IS 2022 | 字节AI Lab联合南科大提出:利用伪标注数据提升端到端S2ST
原文链接:https://www.techbeat.net/article-info?id=4010
作者: 岳凤鹏
互联网的极速发展使得世界各地可以更加紧密地进行商务及日常交流,然而语言不通使得这样的交流产生了壁垒。 机器翻译的研究致力于打破不同语言使用者交流的壁垒,追求更流畅的沟通。文本翻译一直是机器翻译的主要工作方向,然而现在的信息表达方式更加多样化,单纯文本的翻译难以满足多样化的场景需求。语音是人类日常交流中的主要信息载体,语音到语音的翻译 (Speech-to-speech Translation, S2ST) 可以帮助人们更加自然高效地交流。在很多场景下,语音到语音的翻译可以提升交流体验感,例如:视频直播、国外旅游、国际贸易等。

论文地址:
https://arxiv.org/pdf/2205.08993.pdf
代码地址:
https://github.com/fengpeng-yue/speech-to-speech-translation
一、端到端语音到语音翻译的现状以及挑战
语音到语音翻译可以有两种实现方式,一种是级联语音识别、机器翻译以及语音合成系统;另一种是端到端的方案:采用一个模型直接把一种语言的语音翻译合成为另一种语言的语音。相比于级联的方案,端到端的研究起步比较晚,并在近些年被Jia等人正式提出并验证可行,该工作被称为Translatotron[1]。之后,Translatotron2[2]被提出以便提高预测语音的鲁棒性,并在翻译中保留源说话者的音色。另一方面,Lee提出在目标语音上采用离散单元 (discrete units)表示的方法[3],旨在为没有文字的语言构建直接的S2ST系统。该方法不再预测连续的频谱图,而是预测从目标语音的自监督表示中学习的离散单元。文本数据可以在多任务学习框架下被使用,也可以不使用。此外,Lee等人提出了一种无文本 S2ST 系统[4],可以在没有任何文本数据的情况下进行训练。同时,它首次尝试了采用真实世界的 S2ST 数据进行训练来生成多说话人目标语音。
端到端的系统往往有更低的延时,同时能缓解级联系统中的误差累计问题。相比于级联系统,数据量不足是端到端系统面临的最大挑战之一。利用伪标注数据在深度学习领域是一种十分有效的提升模型性能的方法,本文将为大家介绍一篇由字节跳动 AI-Lab 与南方科技大学共同发表在 InterSpeech 2022 上的文章 ——Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation[5]。
二、伪标注数据的使用方法
随着工业和学术界的不断积累,语音识别的开源数据量越来越多。我们可以将开源的语音识别数据中的文本经过机器翻译系统翻译到目标语言,再将目标语言的文本经过语音合成系统合成到目标语音,以此来构造伪标注的语音到语音的翻译数据集。为了缓解端到端语音到语音翻译数据量不足的问题,本文探索了三种利用伪标注数据 (Pseudo Translation Labeling,PTL) 的方法:1、Pre-training and Fine-tuning,2、Mixed-tuning,3、Prompt-tuning。
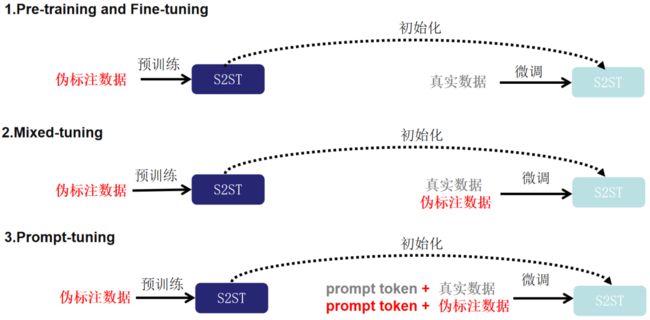
1. Pre-training and Fine-tuning
在这个方法中,论文利用伪标注数据首先预训练一个端到端的语音到语音翻译的模型。然后利用真实数据在这个模型上进行微调。
2. Mixed-tuning
相比于Pre-training and Fine-tuning,在微调阶段除了采用真实数据,论文使用真实数据和伪标注数据一起微调模型。
3. Prompt-tuning
为了增强模型学习各种数据源之间差异的能力,论文采用“预训练、提示和预测”[6]范式。在预训练的基础上,将数据集的类别作为prompt,并在提示调整阶段以预定义embedding的形式将其附加到每个样本的输入特征中。通过明确的prompt,其可以在推理阶段操纵模型适应不同源的数据。
