深度学习 06_图像金字塔(OpenCV系列)
目录
8.图像金字塔
8.1 图像金字塔介绍
8.2 高斯金字塔
8.3 拉普拉斯金字塔
9 图像直方图
9.1. 使用OpenCV统计直方图
9.2 使用OpenCV绘制直方图
9.3 使用掩膜的直方图
编辑
9.4 直方图均衡化原理
8.图像金字塔
8.1 图像金字塔介绍
图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。简单来说, 图像金字塔是同一图像不同分辨率的子图集合.
图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
常见两类图像金字塔 :
高斯金字塔 ( Gaussian pyramid) : 用来向下/降采样,主要的图像金字塔.
拉普拉斯金字塔(Laplacian pyramid) : 用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。
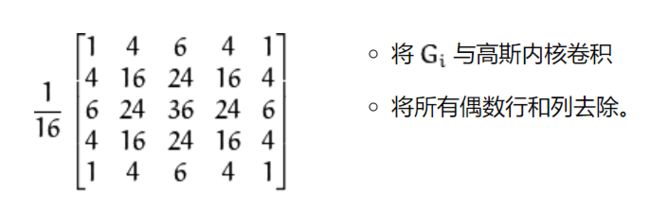
8.2 高斯金字塔
高斯金字塔是通过高斯平滑和亚采样获得一系列下采样图像.
原理非常简单, 如下图所示:
原始图像 M * N -> 处理后图像 M/2 * N/2.
每次处理后, 结果图像是原来的1/4.
注意: 向下采样会丢失图像信息.
向上取样:
-
向上取样是向下取样的相反过程, 是指图片从小变大的过程.
-
将图像在每个方向扩大为原来的两倍, 新增的行和列用0填充
-
先使用先前同样的内核(乘以4)和放大后的图像卷积, 获得近似值

pyrDown 向下采样:
import cv2
import numpy as np
img = cv2.imread('./lena.png')
print(img.shape)
# 下采样, 大小变为原来的1/4
dst = cv2.pyrDown(img)
print(dst.shape)
cv2.imshow('img', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()pyrUp 向上采样:
# 向上采样
import cv2
import numpy as np
img = cv2.imread('./lena.png')
print(img.shape)
# 向上采样
dst = cv2.pyrUp(img)
print(dst.shape)
cv2.imshow('img', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()取样可逆性研究:
在根据向上和向下取样的原理, 我们能够发现图像在变大变小的过程中是有信息丢失的. 即使把图片变回原来大小,图片也不是原来的图片了, 而是损失了一定的信息. # 不可逆
# 研究采样中图像的损失
import cv2
import numpy as np
img = cv2.imread('./lena.png')
# 先放大, 再缩小
dst = cv2.pyrUp(img)
dst = cv2.pyrDown(dst)
cv2.imshow('img', img)
cv2.imshow('dst', dst)
cv2.imshow('loss', img - dst) # 显示差值
cv2.waitKey(0)
cv2.destroyAllWindows()8.3 拉普拉斯金字塔
将降采样之后的图像再进行上采样操作,然后与之前还没降采样的原图进行做差得到残差图!为还原图像做信息的准备!
也就是说,拉普拉斯金字塔是通过源图像减去先缩小后再放大的图像的一系列图像构成的。保留的是残差!
# 研究采样中图像的损失
import cv2
import numpy as np
img = cv2.imread('./lena.png')
dst = cv2.pyrDown(img)
dst = cv2.pyrUp(dst)
lap0 = img - dst
cv2.imshow('img', img)
cv2.imshow('dst', dst)
cv2.imshow('lap0', lap0)
cv2.waitKey(0)
cv2.destroyAllWindows()9 图像直方图
在统计学中,直方图是一种对数据分布情况的图形表示,是一种二维统计图表.
图像直方图是用一表示数字图像中亮度分布的直方图,标绘了图像中每个亮度值的像素数。可以借助观察该直方图了解需要如何调整亮度分布的直方图。这种直方图中,横坐标的左侧为纯黑、较暗的区域,而右侧为较亮、纯白的区域。因此,一张较暗图片的图像直方图中的数据多集中于左侧和中间部分,而整体明亮、只有少量阴影的图像则相反。
-
横坐标: 图像中各个像素点的灰度级.
-
纵坐标: 具有该灰度级的像素个数.

9.1. 使用OpenCV统计直方图
calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
-
images: 原始图像
-
channels: 指定通道.
-
需要用中括号括起来, 输入图像是灰度图像是, 值是[0], 彩色图像可以是[0], [1], [2], 分别对应B,G,R.
-
-
mask: 掩码图像
-
统计整幅图像的直方图, 设为None
-
统计图像某一部分的直方图时, 需要掩码图像.
-
-
histSize: BINS的数量
-
需要用中括号括起来, 例如[256]
-
-
ranges: 像素值范围, 例如[0, 255]
-
accumulate: 累积标识
-
默认值为False
-
如果被设置为True, 则直方图在开始分配时不会被清零.
-
该参数允许从多个对象中计算单个直方图, 或者用于实时更新直方图.
-
多个直方图的累积结果, 用于对一组图像计算直方图.
-
import cv2
import matplotlib.pyplot as plt
lena = cv2.imread('./lena.png')
# 直方图
hist = cv2.calcHist([lena], [0], None, [256], [0, 255])
print(type(hist))
print(hist.size)
print(hist.shape)
print(hist)9.2 使用OpenCV绘制直方图
可以利用matplotlib把OpenCV统计得到的直方图绘制出来. # plt.plot(hist)
import cv2
import matplotlib.pyplot as plt
lena = cv2.imread('./lena.png')
histb = cv2.calcHist([lena], [0], None, [256], [0, 255])
histg = cv2.calcHist([lena], [1], None, [256], [0, 255])
histr = cv2.calcHist([lena], [2], None, [256], [0, 255])
plt.plot(histb, color='b')
plt.plot(histg, color='g')
plt.plot(histr, color='r')
plt.show()
9.3 使用掩膜的直方图
如何生成掩膜
-
先生成一个全黑的和原始图片大小一样大的图片. mask = np.zeros(image.shape, np.uint8)
-
将想要的区域通过索引方式设置为255. mask[100:200,, 200: 300] = 355
import cv2
import matplotlib.pyplot as plt
lena = cv2.imread('./lena.png')
gray = cv2.cvtColor(lena, cv2.COLOR_BGR2GRAY)
mask = np.zeros(gray.shape, np.uint8)
mask[200:400, 200: 400] = 255
hist_mask = cv2.calcHist([gray], [0], mask, [256], [0, 255])
hist_img = cv2.calcHist([gray], [0], None, [256], [0, 255])
plt.plot(hist_mask)
plt.plot(hist_img)
cv2.imshow('mask', cv2.bitwise_and(gray, gray, mask=mask))
cv2.waitKey(0)
cv2.destroyAllWindows()
9.4 直方图均衡化原理
直方图均衡化是通过拉伸像素强度的分布范围,使得在0~255灰阶上的分布更加均衡,提高了图像的对比度,达到改善图像主观视觉效果的目的。对比度较低的图像适合使用直方图均衡化方法来增强图像细节。
原理:
-
计算累计直方图
-
将累计直方图进行区间转换
-
在累计直方图中, 概率相近的原始值, 会被处理为相同的值
equalizeHist(src[, dst])
-
src 原图像
-
dst 目标图像, 即处理结果
import cv2
import matplotlib.pyplot as plt
lena = cv2.imread('./lena.png')
gray = cv2.cvtColor(lena, cv2.COLOR_BGR2GRAY)
# lena变黑
gray_dark = gray - 40
# lena变亮
gray_bright = gray + 40
# 查看各自的直方图
hist_gray = cv2.calcHist([gray], [0], None, [256], [0, 255])
hist_dark = cv2.calcHist([gray_dark], [0], None, [256], [0, 255])
hist_bright = cv2.calcHist([gray_bright], [0], None, [256], [0, 255])
plt.plot(hist_gray)
plt.plot(hist_dark)
plt.plot(hist_bright)
# 进行均衡化处理
dark_equ = cv2.equalizeHist(gray_dark)
bright_equ = cv2.equalizeHist(gray_bright)
cv2.imshow('gray_dark', np.hstack((gray_dark, dark_equ)))
cv2.imshow('gray_bright', np.hstack((gray_bright, bright_equ)))
cv2.waitKey(0)
cv2.destroyAllWindows()