Pytorch tutorial
Pytorch tutorial
常用功能:
torch.tensor与np.array
np.array([3,4,5.])
torch.tensor([3,4,5.])
互相转化:
torch.from_numpy(x_numpy)
x_torch.numpy())
求范数:
np.linalg.norm(x_numpy)
torch.norm(x_torch)


求均值
np.mean(x_numpy,axis=0)
torch.mean(x_torch,dim=0))
Tensor.view()
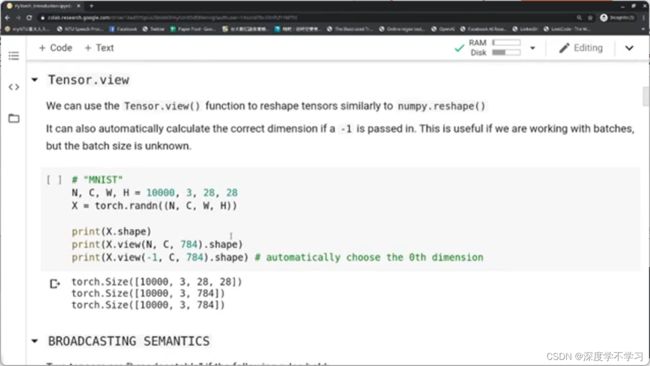
N,C,W,H=10000,3,28,28
X=torch.randn((N,C,W,H))#randn加入随机噪声random noise
X.shape
X.view(N,C,784).shape
X.view(-1,C,784).shape
Broadcast
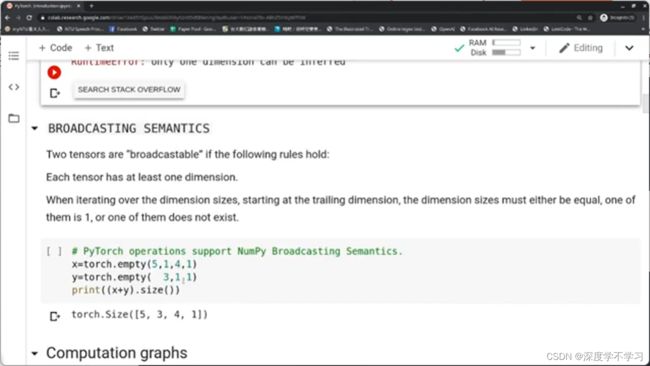
要求至少有一个维度,且对应的维度要么相等,要么有一个是1,要么其中一个不存在。
x=torch.empty(5,1,4,1)
y=torch.empty( 3,1,1)
print((x+y).size())
维度广播时,torch会以大的为主
得到torch.Size([5,3,4,1])
把数据放到gpu上
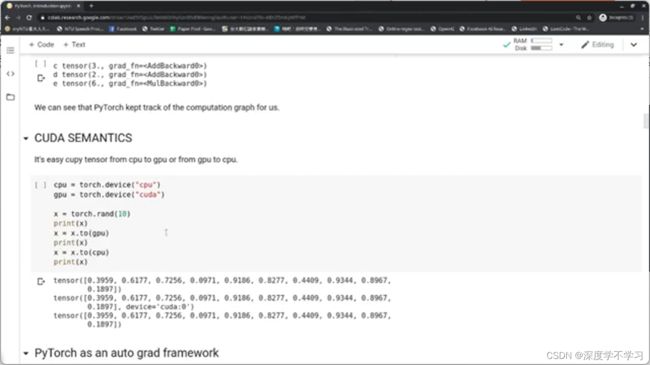
自动微分

def f(x):
return (x-2)**2
def fp(x)
return 2*(x-2)
x=torch.tensor([1.0],requires_grad=Ture)
y=f(x)
y.backward()#计算梯度
print(fp(x))
print(x.grad)
相等
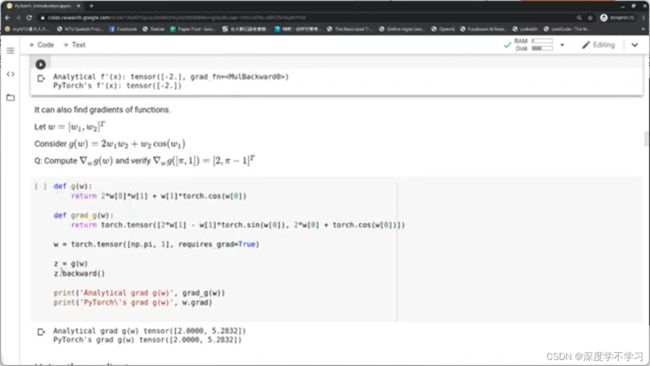
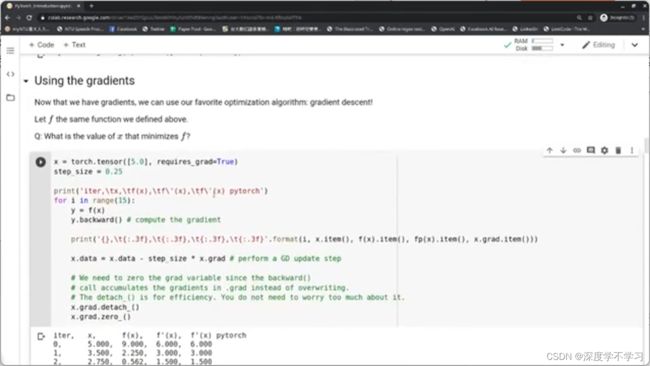
使用梯度:
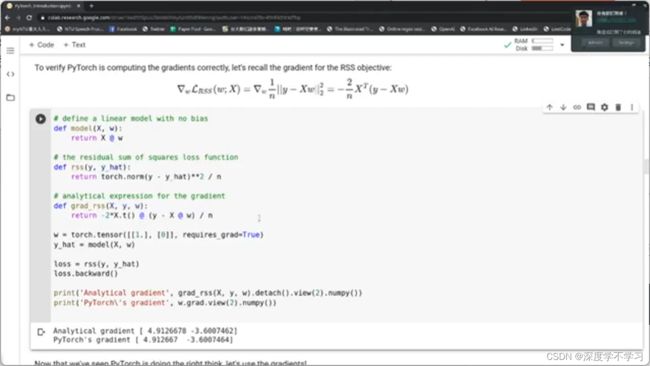
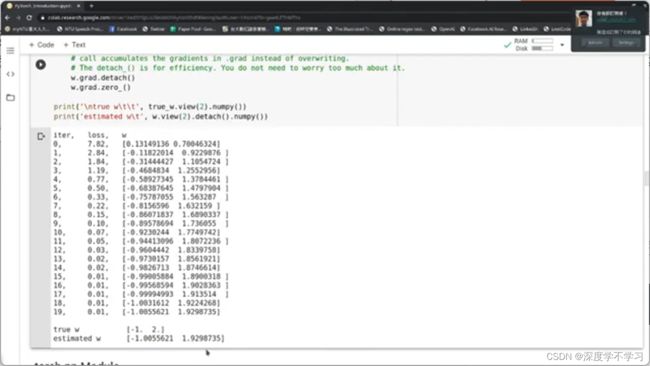
线性回归:

torch.nn.Module
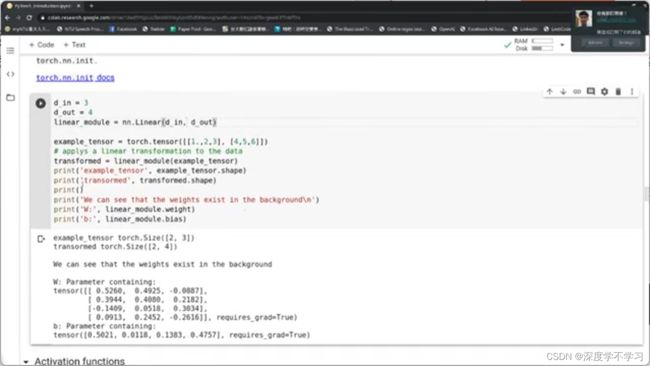
Activation functions:

Sequential:将mudule结合在一起
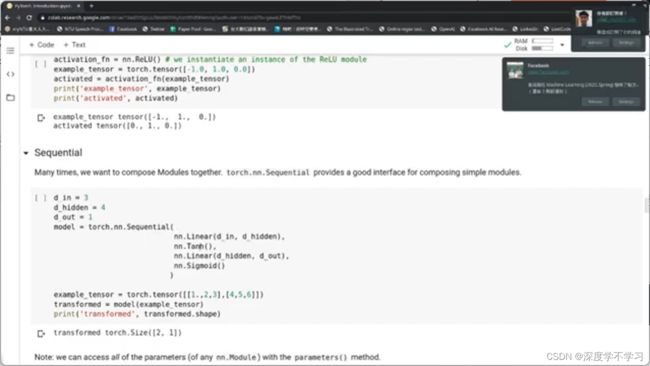
d_in=3
d_hidden=4
d_out=1#表示参数的dimension
model=torch.nn.Sequential(
