Hadoop 和 Spark 知识点整理汇总
文章目录
- 前言
- 一、LINUX 系统常用命令汇总
- 二、Hadoop 常用命令汇总
- 三、Hadoop 基本概念
-
- 1. Hadoop 特性
- 2. Hadoop 架构
-
- 2.1 Hadoop 集群
- 2.2 HDFS
- 2.3. YARN
- 四、Hadoop HDFS命令
-
- 1. HDFS 命令通用格式
- 2. 创建与查看 HDFS 目录
- 3. HDFS 与本地计算机之间的文件复制
- 4. 复制与删除 HDFS文件
- 5. 在Hadoop HDFS Web 用户界面浏览 HDFS
- 五、Hadoop MapReduce
-
- 1. MapReduce 介绍
- 2. MapReduce 原理
- 3. MapReduce 集群上的实现
- 4. 不止一个MapReduce:作业链
- 六、Hadoop Streaming
-
- 1. Hadoop Streaming 介绍
- 2. Hadoop Streaming 工作原理
- 3. Hadoop Streaming 执行
- 4. Python 的 MapReduce 框架
- 5. MapReduce 高级工具
- 七、Spark 内存计算
-
- 1. 为什么需要 Spark?
- 2. Spark 基础
-
- Spark 栈
- RDD
- 使用RDD编程
- 3. Spark 执行机制
- 4. 基于 PySpark 的交互性 Spark
- 5. Spark 应用程序模版
- 6. 总结
- 八、分布式分析和模式
-
- 1. 前言
- 2. 键计算
-
- 复合键
- 键空间模式
- pair 与 stripe
- 3. 设计模式
-
- 概要
- 索引
- 过滤
- 4.迈向最后一英里分析
-
- 模型拟合
- 模型验证
- 九、数据挖掘和数据仓储
-
- 1. Hive 结构化数据查询
-
- Hive命令行接口(CLI)
- Hive查询语言
- Hive数据分析
- 2. HBase
-
- NoSQL与列式数据库
- HBase实时分析
- 十、数据采集
-
- 1. 使用Sqoop导入关系数据
-
- 从MySQL导入HDFS
- 从MySQL导入Hive
- 从MySQL导入HBase
- 2. 使用Flume获取流式数据
-
- Flume数据流
- 使用Flume获取产品印象数据
- 十一、使用高级API进行分析
-
- 1. Pig
-
- Pig Latin
- 数据类型
- 关系运算符
- 用户定义函数
- 2. Spark高级API
-
- Spark SQL
- DataFrame
- 3. 总结
- 十二、机器学习
-
- 1. 使用Spark进行可扩展的机器学习
- 2. 协同过滤
- 3. 分类
- 3. 聚类
- 十三、总结:分布式数据科学实战
-
- 1. 数据产品生命周期
-
- 数据湖泊
- 数据采集
- 计算数据存储
- 2. 机器学习生命周期
- 3. 总结
前言
2020年9月至11月,我通过一本理论书简单地学习了 Hadoop 和 Spark 的基本知识,大体上了解了 Hadoop 和 Spark 的一些底层工作机制、基本原理和实用工具等。之后,我又根据另一本实践书学习了 Hadoop 和 Spark 中像是伪分布式环境搭建、集群部署等实践性内容,跑了几个 demo。
但是,随着转而去学其他的知识,关于 Hadoop 和 Spark 的相关内容逐渐被我遗忘。因此,为了避免这两部分内容被我彻底抛弃,同时为了将来找工作时能够回忆起相关知识点,我打算用这篇博客来记录我所学习到的 Hadoop 和 Spark 的重要知识点。
一、LINUX 系统常用命令汇总
这一部分将学习过程中常见的 LINUX 系统命令行命令进行汇总。
| 命令 | 含义 |
|---|---|
| cd <路径> | 切换到目标路径 |
| chomd <权限> <文件> | 控制文件的权限 +:增加权限;-:取消权限 r 读 w 写 x 执行 |
| cp < src > < dst > | 复制文件 |
| echo <内容> | 输出内容到标准输出 |
| ll <目录名称> | 列出来指定目录下的详细结果,包括时间、是否可读写等信息 |
| ls <目录名称> | 列出来指定目录下的简略结果,只列出文件名或者目录名 |
| mkdir <目录名称> | 创建目录 |
| mv < src > < dst > | 移动(剪切)文件 |
| rm <文件名称> | 删除文件 |
| sudo <命令> | 对命令赋予管理员权限 |
| 竖杠 | pipe管道 |
二、Hadoop 常用命令汇总
这一部分将学习过程中常见的 Hadoop 操作系统常见命令进行汇总。
| 命令 | 含义 |
|---|---|
| hadoop fs -命令 | HDFS命令的通用格式 |
| hadoop fs -help | 查看 fs 命令下可用的命令 |
| hadoop fs -mkdir <目录名称> | 创建 HDFS 目录 |
| hadoop fs -mkdir -p <多级目录名称> | 创建 HDFS 多级目录 |
| hadoop fs -ls <目录名称> | 列出指定 HDFS 目录下的文件 如果未指定目录名称,则显示 “/user/登录用户” 下的目录 |
| hadoop fs –chmod/-chgrp/-chown <8进制数> <文件或目录名称> | 更改分布式文件系统上文件的其他用户、组和所有者的 rwx 权限 |
| hadoop fs -copyFromLocal < src > < dst > hadoop fs -put < src > < dst > |
复制本地(local)文件到 HDFS |
| hadoop fs -moveFromLocal < src > < dst > | 剪切本地(local)文件到 HDFS |
| hadoop fs -cat <文件名称> | 读取HDFS目录下的文件内容 |
| hadoop fs –tail <文件名称> | 仅检查文件的最后 1000 字节 |
| hadoop fs -copyToLocal < src > < dst > hadoop fs -get < src > < dst > |
将 HDFS 上的文件复制到本地(local) |
| hadoop fs -moveToLocal < src > < dst > | 将 HDFS 上的文件剪切到本地(local) |
| hadoop fs -cp < src > < dst > | 复制 HDFS 文件到 HDFS 另一文件 |
| hadoop fs -mv < src > < dst > | 移动(剪切) HDFS 文件到 HDFS 另一文件 |
| hadoop fs -rm <文件名称> | 删除 HDFS 文件 |
| hadoop fs -rm -R <目录名称> | 删除 HDFS 目录 |
三、Hadoop 基本概念
1. Hadoop 特性
| 特性 | 含义 |
|---|---|
| 容错性 | 如果一个组件失败,不应导致整个系统出现故障,系统应能降级到较低性能状态。 如果失败的组件恢复了,它应该能够重新加入系统。 |
| 可恢复性 | 发生故障时,不应丢失数据。 |
| 一致性 | 一个作业或任务的失败不应该影响最终的结果。 |
| 可扩展性 | 负载的增加(更多的数据或更多的计算)导致性能下降,而不是出现故障; 资源的增加应使容量按比例增加。 |
2. Hadoop 架构
Hadoop 由两个主要组件组成:HDFS 和 YARN,它们实现了分布式存储和分布式计算。HDFS(Hadoop Distributed File System)是 Hadoop 的分布式文件系统,负责管理存储在集群中磁盘上的数据;YARN(Yet Another Resource Negotiator) 则是集群资源管理器,将计算资源(worker 节点上的处理能力和内存)分配给希望执行分布式计算的应用程序。架构栈如下图所示。

