推荐系统的链路一致性与position-bias建模

©作者 | Recommender
研究方向 | 推荐排序算法

前言
在大多数搜广推场景中,广泛存在着各种各样的 bias。在不同的场景中,不同的 bias 造成的影响不同。比如推荐系统链路中存在的不一致性导致选择性偏差(多目标架构中的多阶段排序过程,存在于端上曝光以前),在端后影响较大的 bias 为曝光 bias、position bias 等。
推荐链路又是一个闭环反馈,在循环中无疑是强化加剧了这种 bias,导致系统性的流行性偏差和推荐结果的不公平性。短期内在用户体验上感知不强,但逐渐同向收敛,导致信息茧房,降低推荐结果的多样性和惊喜度;推荐内容的同质化倾向严重,使整体内容池的分发生态劣化。本文主要针对多阶段的排序部分,梳理推荐链路中的一致性建模策略;另外针对端上曝光后典型存在的 position bias 问题,对比 PAL 和 DPIN 两种模型的建模思路和实现方案。
重点推荐 SIGIR 对纠偏主题的两篇最佳论文,对更深刻地认识推荐系统中的偏差很有帮助。
1. “Should I follow the crowd? A probabilistic analysis of the effectiveness of popularity in recommender systems.” The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
2. “Controlling fairness and bias in dynamic learning-to-rank.” Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020.

多阶段排序的一致性建模
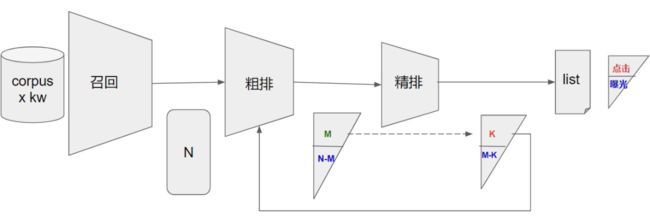
所谓一致性建模,主要解决的是线上和线下的不一致性 bias。线上各阶段排序模型的功能,均是选择 top-k 集合的问题,只是选择取向不同。每个模块都是学习下一阶段的正样本,比如精排模型是在其吐出的展示集合里学习用户点击的集合,对应着粗排也是在其吐出的集合里学习精排想要的集合。但是在线下训练模型时,经常面对的问题是无法真实地还原线上环境,引入了模块间对目标集合选择的不一致性。
纵观整个推荐链路,每个模块历史上均存在着不一致性。但基本的解决思路还是相近的,既实现模块间解耦,也在选择集合时实现递进式的目标对齐和模块间一致性建模。以下对不同的漏斗模块逐步拆解,介绍对应的解决方案。
2.1 粗排阶段
粗排的发展路线主要还是受架构和算力的约束。远古时期的粗排模型作为小精排,分担性能压力。随着架构升级和算力提升,逐渐独立解耦,发展为独立模块作优化。对更多种特征支持度更高,更复杂的模型适应性更高。整体来说粗排部分逐渐丢弃历史上作为小精排的角色,作为推荐漏斗的一部分参与子集选择。
粗排线上推理时面对的问题是,对于多路召回或召回后叠加的漏斗吐出的候选集合,挑选出后续链路(这里主要说精排,多漏斗链路类似)最需要的 top-K 子集合。粗排的学习目标,归根到底是学习精排。线上面对的候选集量级更大,离线的训练集对应也要更多,扩展其感受野。实现链路目标一致性,便是粗排要选择出精排需要的集合。因此对精排吐出的集合建模,同时对精排不认可的候选集合作负采样。对齐线上精排想要的集合。相对完整地复现线上的推理环境。
2.2 精排阶段
精排的建模大多是基于曝光和点击样本,学习用户真实有效的兴趣。从多目标角度来看,就是从不同方面对候选集进行预估,点击、时长、完播、互动等等。对于精排模型线上面临的是粗排吐出的集合,进一步通过多目标融合排序,得到“十项全能”的候选子集合(参考:推荐系统中的多任务学习与多目标排序工程实践 [10])。
因此如果仅用曝光后的数据训练模型,则会导致离线面对的是线上预估样本的子集,造成选择性偏差,通过闭环反馈循环,强化偏差,产生更大的流行性偏差,导致预估和内容生态问题。下面简单介绍美团的做法,核心思路是补充样本和多阶段训练,拓宽精排模型的感受野,优化可能存在的生态问题。补充样本的做法如下:
主流量样本补充:对样本按照其历史点击率,拟合线上点击率分布进行采样
随机游走进行负样本抽取,对 label 优化进行控制置信度。
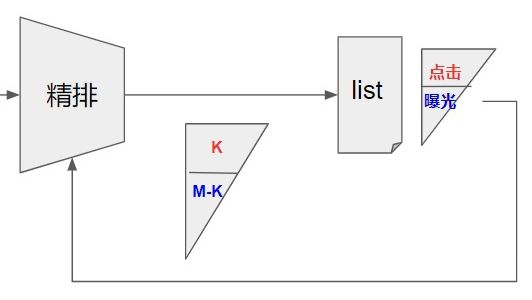
多阶段训练:简言之就是对全量样本训练后,再训练补充样本。此处包含两个逻辑:
1. 保留部分全量采样样本,维持原优化方向不至于处于“跳出”局部最优阶段,为负样本“保驾护航”;
2. 补充置信的负采样样本,使得模型在整个训练阶段的末期扩展感受野。
一般来说这里直接性的疑问,就是为什么不全部合并起来一起训练。如果全部合并打散训练,极大可能导致负采样样本信息在全量样本中淹没;此外,多阶段训练最大的优势就是可以将初次训练的模型对齐 base 的效果,然后通过控制后阶段不同样本的强度,拓宽其感受野。具体实践中,在保证基础指标的前提下,联合控制多阶段中多样本参与训练的强度。相比粗排,精排阶段仅强化对部分负样本的感知,理论上利好生态,特别是对精排阶段难曝光的私域流量有较大改善。
2.3 重排阶段