nn.Linear(d_in,d_hidden),
nn.Tanh(),
nn.Linear(d_hidden,d_out),
nn.Sigmoid()
)
example_tensor=torch.tensor([[1.,2,3],[4,5,6]])
transformed=model(example_tensor)
print(transformed.shape)
Model的参数:

params=model.parameters()
for param in params:
print(param)
Loss functions:
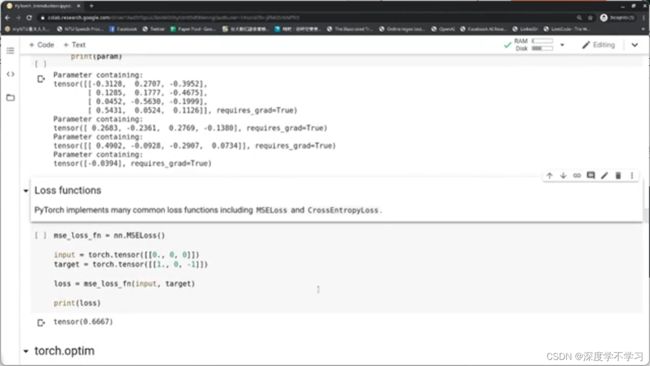
mse_loss_fn=nn.MSELoss()
input=torch.tensor([[0.,0,0]])
target=torch.tensor([[1.,0,-1]])
loss=mes_loss_fn(input,target)
print(loss)
tensor(0.6667)
torch的优化器:
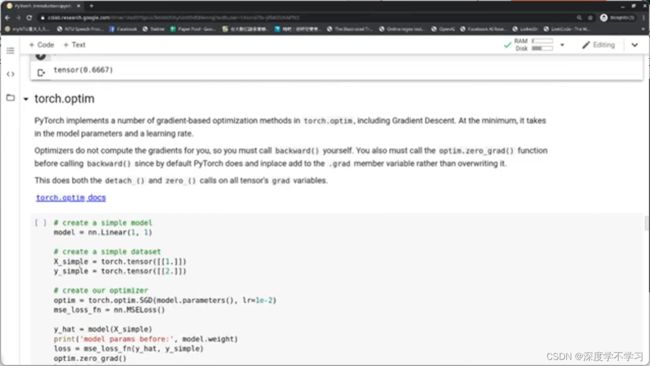
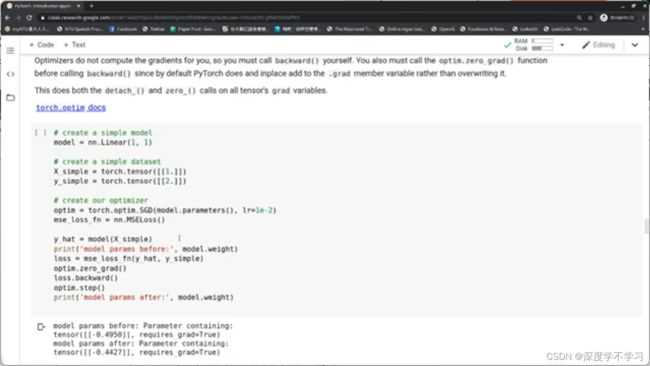
#先建立一个简单的model
model=nn.Linear(1,1)
#建立简单的数据集
X_simple=torch.tensor([[1.]])