2.1 Hadoop 集群
Hadoop 是一个以协调方式运行的机器集群,然而,Hadoop 其实是运行在集群上的软件的名称,即 HDFS 和 YARN,它们由在一组计算机上运行的 6 种后台服务组成。
所谓集群,就是运行 HDFS 和 YARN 的一组计算机,每台计算机被称为一个节点。集群可以有一个节点,也可以有成千上万个节点,但是所有集群都是水平扩展的,这意味着在添加更多节点时,集群以线性方式提升容量和性能。Hadoop 中的节点主要分为两类:
| 节点类型 | 功能 |
|---|---|
| master 节点 | 这些节点为 Hadoop 的 worker 节点提供协调服务,通常是用户访问集群的入口点。 没有master 节点,协调就不复存在,也就不可能进行分布式存储或计算。 |
| worker 节点 | worker 节点运行的服务从 master 节点接受任务——存储或检索数据、运行特定应用程序。 worker 节点通过并行分析运行分布式计算。 |
HDFS 和 YARN 都有多个 master 服务,负责协调运行在各个 worker 节点上的 worker 服务。worker 节点实现 HDFS 和 YARN 的 worker 服务。HDFS 的 master 服务和 worker 服务如下所示:
| HDFS 服务名称 | 功能 |
|---|---|
| NameNode(master 服务) | 用于存储文件系统的目录树、文件元数据和集群中每个文件的位置。 如果客户端想访问 HDFS,必须先通过从 NameNode 请求信息来查找相应的存储节点。 |
| Secondary NameNode(master 服务) | 代表 NameNode 执行内务任务并记录检查点。 虽然它叫这个名字,但它并不是 NameNode 的备份。 |
| DataNode(worker 服务) | 用于存储和管理本地磁盘上的 HDFS 块,将各个数据存储的健康状况和状态报告给 NameNode。 |

从宏观上看,当从 HDFS 访问数据时,客户端应用程序必须先向 NameNode 发出请求,以在磁盘上定位数据。NameNode 将回复一个存储数据的 DataNode 列表,客户端必须直接从 DataNode 请求每个数据块。注意,NameNode 不存储数据,也不将数据从 DataNode 传递到客户端,而是像交警指挥交通一般,将客户端指向正确的 DataNode。请注意,在较大的集群中,NameNode 和 Secondary NameNode 将驻留在不同的计算机上,从而避免竞争资源。
和 HDFS 类似,YARN 也有两个 master 服务和一个 worker 服务,如下所示:
| YARN 服务名称 | 功能 |
|---|---|
| ResourceManager (master 服务) |
为应用程序分配和监视可用的集群资源(如内存和处理器核心这样的物理资源),处理集群上作业的调度。 |
| ApplicationMaster (master 服务) |
根据 ResourceManager 的调度,协调在集群上运行的特定应用程序。 |
| NodeManager (worker 服务) |
在单个节点上运行和管理处理任务,报告任务运行时的健康状况和状态。 |
与 HDFS 的工作方式类似,如果客户端希望执行作业,就必须先向 ResourceManager 请求资源,ResourceManager 会分配一个应用程序专用的 ApplicationMaster,它在作业的执行过程中会一直存在。ApplicationMaster 跟踪作业的执行,ResourceManager 则跟踪节点的状态,每个 NodeManager 创建容器并在其中执行任务。
2.2 HDFS
HDFS 被设计用于存储非常大的文件,使用流访问数据,有一些注意事项:
- 与占用相同容量的数以亿计的小文件相比,HDFS 更适合处理数量适中但非常大的文件;
- HDFS 采用 WORM 模式,即写一次读多次(write once, read many),它不允许随机写入或追加到文件;
- HDFS 针对文件的大型流式读取进行了优化,不采用随机读取或随机选择。
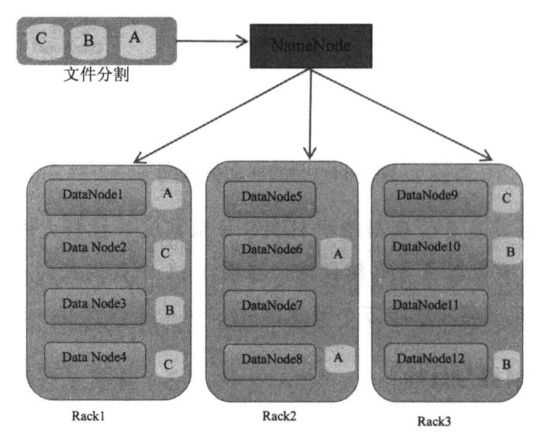
①文件块
HDFS 文件分为多个块,块大小是可以在 HDFS 中读取或写入的最小数据量,小于块大小的文件不占用实际文件系统上一个完整块的空间。为了实现最佳性能,Hadoop 更喜欢分解成小块的大文件,能将许多较小的文件合并成一个大文件就很好。
块将跨 DataNode 复制。默认情况下,块将复制三份,但也可在运行时配置。因此,每个块都将分布在三台计算机和三块磁盘上。即使两个节点都发生了故障,数据也不会丢失。请注意,这意味着集群中的潜在数据存储容量仅为可用磁盘空间的三分之一。
②数据管理
主 NameNode 记录组成文件的块和这些块所在的位置。NameNode 与 DataNode(集群中实际保存块的进程)进行通信。与每个文件相关联的元数据被存储在 NameNode 的 master 节点的内存中,以便进行快速查找。如果 NameNode 停止或发生故障,整个集群都将无法访问。
Secondary NameNode 不是 NameNode 的备份,而是代表 NameNode 执行内务任务。
当客户端应用程序想要读取文件时,它首先从 NameNode 请求元数据,以定位组成文件的块以及存储块的 DataNode 的位置。然后,应用程序直接与 DataNode 通信以读取数据。因此,NameNode 仅仅扮演着日志或查找表的角色,而不是同时读取的瓶颈。
2.3. YARN
YARN 将工作负载管理与资源管理分离,以便多个应用程序可以共享一个集中的公共资源管理服务。通过在 YARN 中提供通用的作业和资源管理能力,Hadoop 不再是一个仅仅专注于 MapReduce 的框架,而成为了一个完整、多应用程序的大数据操作系统。
YARN 的架构图如下图所示,从图中我们可以看出:
- 在 Client 客户端,用户向 ResourceManager 请求执行运算(或执行任务)。
- 在 NameNode 会有 ResourceManager 统筹管理运算的请求。
- 在其他的 DataNode 会有 NodeManager 负责运行,以及监督每一个任务,并且向 ResourceManager 汇报状态。