重排阶段参考价值比较大的是阿里两阶段重排框架和快手重排序演进的方案。核心思路均是将重排阶段拆解为两阶段:首先通过多队列产生队列,构成丰富的 list 候选集;然后通过 list-wise 模型选取最佳队列,实现 session 最优。这里可以类比为召回-排序的模块,只不过参与的项有 item 变为 item 的 list,排序问题由 point-wise 变为了 list-wise。
如果在训练的时候仅用展示 list,通过后验统计得到正样本,也是存在诸多不一致性的,此外还存在比较严重的 position-wise(靠后 session 的消费统计一定偏差)。同所有的排序阶段,个人认为也是存在线下 & 线上的不一致性的。而且 list-wise 的学习受当前推荐闭环反馈的影响较大,容易导致仅对当前推荐列表拟合较好的问题,因此对建模的要求更高。(参考美团 DPIN 论文验证随机流量上的实验思路)
除此以外,想从另一种角度对比 point-wise 和 list-wise 模型:
point-wise 的训练可以通过历史 I-I 共现,实现样本穿越(跨样本 item),学习特征交互后稳定的 item 向量空间;(参考:特征交互建模:从笛卡尔积到 CAN 网络 [11])
list-wise 模型评估的是各个 item 组合后的结果,因此不同 list 的组合数超高,与高热 corpus 的量级有关。虽然 list 共现频率很低,但 list-wise 模型主要建模 session 内的连续语义信息,使最终选择的序列有较好的画风,消费中保持兴趣的连贯性和兴趣的自然泛化。
2.4 一致性建模总结
多阶段的排序模块中,各模型的优化目标就是后续漏斗所需要的的子集合。对于解决线上 & 线下不一致性的问题,基本解决思路还是瞄准下一级想要的集合,构造相对完备的负样本,对离线训练的模型复现线上见识过的样本分布。实现整个端上曝光以前整个推荐链路中的目标一致性建模。

Position-Bias纠偏方案
在广告场景中,端上曝光以后的位置偏差会使得展示位高的 item 点击率偏好,因为整个推荐闭环就是鸡生蛋,蛋生鸡的关系。展示位偏高的 item 进入样本,训练时贡献较多梯度,决定着学习和优化的方向,在推理时模型对这些相关的 item 打分自然有偏向,导致在整个候选集在分发上存在不公平性,随着闭环反馈进一步导致流行性偏差。直观的方式是将 position 信息喂入模型,希望模型学到不同的 item 在不同的位置上的隐含信息。但在推理时由于并不包含该信息,因此对应着有两种方式实现线上预估,分别是:默认位置填充,和位置遍历的方式。
3.1 PAL

该模型对用户 u 在上下文 c 中对第 k 个位置上第 i 个广告点击率建模,将点击率拆解为曝光概率和兴趣相关概率相乘的模式。模型学习这两个子目标,推理时将两个预估分相乘作为最终的排序分。
训练时通过离线引入位置信息进行联合优化学习,在线上推理时填充默认值(比如,首位)实现。

3.2 DPIN
DPIN 是美团 2021 年对广告系统位置偏差的优化模型,思路是抛弃了 PAL 提出的两概率相乘的建模方案,而是组合位置和候选集的纠偏策略,直接预测公式左侧的点击率。相对于借助中间的曝光概率,这里建模更为直接。

模型本身依旧是个 point-wise 模型,只是集成用户在各位置上的历史序列特征及其发生时的上下文特征,然后通过多级 Transformer 实现深度位置语义建模。将候选集兴趣相关信息和各位置语义信息拼接,得到广告在各个位置上的融合信息。最后通过最后的神经网络学习融合组合的点击率。预测目标是位置上的多分类问题,将广告放在对应的位置上。线上排序时按照点击率和 bid 的乘积进行贪婪排序。对不同的位置,依次挑选候选集填充。
位置偏差纠正很容易受现推荐列表的影响,很容易只是对当前推荐闭环拟合的好(只是学到了历史样本中,对应广告放在对应位置上),并没有真正解决位置偏差的问题。因此论文补充在随机流量上的实验,说明模型是实现了用户、上下文、位置、广告的联合建模,缓解 position bias。

总结
最近参与推荐系统中纠偏的部分工作,客户端曝光以前的偏差,主要存在推荐的级联链路中,每个模块面对不同量级的候选集时,选择出满足下一阶段需要的子集合。对多阶段的模型补充线上负样本,明确各模块的定位,实现线上&线下的一致性,整个链路上呈现递增式的级联放大。对端上曝光以后的阶段,主要存在的是位置偏差,在推荐闭环反馈作用下,进一步导致流行性偏差。
简单介绍了两个模型 PAL 和 DPIN,最后对比了两种不同的建模思路。推荐系统中广泛存在着不同的 bias,一般在消费指标上体现得不明显;但从业务角度来看对整个推荐的生态、内容结构以及受潜移默化影响的用户结构都是最重要的。(参考:推荐系统 Bias 大全 [12])

参考链接
[1] Louis:召回和粗排负样本构造问题:
https://zhuanlan.zhihu.com/p/352961688
[2] 水哥:推荐系统全链路(2):召回粗排精排-级联漏斗(上):
https://zhuanlan.zhihu.com/p/396951216
[3] 萧瑟:阿里定向广告最新突破:面向下一代的粗排排序系统COLD:
https://zhuanlan.zhihu.com/p/186320100
[4]《COLD: Towards the Next Generation of Pre-Ranking System》:
https://arxiv.org/abs/2007.16122
[5] KDD Cup 2020 Debiasing比赛冠军技术方案及在美团的实践:
https://tech.meituan.com/2020/08/20/kdd-cup-debiasing-practice.html
[6]《Revisit Recommender System in the Permutation Prospective》
https://arxiv.org/abs/2102.12057
[7] 渠江涛:重排序在快手短视频推荐系统中的演进:
https://mp.weixin.qq.com/s/OTyEbPCBh1NHogPM7bBtvA
[8] (PDF) PAL: a position-bias aware learning framework for CTR prediction in live recommender systems:
https://www.researchgate.net/publication/335771749_PAL_a_position-bias_aware_learning_framework_for_CTR_prediction_in_live_recommender_systems
[9] SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案:
https://tech.meituan.com/2021/06/10/deep-position-wise-interaction-network-for-ctr-prediction.html
[10] 推荐系统中的多任务学习与多目标排序工程实践
https://zhuanlan.zhihu.com/p/422925553
[11] 特征交互建模:从笛卡尔积到 CAN 网络
https://zhuanlan.zhihu.com/p/458588237
[12] 推荐系统 Bias 大全
https://mp.weixin.qq.com/s/2HGmzAo1kDrwfsVTYIFJDQ
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
