一、Pytorch安装
安装cuda和cudnn,例如cuda10,cudnn7.5
官网下载torch:https://pytorch.org/ 选择下载相应版本的torch 和torchvision的whl文件
使用pip install whl_dir安装torch,并且同时安装torchvision
二、初步使用pytorch
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch import time # 查看torch版本 print(torch.__version__) # 定义矩阵a和b,随机值填充 a = torch.randn(10000, 1000) b = torch.randn(1000, 2000) # 记录开始时间 t0 = time.time() # 计算矩阵乘法 c = torch.matmul(a, b) # 记录结束时间 t1 = time.time() # 打印结果和运行时间 print(a.device, t1 - t0, c.norm(2)) # 这里的c.norm(2)是计算c的L2范数 # 使用GPU设备 device = torch.device('cuda') # 将ab搬到GPU a = a.to(device) b = b.to(device) # 运行,并记录运行时间 t0 = time.time() c = torch.matmul(a, b) t1 = time.time() # 打印在GPU上运行所需时间 print(a.device, t1 - t0, c.norm(2)) # 再次运行,确认运行时间 t0 = time.time() c = torch.matmul(a, b) t1 = time.time() print(a.device, t1 - t0, c.norm(2))
运行结果如下:
1.1.0 cpu 0.14660906791687012 tensor(141129.3906) cuda:0 0.19049072265625 tensor(141533.1250, device='cuda:0') cuda:0 0.006981372833251953 tensor(141533.1250, device='cuda:0')
我们发现,两次在GPU上运行的时间不同,第一次时间甚至超过CPU运行时间,这是因为第一次运行有初始化GPU运行环境的时间开销。
三、自动求导
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch # 定义a b c x的值,abc指定为需要求导requires_grad=True x = torch.tensor(2.) a = torch.tensor(1., requires_grad=True) b = torch.tensor(2., requires_grad=True) c = torch.tensor(3., requires_grad=True) # 定义y函数 y = a * x ** 2 + b * x + c; # 使用autograd.grad自定求导 grads = torch.autograd.grad(y, [a, b, c]) # 打印abc分别的导数值(带入x的值) print('after', grads[0],grads[1],grads[2])
四、pytorch数据类型
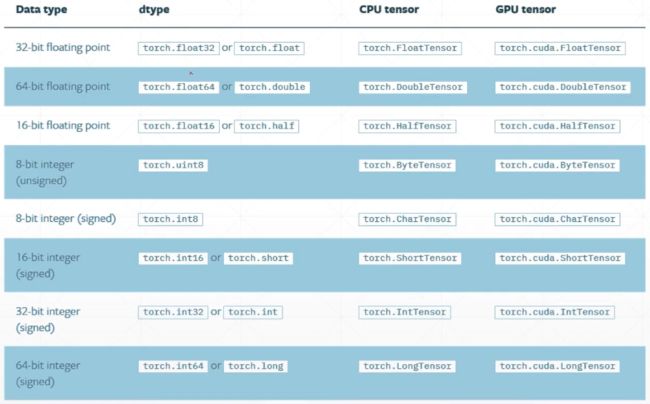
查看数据的类型:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.randn(2, 3) print(a.type()) # 打印torch.FloatTensor print(type(a)) # 打印print(isinstance(a, torch.FloatTensor)) # 打印True print(isinstance(a, torch.cuda.FloatTensor)) # 打印False # 将a放到GPU中 a = a.to(torch.device('cuda')) # 或这样也可以 a = a.cuda() print(isinstance(a, torch.cuda.FloatTensor)) # 打印True
查看数据的维度等信息:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.randn(2, 3) # b是一个dim为0的标量(就是一个数) b = torch.tensor(2.2) # 查看shape print(a.shape) # 返回torch.Size([2,3]) print(b.shape) # 返回torch.Size([]) print(len(a.shape)) # 返回2 print(len(b.shape)) # 返回0,表示dim为0 # size()和shape是一样的,size是成员函数,shape是成员属性 print(a.size()) # 返回torch.Size([2,3]) print(a.size(0)) # 返回2 print(a.size(1)) # 返回3 print(b.size()) # 返回torch.Size([]) # 返回a的维度,返回2,表示2D矩阵 print(a.dim())
五、pytorch基本使用
定义数据:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch import numpy as np # 建议使用torch.tensor()来直接赋值 a = torch.tensor([1., 2., 3.]) # 直接赋值(建议) # 不建议用FloatTensor来直接赋值,避免混淆 a_2 = torch.FloatTensor([1.,2.,3.]) # 也可以用FloatTensor赋值 # 建议使用FloatTensor传入shape来定义数据结构 b = torch.FloatTensor(1) # 参数表示shape,这里是2个元素的向量,值未初始化,可能很大或很小 c = torch.FloatTensor(3, 2) # 这里表示维度为[3,2]的矩阵,值未初始化,可能很大或很小 d = torch.ones(3, 3) # 定义维度为[3,3]的全1矩阵 # 同numpy来转换数据 e_np = np.ones((3, 3)) # 定义numpy的全1 ndarray e = torch.from_numpy(e_np) # 使用numpy转换到tensor print('a: ', a) print('b: ', b) print('c: ', c) print('d: ', d) print('e: ', e)
打印结果:
a: tensor([1., 2., 3.]) b: tensor([1.1729e-42]) c: tensor([[4.0006e-28, 8.5339e-43], [2.3196e-07, 4.5909e-41], [0.0000e+00, 0.0000e+00]]) d: tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]]) e: tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]], dtype=torch.float64)
随机数据与不同dim的数据:
# 正太分布随机数 randn_mat = torch.randn(2,3) print(randn_mat) # 均匀分布随机数,范围[0,1] rand_mat = torch.rand(2,3) print(rand_mat) # Int随机,返回[0,10),注意是前闭后开区间 randint_mat = torch.randint(0,10,[3,3]) print(randint_mat) # 二维tensor,可以表示4张mnist图片(图片已fla) tensor_2d = torch.rand(4,784) # 三维tensor,可以表示20句话,每句话10个单词,每个单词用onehot来表示[1,100] tensor_3d = torch.rand(20,10,100) # 四维tensor,可以表示4张mnist图片,h w都是28,channel为1 tensor_4d = torch.rand(4,1,28,28) # 使用和tensor_4d相同的随机方式和维度定义tensor_4d_2 tensor_4d_2 = torch.rand_like(tensor_4d) # 看tensor_4d有多少元素 print(torch.numel(tensor_4d))
设置默认Tensor类型:(在某个场景需要使用高精度double)
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch torch.set_default_tensor_type(torch.DoubleTensor) a = torch.Tensor([1.1,2.2]) print(a.type()) # 输出torch.DoubleTensor
生成同元素的矩阵:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch # 生成一个元素全是7.0的2*3矩阵 a = torch.full([2,3],7.) print(a) # 生成一个元素全是7.0的2维向量 b = torch.full([2],7.) print(b) # 生成值为7.0的标量 c = torch.full([],7.) print(c)
arange、linspace和logspace:
# linspace将[0,10]等分,steps表示数量(非步长) aa = torch.linspace(0,10,steps=4) print(aa) # 打印tensor([0.0000, 3.3333, 6.6667, 10.0000]) bb = torch.linspace(0,10,steps=10) print(bb) # 将[0,1]分成10个数n,算base的n次方 cc = torch.logspace(0,1,steps=10,base=2) print(cc) # 输出tensor([1.0000, 1.0801, ... ,2.0000]) dd = torch.logspace(0,-1,steps=10) print(dd) # [0,10)之间等差数列,step为步长 ee = torch.arange(0,10,step=2) print(ee) # 输出tensor([0,2,4,6,8])
生成全一矩阵,零矩阵,单位矩阵:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch # 3*3全一矩阵 a = torch.ones(3,3) # 生成一个shape和a一样的全一矩阵 a_2 = torch.ones_like(a) # 3*3零矩阵 b = torch.zeros(3,3) # 生成一个shape和a一样的零矩阵 b_2 = torch.zeros_like(a) # 3*3单位矩阵 c = torch.eye(3,3) # 或torch.eye(3) # 如果不是方阵,会自动填充0,不会报错 d = torch.eye(3,4) d_2 = torch.eye(4,3)
使用随机种子来完成shuffle:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.rand(10, 3) b = torch.rand(10, 2) print('a:', a) print('b:', b) # 产生一个随机顺序的index向量,根据需要shuffle的实际数据的维度 idx = torch.randperm(10) print('idx:', idx) # 这里输出的是[0,10)的一维向量,顺序是乱的 # 用同一个随机种子做shuffle,如果需要shuffle顺序不同,则需要产生不同的idx a = a[idx] # 相当于做了shuffle b = b[idx] # 相当于做了shuffle print('a after shuffle:', a) print('b after shuffle:', b)
索引和切片:
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch import numpy as np a = torch.rand(4, 3, 32, 32) # 基本索引(和numpy类似) print(a[2][1][15][15]) print(a[2, 1, 15, 15]) # 切片索引(和numpy类似) print(a[:2, :-1, 3:6, 7:9].size()) print(a[:1, :, :, :].size()) # 带步长的切片索引(和numpy类似) print(a[:, :2, :18:2, ::3].shape) # 指定某一个维度截取,例如取0,1和第3张图片 print(a.index_select(0, torch.tensor([0, 1, 3])).size()) # 取所有图片,但只取0和2个channel print(a.index_select(1, torch.tensor([0, 2])).size()) # 取图片的上半部分 print(a.index_select(2, torch.arange(0, 14)).size()) # 取图片的右半部分 print(a.index_select(3, torch.arange(14, 28)).size()) # 使用...来方便取值 print(a[0, ...].size()) print(a[:, :2, ...].size()) print(a[..., :13, :].size()) # 使用mask来取值 b = torch.randn(5, 5) # 大于0.5的位置为1,小于0.5的位置为0 mask = b.ge(0.5) print(mask.type()) # type为ByteTensor # 得到的b_seleted是一个向量,和b的维度没有关系 b_seleted = torch.masked_select(b, mask) print(b_seleted.size()) # 输出torch.Size(7),根据b中数据大于0.5的元素个数 # 对flatten以后的数据按index取值(不常用) token = torch.take(b, torch.tensor([2, 6, 13, 22, 24])) print(token.size()) # 输出torch.Size(5)
六、维度变换
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.rand(4, 1, 28, 28) a_1 = a.view(4, 784) print(a_1.size()) a_2 = a.view(4, 1, 28, 28) print(a_2.size()) a_3 = a.view(4 * 1 * 28, 28) print(a_3.size()) # 尽量不要这样转,因为乱转维度可能破坏数据的几何特性 a_4 = a.view(4, 28, 28, 1) print(a_4.size())
七、squeeze和unsqueeze
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch ## 添加维度 src1 = torch.rand(4,1,28,28) # 在size的index=0的位置插入一个维度,比如理解为batch,每个batch有4张图片 b = src1.unsqueeze(0) print(b.size()) # 输出torch.Size([1, 4, 1, 28, 28]) # 在size的最后一个位置插入一个维度 c = src1.unsqueeze(-1) print(c.size()) # 输出torch.Size([4, 1, 28, 28, 1]) ##======================================## ## 删除维度 src2 = torch.rand(1,32,3,1) # 删除所有可以删除的维度 d = src2.squeeze() print(d.size()) # 删除第一个维度 e = src2.squeeze(0) print(e.size()) # 删除最后一个维度 f = src2.squeeze(-1) print(f.size())
八、expand和repeat
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch src = torch.rand(4, 32, 14, 14) b = torch.rand(1, 32, 1, 1) ### 使用expand来扩展维度 ### 注意,被扩展的维度只能是1-->n,而不能是m-->n。数据会自动复制 # 将c扩展为torch.Size([4,32,14,14]) c = b.expand(4, 32, 14, 14) # 将c扩展为和src一样的维度 d = b.expand_as(src) print(c.size()) print(c) print(d.size()) print(d) # 只指定需要扩展的维度,其他维度不动可以填-1 e = b.expand(4, -1, -1, -1) print(e.size()) # 输出torch.Size([4,32,1,1]) ##====================================## ## 使用repeat来扩展维度 # repeat的参数不是代表扩展后的维度,而是分别需要复制多少次 f = b.repeat(4, 1, 14, 14) print(f.size()) # 扩展后的维度为torch.Size([4,32,14,14])
九、转置和transpose
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.rand(3, 4) # a的转置 a_t = a.t() print(a_t.size()) ### 使用transpose交换维度 # 假设b代表4张mnist图片,维度分别代表B,C,H,W b = torch.rand(4, 1, 28, 28) # 将b的C和W维度交换,得到的维度为B,W,H,C b_trans = b.transpose(1, 3) print(b_trans.size()) # 输出torch.Size([4,28,28,1]) # 在交换维度后,需要随时用contiguous()来将数据重新归为连续状态 c = torch.rand(4, 3, 32, 32) # 交换维度,然后使之连续,然后调整维度,然后再交换回来,看c和d是否一致 d = c.transpose(1, 3).contiguous().view(4, 32, 32, 3).transpose(1, 3) # 如果输出为1,则表示c和d数据相同 print(torch.all(torch.eq(c, d))) ### 使用permute()直接调整所有维度的顺序 # 将维度变为H,W,C,B e = c.permute(2,3,1,0) print(e.size())
十、broadcasting广播
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch # 假设得到一个feature map,维度为4,64,20,20(B,C,H,W) fm = torch.zeros(4, 64, 20, 20) print(fm.type()) # 要为每一个channel加上一个bias(每个channel对应一个卷积核的结果) bias = torch.arange(64) # 将LongTensor转换为FloatTensor bias = bias.type(torch.FloatTensor) print(bias.size()) # 我们要给每个channel对应的4张20*20的feature map的所有元素加上bias # 首先我们要从最小(最小范围)的维度开始扩展 bias = bias.unsqueeze(-1).unsqueeze(-1) print(bias.size()) # 在fm的channel后面有H和W两个维度,所以我们在bias后面添加两个维度 # 然后使用broadcasting res = fm+bias print(res.size()) print(res)
十一、矩阵拼接
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch ### 使用concat拼接矩阵 a = torch.rand(3, 4) b = torch.rand(5, 4) # 对行拼接,即3行+5行=8行。类似于excel中条目累加 ab_cat = torch.cat([a, b, ], dim=0) print(ab_cat.size()) # 输出torch.Size([8,4]) c = torch.rand(4, 5) d = torch.rand(4, 6) # 对列拼接,即5列+6列=11列。类似于excel中不同字段拼接 cd_cat = torch.cat([c, d], dim=1) print(cd_cat.size()) # 输出torch.Size([4,11]) # 在googLenet中对于Inception的拼接,是按channel进行拼接的 res_conv3 = torch.rand(4, 64, 28, 28) res_conv1 = torch.rand(4, 128, 28, 28) res = torch.cat([res_conv3, res_conv1], 1) print(res.size()) # 输出torch.Size([4,192,28,28]) ### 使用stack组合两个矩阵 aa = torch.rand(32, 8) bb = torch.rand(32, 8) # 将两个矩阵组合起来,并且在指定位置创建新维度 # 可以理解为两张图片组成一个batch,而不是两张图片拼在一起 ac_stack = torch.stack([aa, bb], dim=0) print(ac_stack.size()) # 输出torch.Size([2,32,8])
十二、矩阵拆分
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch ### 使用split拆分矩阵 a = torch.rand(2, 32, 8) # 平均拆分 a1, a2 = a.split(1, dim=0) print(a1.size()) # torch.Size([1,32,8]) b = torch.rand(7, 32, 8) # 按个数拆分 b1, b2, b3 = b.split([3, 3, 1], dim=0) print(b1.size()) # torch.Size([3,32,8]) ### 使用chunk拆分矩阵 c = torch.rand(8, 32, 8) # 将c拆分在dim=0上拆分为两半 c1, c2 = c.chunk(2, dim=0) print(c1.size()) # 拆分为4份 c3, c4, c5, c6 = c.chunk(4, dim=0) print(c3.size()) # 拆分为3份,3+3+2 c7, c8, c9 = c.chunk(3, dim=0) print(c7.size(), c8.size(), c9.size())
十三、基本运算
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.rand(3, 4) b = torch.rand(4) ### 基本运算 # a+b broadcasting ab_sum1 = a + b ab_sum2 = torch.add(a, b) print(torch.all(ab_sum1.eq(ab_sum2))) # a-b broadcasting ab_sub1 = a - b ab_sub2 = torch.sub(a, b) print(torch.all(ab_sub1.eq(ab_sub2))) # a*b broadcasting ab_mul1 = a * b ab_mul2 = torch.mul(a, b) print(torch.all(ab_mul1.eq(ab_mul2))) # a/b broadcasting ab_div1 = a / b # 整除用// ab_div2 = torch.div(a, b) print(torch.all(ab_div1.eq(ab_div2))) ### 矩阵乘法 c = torch.rand(2, 3) d = torch.rand(3, 4) # 矩阵乘法的三种方式,推荐第二种,即matmul()和第三种@ cd_mm1 = torch.mm(c, d) cd_mm2 = torch.matmul(c, d) cd_mm3 = c @ d print(torch.all(cd_mm1.eq(cd_mm2))) print(torch.all(cd_mm2.eq(cd_mm3))) ### 超过二维的矩阵乘法 e = torch.rand(4, 3, 28, 64) f = torch.rand(4, 3, 64, 32) # 只针对最后两维做乘法,前面的两维至少要满足能够broadcasting ef_mm = e @ f print(ef_mm.size()) # 输出torch.Size([4,3,28,32]) g = torch.rand(4, 1, 64, 32) # 这里的第二个维度使用了broadcasting eg_mm = e @ g print(eg_mm.size()) # 输出torch.Size([4,3,28,32]) ### 错误示范 # h = torch.rand(4, 64, 32) # # 由于无法执行broadcast,报错 # eh_mm = e @ h # print(eh_mm.size()) aa = torch.full([3, 3], 10) ### N次方 # 使用以下两种方式计算N次方 print(aa.pow(2)) print(aa ** 3) ### 平方根 print(aa.sqrt()) # 平方根的倒数 print(aa.rsqrt()) # 开三次方 print(aa ** (1 / 3)) ### exp bb = torch.exp(aa) print(bb) ### log a_log10 = torch.log10(aa) a_log2 = torch.log2(aa) b_log = torch.log(bb) # 以e为底 print(a_log10) print(a_log2) print(b_log) ### 向上向下取整 aaa = torch.randn(2, 3) a_floor = aaa.floor() # 向下取整 a_ceil = aaa.ceil() # 向上取整 print(a_floor) print(a_ceil) ### 截取整数和小数 a_trunc = aaa.trunc() # 截取整数部分 a_frac = aaa.frac() # 截取小数部分 print(a_trunc) print(a_frac) ### 四舍五入 a_round = aaa.round() print(a_round) ### 最大值最小值,中值,平均 grad = torch.randn(2, 3) * 15 print(grad) print(grad.max()) # 最大值 print(grad.min()) # 最小值 print(grad.mean()) # 平均值 print(grad.median()) # 中间值 print(grad.prod()) # 所有元素累乘 print(grad.sum()) #所有元素求和 # 将小于10的数全部置为5,大于5的数不变 print(grad.clamp(5)) # 将数值全部限定在0-10范围,大于10的取10,小于0的取0. print(grad.clamp(0, 10))
十四、范数
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch ### 范数norm a = torch.ones(8) b = torch.ones(2, 4) c = torch.ones(2, 2, 2) print(a.norm(1), b.norm(1), c.norm(1)) # 8,8,8 print(a.norm(2), b.norm(2), c.norm(2)) # 2.8284,2.8284,2.8284 # 指定在哪一维上做norm # 在b的dim=1上做L1范数 print(b.norm(1, dim=1)) # [4,4] print(b.norm(2, dim=1)) # [2,2] print(c.norm(1, dim=0)) # [[2,2],[2,2]] print(c.norm(2, dim=0)) # [[1.4142,1.4142],[1.4142,1.4142]]
十五、argmax和argmin
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.arange(12) idx = torch.randperm(12) a = a[idx] a = a.view(3, 4).type(torch.float32) print(a) # 不带参数的argmax和argmin会把矩阵压平来返回index print(a.argmax()) print(a.argmin()) # 如果想要在某个维度上使用argmax和argmin # 返回每一列上最大值的index组成的向量,维度等于行的维度 print(a.argmax(dim=0)) # 获取每一列的最大值组成的向量,以及对应index组成的向量 print(a.max(dim=0)) # 返回每一行上最小值的index组成的向量,维度等于列的维度 print(a.argmin(dim=1)) # 获取每一行的最小值组成的向量,以及对应index组成的向量 print(a.min(dim=1)) ### keepdim # 返回的不是一个向量,返回保持是矩阵[3,4]--->[3,1],而不是[3] print(a.max(dim=1, keepdim=True).values.size()) # torch.Size([3,1]) ### 获取topk # 获取最大top2,[3,4]--->[3,2] print(a.topk(2, dim=1)) # 获取最小top3,[3,4]--->[3,3] print(a.topk(3, dim=1, largest=False)) ### 获取第n小 # 获取每行第3小的数及index print(a.kthvalue(3, dim=1)) # 获取每列第2小的数及index print(a.kthvalue(2, dim=0))
十六、矩阵比较
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch a = torch.randn(3, 4) print(a) # 大于,满足的位置为1,不满足的位置为0 print(a > 0) print(torch.gt(a, 0)) # 大于等于,同上 print(a >= 0) print(torch.ge(a, 0)) # 小于,同上 print(a < 0) print(torch.lt(a, 0)) # 小于等于,同上 print(a <= 0) print(torch.le(a, 0)) # 不等于,同上 print(a != 0) # 等于,同上 print(a == 0) print(torch.eq(a, a)) # 判断是否一样,和上面的不一样 print(torch.equal(a, a)) # 输出True(和前面不一样)
十七、高级操作where gather
# -*- coding:utf-8 -*- __author__ = 'Leo.Z' import torch ### 高级操作where,可以实现高度并行的赋值 a = torch.tensor([[1, 2], [3, 4]]) b = torch.tensor([[5, 6], [7, 8]]) # 我们使用一个condition矩阵来决定取a和b中的哪些值来组成c cond = torch.ByteTensor([[0, 1], [1, 0]]) # 通过cond来选择每一个元素从a还是b中获得,1表示a,0表示b c = torch.where(cond, a, b) print(c) # 还可以这样用 cond2 = torch.rand(2, 2) c2 = torch.where(cond2 > 0.5, a, b) print(c2) ### 高级操作gather,实现查表 # 假设33是dog,44是cat,55是fish table = torch.tensor([33, 44, 55]) # 假设我有一个向量,所有元素都是0,1,2。对应table中dim=0的3个index find_list = torch.tensor([2, 1, 2, 0, 0, 1, 2]) found_in_table = torch.gather(table, dim=0, index=find_list) print(found_in_table) # 输出tensor([55,44,55,33,33,44,55]) # 也可以是多维的 table2 = torch.rand(4, 10) find_list2 = torch.randint(0, 10, [4, 5]) # 在每一行中获取5个index对应的值 found_in_table2 = torch.gather(table2, dim=1, index=find_list2) print(found_in_table2) # 输出一个4*5的矩阵,其中的值都来自于table2