Event causality extraction based on connectives analysis
Event causality extraction based on connectives analysis
Sendong Zhao, Ting Liu, Sicheng Zhao, Yiheng Chen, Jian-Yun Nieb
School of Computer Science and Technology, Harbin Institute of Technology, ChinabDepartment of Computer Science, Université de Montréal, Canada

精简总结
本文提出了一种基于受限制的隐藏朴素贝叶斯模型,用于提取文本中的因果关系。除此之外提出了一个因果连接的新特征,来自包含连接词的句子的树核相似性。最后在公共数据集上进行了实验,表明本文的方法超越了所有基线。
一、Introduction
自然语言文本中提供了大量因果关系。例如,句子“财务压力是离婚的主要原因”表达了因果关系。从文本中提取因果关系可用于许多任务,例如事件检测和预测[1],生成未来场景[2,3]和回答问题[4]。知识。
本文旨在将因果关系作为一种知识进行挖掘。因果关系通常由言语和非言语的交往模式(例如,cause,lead to,because of)或词汇句法模式引起。在上面的示例中,因果关系由术语“cause of”引起。
已经做出了许多努力来从文本中提取因果关系[4,2,5,6]。类似于其他关系的提取(例如,is-a [7],part-of [8]),先前的因果关系提取方法分为两类:基于模式的方法,包括词汇-句法模式,语义关系模式,自构造了基于机器学习的约束和方法。这些方法中的大多数都严重依赖于知识库,例如Wikipedia,WordNet。但是,他们很少在句子的句法结构中考虑因果联系引起因果关系的方式,这对因果关系提取很重要。结果,他们在没有知识基础的因果关系提取方面表现不佳。
通常,我们的工作基于两个观察结果。一方面,一些因果联系词在表达因果关系上表现出相似性,例如“增加”和“减少”。另一方面,给定因果关系的话,句子的形成可以部分确定,并且在给定语法树的情况下,每个节点的位置可以在一定程度上确定。因此,我们使用了连接类别的新功能来对第一个观测值进行编码,并使用RHNB对第二个观测值进行建模。

从表1中的示例可以看出,因果对可以由不同的因果连接词引起。在示例1和2中,因果对都是(财务压力,离婚)。但是,这两个因果对的连接是不同的。因此,这两个例子的句法依存结构是不同的。因果关系句的表达因果关系的句子的句法依存结构也有所不同。换句话说,每个因果关系词都有其表达因果关系的方式。但是,大多数因果关系词并没有表达因果关系的独特方法。因果关系词经常被用来引起因果关系,例如“增加”和“减少”。因此,我们建议将因果关系词根据其引起因果关系的方式分为不同的类别。这样做的目的是充分利用可能属于同一类别的相似因果连接词实例的协作过滤。
除了因果连接词的分类外,还有许多其他功能可以为因果关系提取提供有用的线索。我们将包括上下文特征,句法特征和位置特征。基于这些特征,可以将因果关系提取作为因果关系对的几个候选者之间的分类。然而,在先前的研究中,通常假定这些特征是独立的,而实际情况并非如此。例如,连接词的类别和句法特征(请参阅下文)可能具有很强的交互性,即它们传达相似的信息。为了解决要素之间可能存在的相互作用,我们提出了一种新的受限隐性朴素贝叶斯(RHNB)模型来提取因果关系,尤其是RHNBmodel不仅具有学习特征之间的隐秘关系的特性,而且还可以避免在隐性朴素贝叶斯上关系学习的过拟合问题。
在本文中,我们开发了一种新颖的因果关系提取方法。贡献可总结如下:
- 通过使用表达因果关系的句法依存结构的相似性,将因果关系词分为不同的类别,从而显着改善因果关系的提取
- 我们提出了一种RHNB模型,该模型能够应对特征之间的相互作用。尤其是,应付因果连接词和词汇句法模式之间相互作用的能力可以极大地改善因果关系的提取。
在本文的其余部分安排如下。我们首先讨论相关工作。然后,讨论了英语中的因果关系表达。然后,我们介绍了因果关系提取的新方法,然后详细描述了我们的实验和结果。最后,本文的结论与未来工作。
二、Related work
事件因果关系提取是一项基本任务,因为事件之间的因果关系可以在许多应用程序中使用。因果关系是预测未来的重要原则。为了预测未来事件,参考文献[1]从大型新闻语料库中提取了事件之间的因果关系。同样,参考文献[3]提出了一种从网络中提取事件因果关系以生成未来场景的监督方法。因果关系也是回答问题的重要资源。参考文献[4]在包含(61%精度)和不包含(36%精度)因果关系模块的问题回答系统上进行了测试。文献[9]探讨了术语或从句之间的句内和句间因果关系的效用,以此来更好地回答问题的原因。
其他作者提出了一些有关因果关系的自动提取和检测的方法。我们提出的方法与以前的研究之间的主要区别可以归纳如下:
- 我们的方法使用了一种新的连接类别特征,该特征是从句子的树核相似性获得的。
- 我们的方法编码特征之间的部分影响。例如,因果连接词通常决定句子的句法结构以及因果关系在句子中的相对位置。
对于事件因果关系的提取和检测,先前方法使用的线索可以粗略地分类为词汇语法模式[10,1],上下文中的单词[9],单词之间的关联[2,11]以及谓词和名词的语义[12, 13]。除了具有与上述特征相似的特征外,我们还提出了一种新的连接类别特征,该特征是从包含因果连接词的句子的树核相似性中获得的。
除[4]以外,所有上述研究仅着重于精度而不是召回者F对其表现的评价。换句话说,这种因果关系对不能在其语料库的任何单个句子中以合理的精度获得。有一些研究不仅针对精度,而且还针对召回,例如[4,14,6,5]。这些因果关系提取研究中通常使用的模型是SVM,决策树等,它们都关注F-sore。半监督方法。然而,以前研究中使用的所有这些方法很少考虑特征之间的交互作用对因果关系提取的影响,特别是结缔特征和词汇句法特征之间的交互作用,这被我们的实验证实是非常有效的。
关于关系提取[15-17]和话语关系识别[18-20]的研究很多 。关系提取的研究通常集中于提取命名实体之间的关系,这与因果关系提取不同。因果关系通常是指事件之间的关系。
三、Expression of causality
在过去的三十年中,语言学家和哲学家进行了大量研究,重点放在因果关系上,尤其是在因果关系的语义学和句法方面。本节介绍用英语表达因果关系的主要方法。这里,我们使用[21]提出的因果关系类别。在大多数情况下,因果关系是由显式因果关系词引起的。参考文献[21]定义了八类显式因果关系词,并分析了它们在LOB语料库中的频率。在兰开斯特大学。详细信息如表2所示。
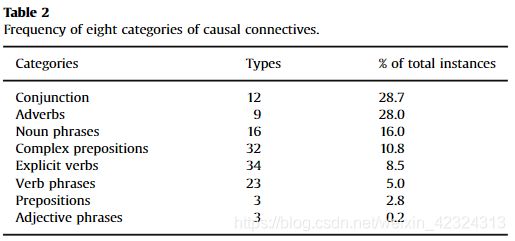
显性连接词所表达的因果关系是一种因果关系,其中因果关系由诸如“cause”,“effect”和“because of”的因果关系所引起。示例2的句子“Finacial stress”是连接词的名义主题,“increases”是“divorce”的直接连接对象。在这个例子中,我们可以看到因果关系表达背后有很强的句法依赖。"Finace stress"和结果事件"divorce"有一个相同的父亲节点,它是连接词”increases“。父子关系分别为“ nsubj”(名义客体)和“ dobj”(直接客体)。该示例可能表明因果关系通常以某些典型的句法模式表达。确实,许多先前的研究严重依赖于这种模式来确定因果关系。例如,参考文献[5]和[6]都使用这种句法结构来检测因果关系。如果因果关系以典型的结构表示,例如“(.*)increase(.*)”,“(.*)cause(.*)”,则它们表现良好。
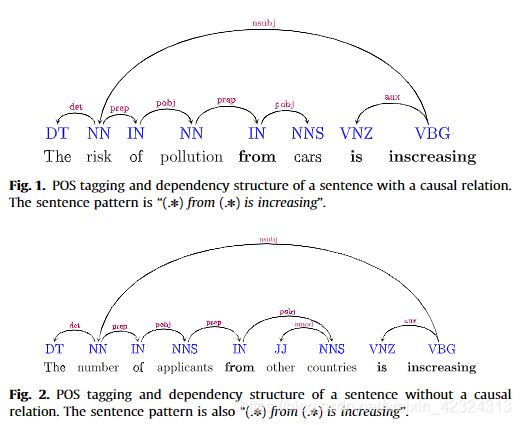
但是,因果关系也可以用其他不太典型的结构表示。例如,图2和3中的两个句子。 1和2具有共同的句法结构“(.*)from(.*)is increasing”。但是,它们的语义关系不同。 [5]和citeIttoo:2013的方法将无法区分案例。为了解决此问题,我们使用了其他上下文特征。语境特征包括因果词。除了以上例子外还有“risk of”和“number of”。直观地,第一组单词可能暗示句子中的因果关系。还将包括其他几种类型的特征。
当使用许多特征时,它们经常是交互的。为了应对这种相互作用,我们使用RHNB模型来学习上下文特征[22]和连接类别之间的关系。
Our method
我们工作的输入是几个没有注解的句子,输出是被确定为因果关系的成对短语。因果关系抽取的过程是为每个句子提取一些候选对,然后确定哪个是因果关系。在本研究中,将因果关系提取转换为二分类[23]框架。
在本节中,我们详细介绍了使用RHNB模型从每个句子中提取因果关系对的方法。我们将因果关系提取视为分类问题。因此,我们应该使用基于某些有用特征的机器学习模型来提取因果对。一方面,除了一些常用的特征,我们提出了因果连接词的一些新的有用的分类特征。因果连接词的新类别特征是从表达因果关系的句子的句法依存结构的相似性获得的。另一方面,我们提出了一个新的RHNB模型来应对特征之间的相互作用,特别是因果连接词和句子的句法模式之间的相互作用。这是影响我们方法性能的关键因素。以下部分将阐明我们方法的这两个优点。
在这项工作中,我们使用一些功能来训练RHNB模型。表3说明了用于训练RHNB的详细特征。我们选择26个特征模板的列表,这些模板分为四个类别:上下文特征,句法特征,位置特征和连接特征。

- 上下文特征:用于区分具有相同或相似句法结构的对的不同语义关系,就像图1和2的情况一样。参考文献[11]还指出,为了更好地预测因果关系,似乎需要更多的上下文知识。
- 句法特征:揭示了句子的不同部分之间的句法关系,这对于识别句子的哪些部分代表因果对事件非常重要。文献[24]证明了句法特征可以改善歧义,消除歧义。
- 位置特征:反映了连接词的位置以及事件与连接词之间的距离。许多其他研究也普遍使用这种功能[14]
- 连接特征:是从连接分析得出的特征。我们发现,某些因果联系词具有与引起因果关系相似的方式,这对于因果关系提取很有意义。因此,我们建议将因果联系词根据其引起因果关系的方式分为不同的类别。这样做的目的是充分利用具有相似因果连接词(可能属于同一类别)的实例的协作过滤。
4.1 因果联系类别
在本节中,我们将因果连接词根据涉及这些因果连接词的句子的依存关系结构划分为不同的类。因果关系词经常以相似的方式引起因果关系。因此,我们建议将因果连接词分为不同的类别。这样做的目的是充分利用因果连接词在同一类别中的实例的协同过滤。例如,在训练集中具有连接性c1的一个实例 I1和在测试集中具有一个连接性c2的另一个实例I2。I1可用于监督从I2ifc1和c2进行的因果关系提取。我们使用卷积树核方法[25]计算涉及因果连接词的两个句子之间的相似度,然后利用这种相似度将因果连接词划分为不同的类。在这里,树核方法被用来测量两个句子的句法结构的相似性。树核方法的思想是计算两个解析树相同子结构的数量。我们将两个因果连接词的相似性定义为句子的两组的平均相似度,这两个句子涉及两个因果连接词。正式定义如下:
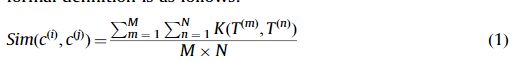
其中ci和cj分别表示因果连接词和因果联系词。Tm和Tn是核函数,用于测量同一子树的句子的依存关系树的相似度:

Tmsub是树Tm的子树,Tnsub是树Tn的子树。
为了将训练数据的因果联系词划分为不同的类别,根据联系者Sim(ci, cj)的相似性,使用了两级K均值-层次混合聚类方法[26]。两级K均值分层混合聚类方法的一个优点是可以自动确定簇的数量。然后,我们使用因果连接词的类别作为表3中所示的功能。
4.2 Restricted Hidden Naive Bays
由于要强调特征之间的关系,尤其是句子的因果联系和句法结构之间的关系,因此在本节中我们使用贝叶斯模型从文本中提取因果关系。具体来说,我们提出了限制隐藏式朴素贝叶斯,这是对隐藏式朴素贝叶斯(HNB)的改进[27]。 RHNB继承了朴素贝叶斯的结构简单性,无需结构学习即可轻松学习。
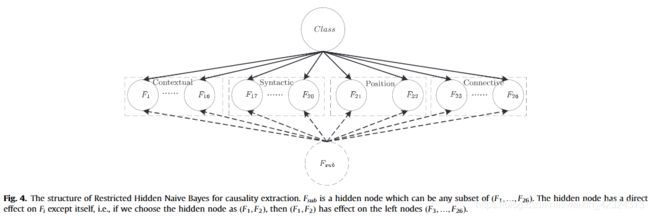
HNB的基本思想是为每个特征创建一个隐藏的父级,该父级结合了除自身以外的所有其他特征的影响。 图3给出了HNB的结构。在图3,Class是类节点,并且还是所有要素节点的父级。每个功能都有一个隐藏的父结点Fhi,i=1, 2, …;,n,以虚线圆圈表示。从隐藏的父结点Fhi到Fi的边也由虚线表示,以将其与规则边缘区分开。 Fhi到Fi的边缘编码除Fi以外的所有特征的影响。

HNB为每个要素创建一个隐藏的父级,该父级结合了所有其他要素的关系。换句话说,HNB假定每个功能都可以受所有其他功能的影响,并从其他功能中了解所有影响。实际上,并非所有功能都有相互作用。因此,假设所有特征都具有相互影响的假设很容易导致训练数据集规模较小时的过度拟合问题[28]。通常,这种关系学习可以学习一些错误关系或嘈杂关系以及正确的关系[29–31]。这会在影响测试集上的性能。因此,我们提出了RHNB,通过限制特征之间的关系来解决HNB在关系学习中的过拟合问题。我们提出的RHNB模型的优点是,我们假设部分功能具有相互作用,但并非所有功能都具有相互作用。这种假设可以避免学习错误或嘈杂的特征之间的某些相互作用。
图4给出了因果关系提取的RHNB的结构。在图4,Class是类节点,也是所有要素节点的父级。从F1到F26的特征分为上下文,句法,位置和连接性四个组。每个要素都有一个相同的隐藏父Fsub,由虚线圆表示。隐藏父Fsub到Fi的弧线也由虚线表示,以将其与常规弧区分开.Fsub是特征模板集(F1, …,F26)的子集。 Fsub可以是任何上下文特征,句法特征,位置特征和连接特征的组合。如果我们将Fsub视为整个特征模板集(F1,…,F26)。 RHNB模型将退化为HNB模型。
Fsub在Fi的作用定义如下:
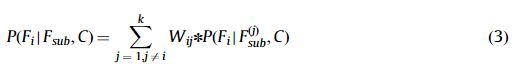
其中C表示实例的类别,Wij是从Fjsub到Fi的边的权重。Wij定义如下:

Wij是每个从隐藏结点Fsub连接的真实影响值。如果wij为0,则影响为0。Ip(Fi;Fjsub|C)是有条件的共同信息,在参考文献[32]中提出:
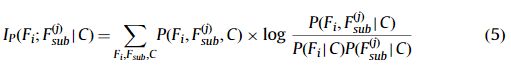
我们利用RHNB和表3中所示的功能从文本中提取因果关系。将分类器RHNB应用于实例I=(f1, …,f26),以确定事件对是否为因果关系:

确定了RHNB的结构。因此,学习RHNB非常简单,主要需要根据训练数据估计RHNB中的参数。 RHNB的参数学习算法描述为Algorithm1。

RHNB的参数学习算法分为四个步骤。首先,我们应该从训练集D计算C类中的每一个值P(C)。然后,我们应该从训练集D中为每个特征Fi和Fjsub计算出P(Fi|C)P(Fjsub|C)。然后,我们应该为每个功能Fi和Fjsub计算Ip(Fi;Fjsub|C)。最后,我们应该为Fjsub和Fi计算每个边的Wij。经过这个过程,我们可以获得RHNB模型中的所有参数。
五、Experimental evaluation
进行了广泛的实验,以验证该方法的有效性。在本节中,我们将描述实验设计并报告结果,以证明我们提取因果关系的方法的优势。
5.1 数据集
语料库由2682个句子组成,其中一半包含因果关系。为了进行评估,我们将所有2682个句子随机分成训练/验证/测试集,比率为8:1:1。第一个用于模型训练,第二个用于对基线方法(如SVM)进行超参数调整,第三个用于评估。这些语料库是通过扩展SemEval-2010-Task8数据集的注释而获得的。在原始数据集中,每个句子中只有一个或两个单词被注释为原因或结果。我们将因果词扩展为短语。例如,将原始数据集中的注释“ The < e1> burst has been caused by water hammer < e2> pressure < e2>“ 修改为“The < e1> burst has been caused by < e2> water hammer pressure < e2>”,其效果被更完整的语义”unitwater hammer pressure“所代替。
5.2 预处理
在处理句子的过程中,我们应用词法化并使用配对工具来执行词性标注和依赖解析[33]。在大多数情况下,因果对的原因和结果不是单个单词,而是一个短语。例如,“heart and lung disease”是“smoking”的一种效应,可以从“Smoking can cause many types of heart and lungdisease”中提取。我们还发现,这些出现的原因或结果的短语总是以名词短语(NPs)的形式出现。因此,为了检测这些NPs作为可能是因果事件的语义单元,我们运行了部分解析器[34],将句子中的NP识别为候选者。
5.3 基线
我们使用[6]和[5]方法作为基线。参考文献[6]使用事件对之间的词汇句法模式提取了因果对。这些模式是通过采用一些因果对评估的自举方法从Wikipedia上的句子中获得的。我们根据训练数据调整了这些模式。参考文献[5]仅在某些词汇语法特征和自构约束条件下使用SVM分类器来提取公共数据集上的因果对。他们在与我们相同的数据集上测试了其因果对,但他们将单字组或二元组识别为因果关系事件,这与我们的方法不同。为了进行比较,我们在他们的方法中添加了短语提取模块。由于我们使用的是SemEval-2010-Task8数据集,因此我们希望将我们的结果与通过最佳系统在SemEval上获得的结果进行比较。 UTD系统[14]获得了SemEval-2010的最佳性能。但是,UTD系统并没有提取句子的因果对,而只是预测每个句子的唯一标记单词对是否为因果对。这意味着对于每个句子,都有一个唯一的标记对要针对UTD系统进行预测。在因果关系抽取的存在性中,每个句子中都有一个以上的事件候选对。而且,UTD系统使用多个外部知识库进行关系分类,例如WordNet,NomLex-Plus,VerbNet和Google N-Gram数据。同时,没有详细介绍UTD的方法。因此,我们认为以UTD为基准是不合适的。
5.4 实施细节
我们没有调整K值。我们使用两级K均值分层混合聚类方法,其中Kis是自动确定的。 SVM中使用RBF内核。为了获得最好的超参数C和r,我们在验证集上进行了网格搜索,并使用它们来获得测试集的结果。
5.5 结果与分析
我们对因果关系从文本中进行了几种比较。通常,有三种类型的比较。一个是在表4上显示的相同数据集上的方法与先前方法之间的比较,一个是在表5上所示的相同数据集上使用我们的特征的分类器之间的比较,另一个是在不同特征和特征的不同用法之间的比较,分别如表6-8所示。赵等。 / Neurocomputing 173(2016)1943–19501947

5.5.1 结果
图4表明我们的方法在所有三个指标上均优于先前的方法。我们对方法的改进进行了显着性检验(t-test)。结果表明,改进具有统计学意义(p-value<0.05)。一方面,与[5]和[6]相比我们的方法使用了更有意义的特征。参考文献[5]仅使用了词汇句法特征和一些自我-构造规则。文献[6]仅在自举框架中对词汇句法模式进行编码。另一方面,我们的RHNB模型比SVM中使用的SVM具有更强大的能力来应对功能之间的影响。考虑特征之间的相互作用,特别是上下文,句法特征与位置和连接特征之间的相互作用,是我们方法的优势。具体来说,表示因果关系因果关系变化的句子的句法依存结构。例如,因果连接词的类别会影响句子的依存结构。通常,描述具有不同连接词的相同因果关系的句子可能需要不同的结构。表1中显示的示例说明了这种现象。
5.5.2 分析
基于表3中的特征,我们在训练集上训练了基于朴素贝叶斯,支持向量机,随机森林,HNB和RHNB的几种模型。我们可以观察到在从表5提取因果关系时不同分类器之间的性能比较。从表5可以得出结论,我们考虑特征之间的关系越多,可以获得的性能就越好。但是,当我们假设每个功能都可能受所有其他功能(即HNB的假设)影响时,性能将比假设每个功能可能会受其他功能的一部分(即RHNB的假设)影响的性能差。从这个意义上说,特征之间的局部关系假设要好于特征之间的完整关系假设(p-valueo0.05)。换句话说,HNB与RHNB(Fsub = Syntactic+Connectiv)的比较表明,RHNB可以避免HNB在关系学习中的过度拟合问题。
在表6,我们进行了六次实验,把Fsub分别设置为NULL,Contextual,Syntactic,Position,Connective和Syntactic+Connective。RHNB(Fsub=NULL)表示RHNB的隐藏结点为null,此时RHNB模型退化为HNB模型。

此外,从结果可以看出,当把Fsub设置成Syntactic+Connective时,RHNB获得最佳结果。比较结果表明RHNB(Fsub=Syntactic+Connective)中的最佳F分数。句法功能对于定位原因事件和结果事件非常有用。具体来说,不同的句法结构通常会影响POS标记,位置和连接词。不同的连接词通常会产生不同的句子句法结构。例如,“lead to”触发的句子句法树中因果事件的位置通常不同于“since”触发的句子的句法树。
表3给出了两种类别特征。为了比较这两种类别的有效性,我们进行了实验,如表7所示。提取时,我们进行以下健全性检查:(1)Fsub设置为Syntactic+Category并得到结果;(2)从Fsub删除“ Fang’s类别”,并记录P,R和F的减少量; (3)从Fsub中删除“Tree Kernel based Category”,并记录P,R和F的减少量;最后,得到表7。
尽管从表6的比较中可以看出每种特征对因果关系提取的贡献,但贡献并不纯。这是因为贡献还包含要素之间的交互作用。因此,为了评估每种功能的重要性,我们还通过分别删除上下文功能,连接功能,句法功能和位置功能来比较朴素贝叶斯分类器。与其他模型相比,朴素贝叶斯分类器未考虑要素之间的关系。因此,评估表3中四种功能的重要性是一个很好的模型。表8中的“Naive Bayes with ALL”表示着我们使用所有四种特征实现N朴素贝叶斯模型。表8中的比较表明,这四种特征对于因果关系提取都很重要。但是,影响结果的重要性不同。通过比较,位置特征是最重要的。如果我们不使用连接特征,那么结果会比随机猜测要好一些。语法特征是第二重要的。先前的研究已经对这两种功能进行了广泛的讨论。如果不使用上下文特征,它将使Fscore降低6.5%。如果不使用位置特征,将使Fscore降低0.6%。因此,上下文特征和位置特征对于提高因果关系提取的性能也很有用。
六、Conclusion
在本文中,我们提出了一个RHNB模型,通过使用一些有用的功能(包括上下文功能,句法功能,位置功能和连接功能)从文本中提取因果关系。一方面,我们使用了一些新功能来提取因果关系。特别是,我们利用表达因果关系的句子的句法依存结构的相似性,将因果关系词划分为不同的类别。首次使用树核方法学习并由[21]提出的连接器类别,以提高因果关系提取的性能。另一方面,我们提出了一种基于HNB的新模型(RHNB),该模型不仅继承了特征之间的关系学习能力,而且避免了HNB的特征之间的关系学习过度拟合的问题。特别是,RHNB具有处理因果联系词和句法句型之间相互作用的能力,被证明是改善因果关系提取的有效线索。对公开可用数据集的评估证明了我们的因果关系提取方法的优势。因果关系抽取是一项基本任务。因此,除了要改善因果关系抽取之外,还有许多有意义的任务需要我们去做,例如产生新的因果假设,产生情景等。同时,因果关系提取及其应用研究充满了挑战,包括文本中因果关系的可信度,反事实因果关系等,需要引起重视。