综述 | 图像特征提取与匹配技术
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
作者:william
链接:https://zhuanlan.zhihu.com/p/133301967
文仅分享,侵删

特征提取和匹配是许多计算机视觉应用中的一个重要任务,广泛运用在运动结构、图像检索、目标检测等领域。每个计算机视觉初学者最先了解的特征检测器几乎都是1988年发布的HARRIS。在之后的几十年时间内各种各样的特征检测器/描述符如雨后春笋般出现,特征检测的精度与速度都得到了提高。
特征提取和匹配由关键点检测,关键点特征描述和关键点匹配三个步骤组成。不同的检测器,描述符以及匹配器之间的组合往往是初学者疑惑的内容。本文将主要介绍关键点检测、描述以及匹配的背后原理,不同的组合方式之间的优劣,并提出几组根据实践结果得出的最佳组合。

特征提取和匹配

Background Knowledge
特征(Feature)
特征是与解决某个应用程序相关的计算任务有关的一条信息。特征可能是图像中的特定结构,例如点,边缘或对象。特征也可能是应用于图像的一般邻域操作或特征检测的结果。这些功能可以分为两大类:
1、图片中特定位置的特征,如山峰、建筑角落、门口或有趣形状的雪块。这种局部化的特征通常被称为关键点特征(或者甚至是角点) ,它们通常以点位置周围出现的像素块来描述,这个像素块往往被称作图像补丁(Image patch)。
2、可以根据其方向和局部外观(边缘轮廓)进行匹配的特征称为边缘,它们也可以很好地指示图像序列中的对象边界和遮挡事件。
特征点
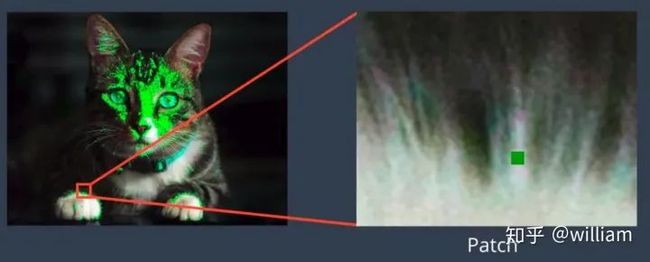
边缘

特征提取和匹配的主要组成部分
1、检测(detection):识别感兴趣点
2、描述(description): 描述每个特征点周围的局部外观,这种描述在光照、平移、尺度和平面内旋转的变化下是(理想的)不变的。我们通常会为每个特征点提供一个描述符向量。
3、匹配(mataching): 通过比较图像中的描述符来识别相似的特征。对于两幅图像,我们可以得到一组对(Xi,Yi)->(Xi’ ,Yi’) ,其中(Xi,Yi)是一幅图像的特征,(Xi’ ,Yi’)是另一幅图像的特征.

Detector
关键点/兴趣点(Key point/ Interest point)
关键点也称兴趣点,是纹理中表达的点。关键点往往是物体边界方向突然改变的点或两个或多个边缘段之间的交点。它在图像空间中具有明确的位置或很好地定位。即使图像域的局部或全局存在如光照和亮度变化等的扰动,关键点仍然是稳定,可以被重复可靠地计算出。除此之外它应该提供有效的检测。
关键点的计算方法有两种:
1、基于图像的亮度(通常通过图像导数)。
2、基于边界提取(通常通过边缘检测和曲率分析)。
关键点检测器光度和几何变化的不变性
在OPENCV库,我们可以选择很多特征检测器,特征检测器的选择取决于将要检测的关键点的类型以及图像的属性,需要考虑相应检测器在光度和几何变换方面的鲁棒性。
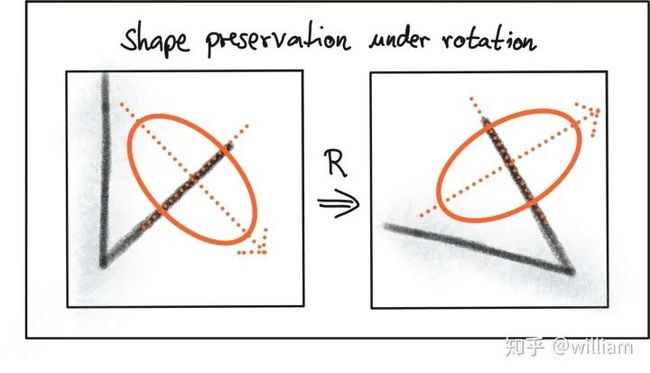
选择合适的关键点检测器时,我们需要考虑四种基本转换类型:
1、旋转变换
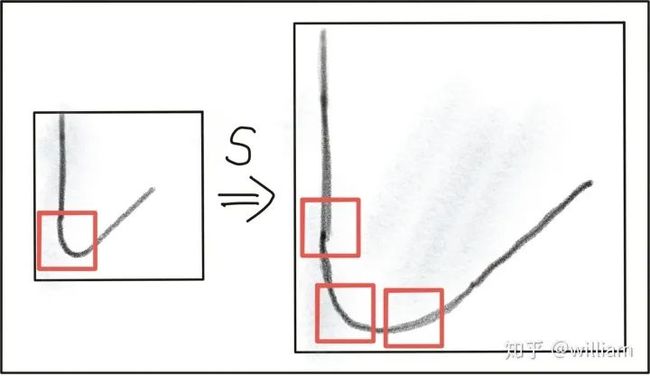
2、 尺度变换
3、 强度变换
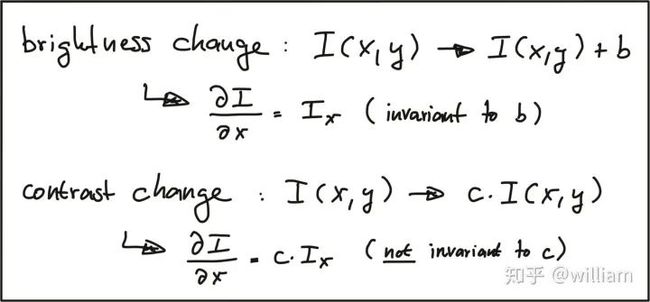
4、仿射变换
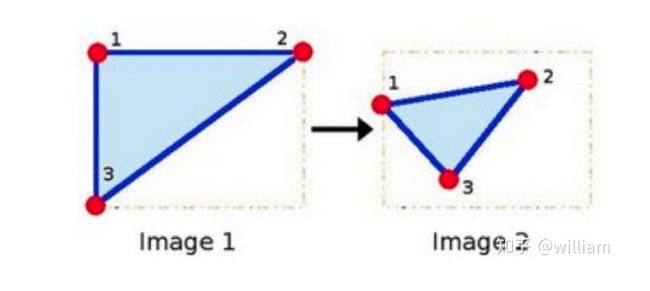
涂鸦序列是计算机视觉中使用的标准图像集之一,我们可以观察到第i+n帧的涂鸦图片包括了所有的变换类型。而对于高速公路序列,当专注于前面的车辆时,在第i帧和第i + n帧之间只有比例变化以及强度变化。

传统的HARRIS传感器在旋转和加性强度偏移情况下具有较强的鲁棒性,但对尺度变化、乘性强度偏移(即对比度变化)和仿射变换敏感。
自动尺度选择
为了在理想尺度上检测关键点,我们必须知道(或找到)它们在图像中的各自维度,并适应本节前面介绍的高斯窗口 w (x,y) 的大小。如果关键点尺度是未知的或如果关键点与存在于不同的大小图像中,检测必须在多个尺度级连续执行。
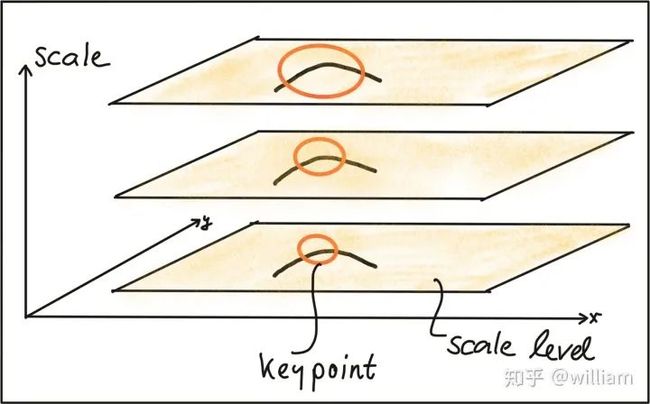
基于相邻层之间的标准差增量,同一个关键点可能被多次检测到。这就提出了选择最能代表关键点的“正确”尺度的问题。1998年Tony Lindeberg 发表了一种“自动选择比例的特征提取(Feature detection with automatic scale selection)”的方法。它提出了一个函数 f (x,y,scale) ,该函数可以用来选择在尺度上 FF 有稳定最大值的关键点。Ff 最大化的尺度被称为各关键点的“特征尺度”。
如在下图中显示了这样一个函数 FF,它经过了几个尺度级别的评估,在第二张图中显示了一个清晰的最大值,可以看作是圆形区域内图像内容的特征尺度。
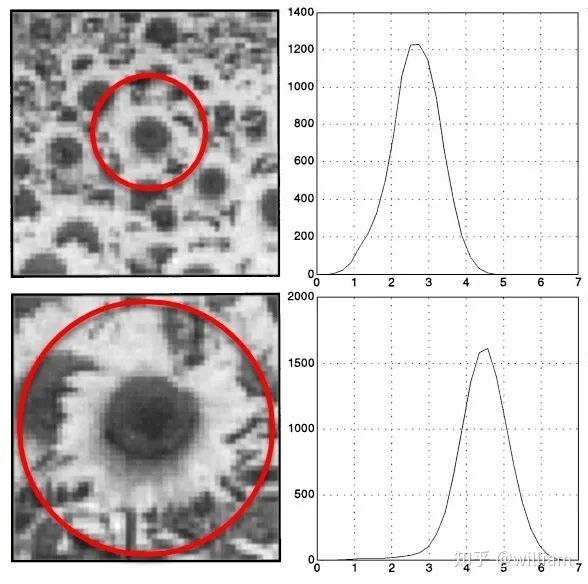
一个好的检测器能够根据局部邻域的结构特性自动选择关键点的特征尺度。现代关键点探测器通常具有这种能力,因此对图像尺度的变化具有很强的鲁棒性。
常见关键点检测器
关键点检测器是一个非常受欢迎的研究领域,因此这些年来已经开发了许多强大的算法。关键点检测的应用包括物体识别和跟踪,图像匹配和全景拼接以及机器人制图和3D建模等。检测器的选择除了需要比较上述转换中的不变性之外,还需要比较检测器的检测性能和处理速度。
经典关键点检测器
经典关键点检测器的目的是为了最大化检测精度,复杂度一般不是首要考虑因素。
HARRIS- 1988 Harris Corner Detector (Harris, Stephens)
Shi, Tomasi- 1996 Good Features to Track (Shi, Tomasi)
SIFT- 1999 Scale Invariant Feature Transform (Lowe) -None free
SURT- 2006 Speeded Up Robust Features (Bay, Tuytelaars, Van Gool) -None free
现代关键点检测器
近年来,一些更快的探测器已经开发出来,用于智能手机和其他便携设备上的实时应用。下面的列表显示了属于这个组的最流行的检测器:
FAST- 2006 Features from Accelerated Segment Test (FAST) (Rosten, Drummond)
BRIEF- 2010 Binary Robust Independent Elementary Features (BRIEF) (Calonder, et al.)
ORB- 2011 Oriented FAST and Rotated BRIEF (ORB) (Rublee et al.)
BRISK- 2011 Binary Robust Invariant Scalable Keypoints (BRISK) (Leutenegger, Chli, Siegwart)
FREAK- 2012 Fast Retina Keypoint (FREAK) (Alahi, Ortiz, Vandergheynst)
KAZE- 2012 KAZE (Alcantarilla, Bartoli, Davidson)

