强化学习之Sarsa算法最简单的实现代码-(环境:“CliffWalking-v0“悬崖问题)
1、算法简介
直接上伪代码:

伪代码解释:
第一行:①设置动作空间A和状态空间S,以后你agent只能执行这A中有的动作,你环境的状态也就S中这么些;
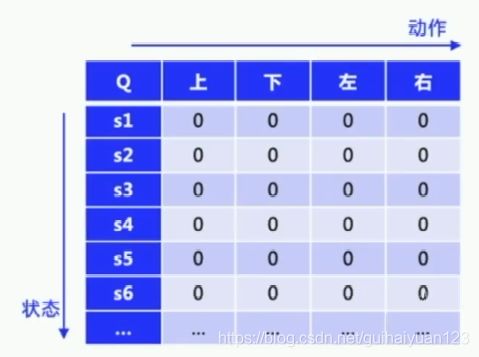
②初始化Q表格,也就是表格的横坐标为动作,纵坐标为状态,每个格子里面的值表示:纵坐标对应的状态s下,执行横坐标对应的动作a,后环境反馈回来的奖励值r(注意啊,这个奖励值先开是都初始化为0啥的,然后不断的episode,这整个表不断的更新,不断的确定哪个状态执行哪个动作奖励是多少,宏观上就是agent不断的确定,不断的强化,比如在这个状态,我该执行哪个动作,强化到最后,我就知道我不管在哪个状态,我都知道,我在这个当前状态我该干啥,强化,强化,强化重要的事说。。。直接点题强化学习,哈哈。。);
③如果当前处在终止状态terminal-state下,(你这个都终止状态了,达到目标了,或者坏了,跑出范围了,摔倒了,也不可能给终止状态上施加啥动作,所以不能有动作啊),此时奖励值r都设置为0;
第二行:不断的循环重复回合episode,不断的训练,一次回合就是环境重置,导演说各就各位,场景开始什么样还原成开始的样子,agent刚开始在哪啥状态姿势,回到刚开始那样,然后就是开始这个回合,agent开始和环境交互搞啊搞,直到到达终止状态;
第三行:它这个初始化状态S不是让你把状态空间S重新初始化一个新的,而是每次回合你都把环境搞乱了,现在要开始新的一个回合,你得把前一个回合搞乱的环境重置一下啊,重新各就各位一下,你这不让它各就各位,那agent每次都在学一个新的环境,回合起始学习的环境是上个环境遗留下来的终止环境,这学个毛线啊吗。说白了,就是 env.reset()。
第四行:在状态为s情况下,我要从Q表中选一个动作a执行到环境中,我采用的是(ε-greedy) ε贪婪策略,这个策略设置一个概率比如0.1。我现在采用这个策略的话,我有0.9的概率是直接从Q表中选取状态s对应的这一行,执行哪个动作给的奖励最高,我就选哪个动作(如果有多个动作给的奖励都是最高,那么我随机选这里面的一个动作a就成);有0.1的概率是随机从动作空间A中挑选动作a,用得到的动作a施加到环境中,那么施加完,环境就会从现在的状态s,转换到状态s'。
第五行:这个episode前面两行该准备的准备完了,现在执行这个episode,直到环境反馈回来的状态为终止状态terminal-state,就终止这个回合episode,否则一直循环,也就是agent不断的和环境进行交互,不断的学习。
第六行:在环境状态为s时,给环境施加一个动作a,得到环境的反馈,下一个状态s'和奖励r(这行代码体现的就是智能体与环境之间的交互)。
第七行:根据第六行,环境返回回来的下个状态s',我们再次使用(ε-greedy) ε贪婪策略,获得环境在下个状态s',要执行的s'上的动作a'(也就下一个要执行动作)。
第八行:这个就是数学公式的伪代码,到过程中就是,你现在要更新的Q表了,要更新Q表中的Q(s, a)这个格子中的奖励值,你首先先取出这个格子中老的Q(s, a)值,然后取出Q(s', a')这个格子中的奖励值,然后根据公式,直接算出新的Q(s, a)这个格子奖励值该是啥。这个α(alpha)就是用于软更新soft update的,类似机器学习中的学习率;这个γ(gamma)就是折扣因子。
第九行:都往前走一步,状态变为下一个装填s',动作变为下一个动作a'
第十行:当此时这个新的状态是终止状态时,我直接停止这轮回合。
代码:使用悬崖问题中最简单的模型"CliffWalking-v0"作为环境,其中o表示能走的路地;C表示悬崖;T表示终点;智能体agent用x表示,x从左下角起始位置,要走到终点T,进入悬崖、出界、终点都是终止状态。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import numpy as np
import gym
class SarsaAgent(object):
def __init__(self, obs_n, act_n, learning_rate=0.01, gamma=0.9, e_greedy=0.1):
self.act_n = act_n # 动作的维度, 有几个动作可选
self.lr = learning_rate # 学习率
self.gamma = gamma # 折扣因子,reward的衰减率
self.epsilon = e_greedy # 按一定的概率随机选动作
self.Q = np.zeros((obs_n, act_n)) # 创建一个Q表格
# 根据输入观察值(这个代码不区分state和observation),采样输出的动作值
def sample(self, obs):
if np.random.uniform(0, 1) < (1.0 - self.epsilon): # 根据table的Q值选动作
action = self.predict(obs) # 调用函数获得要在该观察值(或状态)条件下要执行的动作
else:
action = np.random.choice(self.act_n) # e_greedy概率直接从动作空间中随机选取一个动作
return action
# 根据输入的观察值,预测输出的动作值
def predict(self, obs):
Q_list = self.Q[obs, :] # 从Q表中选取状态(或观察值)对应的那一行
maxQ = np.max(Q_list) # 获取这一行最大的Q值,可能出现多个相同的最大值
action_list = np.where(Q_list == maxQ)[0] # np.where(条件)功能是筛选出满足条件的元素的坐标
action = np.random.choice(action_list) # 这里尤其如果最大值出现了多次,随机取一个最大值对应的动作就成
return action
# 给环境作用一个动作后,对环境的所有反馈进行学习,也就是用环境反馈的结果来更新Q-table
def learn(self, obs, action, reward, next_obs, next_action, done):
"""
on-policy
obs:交互前的obs, 这里observation和state通用,也就是公式或者伪代码码中的s_t
action: 本次交互选择的动作, 也就是公式或者伪代码中的a_t
reward: 本次与环境交互后的奖励, 也就是公式或者伪代码中的r
next_obs: 本次交互环境返回的下一个状态,也就是s_t+1
next_action: 根据当前的Q表,针对next_obs会选择的动作,a_t+1
done: 回合episode是否结束
"""
predict_Q = self.Q[obs, action]
if done:
target_Q = reward # 如果到达终止状态, 没有下一个状态了,直接把奖励赋值给target_Q
else:
target_Q = reward + self.gamma * self.Q[next_obs, next_action] # 这两行代码直接看伪代码或者公式
self.Q[obs, action] = predict_Q + self.lr * (target_Q - predict_Q) # 修正q
def run_episode(env, agent, render=False):
total_steps = 0 # 记录每一个回合episode走了多少step
total_reward = 0 # 记录一个episode获得总奖励
obs = env.reset() # 重置环境,重新开始新的一轮(episode)
action = agent.sample(obs) # 根据算法选择一个动作,采用ε-贪婪算法选取动作
while True:
next_obs, reward, done, info = env.step(action) # 与环境进行一次交互,即把动作action作用到环境,并得到环境的反馈
next_action = agent.sample(next_obs) # 根据获得的下一个状态,执行ε-贪婪算法后,获得下一个动作
# 训练Sarsa算法, 更新Q表格
agent.learn(obs, action, reward, next_obs, next_action, done)
action = next_action
obs = next_obs # 存储上一个观测值(这里状态和观测不区分,正常observation是state的一部分)
total_reward += reward
total_steps += 1
if render:
env.render() # 重新画一份效果图
if done: # 如果达到了终止状态,则回合结束,跳出该轮循环
break
return total_reward, total_steps
def test_episode(env, agent):
total_reward = 0
obs = env.reset()
while True:
action = agent.predict(obs) # greedy
next_obs, reward, done, info = env.step(action)
total_reward += reward
obs = next_obs
time.sleep(0.5)
env.render()
if done:
print('test reward = %.lf' % (total_reward))
def main():
env = gym.make("CliffWalking-v0") # 悬崖边行走游戏,动作空间及其表示为:0 up , 1 right, 2 down, 3 left
agent = SarsaAgent(
obs_n=env.observation_space.n,
act_n=env.action_space.n,
learning_rate=0.1,
gamma=0.9,
e_greedy=0.1)
is_render = False
for episode in range(500):
ep_reward, ep_steps = run_episode(env, agent, is_render)
print('Episode %s: steps = %s, reward = %.lf' % (episode, ep_steps, ep_reward))
# 每隔20个episode渲染一下看看效果
if episode % 20 == 0:
is_render = True
else:
is_render = False
# 训练结束,查看算法效果
test_episode(env, agent)
if __name__ == '__main__':
main()
,