【cs231n assignment1】KNN
个人学习笔记
date:2023.01.02
Goals

- 理解图像分类步骤以及数据驱动方法(训练、预测阶段)
- 理解如何分配训练、验证、测试集,并使用验证集进行超参数调参
- 掌握使用Numpy书写高效向量代码的能力
- 完成并应用KNN分类器
数据集及其处理
# Subsample the data for more efficient code execution in this exercise
num_training = 5000
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# Reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape, X_test.shape)
分析:
- 输出为(5000, 3072) (500, 3072)
- 提取其中的5000个作为training set,其中的500个作为test set。
- 使用
np.reshape()将image尺寸由32x32x3拉直为一个行向量,因为我们要算distance是将所有元素运算相加。-1则表示让编译器自行判断该换成什么shape。
KNN分类器
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)
分析:
- 创建分类器对象
- 训练模型
距离计算
本次作业均用欧氏距离:
d ( i , j ) = ∑ q ( X i p − X t r a i n j p ) 2 d(i,j)= \sqrt[]{\sum_{q}(X_{i}^p-Xtrain_{j}^p)^2 } d(i,j)=q∑(Xip−Xtrainjp)2
(一) 使用2个循环来编写距离
- 函数
np.sqrt()表示开方 - 函数
np.sum()表示求和 - 函数
np.square()表示平方 - 两个循环
i和j表示测试集和训练集的序号 - 将第
i个测试图像和第j个训练图像做运算得到欧氏距离,存储到dists[i,j],且X[i,:]表示第i个测试图像的所有元素的行向量,X_train[j,:]表示训练图像所有元素的行向量,直接做减法即可。
def compute_distances_two_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data.
Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension, nor use np.linalg.norm(). #
#####################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dists[i,j] = np.sqrt(np.sum(np.square(X[i,:]-self.X_train[j,:])))
#dists[i,j]=np.sqrt(np.sum(np.square(X[i,:]-self.X_train[j,:])))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists
(二) 使用一个循环来编写距离
- 一个以
i测试集序号为条件的循环,代码X_train - X[i,:]表示训练集5000张图像和第i张测试图像相减,然后再做一系列运算,将结果存储到dists[i,:]表示第i张测试图像和5000张训练图像的欧氏距离 np.sum(a,axis=1)表示矩阵a的纵轴元素相加,既每一行的3072的元素平方后相加,得到一个5000个元素的行向量
def compute_distances_one_loop(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a single loop over the test data.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test): #500
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
# Do not use np.linalg.norm(). #
#######################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dists[i,:]=np.sqrt(np.sum(np.square(self.X_train-X[i,:]),axis=1))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists
(三)不使用循环编写距离
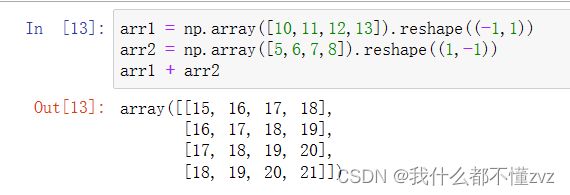
- 题目提示使用矩阵完全平方公式以及广播机制计算求和
- 广播机制求和如下图,
行vector+列vector = 行x列 matrix
def compute_distances_no_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using no explicit loops.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy, #
# nor use np.linalg.norm(). #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#dists = np.sqrt(np.square(X).sum(1).reshape([-1,1]) + np.square(self.X_train).sum(1).reshape([1,-1])- 2*X.dot(self.X_train.T))
dists=np.sqrt(np.square(X).sum(1).reshape([-1,1])+np.square(self.X_train).sum(1).reshape([1,-1])-2*X.dot(self.X_train.T))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists
预测标签
使用到的变量:
num_test = dists.shape[0], 就是测试集长度y_pred = np.zeros(num_test),就是预测结果,长度为测试集长度closest_y = []将第i幅测试图形预测的结果存储到此
分析:
np.argsort()函数,就是排序,然后返回索引,索引值既是由小到大元素的索引值。比如arr =[3,2,1], 则返回[2,1,0]knn=np.argsort(dists[i,:])[0:k]表示第i幅测试图形与5000张训练图像的L2距离排序索引,然后取前k个(knn算法嘛)labels=self.y_train[knn]返回对应的标签(既与之距离最小的k张训练图像的labels)np.bincount返回某一个值出现的次数的列表,比如[0,0,0,3,3,1] 则返回列表[3,1,0,2] 表示数字0出现3次,数字1出现1次,数字2出现0次np.argmax()返回最大值的索引,该索引就是labels,存储到y_pred[i]
def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point.
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
#########################################################################
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# testing point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#knn = np.argsort(dists[i,:])[0:k]
#labels = self.y_train(knn)
#closest_y = labels
knn=np.argsort(dists[i,:])[0:k]
labels=self.y_train[knn]
closest_y=labels
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#########################################################################
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#y_pred[i]= np.argmax(np.bincount(closest_y.astype(int))
y_pred[i]=np.argmax(np.bincount(closest_y.astype(int)))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return y_pred
距离矩阵的可视化
dists = classifier.compute_distances_two_loops(X_test)
print(dists.shape) #500*5000
plt.imshow(dists, interpolation='none')
plt.show()

分析:
- 在黑色背景下,横轴纵轴出现相互交织的亮痕。横轴的亮痕表示测试图像与训练图像的L2距离,纵轴的亮痕则表示训练图像和所有测试图形的L2距离。亮痕越亮说明距离越大,那么就越不相似,反之则越相似。
预测结果以及准确率
分析:
- 已知KNN分类器predict函数最后返回的是索引数组,表示预测的标签结果。
y_test变量数组装载着测试集对应的标签
# Now implement the function predict_labels and run the code below:
# We use k = 1 (which is Nearest Neighbor).
y_test_pred = classifier.predict_labels(dists, k=1)
# Compute and print the fraction of correctly predicted examples
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
结果:
Got 137 / 500 correct => accuracy: 0.274000
评价:
shit。 k值变大,准确率会高一点。
关于L1距离的镶嵌问题

- cs231n课上说对于标签是有意义时,L1距离可能会比L2距离效果更好。L2距离是一个圆,它分辨不出任何变化。
- 使用KNN会出现维度灾难。
- 答案应为1和3。 1: 减去均值,L1距离总体不变(与其他距离的大小不变)。 3:减去均值,除以标准差,同1。 若为2,则可能变化,所有图在一个像素的均值有所不同,距离大小比较可能会变化。
耗时
# Let's compare how fast the implementations are
def time_function(f, *args):
"""
Call a function f with args and return the time (in seconds) that it took to execute.
"""
import time
tic = time.time()
f(*args)
toc = time.time()
return toc - tic
two_loop_time = time_function(classifier.compute_distances_two_loops, X_test)
print('Two loop version took %f seconds' % two_loop_time)
one_loop_time = time_function(classifier.compute_distances_one_loop, X_test)
print('One loop version took %f seconds' % one_loop_time)
no_loop_time = time_function(classifier.compute_distances_no_loops, X_test)
print('No loop version took %f seconds' % no_loop_time)
# You should see significantly faster performance with the fully vectorized implementation!
# NOTE: depending on what machine you're using,
# you might not see a speedup when you go from two loops to one loop,
# and might even see a slow-down.

个人笔记本,且样本小,不具参考价值。
交叉验证
既将训练集随机分成几个folds,然后将其中一个folds作为验证集,其余folds为训练集。在训练集上训练,在验证集上进行超参数调参,选取最好的一组超参数,最后到测试集验证模型的鲁棒性。
- 题目提示使用
np.array_split()函数将数组分割

num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
################################################################################
# TODO: #
# Split up the training data into folds. After splitting, X_train_folds and #
# y_train_folds should each be lists of length num_folds, where #
# y_train_folds[i] is the label vector for the points in X_train_folds[i]. #
# Hint: Look up the numpy array_split function. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
X_train_folds = np.array_split(X_train,num_folds)
Y_train_folds = np.array_split(y_train,num_folds)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
- 以
k为条件外部循环,以i为条件内部循环,i为从0~num_folds的序号,表示num_folds次交叉验证。 - 首先
i为测试图形,其余folds为训练图像。使用indx数组装载训练图像序号。然后将测试图像和训练图像分别赋值为X_test_n、X_train_n, 其中y_test_n和y_train_n为其对应标签。 - 使用
np.concatenate(list,axis=0)进行横轴方向的拼接。 - 训练、预测、将准确率复制到数组中
# A dictionary holding the accuracies for different values of k that we find
# when running cross-validation. After running cross-validation,
# k_to_accuracies[k] should be a list of length num_folds giving the different
# accuracy values that we found when using that value of k.
k_to_accuracies = {}
################################################################################
# TODO: #
# Perform k-fold cross validation to find the best value of k. For each #
# possible value of k, run the k-nearest-neighbor algorithm num_folds times, #
# where in each case you use all but one of the folds as training data and the #
# last fold as a validation set. Store the accuracies for all fold and all #
# values of k in the k_to_accuracies dictionary. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for k in k_choices:
curr_acc=[]
for i in np.arange(num_folds):
#indx = np.array([j for j in range(num_folds) if j!=i])
indx = np.array([j for j in range(num_folds) if j!=i])
X_test_n = X_train_folds[i]
Y_test_n = Y_train_folds[i]
np.array(X_train_folds)[indx]
X_train_n = np.concatenate(np.array(X_train_folds)[indx],axis=0)
Y_train_n = np.concatenate(np.array(Y_train_folds)[indx],axis=0)
classifier = KNearestNeighbor()
classifier.train(X_train_n, Y_train_n)
dists = classifier.compute_distances_no_loops(X_test_n)
y_test_n_pred = classifier.predict_labels(dists, k)
num_correct = np.sum(y_test_n_pred == Y_test_n)
accuracy = float(num_correct) / len(Y_test_n)
curr_acc.append(accuracy)
k_to_accuracies[k]=curr_acc
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
输出结果如此(部分截图):

小结
图像分类步骤以及数据驱动方法
- 需要有数据集,并且随机分配,分成训练集、验证集、测试集
- 完成分类器书写工作
- 创建分类器、传入参数、进行训练(得出距离矩阵)、验证结果
- 通过验证集得出最佳的 k
- 使用最佳的 k ,对测试集进行预测,得到最终模型效果。
理解如何分配训练、验证、测试集
- 可能要使用
np.random.choice函数或np.random.shuffle函数等,随机分配训练集和测试集。 - 交叉验证的步骤,就是训练集以
num_folds为循环条件,i为验证图像,其余为训练图像,将对应序号的图像装入对应数组。然后训练、预测,将精确度保存,然后重复循环num_folds次。 - 最后比较精确度,选取最佳参数k
KNN分类器
- 传参、L2距离计算函数、预测函数
- 预测函数就是将测试图像与训练图像进行距离计算,选取前k个最短距离,然后将出现频率最大的label作为预测结果,返回预测结果数组。