Feature Descriptor
基于梯度与二进制的描述符
由于我们的任务是在图像序列中找到对应的关键点,因此我们需要一种基于相似性度量将关键点彼此可靠地分配的方法。很多文献中已经提出了各种各样的相似性度量(称为Descriptor),并且在很多作者已经同时发布了一种用于关键点检测的新方法以及针对其关键点类型进行了优化的相似性度量。也就是说已经封装好的OPENCV关键点检测器函数大部分同样可以用来生成关键点描述符。
区别在于:
关键点检测器是一种根据函数的局部最大值从图像中选择点的算法,例如我们在HARRIS检测器中看到的“角度”度量。
关键点描述符是用于描述关键点周围的图像补丁值的向量。描述方法有比较原始像素值的方法也有更复杂的方法,如梯度方向的直方图。
关键点检测器一般是从一个帧图片中寻找到特征点。而描述符帮助我们在“关键点匹配”步骤中将不同图像中的相似关键点彼此分配。如下图所示,一个帧中的一组关键点被分配给另一帧中的关键点,以使它们各自描述符的相似性最大化,并且这些关键点代表图像中的同一对象。除了最大化相似性之外,好的描述符还应该能够最大程度地减少不匹配的次数,即避免将彼此不对应于同一对象的关键点分配给彼此。
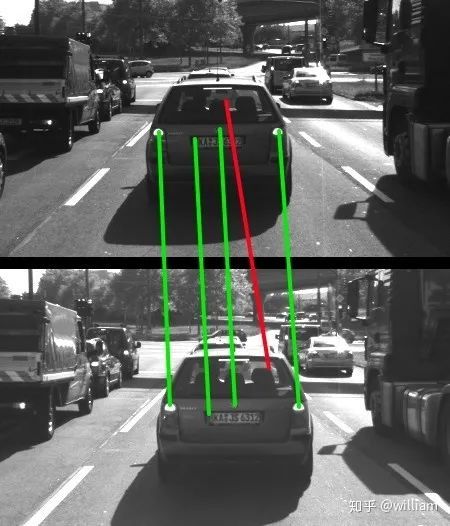
基于梯度HOG描述符
虽然出现了越来越多快速的检测器/描述符组合,但是基于定向直方图(HOG)描述符之一的尺度不变特征转换(SIFT)依然被广泛运用。HOG的基本思想是通过物体在局部邻域中的强度梯度分布来描述物体的结构。为此,将图像划分为多个单元,在这些单元中计算梯度并将其收集到直方图中。然后,将所有单元格的直方图集用作相似性度量,以唯一地标识图像块或对象。
SIFT/SURF使用HOG作为描述符,既包括关键点检测器,也包括描述符,功能很强大,但是被专利保护。SURF是在SIFT的基础上改进,不仅提高了计算速度,而且更加安全鲁棒性,两者的实现原理很相似。在此我先仅介绍SIFT。
SIFT方法遵循五步过程,下面将对此进行简要概述。
首先,使用称为“拉普拉斯高斯(LoG)”的方法来检测图像中的关键点,该方法基于二阶强度导数。LoG应用于图像的各种比例级别,并且倾向于检测斑点而不是拐角。除了使用唯一的比例级别外,还根据关键点周围局部邻域中的强度梯度为关键点分配方向。
其次,对于每个关键点,其周围区域都会通过消除方向而改变,从而确保规范的方向。此外,该区域的大小将调整为16 x 16像素,从而提供了标准化的图像补丁。

第三,基于强度梯度_Ix_和_Iy_计算归一化图像补丁内每个像素的方向和大小。
第四,将归一化的贴片划分为4 x 4单元的网格。在每个单元内,超出幅度阈值的像素的方向收集在由8个bin组成的直方图中。
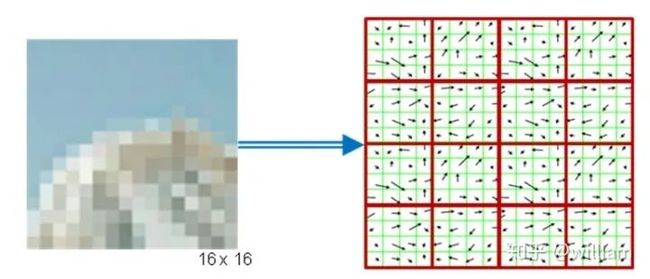
最后,将所有16个单元格的8柱状直方图连接到一个128维向量(描述符)中,该向量用于唯一表示关键点。
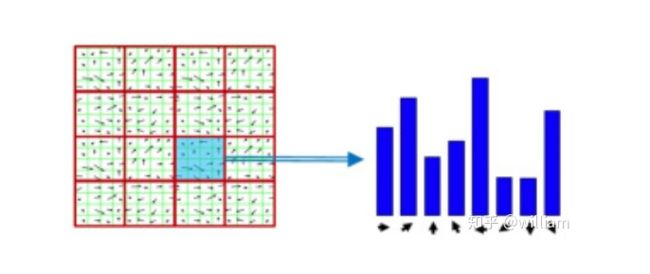
SIFT检测器/描述符即使在杂波中和部分遮挡下也能够可靠地识别物体。尺度,旋转,亮度和对比度的均匀变化是不变的,仿射失真甚至是不变的。
SIFT的缺点是速度低,这使其无法在智能手机等实时应用中使用。HOG系列的其他成员(例如SURF和GLOH)已针对速度进行了优化。但是,它们仍然在计算上过于昂贵,因此不应在实时应用中使用。此外,SIFT和SURF拥有大量专利,因此不能在商业环境中自由使用。为了在OpenCV中使用SIFT,必须使用#include
二进制Binary描述符
基于HOG的描述符的问题在于它们基于计算强度梯度,这是非常昂贵的操作。即使已进行了一些改进(例如SURF),使用了积分图像,速度提高了,但这些方法仍然不适合处理能力有限的设备(例如智能手机)上的实时应用程序。二进制描述符家族是基于HOG的方法的一种更快(免费)的替代方案,但准确性和性能稍差。
二进制描述符的核心思想是仅仅依赖强度信息(即图像本身) ,并将关键点周围的信息编码为一串二进制数字,当搜索相应关键点时,这些数字可以在匹配步骤中非常有效地进行比较。也就是说二进制描述符将兴趣点的信息编码成一系列数字,并作为一种数字“指纹” ,可用于区分一个特征和另一个特征。目前,最流行的二进制描述符是 BRIEF、 BRISK、 ORB、 FREAK 和 KAZE (所有这些都可以在 OpenCV 库中找到)。

二进制描述符
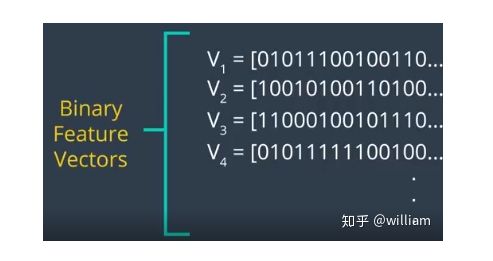
从高层次的角度来看,二进制描述符由三个主要部分组成:
1、一种描述样本点位于关键点附近的位置的采样模式( sampling pattern )。
2、一种消除了图像补丁围绕关键点位置旋转影响的方向补偿方法( orientation compensation)。
3、一种样本对选择的方法(ample-pair selection),它产生成对的样本点,这些样本点根据它们的强度值相互比较。如果第一个值大于第二个值,我们就在二进制字符串中写一个“1” ,否则就写一个“0”。在对采样模式中的所有点对执行此操作之后,将创建一个长的二进制链(或“ string”)(因此得到描述符类的族名)。
BRISK“二进制鲁棒不变可伸缩关键点”关键点检测器 / 描述符是二进制描述符的代表。在此我先仅介绍BRISIK。
2011年Stefan Leutenegger 提出的BRISK 是一个基于 FAST 的检测器和一个Binary描述符的组合,这个描述符由通过对每个关键点邻域进行专门采样而获得的强度比较创建。
BRISK的采样模式由多个采样点(蓝色)组成,其中每个采样点周围的同心环(红色)表示应用高斯平滑的区域。与某些其他二进制描述符(例如ORB或Brief)相反,BRISK采样模式是固定的。平滑对于避免混叠非常重要(这种效应会导致不同信号在采样时变得难以区分-或彼此混叠)。
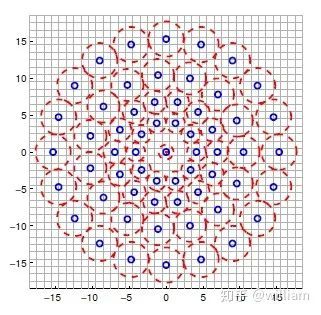
在样本对选择期间,BRISK算法会区分长距离对和短距离对。长距离对(即在样本图案上彼此之间具有最小距离的样本点)用于根据强度梯度估算图像补丁的方向,而短距离对用于对已组装的描述符字符串进行强度比较。在数学上,这些对表示如下:
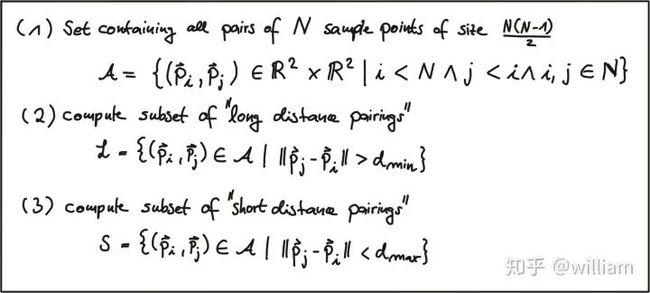
首先,我们定义所有可能的采样点对的集合A。然后,我们从A提取子集L,子集L的欧氏距离大于上阈值。L是用于方向估计的长距离对。最后,我们从A提取欧氏距离低于下阈值的那些对。该集合S包含用于组装二进制描述符串的短距离对。
下图显示了短对(左)和长对(右)的采样模式上的两种距离对。
从长对中,关键点方向向量G 计算如下:

首先,根据归一化的单位矢量计算两个采样点之间的梯度强度,归一化的单位矢量给出两个点之间的方向,乘以两个点在各自比例下的强度差。然后在(2)中,关键点方向向量 g 从所有梯度强度的总和中计算出。
基于 g ,我们可以使用采样模式的方向重新排列短距离配对,从而确保旋转不变性。基于旋转不变的短距离配对,可以如下构建最终的二进制描述符:

从 g 计算出关键点的方位后,我们使用它使短距离配对旋转不变。然后,所有对之间的强度 S 被比较并用于组装可用于匹配的二进制描述符。


OPENCV Detector/Descriptor implementation
目前存在各种各样的特征点检测器/描述符,如 HARRIS, SHI-TOMASI, FAST, BRISK, ORB, AKAZE, SIFT, FREAK, BRIEF。每一种都值得单独用一篇博客去描述,但是本文的目的是为了给大家一份综述,因此不详细的从原理上分析这些检测器/描述符。网上有大量描述这些检测器/描述符的文章,但是我还是建议大家先看OPENCV库的Tutorial: How to Detect and Track Object With OpenCV.
以下我会介绍各个特征点检测器/描述符的代码实现以及参数详解, 文章结尾会基于实际结果对这些组合进行评价。
有些OPENCV函数可以同时用于检测器/描述符,但是有的组合会出现问题。
SIFT Detector/Descriptor SIFT detector and ORB descriptor do not work together
int nfeatures = 0;// The number of best features to retain.
int nOctaveLayers = 3;
// The number of layers in each octave. 3 is the value used in D. Lowe paper.
double contrastThreshold = 0.04;
// The contrast threshold used to filter out weak features in semi-uniform (low-contrast) regions.
double edgeThreshold = 10;// The threshold used to filter out edge-like features.
double sigma = 1.6;
// The sigma of the Gaussian applied to the input image at the octave \#0.
xxx=cv::xfeatures2d::SIFT::create(nfeatures, nOctaveLayers, contrastThreshold, edgeThreshold, sigma);HARRIS Detector
// Detector parametersint blockSize = 2; // for every pixel, a blockSize × blockSize neighborhood is consideredint apertureSize = 3; // aperture parameter for Sobel operator (must be odd)int minResponse = 100; // minimum value for a corner in the 8bit scaled response matrixdouble k = 0.04; // Harris parameter (see equation for details)// Detect Harris corners and normalize outputcv::Mat dst, dst_norm, dst_norm_scaled;dst = cv::Mat::zeros(img.size(), CV_32FC1);cv::cornerHarris(img, dst, blockSize, apertureSize, k, cv::BORDER_DEFAULT);cv::normalize(dst, dst_norm, 0, 255, cv::NORM_MINMAX, CV_32FC1, cv::Mat());cv::convertScaleAbs(dst_norm, dst_norm_scaled);// Look for prominent corners and instantiate keypointsdouble maxOverlap = 0.0; // max. permissible overlap between two features in %, used during non-maxima suppressionfor (size_t j = 0; j < dst_norm.rows; j++) { for (size_t i = 0; i < dst_norm.cols; i++) { int response = (int) dst_norm.at(j, i); if (response > minResponse) { // only store points above a threshold cv::KeyPoint newKeyPoint; newKeyPoint.pt = cv::Point2f(i, j); newKeyPoint.size = 2 * apertureSize; newKeyPoint.response = response; // perform non-maximum suppression (NMS) in local neighbourhood around new key point bool bOverlap = false; for (auto it = keypoints.begin(); it != keypoints.end(); ++it) { double kptOverlap = cv::KeyPoint::overlap(newKeyPoint, *it); if (kptOverlap > maxOverlap) { bOverlap = true; if (newKeyPoint.response > (*it).response) { // if overlap is >t AND response is higher for new kpt *it = newKeyPoint; // replace old key point with new one break; // quit loop over keypoints } } } if (!bOverlap) { // only add new key point if no overlap has been found in previous NMS keypoints.push_back(newKeyPoint); // store new keypoint in dynamic list } } } // eof loop over cols} // eof loop over rows SHI-TOMASI Detector
int blockSize = 6;
// size of an average block for computing a derivative covariation matrix over each pixel neighborhood
double maxOverlap = 0.0; // max. permissible overlap between two features in %
double minDistance = (1.0 - maxOverlap) * blockSize;
int maxCorners = img.rows * img.cols / max(1.0, minDistance); // max. num. of keypoints
double qualityLevel = 0.01; // minimal accepted quality of image corners
double k = 0.04;
bool useHarris = false;
// Apply corner detection
vector corners;
cv::goodFeaturesToTrack(img, corners, maxCorners, qualityLevel, minDistance, cv::Mat(), blockSize, useHarris, k);
// add corners to result vector
for (auto it = corners.begin(); it != corners.end(); ++it) {
cv::KeyPoint newKeyPoint;
newKeyPoint.pt = cv::Point2f((*it).x, (*it).y);
newKeyPoint.size = blockSize;
keypoints.push_back(newKeyPoint);
} BRISIK Detector/Descriptor
int threshold = 30; // FAST/AGAST detection threshold score.
int octaves = 3; // detection octaves (use 0 to do single scale)
float patternScale = 1.0f; // apply this scale to the pattern used for sampling the neighbourhood of a keypoint.
xxx=cv::BRISK::create(threshold, octaves, patternScale);FREAK Detector/Descriptor
bool orientationNormalized = true;// Enable orientation normalization.
bool scaleNormalized = true;// Enable scale normalization.
float patternScale = 22.0f;// Scaling of the description pattern.
int nOctaves = 4;// Number of octaves covered by the detected keypoints.
const std::vector &selectedPairs = std::vector();
// (Optional) user defined selected pairs indexes,
xxx=cv::xfeatures2d::FREAK::create(orientationNormalized, scaleNormalized, patternScale, nOctaves,selectedPairs); FAST Detector/Descriptor
int threshold = 30;// Difference between intensity of the central pixel and pixels of a circle around this pixel
bool nonmaxSuppression = true;// perform non-maxima suppression on keypoints
cv::FastFeatureDetector::DetectorType type = cv::FastFeatureDetector::TYPE_9_16;
// TYPE_9_16, TYPE_7_12, TYPE_5_8
xxx=cv::FastFeatureDetector::create(threshold, nonmaxSuppression, type);ORB Detector/Descriptor SIFT detector and ORB descriptor do not work together
int nfeatures = 500;// The maximum number of features to retain.
float scaleFactor = 1.2f;// Pyramid decimation ratio, greater than 1.
int nlevels = 8;// The number of pyramid levels.
int edgeThreshold = 31;// This is size of the border where the features are not detected.
int firstLevel = 0;// The level of pyramid to put source image to.
int WTA_K = 2;
// The number of points that produce each element of the oriented BRIEF descriptor.
auto scoreType = cv::ORB::HARRIS_SCORE;
// The default HARRIS_SCORE means that Harris algorithm is used to rank features.
int patchSize = 31;// Size of the patch used by the oriented BRIEF descriptor.
int fastThreshold = 20;// The fast threshold.
xxx=cv::ORB::create(nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K, scoreType,patchSize, fastThreshold);AKAZE Detector/Descriptor KAZE/AKAZE descriptors will only work with KAZE/AKAZE detectors.
auto descriptor_type = cv::AKAZE::DESCRIPTOR_MLDB;
// Type of the extracted descriptor: DESCRIPTOR_KAZE, DESCRIPTOR_KAZE_UPRIGHT, DESCRIPTOR_MLDB or DESCRIPTOR_MLDB_UPRIGHT.
int descriptor_size = 0;// Size of the descriptor in bits. 0 -> Full size
int descriptor_channels = 3;// Number of channels in the descriptor (1, 2, 3)
float threshold = 0.001f;// Detector response threshold to accept point
int nOctaves = 4;// Maximum octave evolution of the image
int nOctaveLayers = 4;// Default number of sublevels per scale level
auto diffusivity = cv::KAZE::DIFF_PM_G2;
// Diffusivity type. DIFF_PM_G1, DIFF_PM_G2, DIFF_WEICKERT or DIFF_CHARBONNIER
xxx=cv::AKAZE::create(descriptor_type, descriptor_size, descriptor_channels, threshold, nOctaves,nOctaveLayers, diffusivity);BRIEF Detector/Descriptor
int bytes = 32;
// Legth of the descriptor in bytes, valid values are: 16, 32 (default) or 64 .
bool use_orientation = false;
// Sample patterns using keypoints orientation, disabled by default.
xxx=cv::xfeatures2d::BriefDescriptorExtractor::create(bytes, use_orientation);
Descriptor Matching
特征匹配或一般意义上的图像匹配是图像配准、摄像机标定和目标识别等计算机视觉应用的一部分,是在同一场景 / 目标的两幅图像之间建立对应关系的任务。一种常用的图像匹配方法是从图像数据中检测出一组与图像描述符相关联的兴趣点。一旦从两个或更多的图像中提取出特征和描述符,下一步就是在这些图像之间建立一些初步的特征匹配。

一般来说,特征匹配方法的性能取决于基本关键点的性质和相关图像描述符的选择。
我们已经了解到关键点可以通过将其局部邻域转换为高维向量来描述,高维向量可以捕获梯度或强度分布的独特特征。
描述符之间的距离
特征匹配需要计算两个描述符之间的距离,这样它们之间的差异被转换成一个单一的数字,我们可以用它作为一个简单的相似性度量。
目前有三种距离度量:
绝对差之和(SAD)- L1-norm
平方差之和(SSD)- L2-norm
汉明距离 (Hamming distance)

SAD和SSD之间的差异在于:首先两者之间的最短距离是一条直线,给定每个向量的两个分量,SAD计算长度差之和,这是一维过程。而SSD计算平方和,遵循毕达哥拉斯定律,在一个矩形三角形中,宽边平方的总和等于斜边的平方。因此,就两个向量之间的几何距离而言,L2-norm是一种更准确的度量。注意,相同的原理适用于高维描述符。
而汉明距离对于仅由1和0组成的二进制描述符很适合,该距离通过使用XOR函数计算两个向量之间的差,如果两个位相同,则返回零如果两位不同,则为1。因此,所有XOR操作的总和就是两个描述符之间的不同位数。
值得注意的是必须根据所使用的描述符的类型选择合适距离度量。
BINARY descriptors :BRISK, BRIEF, ORB, FREAK, and AKAZE- Hamming distance
HOG descriptors : SIFT (and SURF and GLOH, all patented)- L2-norm
寻找匹配对
让我们假设在一个图像中有N个关键点及其关联的描述符,在另一幅图像中有M个关键点。
蛮力匹配(Brute Force Matching)
寻找对应对的最明显方法是将所有特征相互比较,即执行N x M比较。对于第一张图像中给定的关键点,它将获取第二张图像中的每个关键点并计算距离。距离最小的关键点将被视为一对。这种方法称为“蛮力匹配(Brute Force Matching)”或“最近邻居匹配(Nearest Neighbor Matching)”。OPENCV中蛮力匹配的输出是一个关键点对的列表,这些关键点对按其在所选距离函数下的描述符的距离进行排序。
快速最近邻(FLANN)
2014年,David Lowe和Marius Muja发布了"快速最近邻(fast library for approximate nearest neighbors(FLANN)")。FLANN训练了一种索引结构,用于遍历使用机器学习概念创建的潜在匹配候选对象。该库构建了非常有效的数据结构(KD树)来搜索匹配对,并避免了穷举法的穷举搜索。因此,速度更快,结果也非常好,但是仍然需要调试匹配参数。
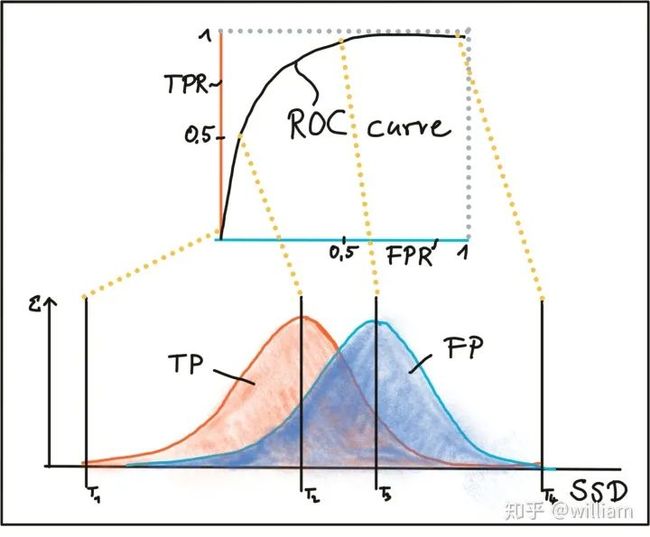
BFMatching和FLANN都接受描述符距离阈值T,该距离阈值T用于将匹配项的数量限制为“好”,并在匹配不对应的情况下丢弃匹配项。相应的“好”对称为“正阳性(TP)”,而错对称为“假阳性(FP)”。为T选择合适的值的任务是允许尽可能多的TP匹配,而应尽可能避免FP匹配。根据图像内容和相应的检测器/描述符组合,必须找到TP和FP之间的权衡点,以合理地平衡TP和FP之间的比率。下图显示了SSD上TP和FP的两种分布,以说明阈值选择。
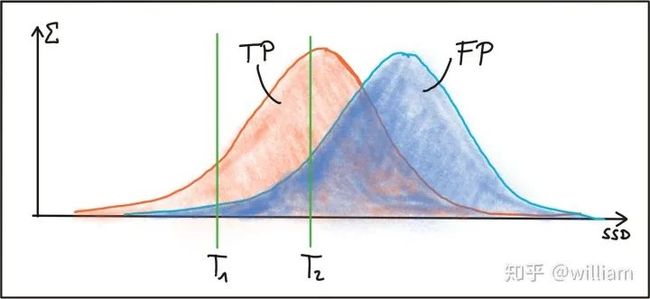
第一阈值T1被设置为两个特征之间的最大允许的SSD,其方式是选择了一些正确的正匹配,而几乎完全避免了错误的正匹配。但是,使用此设置也将丢弃大多数TP匹配项。通过将匹配阈值增加到T2,可以选择更多的TP匹配,但是FP匹配的数量也将显着增加。在实践中,几乎没有找到TP和FP的清晰明了的分离,因此,设置匹配阈值始终是平衡“好”与“坏”匹配之间的折衷。尽管在大多数情况下都无法避免FP,但目标始终是尽可能降低FP次数。在下文中,提出了实现这一目标的两种策略。
选择匹配对
BFMatching- crossCheck
只要不超过所选阈值T,即使第二图像中不存在关键点,蛮力匹配也将始终返回与关键点的匹配。这不可避免地导致许多错误的匹配。抵消这种情况的一种策略称为交叉检查匹配,它通过在两个方向上应用匹配过程并仅保留那些在一个方向上的最佳匹配与在另一个方向上的最佳匹配相同的匹配来工作。交叉检查方法的步骤为:
1、对于源图像中的每个描述符,请在参考图像中找到一个或多个最佳匹配。
2、切换源图像和参考图像的顺序。
3、重复步骤1中源图像和参考图像之间的匹配过程。
4、选择其描述符在两个方向上最匹配的那些关键点对。
尽管交叉检查匹配会增加处理时间,但通常会消除大量的错误匹配,因此,当精度优于速度时,应始终执行交叉匹配。交叉匹配一般仅仅用于BFMatching。
Nearest neighbor distance ratio (NN)/K-nearest-neighbor(KNN)
减少误报数量的另一种非常有效的方法是为每个关键点计算最近邻距离比(nearest neighbor distance ratio)。
KNN与NN的区别在与 NN 每个特征点只保留一个最好的匹配 (keeping only the best match),而KNN 每个特征点保留k个最佳匹配(keeping the best k matches per keypoint). k一般为2.
主要思想是不要将阈值直接应用于SSD。相反,对于源图像中的每个关键点,两个(k=2)最佳匹配位于参考图像中,并计算描述符距离之间的比率。然后,将阈值应用于比率,以筛选出模糊匹配。下图说明了原理。
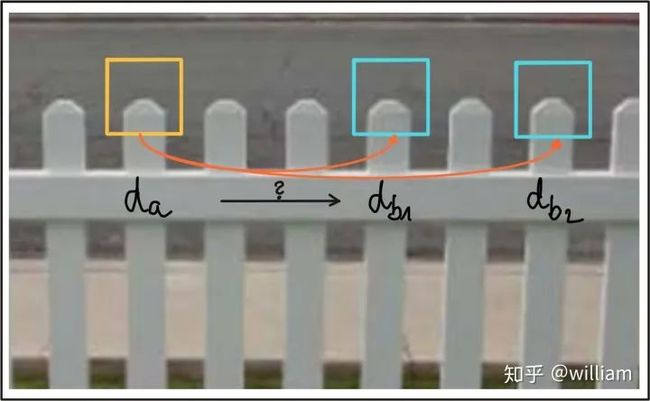
在该示例中,将具有关联描述符da的图像补丁与其他两个具有描述符的图像补丁d_ b1 和 d_b2进行比较 。可以看出,图像补丁看起来非常相似,并且会导致模棱两可,因此不可靠。通过计算最佳匹配与次佳匹配之间的SSD比值,可以过滤掉这些较弱的候选对象。
在实践中,已证明阈值0.8可以在TP和FP之间提供良好的平衡。在原始SIFT中检查的图像序列中,使用此设置可以消除90%的错误匹配,而丢失少于5%的正确匹配。注意,只有KNN能设置阈值0.8。NN只会提供一个最佳匹配。
以下是匹配的执行代码:
void matchDescriptors(std::vector &kPtsSource, std::vector &kPtsRef, cv::Mat &descSource,cv::Mat &descRef,std::vector &matches, std::string descriptorclass, std::string matcherType,std::string selectorType) {
// configure matcher
bool crossCheck = false;
cv::Ptr matcher;
int normType;
if (matcherType.compare("MAT_BF") == 0) {
int normType = descriptorclass.compare("DES_BINARY") == 0 ? cv::NORM_HAMMING : cv::NORM_L2;
matcher = cv::BFMatcher::create(normType, crossCheck);
} else if (matcherType.compare("MAT_FLANN") == 0) {
// OpenCV bug workaround : convert binary descriptors to floating point due to a bug in current OpenCV implementation
if (descSource.type() !=CV_32F) {
descSource.convertTo(descSource, CV_32F);
// descRef.convertTo(descRef, CV_32F);
}
if (descRef.type() !=CV_32F) {
descRef.convertTo(descRef, CV_32F);
}
matcher = cv::DescriptorMatcher::create(cv::DescriptorMatcher::FLANNBASED);
}
// perform matching task
if (selectorType.compare("SEL_NN") == 0) { // nearest neighbor (best match)
matcher->match(descSource, descRef, matches);
// Finds the best match for each descriptor in desc1
} else if (selectorType.compare("SEL_KNN") == 0) { // k nearest neighbors (k=2)
vector> knn_matches;
matcher->knnMatch(descSource, descRef, knn_matches, 2);
//-- Filter matches using the Lowe's ratio test
double minDescDistRatio = 0.8;
for (auto it = knn_matches.begin(); it != knn_matches.end(); ++it) {
if ((*it)[0].distance < minDescDistRatio * (*it)[1].distance) {
matches.push_back((*it)[0]);
}
}
}
} 
Evaluating Matching Performance
目前特征提取与匹配存在大量的检测器和描述符类型,为了解决的问题,必须基于诸如关键点的准确性或匹配对的数量之类的要求来选择合适的算法对。下面,概述了最常用的措施。
真阳性率(True Positive Rate-TPR)是已经匹配的正确关键点 (true positives - TP)和所有潜在匹配的总和之间的比值,包括那些被检测器/描述符(false negatives - FN)错过了的。完美匹配器的TPR为1.0,因为不会有错误匹配。TPR也称为召回(recall),可用于量化实际发现了多少个可能的正确匹配。
假阳性率 (False Positive Rate-FPR)是已经匹配错误的关键点(f_alse positives - FP_)和所有应该不被匹配的特征点之间的比值。完美匹配器的FPR为0.0。FPR也称为 false alarm rate,它描述检测器/描述符选择错误的关键点对的可能性。
Matcher Precision是正确匹配的关键点(TP)的数量除以所有匹配的数量。此度量也称为 inlier ratio。
很多人对于TP, FP, FN以及 TN的理解经常会产生偏差,尤其是FN和TN。下图是它们各自的定义:
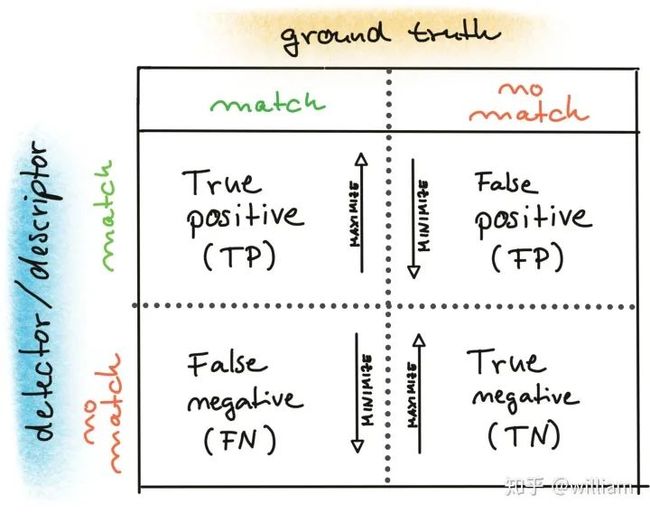
在这里我们需要介绍ROC的定义。
ROC曲线是一个图形化的图表,它显示了一个检测器 / 描述符如何很好地区分真假匹配,因为它的区分阈值是不同的。ROC 可以直观地比较不同的检测器 / 描述符,并为每个检测器选择一个合适的鉴别阈值。
下图显示了如何通过更改SSD的鉴别阈值,根据正阳性和假阳性的分布构造ROC。理想的检测器/描述符的TPR为1.0,而FPR同时接近0.0。
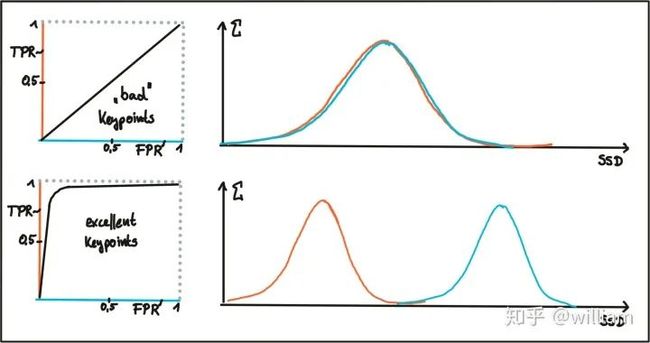
在下图中,显示了两个好的和不好的检测器/描述符的示例。在第一个示例中,无法安全区分TP和FP,因为两条曲线都匹配,并且辨别阈值的更改将以相同的方式影响它们。在第二个示例中,TP和FP曲线没有明显重叠,因此可以选择合适的鉴别器阈值。
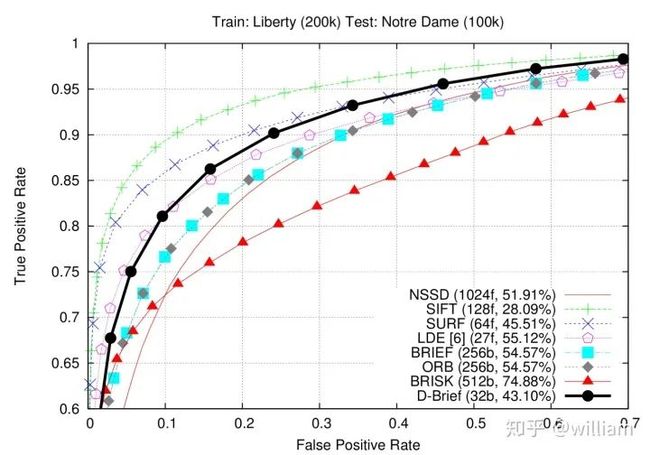
在该图中,您可以看到不同描述符(例如,SIFT,BRISK和其他几个描述符)的ROC曲线,并在视觉上进行比较。请注意,这些结果仅对实际用于比较的图像序列有效-对于其他图像集(例如,交通场景),结果可能会有很大差异。

Conclusion
2D_Feature_Tracking项目的目的在于使用检测器和描述符的所有可能组合,为所有10张图像计算只在前方车辆范围内的关键点数量,检测时间,描述时间,匹配时间以及匹配的关键点数量。在匹配步骤中,使用BF方法及KNN选择器并将描述符距离比设置为0.8。
以下是结果:
不同检测器的平均检测时间及检测出的关键点数目
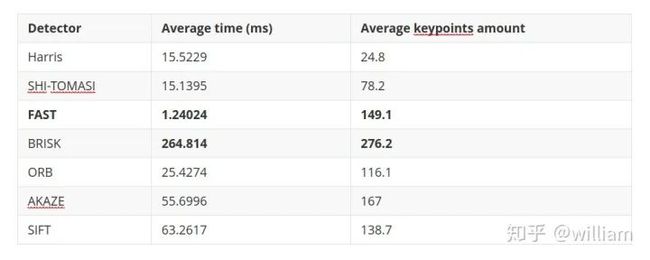
不同检测器和描述符组合的描述时间
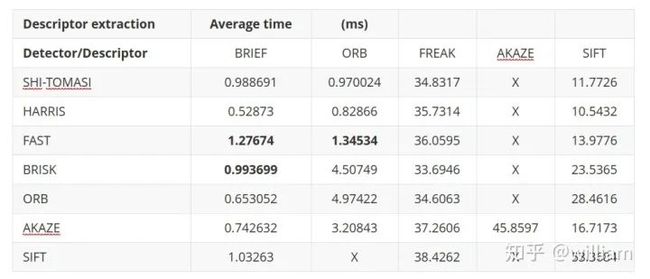
不同检测器和描述符组合的匹配点数目(控制匹配算法为不变量)
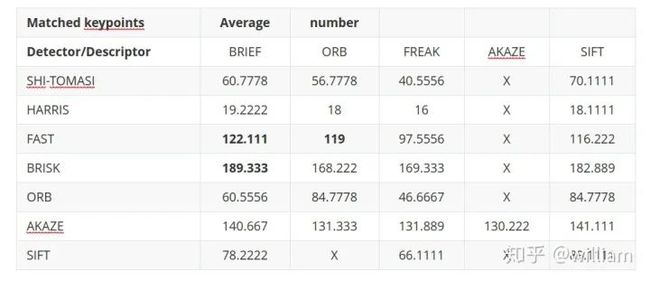
不同检测器和描述符组合的总运行时间
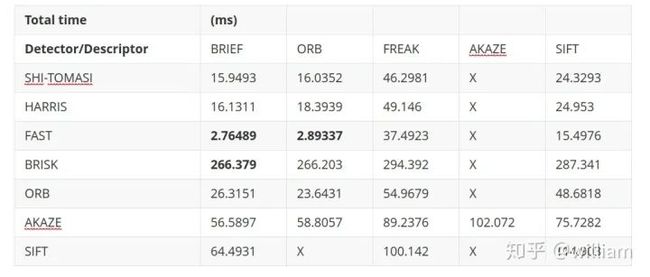
从上表中的第一印象可以可以看出:
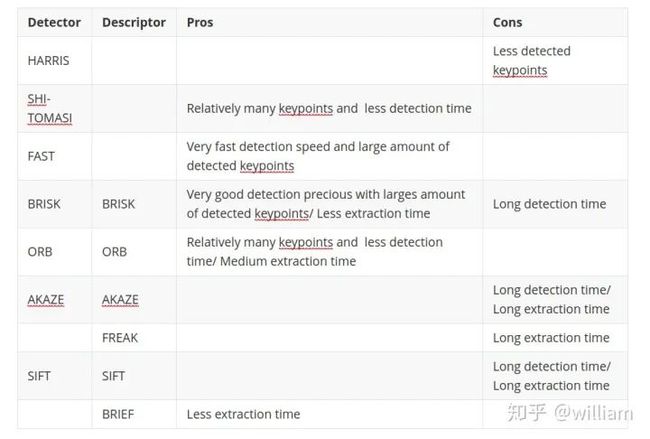
通过考虑所有这些变化,我可以说检测器/描述符的前三个组合是:
FAST + BRIEF (Higher speed and relative good accuracy)
BRISK + BRIEF (Higher accuracy)
FAST + ORB (relatively good speed and accuracy)
以上结论是基于实际测试比较表面数据得到的结论,你们也可以自己尝试修改我代码库中的检测器和描述符组合,看看结果有什么不同。
最后引用Shaharyar Ahmed Khan Tareen在其比较不同检测器和描述器组合性能的论文A Comparative Analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK中的结论:
SIFT,SURF和BRISK被认为是大多数尺度不变特征检测器(基于可重复性),它们在广泛的尺度尺度变化中不受影响。ORB具有最小的尺度不变性。ORB(1000),BRISK(1000)和AKAZE比其他旋转不变性更高。与其他相比,ORB和BRISK通常对仿射更改更加不变。与其余图像相比,SIFT,KAZE,AKAZE和BRISK具有更高的图像旋转精度。尽管ORB和BRISK是可以检测大量特征的最有效算法,但如此大量特征的匹配时间会延长总图像匹配时间。相反,ORB(1000)和BRISK(1000)执行最快的图像匹配,但其准确性受到损害。对于所有类型的几何变换,SIFT和BRISK的总体精度最高,SIFT被认为是最精确的算法。
定量比较表明,特征检测描述器检测大量特征的能力的一般顺序为:
ORB>BRISK>SURF>SIFT>AKAZE>KAZE
每个特征点的特征检测描述器的计算效率顺序为:
ORB>ORB (1000) >BRISK>BRISK (1000) >SURF (64D)>SURF (128D) >AKAZE>SIFT>KAZE
每个特征点的有效特征匹配顺序为:
ORB (1000) >BRISK (1000) >AKAZE>KAZE>SURF (64D)>ORB>BRISK>SIFT>SURF (128D)
特征检测描述器的整体图像匹配速度顺序为:
ORB (1000) >BRISK (1000) >AKAZE>KAZE>SURF (64D)>SIFT>ORB>BRISK>SURF (128D)
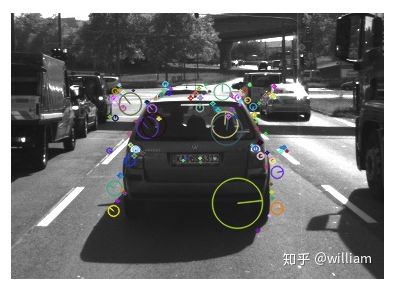
备注:不同检测器的检测图像,从中可以看出它们关键点邻域的大小和分布。
HARRIS

Shi-Tomasi

FAST

BRISIK

ORB

AKAZE

SIFT
引用资料
UDACITY
A Comparative Analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK
Deepanshu Tyagi
如果你想了解整个图像特征提取匹配的流程,可以参看我的代码库的README文件。
如果有什么疑问,可以随时联系我的个人邮箱。
Github:https://github.com/williamhyin/SFND_2D_Feature_Tracking
Email:[email protected]
Linkedin:https://linkedin.com/in/williamhyin
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~