目录
零、即看即用
一、perf 命令
perf简介
perf record参数
命令例子
二、火焰图的含义
三、互动性
四、火焰图示例
五、局限
六、Node 应用的火焰图
七、浏览器的火焰图
八、参考链接
九、其他性能分析工具
十、perf工具远比上面讲的更强大
perf top
perf stat
perf record
perf report
十一、perf命令详情
perf火焰图大量unknown的问题
栈回溯方式
测试
总结
perf 的工作原理
报错记录
零、即看即用
前提:下载flamegraph工具包
git clone https://github.com/brendangregg/FlameGraph.git
方法一、
第1步、监测进程
$ sudo perf record -a --call-graph dwarf -p 667651 sleep 30
-p 13204:监测进程号13204 (如果想监视线程则用 -t 6665 #6665为线程号)
--call-graph:
dwarf:表示回溯方式,perf 同时支持 3 种栈回溯方式:fp, dwarf, lbr,推荐dwarf,理由见文章末尾
sleep 30:持续30秒。(注意sleep 前面没有--,--sleep用法是错的)
Ctrl+c结束执行后,在当前目录下会生成采样数据perf.data.
第2步、 解析数据
用perf script工具对perf.data进行解析
perf script -i perf.data &> perf.unfold
第3步、符号进行折叠
将perf.unfold中的符号进行折叠:
#./stackcollapse-perf.pl perf.unfold &> perf.folded
第4步、生成svg图
./flamegraph.pl perf.folded > perf-$(date +%Y%m%d-%H:%M:%S).svg
进入flamegraph目录把下面的yourProcessName替换成你程序的名字,拷贝执行即可:
pname=yourProcessName&&sudo perf record -a --call-graph dwarf -p $(pidof pname) sleep 30 &&perf script -i perf.data &> perf.unfold&&./stackcollapse-perf.pl perf.unfold &> perf.folded&&./flamegraph.pl perf.folded > perf-$(date +%Y%m%d-%H:%M:%S).svg
方法二、
1,perf record --call-graph dwarf -p 12345
2,perf script | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > process.svg
用法三、
使用perf采样
1.直接使用perf启动服务
# perf record -g ls
--------------------------------
2.挂接到已启动的进程
# 使用PID监控程序
# sudo perf record -e cpu-clock -g -p pid
# 如果svg图出现unknown函数,使用如下
# sudo perf record -e cpu-clock --call-graph dwarf -p pid
# 使用程序名监控程序
# sudo perf record -e cpu-clock -g -p `pgrep your_program`
------------------------------------
第一种方式不需要root权限,第二种方式需要root权限
使用ctrl+c中断perf进程,或者在命令最后加上参数 --sleep n (n秒后停止)
perf record表示记录到文件,perf top直接会显示到界面
如果record之后想直接输出结果,使用perf report即可
原文链接:https://blog.csdn.net/u013919153/article/details/110559888
火焰图实例下载:https://download.csdn.net/download/bandaoyu/24318994?spm=1001.2014.3001.5503
一、perf 命令
perf简介
perf 命令(performance 的缩写),它是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。
Perf是一个包含22种子工具的工具集,以下是最常用的5种:
perf-list :Perf-list用来查看perf所支持的性能事件,有软件的也有硬件的。
perf-stat
perf-top: perf top主要用于实时分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数、模块函数与内核函数,甚至能够定位到热点指令。默认的性能事件为cpu cycles。
perf-record
perf-report
perf record参数
Perf record
记录一段时间内系统/进程的性能时间
参数:
-e:选择性能事件
-p:待分析进程的id
-t:待分析线程的id
-a:分析整个系统的性能
-C:只采集指定CPU数据
-c:事件的采样周期
-o:指定输出文件,默认为perf.data
-A:以append的方式写输出文件
-f:以OverWrite的方式写输出文件
-g:记录函数间的调用关系通常,它的执行频率是 99Hz(每秒99次),如果99次都返回同一个函数名,那就说明 CPU 这一秒钟都在执行同一个函数,可能存在性能问题。
13204是进程号
$ sudo perf record -F 99 -p 13204 -g sleep 30
上面的代码中,perf record表示记录,-F 99表示每秒99次,-p 13204是进程号,即对哪个进程进行分析,-g表示记录调用栈,sleep 30则是持续30秒。
运行后会产生一个庞大的文本文件。如果一台服务器有16个 CPU,每秒抽样99次,持续30秒,就得到 47,520 个调用栈,长达几十万甚至上百万行。
举例:
sudo perf record -e cpu-clock -g -p 2548
-g 选项是告诉perf record额外记录函数的调用关系
-e cpu-clock 指perf record监控的指标为cpu周期
-p 指定需要record的进程pid为了便于阅读,perf record命令可以统计每个调用栈出现的百分比,然后从高到低排列。
$ sudo perf report -n --stdio

这个结果还是不易读,所以才有了火焰图。
生成火焰图
1、Flame Graph项目位于GitHub上:https://github.com/brendangregg/FlameGraph
2、可以用git将其clone下来:git clone https://github.com/brendangregg/FlameGraph.git
我们以perf为例,看一下flamegraph的使用方法:
1、第一步
$sudo perf record -e cpu-clock -g -p 28591
Ctrl+c结束执行后,在当前目录下会生成采样数据perf.data.
2、第二步
用perf script工具对perf.data进行解析
perf script -i perf.data &> perf.unfold
3、第三步
将perf.unfold中的符号进行折叠:
#./stackcollapse-perf.pl perf.unfold &> perf.folded
4、最后生成svg图:
./flamegraph.pl perf.folded > perf.svg

命令例子
3.2查看单个进程各个函数cpu使用率
| perf top -e cycles -p 3352 |
3.3使用perf record 记录:
| perf record -e cpu-clock -p 进程号 perf report |
3.4统计进程里最耗时函数
| perf record -e cycles –g -p 进程号 perf report |
| perf record -a -F 1000 sleep 5 |
其中-F 1000是指定采样频率为1000次/秒
Sleep 5 指采样5秒
| perf stat -e 'sched:*' -p 28135 sleep 5 |
统计5秒内28135进程调度情况
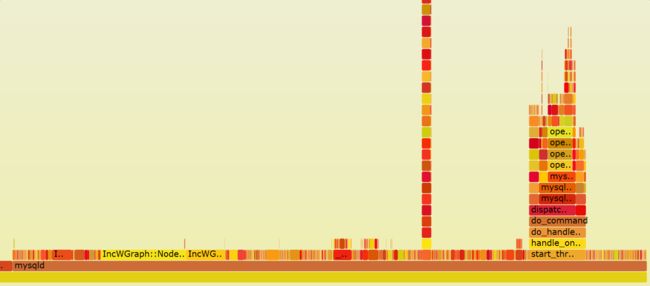
二、火焰图的含义
火焰图是基于 perf 结果产生的 SVG 图片(http://queue.acm.org/downloads/2016/Gregg4.svg),用来展示 CPU 的调用栈。
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
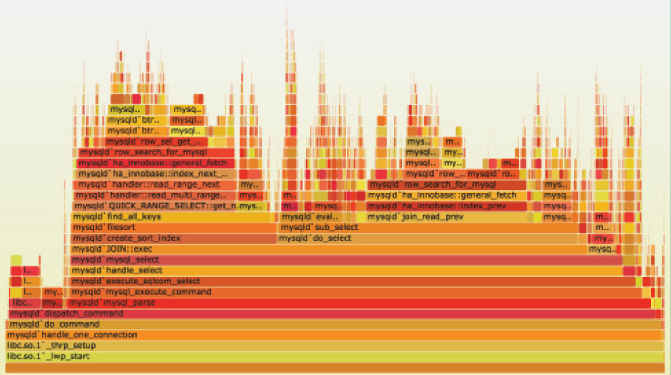
三、互动性
火焰图是 SVG 图片(http://queue.acm.org/downloads/2016/Gregg4.svg),可以与用户互动。
(1)鼠标悬浮
火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。下面是一个例子。
mysqld'JOIN::exec (272,959 samples, 78.34 percent)
(2)点击放大
在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息。

左上角会同时显示"Reset Zoom",点击该链接,图片就会恢复原样。
(3)搜索
按下 Ctrl + F 会显示一个搜索框,用户可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示。
四、火焰图示例
下面是一个简化的火焰图例子。
首先,CPU 抽样得到了三个调用栈。
func_c func_b func_a start_thread func_d func_a start_thread func_d func_a start_thread
上面代码中,start_thread是启动线程,调用了func_a。后者又调用了func_b和func_d,而func_b又调用了func_c。
经过合并处理后,得到了下面的结果,即存在两个调用栈,第一个调用栈抽中1次,第二个抽中2次。
start_thread;func_a;func_b;func_c 1 start_thread;func_a;func_d 2
有了这个调用栈统计,火焰图工具(https://github.com/brendangregg/FlameGraph)就能生成 SVG 图片。

上面图片中,最顶层的函数g()占用 CPU 时间最多。d()的宽度大,但是它直接耗用 CPU 的部分很少(主要是d()内调用的e()和f()消耗)。b()和c()没有直接消耗 CPU(因为一层一层调用,最终上c()内调用的函数消耗cpu)。因此,如果要调查性能问题,首先应该调查g(),其次是i()。
另外,从图中可知a()有两个分支b()和h(),这表明a()里面可能有一个条件语句,而b()分支消耗的 CPU 大大高于h()。
五、局限
两种情况下,无法画出火焰图,需要修正系统行为。
(1)调用栈不完整
当调用栈过深时,某些系统只返回前面的一部分(比如前10层)。
(2)函数名缺失
有些函数没有名字,编译器只用内存地址来表示(比如匿名函数)。
六、Node 应用的火焰图
Node 应用的火焰图就是对 Node 进程进行性能抽样,与其他应用的操作是一样的。
$ perf record -F 99 -p `pgrep -n node` -g -- sleep 30
详细的操作可以看这篇文章。
七、浏览器的火焰图
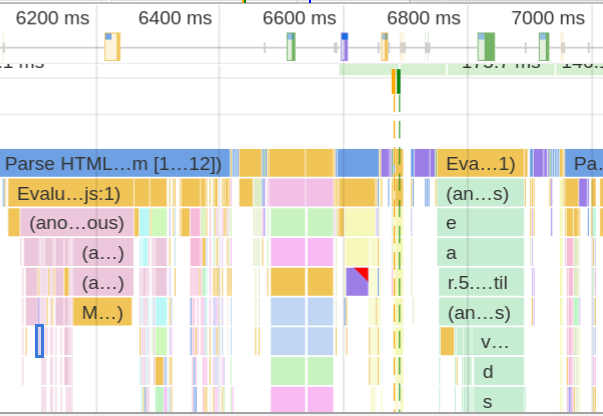
Chrome 浏览器可以生成页面脚本的火焰图,用来进行 CPU 分析。
打开开发者工具,切换到 Performance 面板。然后,点击"录制"按钮,开始记录数据。这时,可以在页面进行各种操作,然后停止"录制"。
这时,开发者工具会显示一个时间轴。它的下方就是火焰图。

浏览器的火焰图与标准火焰图有两点差异:它是倒置的(即调用栈最顶端的函数在最下方);x 轴是时间轴,而不是抽样次数。
八、参考链接
- 火焰图的介绍论文
- 火焰图官方主页
- 火焰图生成工具
摘自:perf + 火焰图分析程序性能:https://www.cnblogs.com/happyliu/p/6142929.html
如何读懂火焰图?http://www.ruanyifeng.com/blog/2017/09/flame-graph.html
九、其他性能分析工具
vtune,gprof、oprofile、valgrind、perf。vtune perf 看不到L3cache 等硬件特性,需要vtune
十、perf工具远比上面讲的更强大
perf工具简介:https://www.cxyzjd.com/article/qq_23662505/114669615
perf工具简介+火焰图制作与解读:https://blog.csdn.net/wujinting007/article/details/112690350
perf top
perf top类似top命令,主要用于实时分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数、
模块函数与内核函数,甚至能够定位到热点指令。默认的性能事件为cpu cycles。
perf stat
用于输出指定程序的性能统计数据
perf record
perf record收集采样信息,并记录在文件中,可以离线分析。使用下面的 perf report解析收集的采样数据文件。
perf report
perf report 主要用来分析上面perf record生成的perf.data文件。
更多详情:
Linux 调试辅助工具之perf 火焰图:https://blog.csdn.net/liuzhanchun/article/details/105507260
perf工具简介+火焰图制作与解读:https://blog.csdn.net/wujinting007/article/details/112690350
https://download.csdn.net/download/bandaoyu/24318994
十一、perf命令详情
perf是Linux下的一款性能分析工具,能够进行函数级与指令级的热点查找。
Perf List
利用perf剖析程序性能时,需要指定当前测试的性能时间。性能事件是指在处理器或操作系统中发生的,可能影响到程序性能的硬件事件或软件事件
Perf top
实时显示系统/进程的性能统计信息
常用参数
-e:指定性能事件
-a:显示在所有CPU上的性能统计信息
-C:显示在指定CPU上的性能统计信息
-p:指定进程PID
-t:指定线程TID
-K:隐藏内核统计信息
-U:隐藏用户空间的统计信息
-s:指定待解析的符号信息
‘‐G’ or‘‐‐call‐graph’
graph: 使用调用树,将每条调用路径进一步折叠。这种显示方式更加直观。
每条调用路径的采样率为绝对值。也就是该条路径占整个采样域的比率。
fractal
默认选项。类似与 graph,但是每条路径前的采样率为相对值。
flat
不折叠各条调用
选项 call_order 用以设定调用图谱的显示顺序,该选项有 2个取值,分别是
callee 与caller。
将该选项设为callee 时,perf按照被调用的顺序显示调用图谱,上层函数被下层函数所调用。
该选项被设为caller 时,按照调用顺序显示调用图谱,即上层函数调用了下层函数路径,也不显示每条调用路径的采样率
注: Perf top需要root权限
Perf stat
分析系统/进程的整体性能概况
task‐clock事件表示目标任务真正占用处理器的时间,单位是毫秒。也称任务执行时间
context-switches是系统发生上下文切换的次数
CPU-migrations是任务从一个处理器迁往另外一个处理器的次数
page-faults是内核发生缺页的次数
cycles是程序消耗的处理器周期数
instructions是指命令执行期间产生的处理器指令数
branches是指程序在执行期间遇到的分支指令数。
branch‐misses是预测错误的分支指令数。
XXX seconds time elapsed系程序持续时间
任务执行时间/任务持续时间大于1,那可以肯定是多核引起的
参数设置:
-e:选择性能事件
-i:禁止子任务继承父任务的性能计数器。
-r:重复执行 n 次目标程序,并给出性能指标在n 次执行中的变化范围。
-n:仅输出目标程序的执行时间,而不开启任何性能计数器。
-a:指定全部cpu
-C:指定某个cpu
-A:将给出每个处理器上相应的信息。
-p:指定待分析的进程id
-t:指定待分析的线程id
Perf record
记录一段时间内系统/进程的性能时间
参数:
-e:选择性能事件
-p:待分析进程的id
-t:待分析线程的id
-a:分析整个系统的性能
-C:只采集指定CPU数据
-c:事件的采样周期
-o:指定输出文件,默认为perf.data
-A:以append的方式写输出文件
-f:以OverWrite的方式写输出文件
-g:记录函数间的调用关系
Perf Report
读取perf record生成的数据文件,并显示分析数据
参数
-i:输入的数据文件
-v:显示每个符号的地址
-d :只显示指定dos的符号
-C:只显示指定comm的信息(Comm. 触发事件的进程名)
-S:只考虑指定符号
-U:只显示已解析的符号
-g[type,min,order]:显示调用关系,具体等同于perf top命令中的-g
-c:只显示指定cpu采样信息
-M:以指定汇编指令风格显示
–source:以汇编和source的形式进行显示
-p:用指定正则表达式过滤调用函数
例1
# perf top -e cycles:k #显示内核和模块中,消耗最多CPU周期的函数
# perf top -e kmem:kmem_cache_alloc #显示分配高速缓存最多的函数
# perf top
Samples: 1M of event 'cycles', Event count (approx.): 73891391490
5.44% perf [.] 0x0000000000023256
4.86% [kernel] [k] _spin_lock
2.43% [kernel] [k] _spin_lock_bh
2.29% [kernel] [k] _spin_lock_irqsave
1.77% [kernel] [k] __d_lookup
1.55% libc-2.12.so [.] __strcmp_sse42
1.43% nginx [.] ngx_vslprintf
1.37% [kernel] [k] tcp_poll
第一列:符号引发的性能事件的比例,默认指占用的cpu周期比例。
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库)。[k]表述此符号属于内核或模块。
第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
例2
# perf top -G #得到调用关系图
# perf top -e cycles #指定性能事件
# perf top -p 23015,32476 #查看这两个进程的cpu cycles使用情况
# perf top -s comm,pid,symbol #显示调用symbol的进程名和进程号
# perf top --comms nginx,top #仅显示属于指定进程的符号
# perf top --symbols kfree #仅显示指定的符号
例3
# perf stat ls
Performance counter stats for 'ls':
0.653782 task-clock # 0.691 CPUs utilized
0 context-switches # 0.000 K/sec
0 CPU-migrations # 0.000 K/sec
247 page-faults # 0.378 M/sec
1,625,426 cycles # 2.486 GHz
1,050,293 stalled-cycles-frontend # 64.62% frontend cycles idle
838,781 stalled-cycles-backend # 51.60% backend cycles idle
1,055,735 instructions # 0.65 insns per cycle
# 0.99 stalled cycles per insn
210,587 branches # 322.106 M/sec
10,809 branch-misses # 5.13% of all branches
0.000945883 seconds time elapsed
输出包括ls的执行时间,以及10个性能事件的统计。
task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
context-switches:上下文的切换次数。
CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU
迁移到另一个CPU。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内
存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配
等情况也会触发缺页异常。
cycles:消耗的处理器周期数。如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz。
可以用cycles / task-clock算出。
stalled-cycles-frontend:略过。
stalled-cycles-backend:略过。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。branch-misses是预测错误的分支指令数。
# perf stat -r 10 ls > /dev/null #执行10次程序,给出标准偏差与期望的比值
# perf stat -v ls > /dev/null #显示更详细的信息
# perf stat -n ls > /dev/null #只显示任务执行时间,不显示性能计数器
# perf stat -a -A ls > /dev/null #单独给出每个CPU上的信息
# perf stat -e syscalls:sys_enter ls #ls命令执行了多少次系统调用
例4
# perf record -p `pgrep -d ',' nginx` #记录nginx进程的性能数据
# perf record ls -g #记录执行ls时的性能数据
# perf record -e syscalls:sys_enter ls #记录执行ls时的系统调用,可以知道哪些系统调用最频繁
例5
# perf lock record ls #记录
# perf lock report #报告
Name acquired contended total wait (ns) max wait (ns) min wait (ns)
&mm->page_table_... 382 0 0 0 0
&mm->page_table_... 72 0 0 0 0
&fs->lock 64 0 0 0 0
dcache_lock 62 0 0 0 0
vfsmount_lock 43 0 0 0 0
&newf->file_lock... 41 0 0 0 0
Name:内核锁的名字。
aquired:该锁被直接获得的次数,因为没有其它内核路径占用该锁,此时不用等待。
contended:该锁等待后获得的次数,此时被其它内核路径占用,需要等待。
total wait:为了获得该锁,总共的等待时间。
max wait:为了获得该锁,最大的等待时间。
min wait:为了获得该锁,最小的等待时间。
例6
# perf kmem record ls #记录
# perf kmem stat --caller --alloc -l 20 #报告
------------------------------------------------------------------------------------------------------
Callsite | Total_alloc/Per | Total_req/Per | Hit | Ping-pong | Frag
------------------------------------------------------------------------------------------------------
perf_event_mmap+ec | 311296/8192 | 155952/4104 | 38 | 0 | 49.902%
proc_reg_open+41 | 64/64 | 40/40 | 1 | 0 | 37.500%
__kmalloc_node+4d | 1024/1024 | 664/664 | 1 | 0 | 35.156%
ext3_readdir+5bd | 64/64 | 48/48 | 1 | 0 | 25.000%
load_elf_binary+8ec | 512/512 | 392/392 | 1 | 0 | 23.438%
Callsite:内核代码中调用kmalloc和kfree的地方。
Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
Hit:调用的次数。
Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
有使用--alloc选项,还会看到Alloc Ptr,即所分配内存的地址。
例7
# perf sched record sleep 10
# perf report latency --sort max
---------------------------------------------------------------------------------------------------------------
Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | Maximum delay at |
---------------------------------------------------------------------------------------------------------------
events/10:61 | 0.655 ms | 10 | avg: 0.045 ms | max: 0.161 ms | max at: 9804.958730 s
sleep:11156 | 2.263 ms | 4 | avg: 0.052 ms | max: 0.118 ms | max at: 9804.865552 s
edac-poller:1125 | 0.598 ms | 10 | avg: 0.042 ms | max: 0.113 ms | max at: 9804.958698 s
events/2:53 | 0.676 ms | 10 | avg: 0.037 ms | max: 0.102 ms | max at: 9814.751605 s
perf:11155 | 2.109 ms | 1 | avg: 0.068 ms | max: 0.068 ms | max at: 9814.867918 s
TASK:进程名和pid。
Runtime:实际的运行时间。
Switches:进程切换的次数。
Average delay:平均的调度延迟。
Maximum delay:最大的调度延迟。
Maximum delay at:最大调度延迟发生的时刻。
例8
# perf probe --line schedule #前面有行号的可以探测,没有行号的就不行了
# perf report latency --sort max #在schedule函数的12处增加一个探测点
参考资料:http://linux.51yip.com/search/perf
perf火焰图大量unknown的问题
使用 perf 进行性能分析时如何获取准确的调用栈
(原文:使用 perf 进行性能分析时如何获取准确的调用栈:https://gaomf.cn/2019/10/30/perf_stack_traceback/)
工具之术
- Debug
- Linux
- x86
perf 是 Linux 下重要的性能分析工具,perf 可以通过采样获取很多性能指标,其中最常用的是获取 CPU Cycles,即程序各部分代码运行所需的时间,进而确定性能瓶颈在哪。不过在实际使用过程中发现,简单的使用perf record -g 获取到的调用栈是有问题的,存在大量 [Unknown] 函数,从 perf report 的结果来看这些部分对应地址大部分都是非法地址,且生成的火焰图中存在很多明显与代码矛盾的调用关系。
最初怀疑是优化级别的问题,然而尝试使用 Og 或 O0 优化依然存在此问题,仔细阅读 perf record 的手册后发现,perf 同时支持 3 种栈回溯方式:fp, dwarf, lbr,可以通过 --call-graph 参数指定,而 -g 就相当于 --call-graph fp.
栈回溯方式
fp 就是 Frame Pointer,即 x86 中的 EBP 寄存器,fp 指向当前栈帧栈底地址,此地址保存着上一栈帧的 EBP 值,具体可参考此文章的介绍,根据 fp 就可以逐级回溯调用栈。然而这一特性是会被优化掉的,而且这还是 GCC 的默认行为,在不手动指定 -fno-omit-frame-pointer 时默认都会进行此优化,此时 EBP 被当作一般的通用寄存器使用,以此为依据进行栈回溯显然是错误的。不过尝试指定 -fno-omit-frame-pointer 后依然没法获取到正确的调用栈,根据 GCC 手册的说明,指定了此选项后也并不保证所有函数调用都会使用 fp…… 看来只有放弃使用 fp 进行回溯了。
dwarf 是一种调试文件格式,GCC 编译时附加的 -g 参数生成的就是 dwarf 格式的调试信息,其中包括了栈回溯所需的全部信息,使用 libunwind 即可展开这些信息。dwarf 的进一步介绍可参考 “关于DWARF”,值得一提的是,GDB 进行栈回溯时使用的正是 dwarf 调试信息。实际测试表明使用 dwarf 可以很好的获取到准确的调用栈。
最后 perf 还支持通过 lbr 获取调用栈,lbr 即 Last Branch Records,是较新的 Intel CPU 中提供的一组硬件寄存器,其作用是记录之前若干次分支跳转的地址,主要目的就是用来支持 perf 这类性能分析工具,其详细说明可参考 “An introduction to last branch records” & “Advanced usage of last branch records”。此方法是性能与准确性最高的手段,然而它存在一个很大的局限性,由于硬件 Ring Buffer 寄存器的大小是有限的,lbr 能记录的栈深度也是有限的,具体值取决于特定 CPU 实现,一般就是 32 层,若超过此限制会得到错误的调用栈。
测试
实际测试下以上 3 种栈回溯方式得到的结果,测试程序是一个调用深度为 50 的简单程序,从 f0() 依次调用至 f50()。
**--call-graph fp**:
(图:略,请到原文查看)
**--call-graph lbr**:
(图:略,请到原文查看)
**--call-graph dwarf**:
(图:略,请到原文查看)
可以看到,的确只有 dwarf 获取到了正确的调用栈。
总结
| 优点 | 缺点 | |
|---|---|---|
fp |
None | 1. 默认 fp 被优化掉了根本不可用。 |
lbr |
1. 高效准确 | 1. 需要较新的 Intel CPU 才有此功能;2. 能记录的调用栈深度有限。 |
dwarf |
1. 准确 | 1. 开销相对较大;2. 需要编译时附加了调试信息。 |
参考资料:
perf Examples:http://www.brendangregg.com/perf.html
perf 的工作原理
基本原理是:
每隔一个固定时间,CPU上产生一个中断,看当前是哪个进程、哪个函数,然后给对应的进程和函数加一个统计值,这样就知道CPU有多少时间在某个进程或某个函数上了。具体原作原理就是直接通过系统调用syscall/ioctl或者监听SW的event来看性能。
详细见本章节内容:
转自:https://blog.csdn.net/u013983194/article/details/112209853
2.1 背景知识
2.1.1 tracepoints
tracepoints是散落在内核源码中的一些hook,它们可以在特定的代码被执行到时触发,这一特定可以被各种trace/debug工具所使用。
perf将tracepoint产生的时间记录下来,生成报告,通过分析这些报告,可以了解程序运行期间内核的各种细节,对性能症状做出准确的诊断。
2.1.2 硬件特性之cache
内存读写是很快的,但是还是无法和处理器指令执行速度相比。为了从内存中读取指令和数据,处理器需要等待,用处理器时间来衡量,这种等待非常漫长。cache是一种SRAM,读写速度非常快,能和处理器相匹配。因此将常用的数据保存在cache中,处理器便无需等待,从而提高性能。cache的尺寸一般都很小,充分利用cache是软件调优非常重要部分
2.2 调优方向
Hardware Event由PMU部件产生,在特定的条件下探测性能事件是否发生以及发生的次数
Software Event是内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件。比如进程切换,ticks等。
Tracepoint Event是内核中静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节。比如slab分配器的分配次数等。
3、Perf检测原理
perf是利用PMU、tracepoint和内核中的计数器来进行性能统计
3.1 PMU

PerformanceMonitor Unit,性能监视单元,其为CPU提供的一个单元,属于硬件的范畴。通过访问相关的寄存器能读取到CPU的一些性能数据,目前大部分CPU都会提供相应的PMU。其包括各种core, offcore和uncore事件
Perf可以对程序进行函数级别的采样,从而了解程序的性能瓶颈在哪里。其基本原理是:每隔一个固定时间,就是CPU上产生一个中断,看当前是哪个进程、哪个函数,然后给对应的进程和函数加一个统计值,这样就知道CPU有多少时间在某个进程或某个函数上了。具体原作原理就是直接通过系统调用syscall/ioctl或者监听SW的event来看性能。
原文链接:https://blog.csdn.net/u013983194/article/details/112209853
perf是一个面向事件(event-oriented)的性能检测工具,内置于Linux内核,又称 perf_events
event 可能的来源:
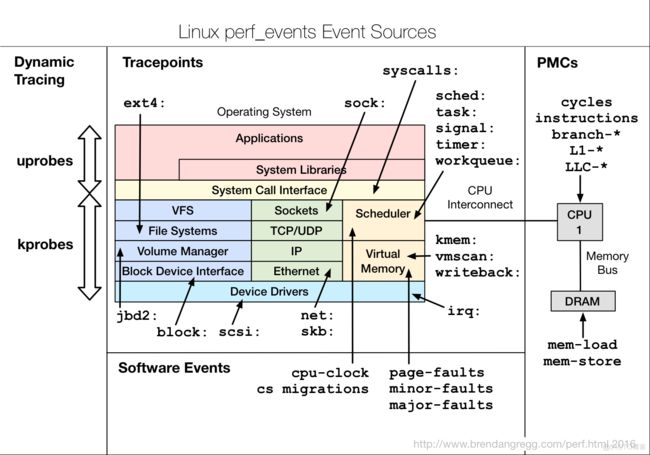
perf 工具将 event 分为:
software events,hardware events,hardware cache events,tracepoint events
software events
使用内核的计数器 kernel counters,记录系统级事件,例如上下文切换,page fault等
hardware events
使用CPU的 Performance Monitoring Unit (PMU),记录微体系结构(micro-architecture)事件,例如cycle数,指令执行数 instructions retired,L1 cache misses等
PMU是一种寄存器,用于记录指定事件发生的次数(perf stat -e 多个事件用逗号隔开)。使用PMU计数时,会设定 Sample After Value (SAV)。当PMU的值超过SAV,将触发一个硬件中断,中断处理程序可以收集CPU的IP,调用堆栈,PID等信息,并认为这SAV次事件都是由于当前指令造成的。
hardware events 记录的误差可能来自于:
超线程共享PMU: 开启超线程后,一个物理核心被虚拟化为两个逻辑核心,但依然共用同一个PMU
事件滑行(Hardware Event Skid): 硬件延迟或指令流重排导致记录的IP并没指向真正发生事件的指令
多路复用:如果记录的事件种类超过了PMU的数量,会对PMU进行多路(时分)复用
中断屏蔽: 用于记录指令的这个中断可能会被其它中断屏蔽掉
详细参考: Understanding How General Exploration Works in Intel® VTune™ Amplifier
hardware cache events
一类特别的 hardware events:有 L1 (d/i)cache, LLC(Last Level Cache), (d/i)TLB, branch 事件
tracepoint events
内核提供的 ftrace 系统调度追踪器
最常用到的命令:
perf stat: obtain event counts
perf record: record events for later reporting
perf report: break down events by process, function, etc.
perf annotate: annotate assembly or source code with event counts
perf top: see live event count
perf bench: run different kernel microbenchmarks
更细节的使用方法可以在上述命令后加-h查看
-----------------------------------
转自:perf 的工作原理 —— Linux 性能检测工具-https://blog.51cto.com/u_15127627/2733823
报错记录
perf: Couldn't synthesize bpf events
回复:
CONFIG_BPF_SYSCALL was not enabled in kernel config. After enabling it, I can see that 'couldn't synthesize bpf' was gone. Marking it as answered.
perf: Couldn't synthesize bpf events :https://stackoverflow.com/questions/66024727/perf-couldnt-synthesize-bpf-events