallBack)
imenu.add_command(label="区域分割", command=CallBack)
#机器学习子菜单
mmenu = tk.Menu(menubar)
mmenu.add_command(label="KNN", command=CallBack)
mmenu.add_command(label="朴素贝叶斯", command=CallBack)
mmenu.add_command(label="支持向量机", command=CallBack)
mmenu.add_command(label="BP神经网", command=CallBack)
mmenu.add_command(label="CNN卷积神经网", command=CallBack)
#子菜单
#将上面定义的空菜单命名,放在菜单栏中,就是装入那个容器中
menubar.add_cascade(label="文件操作", menu=fmenu)
menubar.add_cascade(label="图像处理", menu=imenu)
menubar.add_cascade(label="机器学习", menu=mmenu)
root.config(menu = menubar) #创建菜单栏完成后,配置让菜单栏menubar显示出来
but1 = tk.Button(
root, text="选择图片", font=('Arial', 12), width=10, height=1, command=OpenPic)
but2 = tk.Button(
root, text="随机目录", font=('Arial', 12), width=10, height=1, command=SelectDir)
but3 = tk.Button(
root, text="备用按钮", font=('Arial', 12), width=10, height=1, command=SaveModel)
but4 = tk.Button(
root, text="CNN卷积", font=('Arial', 12), width=10, height=1, command=BeginTrain)
but5 = tk.Button(
root, text="测试CNN", font=('Arial', 12), width=10, height=1, command=TestCnn)
but6 = tk.Button(
root, text="随机测试CNN", font=('Arial', 12), width=10, height=1, command=DirTestCnn)
dd = 40
but1.place(x=100, y=600 + dd)
but2.place(x=300, y=600 + dd)
but3.place(x=500, y=600 + dd)
but4.place(x=100, y=650 + dd)
but5.place(x=300, y=650 + dd)
but6.place(x=500, y=650 + dd)
#在图形界面上设定输入框控件entry并放置控件
entry1 = tk.Entry(root, font=('Arial', 13), width=15, textvariable=ResultStr)
entry1.place(x=900, y=400)
ResultStr.set('')
#设定标签
Lab1 = tk.Label(root, text="识别结果:", font=('Arial', 13), width=10, height=1)
Lab1.place(x=780, y=400)
Lab5 = tk.Label(root, text="图片显示窗口:", font=('Arial', 12), width=10, height=1)
Lab5.place(x=850, y=50)
# 设置目标标签无线按钮
Target = [('向日葵', 0), ('樱花', 1), ('水仙花', 2), ('牡丹', 3), ('玫瑰', 4),
('百合花', 5), ('莲花', 6), ('菊花', 7), ('蝴蝶兰', 8), ('郁金香', 9)]
Target_startx = 20
Target_starty1 = 530
Target_starty2 = 570
TargetVector = np.zeros(10)
TargetV = tk.IntVar() #tk.Intvar()用于记录数值
#根据结果设置按钮
def SetTargt():
global ResultStr,Target
for txt,num in Target:
if(ResultStr.get() == txt): #get()获取值选中的值
TargetV.set(num)
print(num,txt)
#遍历Target数组
for txt, num in Target:
# 生成设置单选按钮
# variable=TargetV,当我们鼠标选中了其中一个选项,把value的值放到变量TargetV中,然后赋值给variable
rbut = tk.Radiobutton(
root, text=txt, value=num, font=('Arial', 13),
width=5, height=1, command=SetTargt(), variable=TargetV)
if(num<=4):
rbut.place(x=Target_startx + (num+1) * 100, y=Target_starty1)
else:
rbut.place(x=Target_startx + (num-4) * 100, y=Target_starty2)
#主窗口循环显示
root.mainloop()
训练集已上传
https://download.csdn.net/download/qq_33290233/16316711?spm=1001.2014.3001.5503