59. 微调(fine-tuning)代码实现
1. 热狗识别
让我们通过具体案例演示微调:热狗识别。 我们将在一个小型数据集上微调ResNet模型。该模型已在ImageNet数据集上进行了预训练。 这个小型数据集包含数千张包含热狗和不包含热狗的图像,我们将使用微调模型来识别图像中是否包含热狗。
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
2. 获取数据集
我们使用的热狗数据集来源于网络。 该数据集包含1400张热狗的“正类”图像,以及包含尽可能多的其他食物的“负类”图像。 含着两个类别的1000张图片用于训练,其余的则用于测试。
解压下载的数据集,我们获得了两个文件夹hotdog/train和hotdog/test。 这两个文件夹都有hotdog(有热狗)和not-hotdog(无热狗)两个子文件夹, 子文件夹内都包含相应类的图像。
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
我们创建两个实例来分别读取训练和测试数据集中的所有图像文件。
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
下面显示了前8个正类样本图片和最后8张负类样本图片。正如所看到的,图像的大小和纵横比各有不同。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);

3. 数据增广
在训练期间,我们首先从图像中裁切随机大小和随机长宽比的区域,然后将该区域缩放为 224×224 输入图像。 在测试过程中,我们将图像的高度和宽度都缩放到256像素,然后裁剪中央 224×224 区域作为输入。 此外,对于RGB(红、绿和蓝)颜色通道,我们分别标准化每个通道。 具体而言,该通道的每个值减去该通道的平均值,然后将结果除以该通道的标准差。
# 使用RGB通道的均值和标准差,以标准化每个通道
# 为什么要这样做,是因为在ImageNet上做了这个事情,所以也要把这个事情搬过来
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 因为我们要用ImageNet上的模型做fine-tuning,所以剪裁大小是224 x 224
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
# 测试集使用的方法也是ImageNet常用的,先resize到256 x 256,再剪裁中央224 x 224
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
4. 定义和初始化模型
我们使用在ImageNet数据集上预训练的ResNet-18作为源模型。 在这里,我们指定pretrained=True以自动下载预训练的模型参数。 如果首次使用此模型,则需要连接互联网才能下载。
# 不仅把模型的定义弄下来了,还把在ImageNet上训练好的parameter拿过来了
pretrained_net = torchvision.models.resnet18(pretrained=True)
预训练的源模型实例包含许多特征层和一个输出层fc。
此划分的主要目的是促进对除输出层以外所有层的模型参数进行微调。
下面给出了源模型的成员变量fc。
pretrained_net.fc

在ResNet的全局平均汇聚层后,全连接层转换为ImageNet数据集的1000个类输出。 之后,我们构建一个新的神经网络作为目标模型。 它的定义方式与预训练源模型的定义方式相同,只是最终层中的输出数量被设置为目标数据集中的类数(而不是1000个)。
在下面的代码中,目标模型finetune_net中成员变量features的参数被初始化为源模型相应层的模型参数。 由于模型参数是在ImageNet数据集上预训练的,并且足够好,因此通常只需要较小的学习率即可微调这些参数。
成员变量output的参数是随机初始化的,通常需要更高的学习率才能从头开始训练。 假设Trainer实例中的学习率为 ,我们将成员变量output中参数的学习率设置为 10 。
finetune_net = torchvision.models.resnet18(pretrained=True) # 把pretrained的模型下载下来之后
# 把最后一个输出层fully- connected随机初始化一个线性层,in_features是512,输出的类别树是2
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
# 再对最后这个全连接线性层做xavier的随机初始化
# ps:前面层的参数都是用pretrained的模型
nn.init.xavier_uniform_(finetune_net.fc.weight);
5. 微调模型
首先,我们定义了一个训练函数train_fine_tuning,该函数使用微调,因此可以多次调用。
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
# 把不是最后一层的所有层的参数都拿出来
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x}, # 这些层使用的学习率是默认的学习率
{'params': net.fc.parameters(), # 最后一层用的学习率是前面的10倍
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else: # 如果没有param_group这个选项,就正常来,和之前一样
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
我们使用较小的学习率,通过微调预训练获得的模型参数。
train_fine_tuning(finetune_net, 5e-5)
运行结果如下:
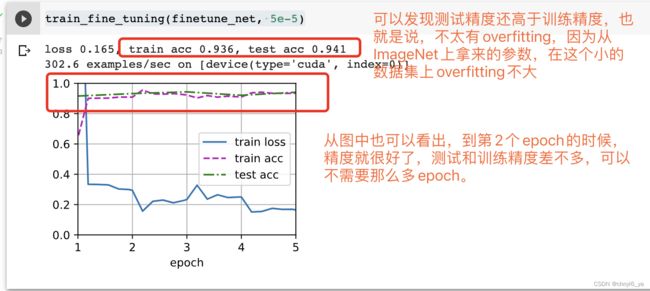
为了进行比较,我们定义了一个相同的模型,但是将其(所有模型参数初始化为随机值)。 由于整个模型需要从头开始训练,因此我们需要使用更大的学习率。
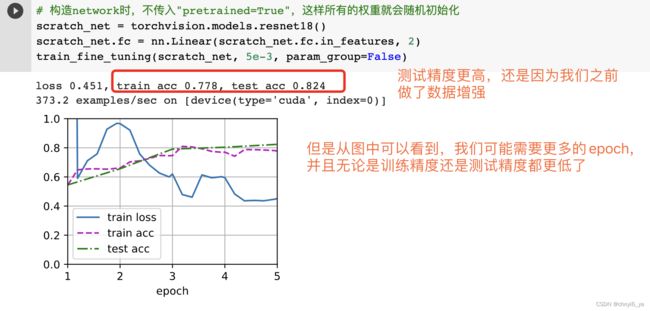
意料之中,微调模型往往表现更好,因为它的初始参数值更有效。
老师建议:从fine-tuning开始,而不是从零开始对数据进行训练,这也是一般的计算机视觉的做法,而且,几乎可以认为,未来所有用于深度学习的应用都会是主要是基于fine-tuning