yolov3改进4层特征检测层
YOLOv3改进方法
YOLOv3的改进方法有很多,本文讲述的是增加一个特征尺度。
以YOLOv3-Darknet53(ALexeyAB版本)为基础,增加了第4个特征尺度:104*104。原版YOLOv3网络结构:
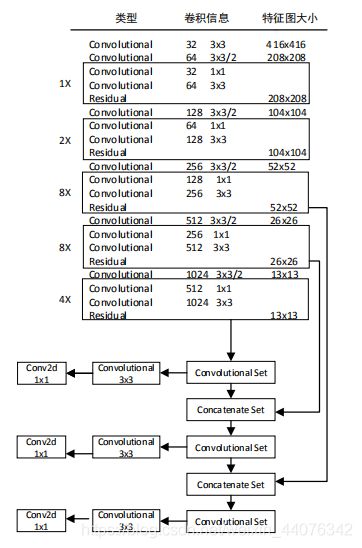
YOLOv3-4l网络结构:
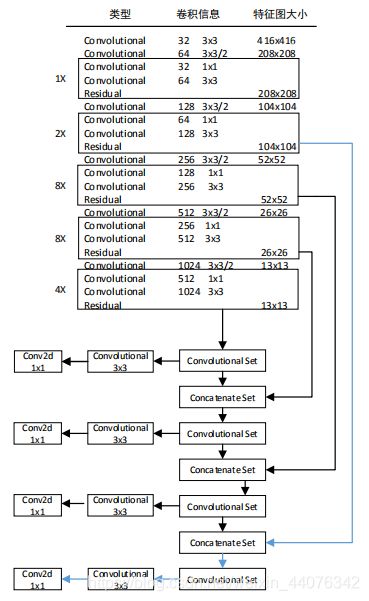
即,在经过2倍上采样后,输出的特征尺度由52x52提升至104x104,再通过route层将第109层与特征提取网络的第11层特征进行特征融合,以充分利用深层特征和浅层特征。其余的特征融合分别为:2倍上采样后输出的第85层和第97层。通过route层分别将第85层与第61层,第97层与第36层的特征图进行特征融合。四个特征尺度分别为:104x104,52x52,26x26和13x13。
具体的步骤为:
(1)修改配置文件cfg
再增加一个检测尺度(在原yolov3的最后一层yolo层的后面,再增加一个检测层:在下方链接里的cfg文件最后的“#######”注释行之后的部分,便是增加的检测层结构)。
yolo-4l的cfg下载地址
链接:https://pan.baidu.com/s/1b92jmcAPTgzxua4Pat7p4A
提取码:xji2
注意:网盘里提供的cfg配置文件,需要进行相应参数修改
(修改示例见链接:yolov3的cfg配置文件注释及修改示例)。
(2)重新计算anchors
由于原先是3个检测尺度共9个anchors,此时是4层共12个anchors。且不同数据库的anchors值不一样(比如自行构建的数据库),所以必须重新计算anchors,并更新到cfg文件中。如果选取的先验框维度比较合适,那么模型就会更容易学习,更易收敛,从而做出更好的预测,预测框与标注真实框的IOU就会更好。
计算数据库的anchors的命令为:
./darknet detector calc_anchors /usr/cx/darknetalexeyAB/darknet-master/names_data/voc.data -num_of_clusters 12 -width 416 -height 416 -show 1
注意:/usr/cx/darknetalexeyAB/darknet-master/names_data/voc.data是我们自己的voc.data的路径,根据自己的项目自行进行修改。
结果如下图所示:

计算多次,每次的anchors值会不一样,但基本相差无几。其实这些anchors值,就是先验框,就是样本库里最经常出现的几类边界框。通过选取专属于实际数据库的anchors,将会加速收敛,更容易学习,提高IOU值。
这里还有另外1种计算anchors的方法, 通过脚本文件来计算anchors锚点值。脚本文件如下所示:
# coding=utf-8
# 通过k-means ++ 算法获取anchors的尺寸
import numpy as np
# 定义Box类,描述bounding box的坐标
class Box():
def __init__(self, x, y, w, h):
self.x = x
self.y = y
self.w = w
self.h = h
# 计算两个box在某个轴上的重叠部分
# x1是box1的中心在该轴上的坐标
# len1是box1在该轴上的长度
# x2是box2的中心在该轴上的坐标
# len2是box2在该轴上的长度
# 返回值是该轴上重叠的长度
def overlap(x1, len1, x2, len2):
len1_half = len1 / 2
len2_half = len2 / 2
left = max(x1 - len1_half, x2 - len2_half)
right = min(x1 + len1_half, x2 + len2_half)
return right - left
# 计算box a 和box b 的交集面积
# a和b都是Box类型实例
# 返回值area是box a 和box b 的交集面积
def box_intersection(a, b):
w = overlap(a.x, a.w, b.x, b.w)
h = overlap(a.y, a.h, b.y, b.h)
if w < 0 or h < 0:
return 0
area = w * h
return area
# 计算 box a 和 box b 的并集面积
# a和b都是Box类型实例
# 返回值u是box a 和box b 的并集面积
def box_union(a, b):
i = box_intersection(a, b)
u = a.w * a.h + b.w * b.h - i
return u
# 计算 box a 和 box b 的 iou
# a和b都是Box类型实例
# 返回值是box a 和box b 的iou
def box_iou(a, b):
return box_intersection(a, b) / box_union(a, b)
# 使用k-means ++ 初始化 centroids,减少随机初始化的centroids对最终结果的影响
# boxes是所有bounding boxes的Box对象列表
# n_anchors是k-means的k值
# 返回值centroids 是初始化的n_anchors个centroid
def init_centroids(boxes,n_anchors):
centroids = []
boxes_num = len(boxes)
centroid_index = np.random.choice(boxes_num, 1)
centroids.append(boxes[centroid_index])
print(centroids[0].w,centroids[0].h)
for centroid_index in range(0,n_anchors-1):
sum_distance = 0
distance_thresh = 0
distance_list = []
cur_sum = 0
for box in boxes:
min_distance = 1
for centroid_i, centroid in enumerate(centroids):
distance = (1 - box_iou(box, centroid))
if distance < min_distance:
min_distance = distance
sum_distance += min_distance
distance_list.append(min_distance)
distance_thresh = sum_distance*np.random.random()
for i in range(0,boxes_num):
cur_sum += distance_list[i]
if cur_sum > distance_thresh:
centroids.append(boxes[i])
print(boxes[i].w, boxes[i].h)
break
return centroids
# 进行 k-means 计算新的centroids
# boxes是所有bounding boxes的Box对象列表
# n_anchors是k-means的k值
# centroids是所有簇的中心
# 返回值new_centroids 是计算出的新簇中心
# 返回值groups是n_anchors个簇包含的boxes的列表
# 返回值loss是所有box距离所属的最近的centroid的距离的和
def do_kmeans(n_anchors, boxes, centroids):
loss = 0
groups = []
new_centroids = []
for i in range(n_anchors):
groups.append([])
new_centroids.append(Box(0, 0, 0, 0))
for box in boxes:
min_distance = 1
group_index = 0
for centroid_index, centroid in enumerate(centroids):
distance = (1 - box_iou(box, centroid))
if distance < min_distance:
min_distance = distance
group_index = centroid_index
groups[group_index].append(box)
loss += min_distance
new_centroids[group_index].w += box.w
new_centroids[group_index].h += box.h
for i in range(n_anchors):
new_centroids[i].w /= len(groups[i])
new_centroids[i].h /= len(groups[i])
return new_centroids, groups, loss
# 计算给定bounding boxes的n_anchors数量的centroids
# label_path是训练集列表文件地址
# n_anchors 是anchors的数量
# loss_convergence是允许的loss的最小变化值
# grid_size * grid_size 是栅格数量
# iterations_num是最大迭代次数
# plus = 1时启用k means ++ 初始化centroids
def compute_centroids(label_path,n_anchors,loss_convergence,grid_size,iterations_num,plus):
boxes = []
label_files = []
f = open(label_path)
for line in f:
label_path = line.rstrip().replace('images', 'labels')
label_path = label_path.replace('JPEGImages', 'labels')
label_path = label_path.replace('.jpg', '.txt')
label_path = label_path.replace('.JPEG', '.txt')
label_files.append(label_path)
f.close()
for label_file in label_files:
f = open(label_file)
for line in f:
temp = line.strip().split(" ")
if len(temp) > 1:
boxes.append(Box(0, 0, float(temp[3]), float(temp[4])))
if plus:
centroids = init_centroids(boxes, n_anchors)
else:
centroid_indices = np.random.choice(len(boxes), n_anchors)
centroids = []
for centroid_index in centroid_indices:
centroids.append(boxes[centroid_index])
# iterate k-means
centroids, groups, old_loss = do_kmeans(n_anchors, boxes, centroids)
iterations = 1
while (True):
centroids, groups, loss = do_kmeans(n_anchors, boxes, centroids)
iterations = iterations + 1
print("loss = %f" % loss)
if abs(old_loss - loss) < loss_convergence or iterations > iterations_num:
break
old_loss = loss
for centroid in centroids:
print(centroid.w * grid_size, centroid.h * grid_size)
# print result
for centroid in centroids:
print("k-means result:\n")
print(centroid.w * grid_size, centroid.h * grid_size)
#只需修改这里的参数n_anchors和grid_size;得到的9个预选框的参数复制到cfg即可
#要修改的路径--训练集train.txt的路径
#label_path = "/home/chris/darknet/scripts/2007_train.txt"
label_path = "/usr/cx/darknetalexeyAB/names_data/2007_train.txt"
n_anchors = 9 #预选框anchors的个数,6,9,12,15,根据自己的实际项目进行设置;
loss_convergence = 1e-6
grid_size = 416 #栅格的尺寸
iterations_num = 100 #迭代的步数
plus = 0 #开关;=1时,使用k-means++算法,一般=0。
compute_centroids(label_path,n_anchors,loss_convergence,grid_size,iterations_num,plus)
脚本文件(命名为k-means.py)
运行python k-means.py即可。
注意修改路径。代码注释中已经标出。
(3)anchors值替换
在cfg文件的每个yolo层,进行如下修改:
1)mask取值变为0~11,3个为一组,最前面一层yolo层的mask赋值为9,10,112)将第二行的anchors值更新替换成步骤(2)中计算得到的anchors值; 3)classes是类别数,此项目仅有1个类别,根据自己的项目修改classes的值; 3)将num=9改成num=12`;
[yolo]
mask = 9,10,11
anchors = 34, 57, 77,110, 145,155, 174,220, 177,324, 212,273, 281,212, 356,206, 241,316, 329,265, 399,265, 346,33
classes=1
num=12
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
(4)模型训练
经过增加cfg配置文件的检测层,计算anchors,并将其更新到cfg配置文件中之后,接下来就可以进行模型的训练了。
注意:由于我们没有对backbone基础网络进行修改,所以,可以使用darknet53.conv.74预训练权重进行训练。
darknet53.conv.74下载链接如下:
darknet53.conv.74权重文件
链接:https://pan.baidu.com/s/14Hwqqsp_ua28Xu27gaQk6g
提取码:dnai
(5)检测结果
训练完之后,便可以对测试验证集进行初步的检测验证。
傍晚同一视频&不同帧&不同算法的检测:
不同场景的列车检测的示意图:

凌晨雪景检测效果: