ICCV 2021 Oral | 姿态估计——零基础看懂RLE
最近ICCV 2021上有一项姿态识别领域非常厉害的工作,它就是今天要介绍的残差似然估计(Residual Log-likelihood Estimation)。其工作的核心在于,通过flow方法,估计出模型输出关节的分布概率密度。一旦估计出令人满意的先验分布函数,就能动态优化损失函数loss,从而促进模型的回归训练。
从结果上讲,该论文也交出了一份令人满意的答卷:有史以来第一次,回归关节坐标的方法比高斯热图方法取得了更好的效果,而且,回归方法还能保持更快、更轻。(For the first time, regression based methods achieve superior performance to the heatmap-based methods, and it's more computation and storage efficient.)
通过flow方法,估计出模型输出关节的分布概率密度。一旦估计出令人满意的先验分布函数,就能动态优化损失函数loss,从而促进模型的回归训练。
然而,对于没有太多这方面基础知识的同学而言,这段话可能有点不好理解,脑子里也会很快地跳出几个问题:
1、为什么要估计关节的概率密度函数?有什么好处?
2、估计出来关节的概率密度分布和我损失函数又有什么关系?
3、为什么要用所谓的flow方法来估计概率密度函数,说到底什么是flow方法?
4、这个残差Residual又是起什么作用的?
没关系,这篇文章的目的就是用尽量简单的语言,从零开始,来一一解答上面的几个小问题。
一、概率密度分布,损失函数与最大似然估计
1、为什么要估计关节的概率密度函数?
2、估计出来关节的概率密度分布和我损失函数又有什么关系?
先拿一个简单的问题问大家:你们有没有想过,为什么平时我们第一印象上总喜欢用均方误差作为回归的损失函数?
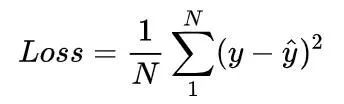
可能有人说,因为均方误差衡量了距离,也有人会说均方误差衡量了目标在预测周围的集中程度,这都有其直觉上的道理。但数学上讲,这其实是和一种常见而重要的概率分布联系在一起的,那就是高斯分布。我们默认用均方误差作为损失函数,其实就是因为高斯分布在自然界中比较常见,而且有较好的性质,所以我们默认要预测的变量服从高斯分布。
是的,如果我们有一个想要预测的变量y,那么变量y的分布情况影响了我们要采用的损失函数。如果y是高斯分布的变量,我们会倾向采用均方误差(l2 loss)来衡量。如果y是拉普拉斯分布的变量,我们会倾向采用绝对值误差来衡量(l1 loss),不一而足。
可是概率分布和损失函数到底是怎么对应上的呢?为什么高斯用l2 loss,拉普拉斯就用l1 loss呢?这就要讲到小标题“最大似然估计,概率密度分布与损失函数”中的第三个词,也就是“最大似然估计”了,正是最大似然估计,将loss和概率密度联系在了一起。
这一段将由变量的高斯分布,推导出一个结论:均方误差
![]()
是最大似然法下的损失函数
![]()
。假设我们要用线性函数
![]()
预测y,而我们事先知道 y 被高斯噪声
![]()
影响 ,那么真实情况下 y 被加性噪声影响的表达式为
![]()
,把噪声单独放在等式一边则有
![]()
。可以看出y也就服从均值为
![]()
,方差为
![]()
高斯分布:  ,展开来写作:
,展开来写作:
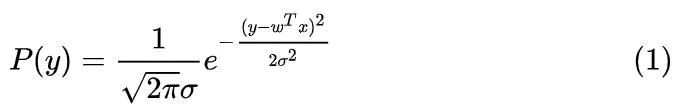
那么我们在得到了一系列的样本
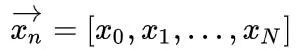
以及

之后,对
![]()
取对数得到对数似然函数
![]()
。而最大似然估计的定义就是:找到合适的参数 ω ,让我们刚刚得到的对数似然函数
![]()
最大。写作:
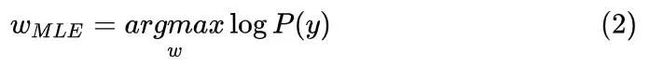
这里的MLE是最大似然估计(Maximum likelihood estimation)的英文简写.带入y的高斯分布表达式(式子1)有
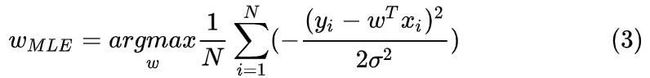
用最大似然估计得到参数w后,现在我们来看损失函数。损失函数的定义就是:找到一个
![]()
,当参数w使真实值
![]()
和预测值
![]()
越接近时,它就越小。写作:
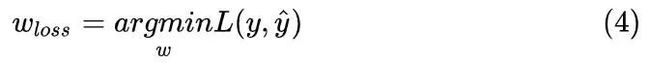
写出用最大似然估计(3)和损失函数(4)优化出的参数 ω ,放在一起对比一下:
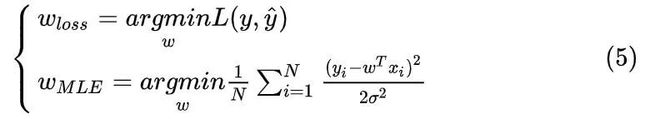
观察两式argmin的右端,画上等号,我们就得到了用最大似然估计法给出的损失函数,终于也就得到了我们的均方值误差!