Y_simple=torch.tensor([[2.]])
#建立optimizer
optim=torch.optim.SGD(model.parameters(),lr=1e-2)
mse_loss_fn=nn.MSELoss()
y_hat=model(X_simple)
print('model params before:',model.weight)
loss=mse_loss_fn(y_hat,y_simple)
optim.zero_grad()#先将gradient清0,因为每次循环backwards时会将gradient累积起来。
loss.backward()#计算梯度
optim.step()#优化,使用计算得到的梯度进行gradient descent
print('model params after:',model.weight)
使用GD方法自动微分的线性回归:
选用连续的数据
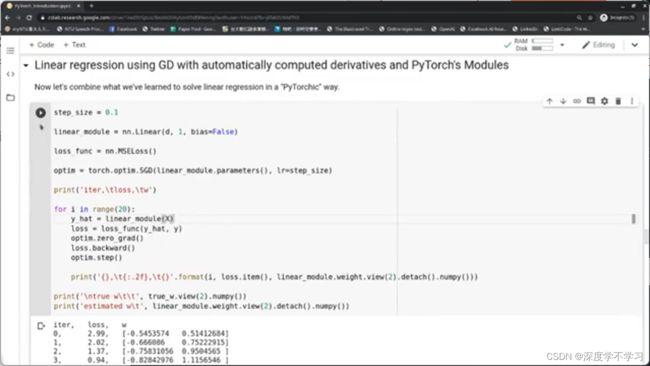
使用SGD方法自动微分的线性回归:
每个循环选取的sample随机

NN:

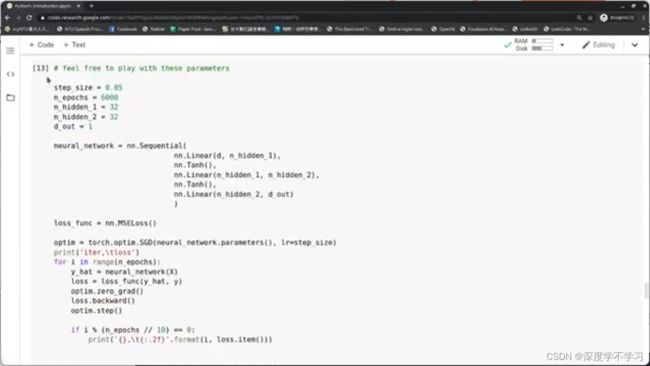
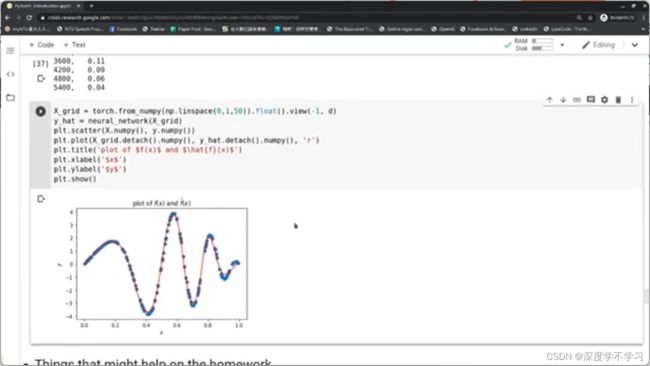
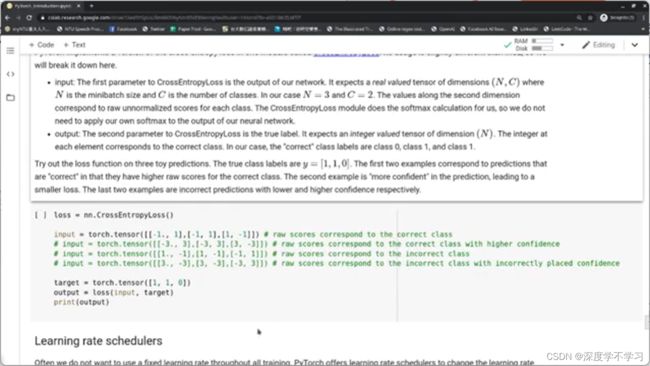
Crossentropy:
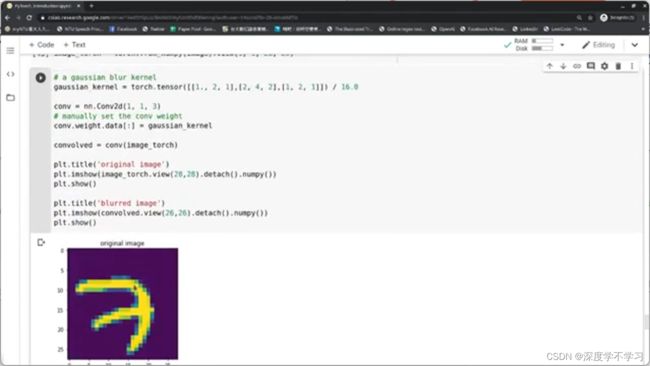
Convolutions:
Custom Datasets:
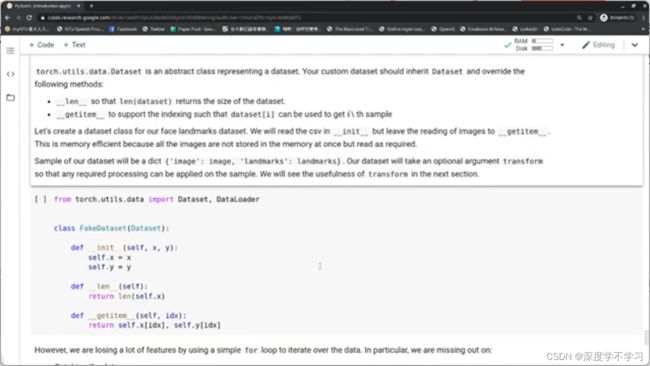
继承Dataset
from torch.utils.data import Dataset,DataLoader
class FakeDataset(Dataset):
def __init__(self,x,y):
self.x=x
self.y=y
def __len__(self):
return len(self.x)
def __getitem__(self,idx):
return self.x[idx],self.y[idx]
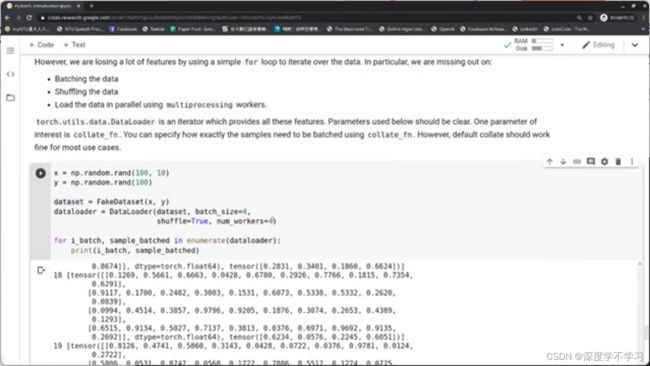
改变浮点数位数,加快计算速度: