分类(六)—— 模型评估与选择
主要内容
分类概述
决策树归纳
K近邻算法
支持向量机
朴素贝叶斯分类
模型评估与选择
组合分类
小结
六、模型评估与选择
构建的分类器总是希望有较好的性能,如何评估分类器性能,需要一些客观的指标进行评判。比如,如何评估分类器的准确率(模型评估)以及如何在多个分类器中选择“最好的”一个。
分类器性能的度量

1.混淆矩阵
根据实际类别与机器学习预测类别的组合(混淆矩阵,Confusion Matrix)可分为真正例(True Positive,TP)(又称真阳性)、假正例(False Positive,FP)(又称假阳性)、假负例(False Negative,FN)(又称假阴性)和真负例(True Negative,TN)(又称真阴性)四种情况。

2.分类器常用评估量
(1)准确率和错误率
分类器在检验集上的准确率(Accuracy)被定义为被该分类器正确分类的元组所占的百分比。

错误率(误分类率):

(2)灵敏性和特效性
灵敏性(7.35)又称真正类率(true positive rate ,TPR),它表示了分类器所识别出的正实例占所有正实例的比例。特效性(7.36)是真负例率,即正确识别的负元组的百分比。

可以证明准确率是灵敏性和特效性度量的函数,即:

(3)精度和召回率
精度和召回率也在分类中广泛使用。精度(Precision)定义为标记为正例的元组实际为正类的百分比,可以看作精确度的度量,也被称为查准率。召回率(Recall)定义为正元组标记为正的百分比,是完全性的度量,也被称为查全率。


除了基于准确率的度量外,还可以在其他方面进行分类器的比较,主要因素有:
(1) 速度:构建和使用分类器的计算开销。
(2)鲁棒性:对有噪声或缺失值数据分类器做出正确预测的能力。通常鲁棒性用噪声和缺失值渐增的一系列合成数据集进行评估。
(3)可伸缩性:对于给定大量数据有效构造分类器的能力。通常,可伸缩性用规模渐增的一系列数据集评估。
(4)可解释性:对分类器提供的理解和洞察水平。可解释性是主观的,因为很难评估。比如决策树和分类规则一般容易解释,但随着它们变得更复杂,其可解释性也随之消失。
(5)P-R曲线
评价一个模型的好坏,不能仅靠精确率或者召回率,最好构建多组精确率和召回率,绘制出模型的P-R曲线。
在绘制P-R曲线的横轴是召回率,纵轴是精确率。P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
(6)接收者操作特征曲线
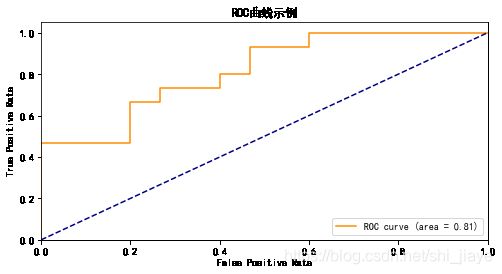
接收者操作特征曲线(Receiver Operating Characteristic Curve,ROC)是一种反映分类模型敏感性和特异性连续变量的综合指标,显示了给定模型的真正例率(TPR)和假正例率(FPR)之间的权衡。ROC通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,并以TPR为纵坐标、FPR为横坐标绘制曲线,曲线下面积越大,诊断准确性越高。ROC曲线上每个点反映着对同一信号刺激的感受性,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
3.Python分类器评估示例。
(1)导入相关模块和数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm,datasets
from sklearn.metrics import roc_curve,auc
from sklearn import model_selection
iris = datasets.load_iris()
X = iris.data
y = iris.target
(2)iris数据取前2类数据并增加随机扰动
X,y = X[y!=2],y[y!=2]
# 增加嗓声
random_state = np.random.RandomState(0)
n_samples,n_features = X.shape
X = np.c_[X,random_state.randn(n_samples,200*n_features)]
(3)数据集划分并进行模型训练
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size=.3,random_state=0)
classifier = svm.SVC(kernel='linear',probability=True,random_state=random_state)
classifier.fit(X_train,y_train)
# SVC(kernel='linear', probability=True,
# random_state=)
(4)在测试集上进行预测并评估
from sklearn.metrics import precision_score,recall_score,f1_score,fbeta_score
y_predict = classifier.predict(X_test)
# classifier.fit(X_train, y_train.ravel())
print("SVM-输出训练集的准确率为:", classifier.score(X_train, y_train))
print('Precision: %.3f' % precision_score(y_true=y_test, y_pred=y_predict))
print('Recall: %.3f' % recall_score(y_true=y_test, y_pred=y_predict))
print('F1: %.3f' % f1_score(y_true=y_test, y_pred=y_predict))
print('F_beta: %.3f' % fbeta_score(y_true=y_test, y_pred=y_predict, beta=0.8))
SVM-输出训练集的准确率为: 1.0
Precision: 0.769
Recall: 0.667
F1: 0.714
F_beta: 0.726
(5)绘制ROC曲线
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr,tpr,threshold = roc_curve(y_test, y_score) #计算真正率和假正率
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.rcParams['font.family']=['SimHei']
plt.figure()
# lw = 2
plt.figure(figsize=(8,4))
plt.plot(fpr, tpr, color='darkorange',
label='ROC curve (area = %0.2f)' % roc_auc)
#假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC曲线示例')
plt.legend(loc="lower right")
plt.show()
模型选择
当假设空间含有不同的复杂度的模型时,会面临模型选择(Model Selection)问题。我们希望所选择的模型要与真模型的参数个数相同,所选择的模型的参数向量与真模型的参数向量相近。然而,一味追求提高分类器的预测能力,所选择的模型的复杂度会比真模型要高,这种现象被称为过拟合(Over-fitting)。过拟合指学习时选择的模型所含的参数过多,导致该模型对已知数据预测的很好,但对未知数据预测很差的现象。因此,模型选择旨在避免过拟合并提高模型的预测能力。在模型选择时,不仅要考虑对已知数据的预测能力,还要考虑对未知数据的预测能力。
模型选择方法主要有正则化和交叉验证方法。
1.正则化
模型选择的典型方法是正则化(Regularization)。正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(Regularizer)或惩罚项(Penalty)。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大,比如,正则化项可以是模型参数向量的范数。

其中,||w||表示参数向量w的L2范数。
正则化项也可以是参数向量的L1范数。

其中,||w||1表示参数向量w的L1范数。
正则化符合奥卡姆剃刀(Occam’s razor)原理。奥卡姆剃刀原理应用于模型选择时认为,在所有可能选择的模型中,能够很好地解释已知数据并且尽可能简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂的模型有较大的先验概率,简单的模型有较小的先验概率。
2.交叉验证
另一种常用的模型选择方法是交叉验证(Cross Validation)。如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集划分为训练集(Training set)、验证集(Validation Set)和测试集(Test Set)三部分。
(1)简单交叉验证
简单交叉验证方法是随机地将已给数据分为训练集和测试集(如70%的数据作为训练集,30%的数据作为测试集),然后用训练集在各种条件下(如不同的参数个数)训练模型在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
from sklearn.model_selection import train_test_split
import numpy as np
X = np.array([[1,2],[3,4],[5,6],[7,8]])
y = np.array([1,2,2,1])
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.50,random_state=5)
print("X_train:\n",X_train)
print("y_train:\n",y_train)
print("X_test:\n",X_test)
print("y_test:\n",y_test)
X_train:
[[5 6]
[7 8]]
y_train:
[2 1]
X_test:
[[1 2]
[3 4]]
y_test:
[1 2]
(2)k-折交叉验证
在k-折交叉验证(k-fold Cross-Validation)中,首先随机地将已给数据划分为k个互不相交的大小相同的子集,然后利用k-1个子集的数据训练模型,利用余下的子集测试模型。将这一过程对可能的k种选择重复进行,最后选出k次评测中平均测试误差最小的模型。
from sklearn.model_selection import KFold
import numpy as np
X = np.array([[1,2],[3,4],[5,6],[7,8]])
y = np.array([1,2,2,1])
kf = KFold(n_splits=2)
for train_index,test_index in kf.split(X):
print("Train:", train_index,"Validation:", test_index)
X_train,X_test = X[train_index],X[test_index]
y_train,y_test = y[train_index],y[test_index]
Train: [2 3] Validation: [0 1]
Train: [0 1] Validation: [2 3]
(3)留一交叉验证
k折交叉验证的特殊情形是k=N,即k设置为元组的个数,称为留一交叉验证(Leave-one-out Cross Validation),往往在数据缺乏的情况下使用。
from sklearn.model_selection import LeaveOneOut
import numpy as np
X = np.array([[1,2],[3,4],[5,6],[7,8]])
y = np.array([1,2,2,1])
loo = LeaveOneOut()
loo.get_n_splits(X)
for train_index,test_index in loo.split(X):
print("train:", train_index,"validation:",test_index)
train: [1 2 3] validation: [0]
train: [0 2 3] validation: [1]
train: [0 1 3] validation: [2]
train: [0 1 2] validation: [3]