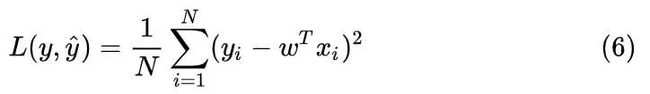
这就解答了为什么 y 服从高斯分布时,损失函数推荐采用均方值误差。通过这种手段,概率分布,最大似然估计和损失函数就联系在一起啦。
用MLE来估计概率密度:flow方法
经过了第一阶段的学习,我们现在知道了很重要的一点,那就是只有在预先知道目标变量分布的情况下,我们才可以更好地构建损失函数,来完成模型参数的学习。
那么问题来了,人体的关节 y ,它是怎样一个分布情况呢?更具体一点讲,我们真正关心的其实是:当我们的标注
![]()
不可能做到完美无误的情况下,它在真实关节点周围是以一种什么样的概率分布出现的呢?因为只有知道了这种偏差
![]()
的概率密度分布函数,我们在回归的时候,才能够建立起恰当的损失函数,来帮助模型更高效地学习。
那么问题来了,我们怎么得到标记与真实值之间偏差
![]()
的概率密度分布呢?这就用到所谓的flow方法了。
问题3,为什么要用所谓的flow方法来估计概率密度函数,说到底什么是flow方法?
问起怎么逼近一个概率密度分布?这个问题大家可能会一头雾水。但如果问题是怎么逼近一个函数
![]()
,这大家肯定是再熟悉不过了。“要逼近一个函数时,为什么不问问神奇的神经网络呢”
通用近似定理:在人工神经网络的数学理论中, 通用近似定理(或称万能近似定理)指出人工神经网络近似任意函数的能力[1]。此定理意味着神经网络可以用来近似任意的复杂函数,并且可以达到任意近似精准度。(wiki百科)
我们现在可以用神经网络估计任意函数
![]()
,那么怎么利用这个特性,来估计出一个概率密度
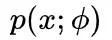
呢?很简单,答案就是去估计一个简单分布
![]()
到目标分布
![]()
的映射函数
![]()
。例如,把待映射的简单分布
![]()
设成高斯分布,再通过神经网络得到映射函数
![]()
。最后,把拟合的映射函数
![]()
带入简单分布
![]()
,我们就可以得到目标分布
![]()
了。
即由这两个式子:
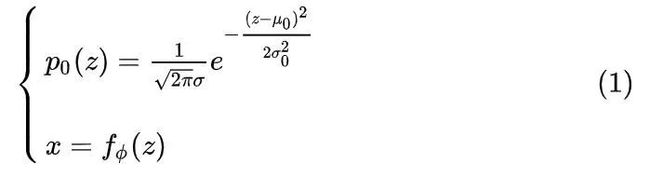
得到目标分布  。而由概率论里“随机变量函数的概率分布”一节类比知,将式子(2)代到式子(1)的时候,不仅带入
。而由概率论里“随机变量函数的概率分布”一节类比知,将式子(2)代到式子(1)的时候,不仅带入
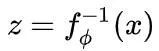
,还要乘上雅可比行列式

, 以对应于一维情况

。
因此有:
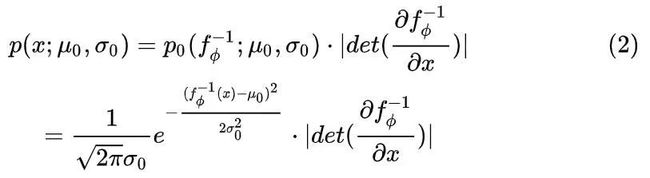
用最大似然估计法,取目标分布的似然函数
![]()
,就得到了论文中的式子(4). 对应本文的式子2的第一行看一下,是不是一模一样呢?

(论文中
![]()
代表测试集中的样本,
![]()
代表我们上面提到的待映射的简单分布
![]()
,我这里是为了具象化说明,所以用高斯分布作为简单分布的例子)
这就是用flow方法来估计概率密度分布的核心思想。至于为什么叫“flow”,因为事实上为了计算雅可比行列式的方便,我们对映射函数
![]()
会进行一系列的链式分解。这个链子的形状就是flow一词的来源。
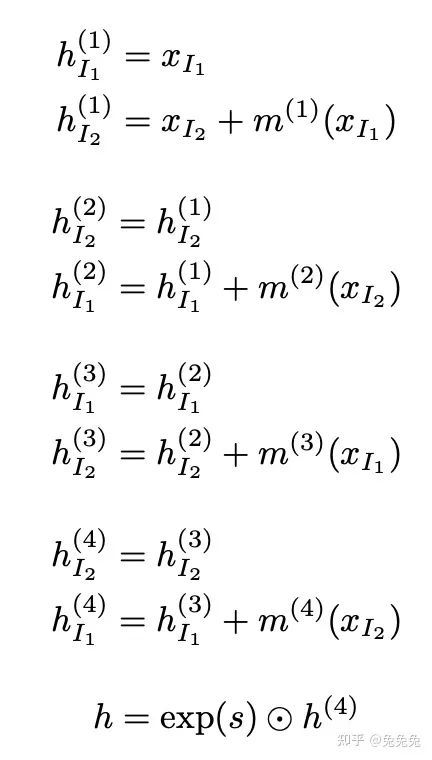
流形的计算式,这就是flow一词的来源
三、RLE与flow的异与同
现在,将图片和坐标作为训练集,通过flow方法不断学习,我们可以得到关节坐标在图片上的分布y了。
能力范围:估计出关节点  的分布函数。
的分布函数。
但是,不要忘记了我们的目标,我们想估计出标注在真实值周围的分布情况,来计算损失函数,而不是关节坐标本身。
目标:在标注不完美的情况下,最好估计出标注
![]()
偏离真实值 y 的偏差
![]()
的分布
那怎么估计出这个差值
![]()
的分布呢?我们反向思考一下
假如这个差值
![]()
的分布形式已知,它会怎么影响最终的结果?
现在, 假装我们已经求出来了差值的分布形式
![]()
,它均值为零,方差为单位一。现在将这个误差作用到通过图片回归出来的坐标
![]()
上。怎么个作用法呢?我们采用最最朴实无华的作用方式:因为差值分布的方差是标准化的,我们将它先乘一个拉伸量
![]()
,再加到回归的坐标
![]()
上:
![]()
就完成了偏差之于坐标的作用过程。
因此,要反过来估计差值分布
![]()
,我们只需要有:
-
坐标值

的回归模型
-
拉伸系数
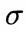
的回归模型
就可以用flow方法,求的差值
![]()
的分布啦!这对应于论文中的下图:
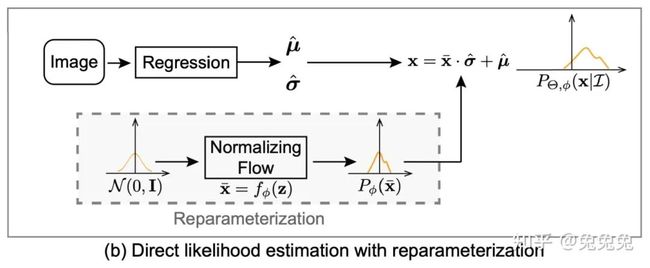
论文中的  对应于本文的误差分布函数
对应于本文的误差分布函数 ![]() ,论文中的
,论文中的  对应于本文的回归坐标
对应于本文的回归坐标  ,论文的
,论文的  对应于本文的拉伸系数
对应于本文的拉伸系数  。
。
通过建立回归模型回归出对应值,再通过flow模型估计分布,至此,我们就完成了我们的最高目标了:
在标注不完美的情况下,最好估计出标注 ![]() 偏离真实值 y 的偏差
偏离真实值 y 的偏差 ![]() 的分布
的分布
那么是不是到这里就结束了?其实还有最后一个问题,这个RLE(Residual Log-likelihood Estimation)中的R (Residual) 在哪里体现呢?原来,为了更快地逼近理想结果,我们不去直接估计目标分布 ![]() ,而是选择去估计目标分布与原始分布(e.g. 高斯分布)的残差
,而是选择去估计目标分布与原始分布(e.g. 高斯分布)的残差
![]()
,记作
![]()
。但分布不能直接除,因此引入中间因子 s 使得残差过程成立:
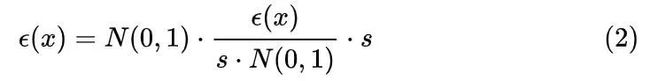
取对数得到似然函数:

这就对应于文章中的公式六:
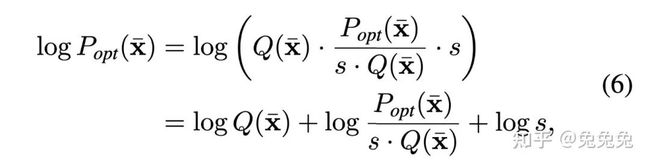
论文中
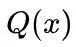
代表某个简单的分布,作用是和残差项结合,以快速逼近目标分布。
![]()
代表误差的最佳估计,对应于上文的
![]()
。
到这里,论文的核心思想才真正结束。
四、总结
最后对本文来一个小小的总结吧:
-
第一部分:通过经典的最大似然估计法,简单解释了概率分布之于损失函数的重要作用
-
第二部分:利用flow方法,让神经网络有能力拟合一个概率分布函数。
-
第三部分:完成了终极目标:标注偏差

的估计。并通过残差模块,让网络的训练过程更快更平滑。
作者:兔兔兔
|关于深延科技|
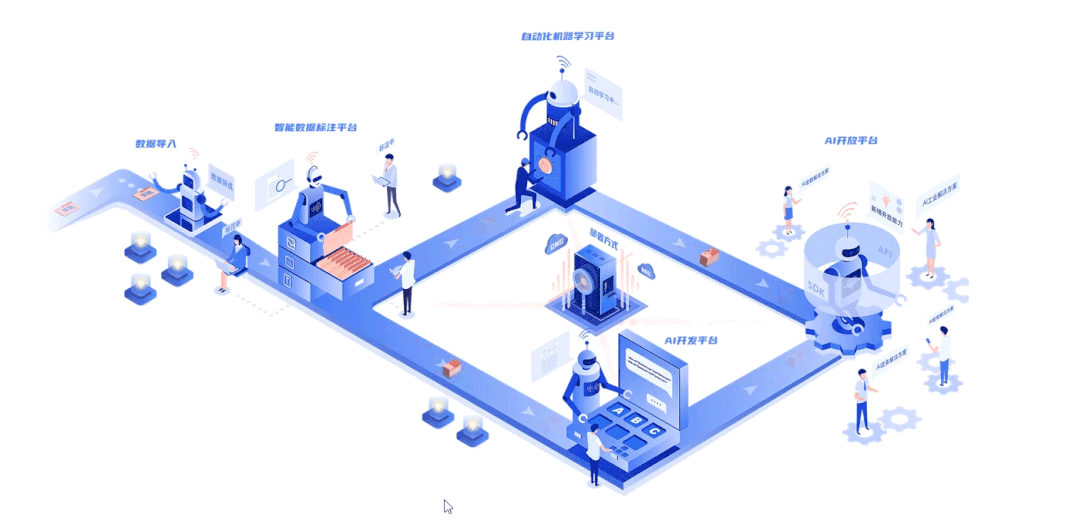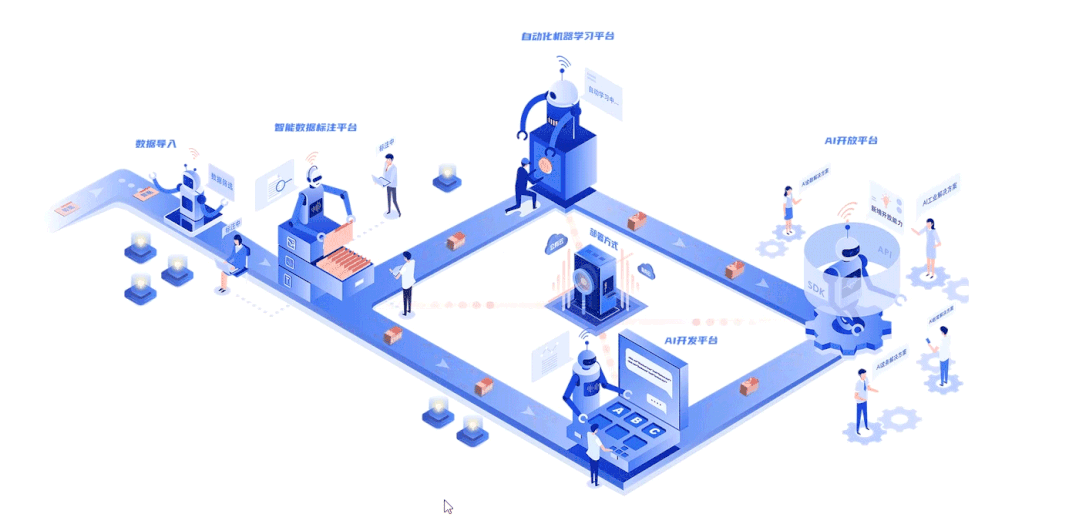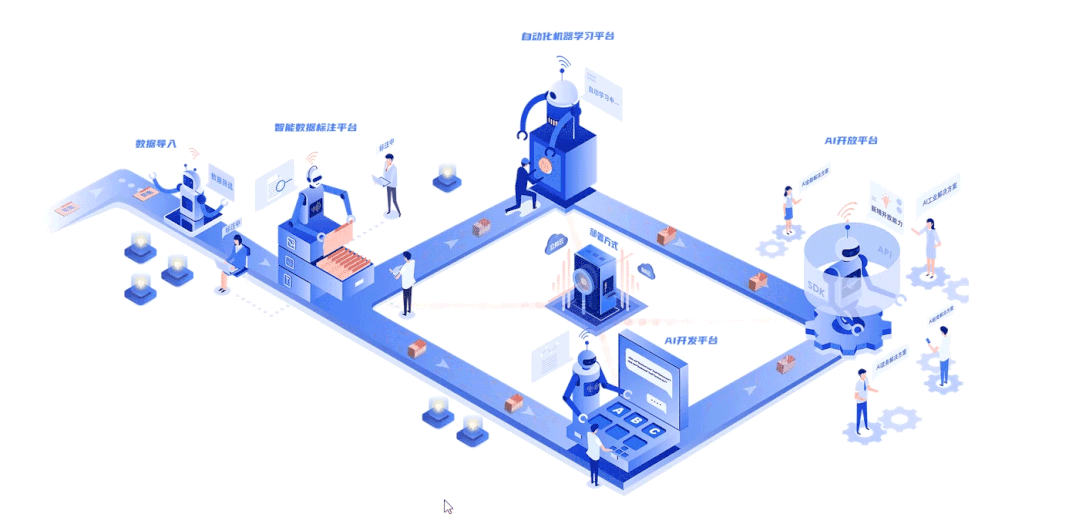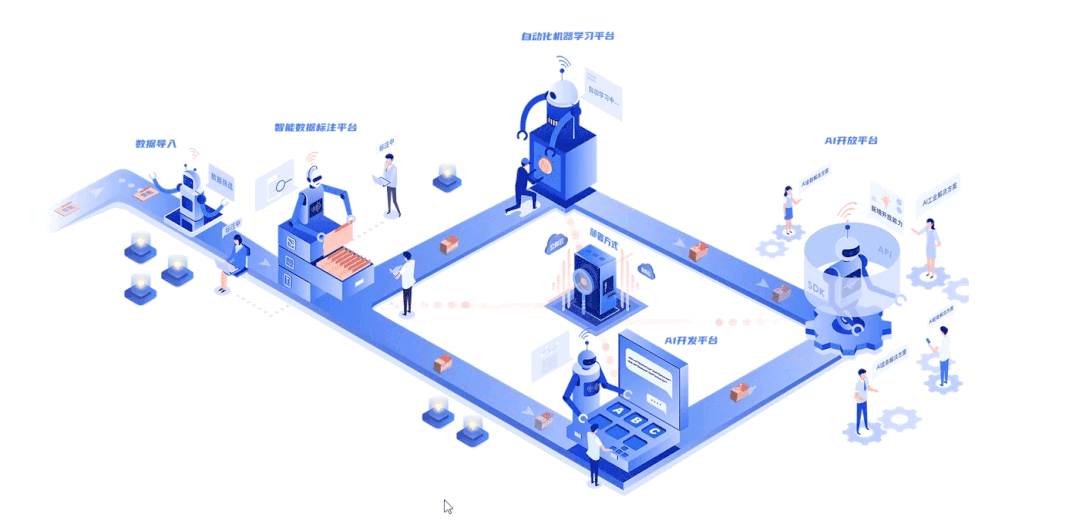
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。