三、实验设置及性能分析
数据构造
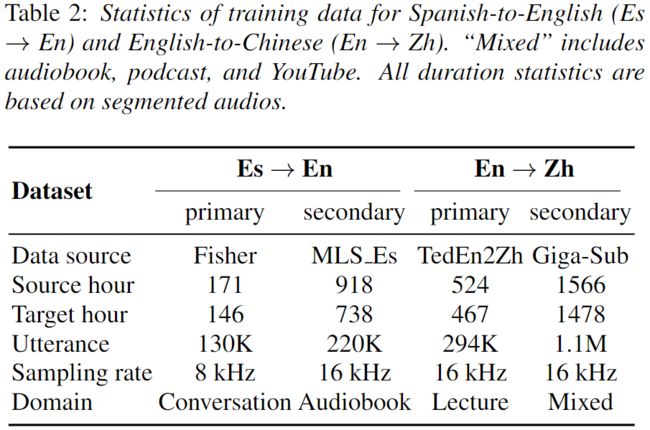
论文中对西班牙语到英语 (Es->En) 和英语到中文 (En-Zh) 两个语言对进行了实验。前者属于同一个语系,而后者属于不同的语系。文中基于两个Speech-to-text Translation (ST) 数据集:Fisher Spanish[7]和TedEn2Zh[8],使用内部语音合成系统从翻译文本中合成目标语音来构造Speech-to-speech Translation (S2ST) 数据集。同时,论文采用语音识别数据集Gigaspeech[9]和multilingual LibriSpeech[10]中的西班牙语数据构造伪标注数据。其统计信息如下:
模型性能
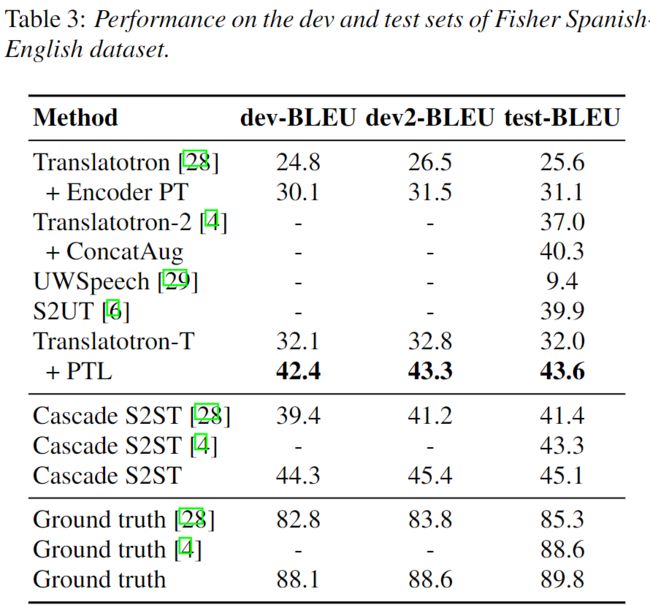
其论文采用了Transformer-based Translatotron的模型结构,并对参数进行了细致调优。在一个性能表现良好的baseline上,论文中的方法对不同语种BLEU评测都得到了有效的提升。在Fisher数据上其方法超过了之前报告的众多方法。
方法比较
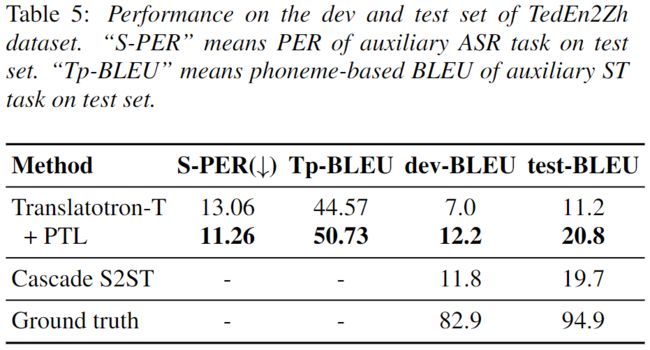
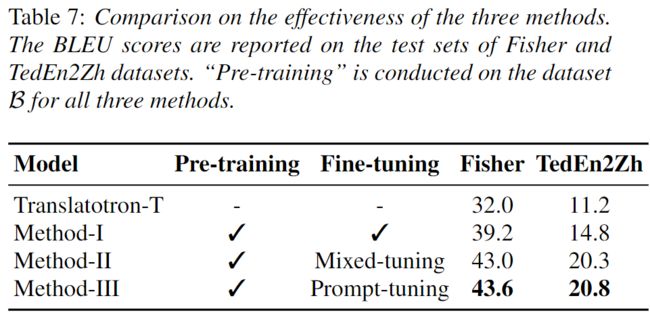
论文中比较了上述三种利用伪标注方法。当通过伪标记数据 (Method-I) 将预训练应用于S2ST时,与基线相比,BLEU分数显著提高。此外,基于预训练,mix-tuning (Method-II) 在Fisher上提高了2.8 BLEU,在TedEn2Zh上提高了5.5 BLEU。如下表所示,两种语言对中的原始数据和伪标注数据存在明显的不匹配。Prompt-tuning (Method-III) 帮助模型区分不同的数据源,并且可以在两种语言对上获得进一步的收益。
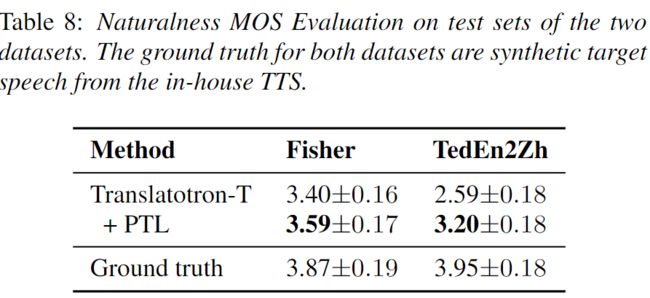
主观评测
为了进行人工评测,论文中使用Hifi-GAN[9]声码器从预测的频谱图合成音频,并进行Mean Opinion Score (MOS) 测试以评估音频的自然度。PTL的方法在MOS上的收益与BLEU一致。同时,PTL方法显著提高了TedEn2Zh数据集上音频的可理解性。
四、总结
今天为大家介绍了InterSpeech 2022上关于利用伪标注数据提升端到端S2ST的论文。该工作尝试采用了三种不同的方式利用伪标注数据,最终prompt-tuning是最为有效的。实验表明,模型的BLEU和MOS评测性能都得到了显著提升。
参考文献
[1]. Jia, Ye and Weiss, Ron J and Biadsy, Fadi and Macherey, Wolfgang and Johnson, Melvin and Chen, Zhifeng and Wu, Yonghui, “Direct Speech-to-Speech Translation with a Sequence-to-Sequence Model,” in Proc. Interspeech 2019, 2019, pp. 1123–1127.
[2]. Jia, Ye and Ramanovich, Michelle Tadmor and Remez, Tal and Pomerantz, Roi. Translatotron 2: Robust direct speech-to-speech translation arXiv preprint arXiv:2107.08661, 2021.
[3]. Lee, Ann and Chen, Peng-Jen and Wang, Changhan and Gu, Jiatao and Ma, Xutai and Polyak, Adam and Adi, Yossi and He, Qing and Tang, Yun and Pino, Juan et al., “Direct speech-to-speech translation with discrete units,” arXiv preprint arXiv:2107.05604, 2021.
[4]. Lee, Ann and Gong, Hongyu and Duquenne, Paul-Ambroise and Schwenk, Holger and Chen, Peng-Jen and Wang, Changhan and Popuri, Sravya and Pino, Juan and Gu, Jiatao and Hsu, Wei-Ning,. Textless speech-to-speech translation on real data,” arXiv preprint arXiv:2112.08352, 2021
[5]. Qianqian Dong and Fengpeng Yue, Tom ko and Mingxuan Wang, Qibing Bai and Yu Zhang. “Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation”, arXiv preprint arXiv:2205.08993, 2022.
[6]. Liu, Pengfei and Yuan, Weizhe and Fu, Jinlan and Jiang, Zhengbao and Hayashi, Hiroaki and Neubig, Graham. “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” arXiv preprint arXiv:2107.13586, 2021
[7]. Post, Matt and Kumar, Gaurav and Lopez, Adam and Karakos, Damianos and Callison-Burch, Chris and Khudanpur, Sanjeev. “Improved speech-to-text translation with the fisher and callhome spanish-english speech translation corpus,” in Proceedings of the 10th International Workshop on Spoken Language Translation: Papers, 2013.
[8]. Liu, Yuchen and Xiong, Hao and Zhang, Jiajun and He, Zhongjun and Wu, Hua and Wang, Haifeng and Zong, Chengqing. “End-to-end speech translation with knowledge distil-
lation,” Proc. Interspeech 2019, pp. 1128–1132, 2019.
[9]. Kong, Jungil and Kim, Jaehyeon and Bae, Jaekyoung. “Hifi-gan: Generative adversarial net-
works for efficient and high fidelity speech synthesis,” Advances in Neural Information Processing Systems, vol. 33, pp. 17 022–17 033, 2020.
Illustration by Dani Grapevine from icons8
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: