Matplotlib&Pandas教程
Matplotlib简介
Matplotlib是一个Python 2D绘图库,Matplotlib可用于Python脚本,Python和IPython shell,jupyter笔记本,Web应用程序服务器等。
Figure: 在任何绘图之前,我们需要一个Figure对象,可以理解成我们需要一张画板才能开始绘图
import matplotlib.pyplot as plt
fig = plt.figure()
Axes:在拥有Figure对象后,在作画前还需要轴,没有轴就没有绘图基准
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set(xlim=[0.5, 4.5], ylim=[-2, 8], title='An Example Axes',
ylabel='Y-Axis', xlabel='X-Axis')
plt.show()
fig.add_subplot(para):
fig = plt.figure()
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
Multiple Axes:
fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].set(title='Upper Left')
axes[0,1].set(title='Upper Right')
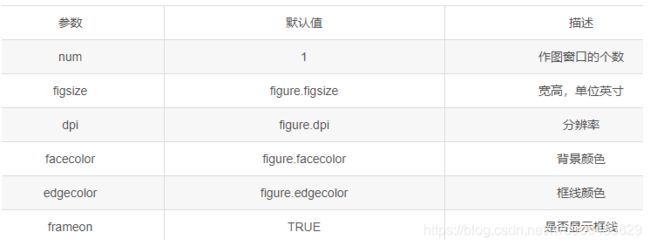
Axis Axes和Figure三者关系:
初步绘制曲线
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-2, 6, 50) # 创建一个numpy数组,x包含了从-2到6之间等间隔的50个值
y1 = x + 3 # 曲线 y1
y2 = 3 - x # 曲线 y2
plt.figure() # 定义一个图像窗口
plt.plot(x, y1) # 绘制曲线 y1
plt.plot(x, y2) # 绘制曲线 y2
plt.show()
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)在指定间隔范围内返回均匀间隔的数字,在[start, stop]范围内计算,返回num个(默认50)均匀间隔的样本
plot()函数的参数除了数据本身,还可以指定点线的属性,包括线段类型、颜色,点的形状、大小等
plt.plot(x,y, # 输入数据点
color = 'green', # 点之间线段的颜色
linestyle = 'dashed', # 线段的类型: 虚线
marker = 'o', # 数据点的绘制方式
markerfacecolor = 'blue', # 数据点的颜色
markersize = 12 # 数据点的大小
)
简单修饰
设置颜色 线条类型,给横纵轴设置上下限
import matplotlib.pyplot as plt
import numpy as np
# 创建一个点数为 8 x 6 的窗口, 并设置分辨率为 80像素/每英寸
plt.figure(figsize=(8, 6), dpi=80)
# 再创建一个规格为 1 x 1 的子图
plt.subplot(111)
x = np.linspace(-2, 6, 50)
y1 = x + 3 # 曲线 y1
y2 = 3 - x # 曲线 y2
# 绘制颜色为蓝色、宽度为 1 像素的连续曲线 y1
plt.plot(x, y1, color="blue", linewidth=1.0, linestyle="-")
# 绘制颜色为紫色、宽度为 2 像素的不连续曲线 y2
plt.plot(x, y2, color="#800080", linewidth=2.0, linestyle="--")
# 设置横轴的上下限
plt.xlim(-1, 6)
# 设置纵轴的上下限
plt.ylim(-2, 10)
# 设置横轴标签
plt.xlabel("X")
#设置纵轴标签
plt.ylabel("Y")
plt.show()
设置精准刻度
# 设置横轴精准刻度
plt.xticks([-1, -0.5, 0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, 5.5])
# 设置纵轴精准刻度
plt.yticks([-2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
plt.show()
注: xticks() 和 yticks() 需要传入一个列表作为参。.该方法默认是将列表的值来设置刻度标签,如果你想重新设置刻度标签,则需要传入两个列表参数给 xticks() 和 yticks() 。第一个列表的值代表刻度,第二个列表的值代表刻度所显示的标签。
添加图例
如果需要在图的左上角添加一个图例。我们只需要在 plot() 函数里以「键 - 值」的形式增加一个参数。首先我们需要在绘制曲线的时候,增加一个 label 参数,然后再调用 plt.legend() 绘制出一个图例。plt.legend() 需要传入一个位置值。
# 绘制颜色为蓝色、宽度为 1 像素的连续曲线 y1
plt.plot(x, y1, color="blue", linewidth=1.0, linestyle="-", label="y1")
# 绘制颜色为紫色、宽度为 2 像素的不连续曲线 y2
plt.plot(x, y2, color="#800080", linewidth=2.0, linestyle="--", label="y2")
plt.legend(loc="upper left")
Pandas教程
pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
# 引入pandas包
import pandas as pd
pandas有两个主要数据结构:series和DataFrame
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的**数据标签(即索引)**组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
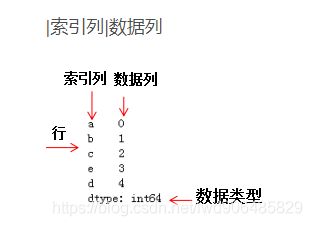
1、pandas Series构造函数
pandas.series(data, index, dtype, copy)
data: 支持多种数据类型,如ndarray, list, constants
index:索引值必须唯一,与data长度相同,默认为np.arrange(n)
dtype:数据类型
copy:是否复制数据,默认为flase
2、创建一个空的Series
#import the pandas library and aliasing as pd
import pandas as pd
s = pd.Series()
print (s)
3、从ndarray创建一个Series
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])
print (s)
4、从字典创建一个Series
# import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data)
print (s)
5、从标量创建一个Series
# import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
s = pd.Series(5, index=[0, 1, 2, 3])
print (s)
6、通过位置访问Series数据
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the first element
print (s[0])
7、通过索引访问Series数据
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve a single element
print (s['a'])
DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
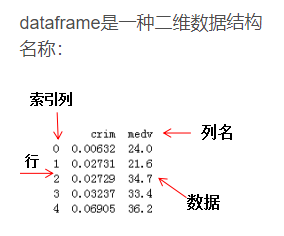
DataFrame构造函数:
pandas.DataFrame(data, index, columns, dtype, copy)
# data 支持多种数据类型 如:ndarray,series,list,dict,ndarray
# index 行标签,如果没有传递索引值,默认值为np.arrange(n)
# columns 列标签,如果没有传递索引值,默认为np.arrange(n)
1、创建一个空的 DataFrame
#import the pandas library and aliasing as pd
import pandas as pd
df = pd.DataFrame()
print (df)
2、从列表创建 DataFrame
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print (df)
二维列表创建DataFrame
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print (df)
执行结果:
Name Age
0 Alex 10
1 Bob 12
2 Clarke 13
3、从 ndarrays/Lists 的字典来创建 DataFrame
# 使用列表作为索引, 创建一个DataFrame
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print (df)
执行结果:
Age Name
rank1 28 Tom
rank2 34 Jack
rank3 29 Steve
rank4 42 Ricky
# index参数为每行分配一个索引
4、从字典列表创建 DataFrame
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
执行结果:
a b c
0 1 2 NaN
1 5 10 20.0
5、从 Series 字典来创建 DataFrame
# 通过传递 Series 字典来创建DataFrame,最终索引是两个Series索引的并集
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print (df)
执行结果:
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
6、读取列
# 从数据帧中读取一列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print (df['one'])
执行结果:
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
7、DataFrame 添加列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
# Adding a new column to an existing DataFrame object with column label by passing new series
print ("Adding a new column by passing as Series:")
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print (df)
print ("Adding a new column using the existing columns in DataFrame:")
df['four']=df['one']+df['three']
print (df)
执行结果:
Adding a new column by passing as Series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
Adding a new column using the existing columns in DataFrame:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
8、DataFrame 读取行
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print (df.loc['b'])
执行结果:
one 2.0
two 2.0
Name: b, dtype: float64
9、添加行
# 使用append()函数将新行添加到DataFrame
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print (df)
执行结果:
a b
0 1 2
1 3 4
0 5 6
1 7 8
Panel
Pandas Panel是3维数据的存储结构,Panel相当于存储DataFrame的字典
axis 0 |
items | item 对应一个内部的数据帧(DataFrame) |
|---|---|---|
axis 1 |
major_axis | 每个数据帧(DataFrame)的索引行 |
axis 2 |
minor_axis | 每个数据帧(DataFrame)的索引列 |
Panel构造函数:
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
# data支持多种数据类型
# items axis=0, major_axis axis=1, minor_axis axis=2
从 DataFrame 字典创建 Panel
#creating an empty panel
import pandas as pd
import numpy as np
data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)),
'Item2' : pd.DataFrame(np.random.randn(4, 2))}
p = pd.Panel(data)
print (p)
执行结果:
<class 'pandas.core.panel.Panel'>
Dimensions: 2 (items) x 4 (major_axis) x 3 (minor_axis)
Items axis: Item1 to Item2
Major_axis axis: 0 to 3
Minor_axis axis: 0 to 2
DataFrame属性和方法
ndim返回对象的维数,DataFrame是一个2D对象
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack']),
'Age':pd.Series([25,26,25,23,30,29,23]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])}
#Create a DataFrame
df = pd.DataFrame(d)
print("Our object is:")
print(df)
print("The dimension of the object is:")
print(df.ndim)
shape返回表示DataFrame的维度的元组。元组(a,b),a表示行数,b表示列数
缺失值处理
为元素赋NaN值或None
import pandas as pd
import numpy as np
ser = pd.Series([0, 1, 2, np.NaN, 9], index=['red', 'blue', 'yellow', 'white', 'green'])
print(ser)
过滤NaN:dropna()
import pandas as pd
import numpy as np
ser = pd.Series([0, 1, 2, np.NaN, 9], index=['red', 'blue', 'yellow', 'white', 'green'])
print(ser.dropna())
为NaN元素填充其他值
fillna()函数用以替换NaN的元素作为参数,所有NaN可以替换为同一个元素
import numpy as np
df = pd.DataFrame([[6,np.nan,6], [np.nan,np.nan,np.nan], [2,np.nan,5]],
index=['blue', 'green', 'red'],
columns=['ball', 'mug', 'pen'])
print(df)
print("--------------")
print(df.fillna(0))
Pandas读写数据
常用读写函数
| 读取函数 | 写入函数 |
|---|---|
| read_csv | to_csv |
| read_excel | to_excel |
| read_hdf | to_hdf |
| read_sql | to_sql |
| read_json | to_json |
| read_html | to_html |
| read_stata | to_stata |
| read_clipboard | to_clipboard |
| read_pickle | to_pickle |
读数据
1、读写CSV(Comma-Separated Values逗号分隔值)
import pandas as pd
csvframe = pd.read_csv("testcsv_01.csv")
print(csvframe)
data = pd.read_csv( my_file.csv )
data = pd.read_csv( my_file.csv , sep= ; , encoding= latin-1 , nrows=1000, skiprows=[2,5])
# sep代表分隔符,nrows=1000表示读取前1000行数据,skiprows=[2,5]表示在读取文件时会移除第2行和第5行
往CSV文件写入数据
import pandas as pd
frame = pd.DataFrame([[0,1,2,3],[4,5,6,7],[8,9,10,11],[12,13,14,15]], columns=['ball', 'pen', 'pencil', 'paper'])
print(frame)
frame.to_csv("testcsv_04.csv")
2、读写Excel文件
import pandas as pd
frame = pd.read_excel("data.xlsx")
print(frame)
import pandas as pd
import numpy as np
frame = pd.DataFrame(np.random.random((4,4)),
index=['exp1','exp2','exp3','exp4'],
columns=['jan2015','Fab2015','Mar2015','Apr2005'])
print(frame)
frame.to_excel("data2.xlsx")
3、读取txt read_table
import pandas as pd
df=pd.read_table('data1.txt', sep='\s+')
print(df)
解析数据时把空行排除在外,文件中的表头或没必要的注释也用不到。使用skiprows选项,可以排除多余行
-
skiprows=5:排除前五行 skiprows=[5]:排除第五行
import pandas as pd df=pd.read_table('data3.txt', sep=',', skiprows=[0,1,3,6]) print(df)