epoch训练时间不同_给训练踩踩油门——Pytorch加速数据读取
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文选自知乎,已获得作者授权,不得二次转载。
作者:MrTian
链接:https://zhuanlan.zhihu.com/p/80695364
需求
最近在训练coco数据集,训练集就有11万张,训练一个epoch就要将近100分钟,训练100个epoch,就需要7天!这实在是太慢了。
经过观察,发现训练时GPU利用率不是很稳定,每训练5秒,利用率都要从100%掉到0%一两秒,初步判断是数据读取那块出现了瓶颈。于是经过调研和实验,制定了下列解决方案。
解决方案
安装:
pip install prefetch_generator使用:
from torch.utils.data import DataLoaderfrom prefetch_generator import BackgroundGenerator class DataLoaderX(DataLoader): def __iter__(self): return BackgroundGenerator(super().__iter__())然后用DataLoaderX替换原本的DataLoader。
提速原因:
原本Pytorch默认的DataLoader会创建一些worker线程来预读取新的数据,但是除非这些线程的数据全部都被清空,这些线程才会读下一批数据。使用prefetch_generator,我们可以保证线程不会等待,每个线程都总有至少一个数据在加载。
(2)data_prefetcher
使用data_prefetcher新开cuda stream来拷贝tensor到gpu。
使用:
def __init__(self, loader, opt): self.loader = iter(loader) self.opt = opt self.stream = torch.cuda.Stream() # With Amp, it isn't necessary to manually convert data to half. # if args.fp16: # self.mean = self.mean.half() # self.std = self.std.half() self.preload() def preload(self): try: self.batch = next(self.loader) except StopIteration: self.batch = None return with torch.cuda.stream(self.stream): for k in self.batch: if k != 'meta': self.batch[k] = self.batch[k].to(device=self.opt.device, non_blocking=True) # With Amp, it isn't necessary to manually convert data to half. # if args.fp16: # self.next_input = self.next_input.half() # else: # self.next_input = self.next_input.float() def next(self): torch.cuda.current_stream().wait_stream(self.stream) batch = self.batch self.preload() return batch然后对训练代码做改造:
for iter_id, batch in enumerate(data_loader): if iter_id >= num_iters: break for k in batch: if k != 'meta': batch[k] = batch[k].to(device=opt.device, non_blocking=True) run_step() # ----改造后----prefetcher = DataPrefetcher(data_loader, opt)batch = prefetcher.next()iter_id = 0while batch is not None: iter_id += 1 if iter_id >= num_iters: break run_step() batch = prefetcher.next()提速原因:
默认情况下,Pytorch将所有涉及到GPU的操作(比如内核操作,cpu->gpu,gpu->cpu)都排入同一个stream(default stream)中,并对同一个流的操作序列化,它们永远不会并行。要想并行,两个操作必须位于不同的stream中。而前向传播位于default stream中,因此,要想将下一个batch数据的预读取(涉及cpu->gpu)与当前batch的前向传播并行处理,就必须:(1)cpu上的数据batch必须pinned;(2)预读取操作必须在另一个stream上进行上面的data_prefetcher类满足这两个要求。注意dataloader必须设置pin_memory=True来满足第一个条件。
(3)把内存当硬盘
把数据放内存里,降低io延迟。
使用:
然后把数据放挂载的目录下,即可。
· size指定的是tmpfs动态大小的上限,实际大小根据实际使用情况而定;
· 数据不一定放在物理内存中,系统根据情况,有可能放在swap的页面,swap一般是在系统盘;
· 重启或者断电后数据全部清空。
如果想系统启动时自动挂载,可以编辑/etc/fstab,在最后添加如下内容:
mount tmpfs in /tmp/tmpfs /tmp tmpfs size=30G 0 0(4)设置num_worker
DataLoader的num_worker如果设置太小,则不能充分利用多线程提速,如果设置太大,会造成线程阻塞,或者撑爆内存,反而导致训练变慢甚至程序崩溃。
他的大小和具体的硬件和软件都有关系,所以没有一个统一的标准,可以通过一些简单的实验来确定。
我的经验是设置成cpu的核心数或者gpu的数量比较合适。
(5)优化数据预处理
主要有两个方面:
尽量简化预处理的操作,使用numpy、opencv等优化过的库,多多利用向量化代码,提升代码运行效率;
尽量缩减数据大小,不要传输无用信息。
(6)其他
使用
TFRecord或者LMDB等,减少小文件的读写;使用
apex.DistributedDataParallel替代torch.DataParallel,使用apex进行加速;使用
dali库,在gpu上直接进行数据预处理。
实验
分别用不同的提速方法做实验,来定量地分析提速的效果。为了快速实验,采用了5000张的小批量训练集,确保一次epoch的训练时间很短。
实验一:
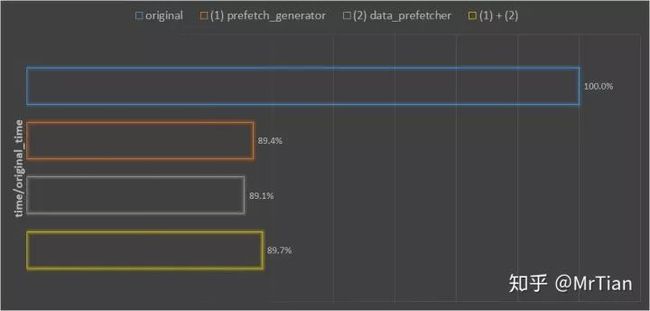
在hdd硬盘上,用同样的参数、同样的数据,分别用不同的优化方法,训练两个epoch,记录训练的时间。
优化方法分别是:
original:默认dataloader,不优化(1)prefetcher_generator:只用prefetcher_generator库优化(2)data_prefetcher:只用data_prefetcher优化(1)+(2):同时用prefetcher_generator和data_prefetcher优化
最后将得到的时间,除以不优化时的训练时间。
从图中可以观察到:
(1)和(2)两种优化方法都差不多有10%左右的训练时间的缩短;
(1)(2)同时使用,并没有进一步缩短训练时间,反而不如只使用一种优化方法。
实验二:
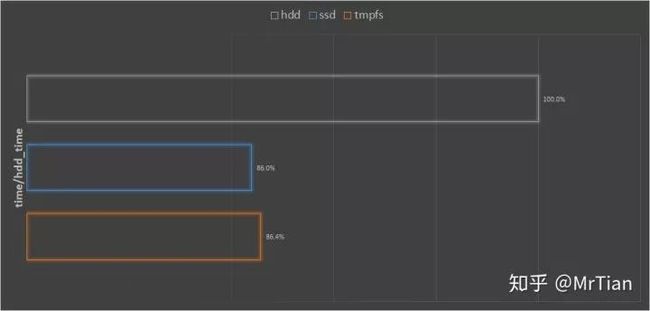
用同样的参数、同样的数据,用默认的dataloader,数据分别在hdd、ssd和tmpfs内存上进行训练两个epoch,记录训练时间。
最后时间统一除以在hdd上的训练时间。
从图中可以观察到:
将数据从hdd挪到ssd或者内存上,训练时间都有14%左右的缩短;
在tmpfs上训练并不比在ssd上快,可能的原因是数据太大,训练时并没有放在物理内存上,而是放在
swap上,而这台机器swap也是在ssd上,所以速度差不多。
实验三:

优化数据预处理代码,尽量用向量化代码,缩减数据传输大小,分别在hdd上,用默认dataloader训练。
如图,训练时间缩短了接近34%!可见,在之前的代码中,主要是预处理部分拖慢了整体的训练速度。
总结
以上定量地分析了各加速方法的效果,当然如果各方法都用上,最后的加速比例不是简单叠加的。
最后,我将数据放在ssd上、用了(1)或者(2)的优化方法、优化了数据预处理代码后,最后使得训练时间缩短了39%!也就是说,如果原来训练一个模型需要7天,现在需要4天半,节省了2天半的时间。
所谓磨刀不误砍柴工,建议大家在正式训练前,花一点时间排查一下训练的瓶颈,尽量提升训练的速度,这是一劳永逸的,将在后面节省大量的时间,是非常值得的。
参考
Should we use BackgroundGenerator when we’ve had DataLoader?
https://github.com/IgorSusmelj/pytorch-styleguide/issues/5#
Dose data_prefetcher() really speed up training?
https://github.com/NVIDIA/apex/issues/304#
如何给你PyTorch里的Dataloader打鸡血
把内存当硬盘,提速你的linux系统
https://www.jianshu.com/p/6f9b200671bb
Guidelines for assigning num_workers to DataLoader
https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813
How to prefetch data when processing with GPU?
https://discuss.pytorch.org/t/how-to-prefetch-data-when-processing-with-gpu/548
-End-
*延伸阅读
PyTorch中的contiguous
40万现金大奖+免费算力+英特尔神经棒,极市开发者榜单邀你来战!
如何给你PyTorch里的Dataloader打鸡血
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~ 