四、Hadoop HDFS命令
1. HDFS 命令通用格式
利用终端 HDFS 命令对 HDFS 进行操作的示意图如下图所示。

HDFS 通用的命令格式如下:
hadoop fs -命令
用户可以进行所有常规的文件系统操作,例如创建目录,移动、删除和复制文件,列出目录内容,修改集群上文件的权限。要查看 fs 命令下可用的命令,键入:
hadoop fs -help
2. 创建与查看 HDFS 目录
①创建目录
在“终端”程序中输入下列命令,创建HDFS目录:
hadoop fs -mkdir <目录名称>
如果我们要一次性创建多级目录,除了利用上述命令一级一级创建以外,还可以加入参数“-p”:
hadoop fs -mkdir -p <多级目录名称>
②查看目录
在“终端”程序中输入下列命令,查看之前创建的 HDFS 目录
hadoop fs -ls
假设当前登录的用户是 hduser,那么上述命令会显示 “/user/hduser” 下的目录。我们也可以列出指定 HDFS 目录下的文件:
hadoop fs -ls <目录名称>
注意:
- linux 系统中有 ll 和 ls 命令都可以用来查看目录下的内容,但是 HDFS 只有 -ls 命令,没有 -ll 命令一说。
- hadoop fs -ls 命令只能查看一级目录,但是我们可以在该命令上加上 -R 参数(R 代表 recursive(递归))来一次查看所有子目录。
- hadoop fs -ls / 用来查看HDFS根目录
- 可以使用模糊查询,例如 “hadoop fs -ls *.tsv” 来列出目录下文件名相匹配的相关文件
假设显示结果如下图所示:
![]()
上述结果中,第 1 列显示文件的权限模式,第 2 列是文件的副本数(默认情况下,副本数为 3)。请注意,目录不会被复制,因此本例中的此列是短横线( - )。其后依次是用户、组、以字节为单位的文件大小(目录为零)、最后一次修改的日期和时间,以及文件名。
③HDFS 文件权限
权限分三种类型:读(r)、写(w)和执行(x)。这些权限定义了所有者、组和任何其他系统用户的访问级别。对于目录来说,执行权限允许访问目录的内容,但是 HDFS 上文件的执行权限被忽略了。在 HDFS 中,读写权限指定谁可以访问数据,以及谁可以追加文件内容。
每个模式有 10 个槽位。第 1 个槽位是 d ,表示“是目录,否则是文件( - )”。接下来的槽位每 3 个为一组,分别表示所有者、组和其他用户的 rwx 权限。有几个 HDFS 的 shell 命令能管理文件和目录的权限,即我们熟悉的 chmod 、chgrp 和 chown 命令。例如:
hadoop fs –chmod 664 shakespeare.txt
上述 chmod 命令将 shakespeare.txt 的权限更改为 -rw-rw-r-- 。664 是为权限三元组设置的标志的八进制表示。6 的二进制数为 110,这意味着设置了读和写的标志,但没有设置执行标志;完全允许是 7,即二进制数 111;只读是 4,即二进制数 100。 chgrp 和 chown 命令分别更改分布式文件系统上文件的组和所有者。
3. HDFS 与本地计算机之间的文件复制
① 从本地计算机复制文件到HDFS
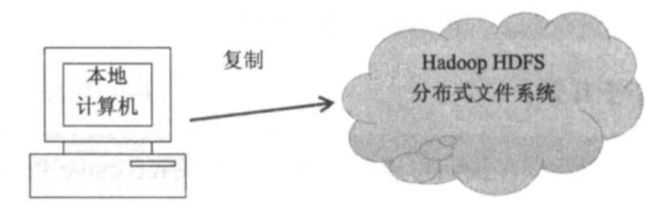
使用下列两个命令均能实现复制本地(local)文件到 HDFS:
hadoop fs -copyFromLocal <从哪复制src> <复制到哪里dst>
hadoop fs -put <从哪复制src> <复制到哪里dst>
整个过程为:copyFromLocal 命令在当前工作目录中搜索要复制的文件,从 NameNode 请求有关该路径的信息,然后直接与 DataNode 通信以传送文件,将其复制到 HDFS 上的目标路径。
注意:
- 复制但不删除本地副本,与复制相对的剪切功能 moveFromLocal 会将本地副本删除。
- 在本地计算机以及远程 HDFS 系统上,都必须考虑相对路径和绝对路径。如果未指定存放位置,那么将直接复制在 “user/当前登录用户/” 目录下。
- < dst >可以仅指定目录,也可以在复制时顺便对文件重命名。
- 使用 copyFromLocal 命令时,如果文件已经存在,系统会回复“File exists”不会复制。但是可以加入 -f(force)选项强制复制并覆盖文件。
- 允许一次复制多个本地文件至HDFS目录,< src >包含多个用空格隔开的文件即可。
- 允许从本地计算机复制整个目录到 HDFS 目录。
- 一定要注意后面加不加 “/”,决定了是复制到当前目录还是当前目录下的同名目录。
put 命令与 copyFromLocal 命令的区别主要有两个:
- 如果文件已经存在,使用 put 命令时系统不会显示文件已经存在,而会直接覆盖;
- put 命令可以接受stdin(标准输入),例如:
- echo abc | hadoop fs -put - /user/hduser/test/echoin.txt
- ls /usr/local/hadoop | hadoop fs -put -/user/duser/test/hadooplist.txt
②读取文件内容
如需读取文件的内容,可使用 cat 命令:
hadoop fs –cat <文件名称>
上述命令会一次列出所有文件内容,如果文件太大,可以加上“| more”或者“| less”,将输出通过管道传递给 more 或者 less 以查看远程文件的内容,命令如下:
hadoop fs –cat <文件名称> | less(或者 | more)
注意:
- more 和 less 均为对文件或其它输出进行分页显示的工具:使用 more 时没有办法向前面翻,只能往后面看;但如果使用了 less,就可以往前往后翻看文件。
还可以使用 tail 命令仅检查文件的最后 1000 字节:
hadoop fs –tail <文件名称>
注意:
- 没有类似 hadoop fs -head 的命令可以用来检查文件的前 1000 字节。不过,可以使用 hadoop fs -cat 并通过管道将文件内容传输到本地 shell 的 head 命令。这种做法很高效,因为 head 命令在读取整个文件之前就终止了远程流。但是以这种方式使用 shell 的 tail 会降低效率,因为在计算输出之前,所有数据都必须从远程文件系统流式传输到本地文件系统。相反, hadoop fs -tail 命令在远程文件中寻址到正确位置,仅通过网络返回所需的数据。
③将 HDFS上的文件复制到本地计算机
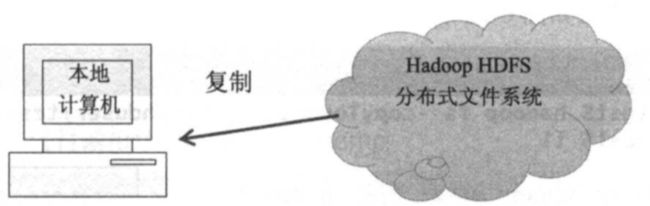
使用下列两个命令均能实现复制 HDFS上的文件到本地计算机:
hadoop fs -copyToLocal <从 hdfs 的哪复制src> <复制到本地的哪dst>
hadoop fs -get <从 hdfs 的哪复制src> <复制到本地的哪dst>
注意:
- dst 可以省略,表示将文件或者目录直接复制到当前目录下.
- 复制但不删除 hdfs 副本,与复制相对的剪切功能 moveToLocal 会将该文件从分布式文件系统中删除。
- get merge 命令复制符合给定模式或指定目录下的所有文件,并将其合并成
本机的单个文件。 - 如果远程系统上的文件较大,可以在管道传输的时候使用压缩工具,原始文件与 压缩后的文件相同,例如:
- hadoop fs –get shakespeare.txt ./shakespeare.from-remote.txt
4. 复制与删除 HDFS文件
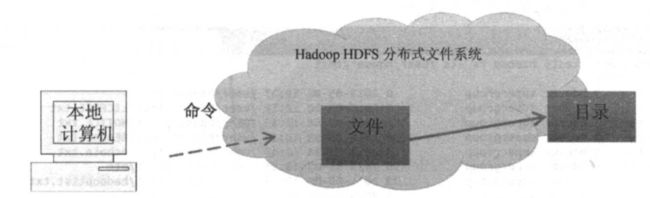
复制HDFS文件,指的是在 HDFS 中复制文件或目录到另一个 HDFS 目录。命令如下:
hadoop fs -cp < src > < dst >
同样,有复制命令就有剪切命令:
hadoop fs -mv < src > < dst >
删除 HDFS 文件的命令如下:
hadoop fs -rm <文件名称>
删除 HDFS 目录及其包含的所有文件的命令如下:
hadoop fs -rm -R <目录名称>
5. 在Hadoop HDFS Web 用户界面浏览 HDFS

我们可以在 Hadoop HDFS web用户界面来浏览 HDFS 目录或文件,网址是——http://master:50070
ResourceManager 也提供了一个 Web 接口来查看作业的状态及日志文件。可以通过托管 ResourceManager 服务的机器的 8088 端口访问 ResourceManager 的 Web UI,此 Web UI 显示所有当前正在运行的作业,以及集群中 NodeManager 的状态。
五、Hadoop MapReduce
1. MapReduce 介绍

当提到 MapReduce 时,通常指的是分布式编程模型。MapReduce 是一个简单但功能强大的计算框架,专门用于在集中管理的机器集群上进行容错的分布式计算。简单来说,Map 就是分配工作,Reduce就是将工作结果汇总整理。
- Map 将任务分割成更小任务,由每台服务器分别运行。
- Reduce将所有服务器的运算结果汇总整理,返回最后的结果。
通过 MapReduce 方式,可以在上千台机器上并行处理巨量的数据,大大减少数据处理的时间。
2. MapReduce 原理
负责分发任务和聚合结果的两类函数分别被称为 map 和 reduce 。这些函数运算的输入和输出数据不是简单的列表或值的集合,MapReduce 其实是利用键值对来协调计算。Python 中 map 和 reduce 函数的伪代码如下所示:
def map(key, value):
# 执行处理
return (intermed_key, intermed_value)
def reduce(intermed_key, values):
# 执行处理
return (key, output)
map 函数以一系列键值对作为输入,然后在每个键值对上进行单独运算。在对输入数据执行了一些分析或变换之后, map 函数输出零个或多个键值对,在以上伪代码中表示为单个元组。整个过程将 map 函数应用于输入列表以创建新的输出列表,如下图所示:

通常来讲,map 操作将进行核心分析或处理,因为这个函数能查看数据集中的每个元素。因此我们能在 map 中实现过滤器:测试每个键值对,确定它是否属于最终数据集;如果是则发出,否则就忽略。在 map 阶段之后,所有发出的键值对将按照键来分组,然后根据键被用于各个 reduce 函数的输入。如下图所示,reduce 函数以一个键和一个值列表作为输入,通常通过聚合操作在整个值列表上进行运算,输出零个或多个键值对。
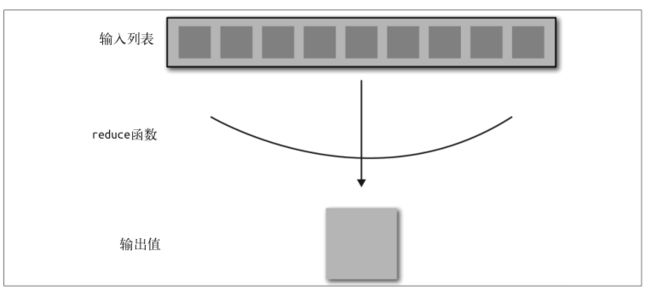
如伪代码所示, reduce 函数是一个有两个参数的函数:一个键(在伪代码中是 intermed_key),以及与之相关联的迭代器或值列表(values)。reducer 对值列表执行最终处理,通常是组合或聚合,然后输出零个或多个键值对。reducer 旨在聚合从 map 阶段输出的大量值,以便将大量数据转换为更小、更易于管理的概要数据。
3. MapReduce 集群上的实现
因为 mapper 对任意列表的每个元素应用相同的函数,所以非常适合被分发到集群的节点上。每个节点获得一个 mapper 操作的副本,并且将 mapper 应用于存储在本地 HDFS 数据节点的数据块中的键值对上。
reducer 需要根据键获取 mapper 的输出作为输入,因此 reducer 的计算也可以被分发出去。每个 reducer 都应该能看到某个独一无二的键的所有值。为了满足该要求,需要 shuffle 和 sort 操作来协调 map 和 reduce 阶段,使 reducer 的输入按键分组并排序。shuffle 和 sort 将 map 阶段的键空间分区,以便将特定键空间分配给特定 reducer。总体来说,MapReduce 的阶段如下图所示。

对上图各阶段的解释如下:
- HDFS 的本地数据以键值对的形式被加载到一个映射过程。
- mapper 输出零个或多个键值对,将计算所得的值映射到一个特定的键上。
- 基于键对这些键值对进行 sort 和 shuffle 操作,然后将它们传递给 reducer,使 reducer 获得键的所有值。
- reducer 输出零个或多个最终的键值对,即输出(归约 map 的结果)。
在拥有几个节点的集群上,MapReduce 流水线的数据流细节如下图所示:

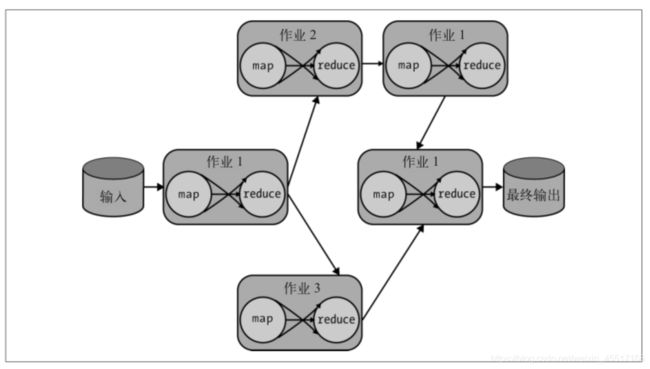
4. 不止一个MapReduce:作业链
复杂的算法或应用程序实际上是通过被称为“作业链”的过程,使用多个 MapReduce 作业执行单个计算来构建的,其中下游 MapReduce 作业的输入是最近的上游作业的输出作业链。如下图所示,通过创建流经中间 MapReduce 作业系统的数据流,可以创建一个分析步骤的流水线,引导我们得到最终结果。

如下图所示, Hadoop MapReduce在运算时需要将中间产生的数据存储在硬盘中。然而,磁盘I/O往往是性能的瓶颈,因此会有读写数据延迟的问题。

六、Hadoop Streaming
1. Hadoop Streaming 介绍
Hadoop Streaming 是一个实用程序,Streaming 作业像普通 Hadoop 作业一样,通过作业客户端传递到集群。但除了可以指定输入和输出的 HDFS 路径的参数外,它还可以指定 mapper 和 reducer 的可执行程序。然后,作业作为普通 MapReduce 作业运行,依然由 ResourceManager 和 MRAppMaster 管理和监控,直到作业完成。
为了执行 MapReduce 作业,Streaming 利用标准 Unix 流进行输入和输出,因此得名 Streaming。mapper 和 reducer 的输入都是从 stdin 读取的。Hadoop 要求由 Python 编写的 mapper 和 reducer 将它们输出的键值对写到 stdout 中。下图演示了 MapReduce 中的这个过程。

注意:
- Hadoop Streaming 中的“流”指的是标准的 Unix 流 stdin 、 stdout 和 stderr(标准错误流)。
- 使用 Python 的 Hadoop 开发人员不一定能够通过 Hadoop Streaming 技术访问完整的 MapReduce API(partitioner、输入和输出格式等功能必须用 Java 编写)。
2. Hadoop Streaming 工作原理
当 Streaming 执行作业时,一般经历以下几步:
- 每个 mapper 任务将在自己的进程内启动提供的可执行文件;
- 将输入数据转换为文本行并将其输送到外部进程的 stdin 的同时,从 stdout 收集输出。输入数据的转换通常是直接将值序列化,因为数据是从 HDFS 读取的,其中每行都是一个新值。mapper 要求输出是键或值格式的字符串,其中键和值通过某个分隔符分隔,默认为制表符( \t )。如果没有分隔符,mapper 就认为输出只有键,值为 null 。可以通过向 Hadoop Streaming 作业传递参数来定制分隔符。
- 对 mapper 的输出进行 shuffle 和 sort (确保每个相同的键都发送给同一个 reducer);
- reducer 启动可执行文件。mapper 输出的键值字符串通过 stdin 传输到 reducer 作为输入,reducer 的输入和 mapper 的输出相互匹配,并保证按键分组。reducer 发送到 stdout 的输出的格式应该与 mapper 的键、分隔符和值的格式相同。
因此,为了使用 Python 编写 Hadoop 作业,需要创建两个 Python 文件:mapper.py 和 reducer.py。只需要在这两个文件中导入 sys 模块,就可以访问 stdin 和 stdout 。代码本身需要以字符串的形式处理输入、解析和转换每个数字或复杂的数据类型,我们也需要将输出序列化为字符串。
注意:
- reducer 更复杂一些,因为针对每行输入,我们都要记录正在处理哪个键,只有看到一个新键时,才能发射一个完整的和。这是因为与本地 API 不同,单个数据值会在 shuffle 和 sort 期间聚合到流进程中,而不是暴露为一个列表或迭代器。请记住,每个 reducer 任务都可以看到同一个键的所有值,但也可以看到多个键。
- reducer 不接收累积值,而是接收从 mapper 输出的、经过排序的逐行输入。
- 每个 Python 文件都应以 “#!/usr/bin/env python” 开头,从而提示 shell 应该使用 Python,而不是 bash 来解释代码。
3. Hadoop Streaming 执行
①使用 Linux 管道模拟 Hadoop MapReduce 流水线
因为 Streaming 使用 Unix 标准管道,所以可以使用 Linux 管道和 sort 命令模拟 Hadoop MapReduce 流水线。具体执行步骤如下:
- 在终端中使用 chmod 命令以确保 mapper.py 和 reducer.py 是可执行的。
- 使用 cat 命令输出文件的内容,通过管道将输出从 stdout 传输到 mapper.py 的 stdin,再传输到 sort ,然后到 reducer.py,最后将结果打印到屏幕上。
Unix 管道是一种测试 Hadoop Streaming 的 mapper 和 reducer 的方法,既简单又有效,还能有效说明集群是如何使用 mapper 和 reducer 代码的。这种方法非常适合在编写脚本时进行快速测试,因为不用等待 Hadoop Streaming 作业完成,也不需要解析 Java 调用过程(traceback)。
②在 Hadoop 集群上执行 Streaming 作业
为了将代码部署到集群,需要将 Hadoop Streaming JAR 提交给作业客户端,并传入自定义的操作符参数。Hadoop Streaming 作业的位置取决于 Hadoop 集群的设置。这样就可以按照如下所示的方法在集群上执行 Streaming 作业:
$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar(Hadoop Streaming 作业的位置) \
-input <输入文件> \
-output <输出文件名称> \
-mapper mapper.py \
-reducer reducer.py \
-file mapper.py \
-file reducer.py
注意:
- 这里使用了 -file 选项,它让 Streaming 作业往集群上发送脚本(否则程序无法在节点上找到这些脚本)。执行此命令将在 Hadoop 集群上启动该作业。mapper.py 脚本和 reducer.py 脚本将在处理之前被发送到集群中的每个节点,并应用于流水线的每个阶段。
- 如果有需要与作业一起发送的其他文件,可以使用 -file 选项将它们与作业打包在一起。代码中使用的任何第三方依赖也应与作业一起被提交,通常打包在 Python ZIP 文件中。对于较大的依赖文件或者需要使用 Cython 编译的依赖,则需要在作业启动之前在每个节点的系统路径中安装相应依赖。
4. Python 的 MapReduce 框架
Hadoop Streaming 稍微高级一点的用法是利用标准错误流( stderr )更新 Hadoop 状态以及 Hadoop 计数器。这种技术本质上是让 Streaming 作业访问 Reporter 对象——MapReduce Java API 的一部分,用于跟踪作业的全局状态。通过将特殊格式的字符串写入 stderr ,mapper 和 reducer 可以更新全局作业状态,以报告进度并表明它们是活动的。对于需要大量时间的作业,确保框架不会认为任务已超时至关重要。
计数器在整个 MapReduce 框架或应用程序范围内进行全局聚合,以键值对的形式保存数值。计数器可以通过满足结合律的运算来累加,这本质上就增加了计数器的值。Hadoop 实现了多个计数器,能对处理的记录和字节数进行计数,自定义计数器也能更轻松地跟踪作业中的指标数据或提供副计算的相关渠道。
举例来说,要实现要使用 Reporter 的 Counter 和 Status 功能的话,可以在 Mapper 和 Reducer 类添加如下方法:
def status(self, message):
sys.stderr.write("reporter:status:{}\n".format(message))
def counter(self, counter, amount=1, group="ApplicationCounter"):
sys.stderr.write(
"reporter:counter:{},{},{}\n".format(group, counter, amount)
)
counter 方法允许 map 和 reduce 函数更新任意命名计数器的计数。根据需要,更新的值可为任意值(默认为递增 1)。可以将计数器的组设置为任意名称,通常默认为应用程序的名称。与之类似, status 方法允许 MapReduce 应用程序向框架发送任意消息,并使它们在日志或 Web 用户界面中可见。
全局范围中有一个能改进由 Python 编写的 Streaming 应用程序的工具:作业配置变量(job configuration variable,简称“JobConf 变量”)。Hadoop Streaming 应用程序自动将作业的配置变量添加到环境中,用下划线( _ )替换圆点( . )来重命名配置变量。例如,如果要访问作业中 mapper 的数量,可以请求 “mapred.map.tasks” 配置变量。要在 Python 代码中访问作业配置变量,可添加以下函数:
import os
def get_job_conf(name):
name = name.replace(".", "_").upper()
return os.environ.get(name)
很明显,使用一个微型、可重用的框架对 Hadoop Streaming 的 Python 开发大有帮助。该框架应该有一个用于处理 mapper 和 reducer 的 Streaming 细节的基类,以及应该在自定义MapReduce Streaming 作业中扩展的抽象基类 Mapper 和 Reducer 。想想下面的框架:
import os
import sys
from itertools import groupby
from operator import itemgetter
SEPARATOR = "\t"
class Streaming(object):
@staticmethod #返回函数的静态方法,允许不实例化调用该方法
def get_job_conf(name):
name = name.replace(".", "_").upper()
return os.environ.get(name)
def __init__(self, infile=sys.stdin, separator=SEPARATOR):
self.infile = infile
self.sep = separator
def status(self, message):
sys.stderr.write("reporter:status:{}\n".format(message))
def counter(self, counter, amount=1, group="Python Streaming"):
msg = "reporter:counter:{},{},{}\n".format(group, counter, amount)
sys.stderr.write(msg)
def emit(self, key, value):
sys.stdout.write("{}{}{}\n".format(key, self.sep, value))
def read(self):
for line in self.infile:
yield line.rstrip() # rstrip() 删除 string 字符串末尾的指定字符(默认为空格)
def __iter__(self):
for line in self.read():
yield line
class Mapper(Streaming):
def map(self):
raise NotImplementedError("Mappers must implement a map method")
class Reducer(Streaming):
def reduce(self):
raise NotImplementedError("Reducers must implement a reduce method")
def __iter__(self):
generator = (line.split(self.sep, 1) for line in self.read())
for item in groupby(generator, itemgetter(0)):
yield item
在编写传递给 Hadoop Streaming 的 mapper 和 reducer 时,只需在 Streaming 作业中引入这个文件,并从该框架中导入合适的类。在扩展类后,只需在代码中实现 map 函数或reduce 函数即可。
5. MapReduce 高级工具
这一节从概念层面去介绍一些在 MapReduce 算法和优化中发挥重要作用的工具
(实际上,这些工具很难在没有 Java API 的情况下实现),我们将讨论 combiner(主要的 MapReduce 优化技术)、partitioner(确保在 reduce 步骤中不出现瓶颈的技术)和作业链(用于组合更大的算法和数据流的技术)。
① combiner
mapper 会产生大量的中间数据,这些中间数据必须通过网络传输,进行 shuffle、sort 和 reduce。由于网络是物理资源,大量数据的传输可能会导致作业延迟和内存瓶颈(比如 reducer 要保存到内存中的数据太多)。
combiner 是解决这个问题的主要机制,而且它本质上也是与 mapper 输出相关联的中间 reducer。在将数据转发到合适的 reducer 之前,combiner 通过执行一个 mapper 局部的 reduce 来减少网络流量。
每个 mapper 都为 reducer 带来额外的工作,即每个 mapper 都会产生重复的键。combiner 预先计算每个键的和,减少生成的键值对的数量,从而减少网络流量。此外,因为存在较少的重复键,所以 shuffle 操作和 sort 操作也变得更快。
只要运算满足交换律和结合律,combiner 和 reducer 就是相同的——这很常见,但也不总是这样。只要 combiner 的输入输出数据类型和 mapper 的输出数据类型一样,则 combiner 可以执行任意的局部聚合(partial reduction)。因此,combiner 的运算与 reducer 不同时,算法常常同时使用 mapper、reducer 和 combiner 实现。要在 Hadoop Streaming 中指定 combiner,可以使用 -combiner 选项,与指定 mapper 和 reducer 类似:
$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar(Hadoop Streaming 作业的位置) \
-input <输入文件> \
-output <输出文件名称> \
-mapper mapper.py \
-combiner combiner.py \
-reducer reducer.py \
-file mapper.py \
-file reducer.py \
-file combiner.py
如果 combiner 与 reducer 匹配,则只需将 reducer.py 文件指定为 combiner 即可,无须添加额外的 combiner 文件。
② partitioner
partitioner 通过划分键空间来控制如何将键及其值发送到每个 reducer,默认使用的 HashPartitioner 通常就能满足需求。它通过计算键的散列值并将键分配给由 reducer 数量确定的键空间,来将键均匀地分配给每个 reducer。给定均匀分布的键空间后,每个 reducer 将获得相对平均的工作负载。
一旦键的分布不平均,比如大量的值与一个键相关联,其他键几乎没有关联的值,在这种情况下,大部分 reducer 的工作量不饱满,并行 reduce 的大多数好处也就无从体现。
一个自定义的 partitioner 可以根据散列之外的其他语义结构(通常是特定于领域的)划分键空间,从而缓解这个问题。最后,因为每个 reducer 都将输出写入自己的 part- 文件*,使用自定义 partitioner 还能支持更清晰的数据组织,让你根据分区条件将分段输出写入每个文件。
③ 作业链
大多数复杂的算法不能使用简单的 map 和 reduce 描述。因此,为了实现更复杂的分析,需要一种被称为作业链的技术。如果可以将复杂的算法分解成几个较小的 MapReduce 任务,那么将这些任务链接在一起就可以产生完整的输出。
作业链是许多小作业的组合,通过将一个或多个作业的输出发送给另一个作业作为
输入,从而实现完整的计算。为了实现这样的算法,开发人员必须考虑每一步计算怎样 reduce 出中间值——不仅仅是 mapper 和 reducer 之间的中间值,还包括作业之间的中间值。

如上图所示,许多作业都被认为是线性作业链。线性依赖性意味着每个 MapReduce 作业仅依赖于前一个作业。然而,这是一种简化的作业链形式,更普遍的作业链表示为作业依赖于一个或多个先前作业的数据流。可以用有向无环图(directed acyclic graph,DAG)来表述复杂作业,它描述数据如何从输入源通过每个作业(有向部分)流向下一个作业,最后作为最终输出(如下图所示)。
在考虑作业链和作业依赖时,注意可能会有仅有 map 的作业。仅有 map 的作业分两种:不需要聚合的作业,以及积极避免 shuffle 阶段和 sort 阶段的作业——要么为了保持数据的顺序,要么为了优化作业的执行。要执行仅有 map 的作业,只需将 reducer 的数目设置为 0 即可。有了 HadoopStreaming,就可以使用 -numReduceTasks 标志指定 reducer 的数目。通过使用 identity mapper,也可以实现仅有 reduce 的作业,“仅有 map”的作业可以使用 identity reducer 实现排序。
七、Spark 内存计算
1. 为什么需要 Spark?
MapReduce 的批处理模型不太适合常见的工作流,包括针对单个数据集的迭代、交互和按需计算。为了实现协调性和容错性,MapReduce 模型需要将中间数据写回 HDFS。不幸的是,将数据从其存储位置移动到计算位置所需要的 I/O 在任何计算系统中都是最大的时间成本。因此,MapReduce 在具有极高的安全性和弹性的同时,运行任务的速度也不可避免会慢一些。

关于**弹性(Flexible)**的解释:
- 传统的关系数据库存储数据时必须有数据表结构 schema(各个数据对象的集合),然而 Hadoop 存储的数据是非结构化(schema-less)的,也就是说可以存储各种形式、不同数据源的数据。
更糟的是,几乎所有应用程序都必须在多个步骤中将多个 MapReduce 作业链接在一起,从而创建面向最终所需结果的数据流。这导致不为用户所需的大量中间数据被写入 HDFS,从而产生额外的磁盘开销。
为了解决这些问题,Hadoop 采用了更通用的资源管理框架进行计算,这便是 YARN。 YARN 为 Hadoop 应用程序提供了更通用的资源访问。因此,专用工具不再需要分解为一系列 MapReduce 作业,可以变得更复杂。
Spark 是应运而生的第一个快速、通用的分布式计算范式,Spark 主要通过名为弹性分布式数据集(resilient distributed dataset,RDD)的新数据模型实现高速运行。该数据模型在计算时存储在内存中,从而避免了昂贵的中间磁盘写操作。它还利用了 DAG (有向无环图)执行引擎优化计算,特别是迭代计算,这对于优化算法和机器学习等数据理论任务来说至关重要。在速度方面的优势使得 Spark 能以交互方式进行访问,使用户成为计算任务的一部分,并支持以前不可能实现的大数据集探索,让数据科学家能更轻松地使用集群。

2. Spark 基础
Spark 主要通过在集群节点的内存中缓存计算所需的数据来实现高速运行。在内存中进行集群计算使 Spark 可以运行迭代算法,因为程序可以为数据创建检查点并引用回它,避免从磁盘重新加载。此外,它支持极快速的交互式查询和流式数据分析。因为 Spark 与 YARN 兼容,所以它可以在现有的 Hadoop 集群上运行并访问任何 Hadoop 数据源,包括 HDFS、S3、HBase 和 Cassandra。
还有一点很重要,Spark 的设计从根本上支持大数据应用程序和数据科学任务。Spark API 不仅支持 map 和 reduce ,还提供了许多强大的分布式抽象。这些抽象同样与函数式编程相关,包括 sample、filter、join 和 collect 等。
先来看看 MapReduce 在迭代算法方面的局限性。例如,为了使用 MapReduce 编程实现有监督学习算法,目标函数的参数必须映射到数据集中的每个实例,并计算和规约误差。在 reduce 阶段结束之后,参数将被更新并馈送到下一个 MapReduce 作业。然而,每个作业都必须从磁盘读取数据,并将误差写回磁盘,这将导致明显的 I/O 延迟。
相反,Spark 在应用程序运行期间将尽可能多的数据集保存在内存中,从而防止在迭代之间重新加载数据。因此,Spark 程序员不是简单地指定 map 步骤和 reduce 步骤,而是在执行某个需要协调的动作(如规约或写入磁盘)之前,指定一系列将应用于输入数据的数据流转换。因为数据流可以通过 DAG 来描述,所以 Spark 的执行引擎提前知道了如何在集群上分发计算并管理计算的细节。
Spark 的通用性意味着可以用它构建更高级的工具,用于实现类 SQL 的计算、图形处理和机器学习算法,乃至交互式 notebook 和数据框——这些都是为数据科学家所熟知的工具,但是是在集群环境中实现的。来了解一下它有哪些工具:
Spark 栈
Spark 是一种通用的分布式计算抽象,可以在独立模式下运行。但是 Spark 只专注于计算而不关心数据存储,因此通常在实现了数据仓储和集群管理工具的集群中运行。当使用 Hadoop 构建 Spark 时,它使用 YARN 通过 ResourceManager 来分配和管理集群资源,如处理器和内存。正因如此,Spark 可以访问所有 Hadoop 数据源,例如 HDFS、HBase、Hive,等等。
Spark 通过 Spark Core 模块将其主要的编程抽象暴露给开发人员。此模块包含基本功能和常规功能,包括定义 RDD 的 API。Spark 构建于这个核心之上,为各种数据科学任务实现与 Hadoop 交互的专用库,如下图所示。

注意:
- 组件库未集成到通用计算框架中,所以 Spark Core 模块非常灵活,允许开发人员以不同的方法轻松解决类似的用例
- Spark 是一个计算框架,旨在利用集群管理平台(如 YARN)和分布式数据存储(如 HDFS)
Spark 主要包含如下组件:
- Spark SQL
这个库提供了更常规、更结构化的数据处理抽象——DataFrame。DataFrame 本质上是组织成列数据的分布式集合,概念上类似于关系数据库中的表。 - Spark Streaming
对无界数据流实现实时处理和操作。Spark Streaming 使程序能够像处理一般的 RDD 一样处理实时数据。 - MLlib
一个常用的机器学习算法库,使用 RDD 上的 Spark 操作实现。该库包含可扩展的学习算法(例如分类、回归等),这些算法需要进行大型数据集的迭代运算。 - GraphX
算法和工具集合,用于操作图形、执行并行图形的操作和计算。GraphX 扩展了 RDD API,囊括了操作图形、创建子图和访问路径中所有顶点的操作。
RDD
我们将 Hadoop 描述为一个分布式计算框架,涉及两个主要问题:如何在集群中分发数据,以及如何分发计算。分布式数据存储问题涉及数据的高可用性(将数据放在它被处理的地方)、可恢复性和持久性。分布式计算意在通过将大型计算或任务分解成更小的独立计算来提高计算的性能(速度),这些计算可以同时(并行)运行,然后聚合得到最终结果。因为每个并行计算在集群中单独的节点或计算机上运行,所以分布式计算框架需要为整个计算提供一致性、正确性和容错保证。
Spark 不处理分布式数据存储,而是依靠 Hadoop 提供此功能,因此通过一个被称为弹性分布式数据集的框架专注于提供可靠的分布式计算。RDD 本质上是一种编程抽象,表示跨机器分区的对象的只读集合。RDD 可以根据转换过程(lineage)重建(因此是容错的),通过并行操作访问,从分布式存储读取和写入,以及高速缓存在 worker 节点的内存中以快速重用——这一点最为重要。
这种内存缓存功能使速度大幅提高,并提供了机器学习所需的迭代计算以及以用户为中心的交互式分析。RDD 使用函数式编程结构体进行操作,函数式编程结构体包括 map 和 reduce ,并在其基础上进行扩展。程序员通过从输入源加载数据,或转换现有集合来创建新的 RDD。RDD转换过程(lineage)主要由应用于 RDD 转换的历史定义,并且因为 RDD 的对象集合是不可变的(不能直接修改),所以转换可以重新应用于部分或整个集合,以便从故障中恢复。因此,Spark API 本质上是创建、转换和导出 RDD 操作的集合。
Spark 中的故障恢复与 MapReduce 的区别很大。在 MapReduce 中,数据在每个临时处理步骤之间是作为文件写入磁盘的。因此,进程在 map、shuffle 和 sort、reduce 之间拉取数据。如果一个进程失败,那么另一个进程就开始拉取数据。在 Spark 中,对象集合存储在内存中。通过保留 RDD 部分的早期检查点或缓存版本,
RDD 转换过程(lineage)可用于重建部分或全部集合。
因此,基本编程模型描述了如何通过编程操作创建和修改 RDD。有两种类型的操作可以应用于 RDD,分别是转换和动作。将转换操作应用于现有 RDD 可以创建新的 RDD,例如对 RDD 应用过滤操作可以生成包含过滤出来的值的较小 RDD。然而,动作才会真正将结果返回给 Spark 驱动程序,协调或聚合 RDD 中的所有分区。在这个模型中, map 是一种转换操作,因为一个函数被传递给存储在 RDD 中的每个对象,并且该函数的输出映射到一个新的 RDD;而像 reduce 这样的聚合是一个动作操作,因为 reduce 需要(根据键)对 RDD 进行重新分区,并计算和返回某个聚合值,如和或平均值。Spark 中大多数动作的设计初衷都只是为了输出——返回单个值或小的值列表,或者将数据写回分布式存储。
Spark 的另一个好处是,它会“延迟”应用转换操作,即向集群提交作业以执行作业之前,检查完整的转换序列和一个动作。这种延迟执行机制带来了明显的存储和计算优化,因为它允许 Spark 建立数据转换过程(lineage)并评估完整的转换链,以便只计算结果所需的数据。例如,如果对 RDD 运行 first() 动作,Spark 将不会读取整个数据集,并只返回第一个匹配行。
使用RDD编程
Spark 应用程序的代码被写在驱动程序(driver program)中,提交时在驱动程序所在机器上被延迟评估。一旦遇到动作,驱动程序代码就被分发到集群上,由 worker 节点在各自的 RDD 分区上执行该代码。然后结果被发送回驱动程序以进行聚合或汇编。
如下图所示,驱动程序通过将来自 Hadoop 数据源的数据集并行化,创建一个或多个 RDD,应用操作来转换 RDD,然后对经过转换的 RDD 调用某个动作以检索输出。“并行化”是一种行为,它将数据集分区,并将数据的每个部分发送到将对其执行计算的节点。

Spark 编程的典型数据流序列如下所示:
- 通过访问存储在磁盘上的数据、并行化某个集合、转换现有 RDD 或缓存来定义一个或多个 RDD。缓存是 Spark 的一个基本过程,即在节点内存中存储 RDD,用于在计算过程中快速访问。
- 通过将闭包(这里指不依赖于外部变量或数据的函数)传递到 RDD 的每个元素,来对 RDD 执行操作。
- 对生成的 RDD 使用聚合动作(例如计数、收集、保存等)。动作将启动集群上的计算,因为在计算聚合之前无法进行任何计算。
当 Spark 在 worker 节点上运行闭包时,闭包中使用的所有变量都将被复制到该节点,但在该闭包的局部范围内维护。如果需要外部数据,Spark 提供了两种类型的共享变量——广播变量和累加器,所有的 worker 节点都可以通过受限方式与它们交互。广播变量被分发给所有 worker 节点,但是只读的,并且通常作为查找表或禁用词列表使用。累加器是一个变量,worker 节点可以“累加”(满足结合律)它,通常用作计数器。这些数据结构类似于 MapReduce 中的分布式缓存和计数器,并且发挥着类似的作用。
3. Spark 执行机制
对 Spark 的执行机制进行简要说明。Spark 应用程序本质上是独立运行的进程的集合,由驱动程序中的 SparkContext 进行协调。该上下文将与某个分配系统资源的集群管理器(例如 YARN)连接。集群中的每个 worker 节点都由一个 executor 管理,executor 又由 SparkContext 管理。executor 管理每台机器上的计算、存储和缓存。驱动程序、YARN 和 worker 节点的交互如下图所示。

但要注意,应用程序代码从驱动程序发送到 executor,executor 指定上下文和要运行的各种任务。executor 与驱动程序来回通信以进行数据的共享或交互。驱动程序是 Spark 作业的关键参与者,因此它们应该和集群待在同一个网络上。这不同于 Hadoop 代码——你可以从任何地方将作业提交到 ResourceManager ,并由 ResourceManager 负责作业在集群上的执行。
可以通过两种模式将 Spark 应用程序提交到 Hadoop 集群,分别是 yarn-client 和 yarn-cluster 。在 yarn-client 模式下,驱动程序在客户端进程内运行。如上所述, ApplicationMaster 仅管理作业的进度并请求资源。然而在 yarn-cluster 模式下,驱动程序在 ApplicationMaster 进程内部运行,因此释放了客户端进程,像传统的 MapReduce 作业一样运行。如果程序员想获取即时结果或想以交互模式运行,可以使用 yarn-client 模式;而对于时间运行长或不需要用户干预的作业,使用 yarn-cluster 模式更为合适。
4. 基于 PySpark 的交互性 Spark
Spark 中的交互式 shell 叫 pyspark 。这种交互方式类似于在 Python 解释器中与本地 Python 代码交互、在命令行中编写命令并接收 stdout 的输出。这种类型的交互还支持交互式 notebook,在 Spark 环境中设置 iPython 或 Jupyter notebook 也非常容易。
在 pyspark 中使用 RDD 是启用 Spark 最简单的方法。为了运行交互式 shell,需要定位 pyspark 命令,该命令位于 Spark 库的 bin 目录。和 $HADOOP_HOME 类似,你也应该配置一个 $SPARK_HOME 。Spark 无须配置即可运行,因此只需下载适用于系统的 Spark 就足够了。将 $SPARK_HOME 替换为下载路径(或设置你的环境)就可以运行交互式 shell,如下所示:
hostname $ $SPARK_HOME/bin/pyspark
PySpark 使用本地 Spark 配置自动创建了一个 SparkContext 。它通过 sc 变量将自己暴露给终端。为了检查到目前为止的转换过程(lineage),可以使用toDebugString 方法来查看 PipelinedRDD 是如何转换的。
请注意,在 MapReduce 作业中,由于 map 和 reduce 之间有 shuffle 阶段和 sort 阶段,所以键会被排序。但因为所有 executor 都可以相互通信,所以 Spark 进行 reduce 时不会对重新分区排序。因此,前面的输出不会按照字母顺序排列。不过,由于用 reduceByKey 算子聚合了相应 RDD,所以即使没有排序,仍然能保证每个键在所有 part 文件中仅出现一次。如果需要排序,可以使用 sort 算子确保所有键在写入磁盘之前都已被排序。
5. Spark 应用程序模版
使用 Python 编写 Spark 应用程序与在交互式控制台中使用 Spark 很像,因为 API 是相同的。但是你不需要在交互式 shell 中输入命令,而是需要创建一个完整的、可执行的驱动程序并将其提交到集群。这涉及一些在 pyspark 中自动处理的内务任务,包括获取 SparkContext 的访问,这是由 shell 自动加载的。
因此,许多 Spark 程序都是简单的 Python 脚本。它包含一些数据(共享变量),定义用于转换 RDD 的闭包,并描述 RDD 转换和聚合的分步执行计划。使用 Python 编写 Spark 应用程序的基本模板如下所示:
''' Spark应用程序,使用spark-submit执行'''
# 导入
from pyspark import SparkConf, SparkContext
# 共享变量和数据
APP_NAME = "My Spark Application"
# 闭包函数
# 主要功能
def main(sc):
"""
这里描述RDD转换和动作
"""
pass
if __name__ == "__main__":
# 配置Spark
conf = SparkConf().setAppName(APP_NAME)
conf = conf.setMaster("local[*]")
sc = SparkContext(conf=conf)
# 执行主要功能
main(sc)
此模板展示了 Python 语言的 Spark 应用程序自上而下的结构:
- import 让各种 Python 库以及 Spark 组件(例如 GraphX 和 SparkSQL)可用于分析
- 为了调试和日志记录,共享数据和变量被指定为模块常量,包括在 Web UI 中使用的应用程序名称
- 为了便于调试,可以让驱动程序包含特定于作业的闭包或自定义算子,这些闭包或自定义算子也可以导入到其他 Spark 作业中
- 最后, main 方法定义转换和聚合 RDD 的分析方法,该 main 方法作为驱动程序运行
这里使用了 ifmain 语句,其中 Spark 配置和 SparkContext 被定义并传递给 main 函数。通过 ifmain 可以轻松地将驱动程序代码导入到其他 Spark 上下文,无须创建新的上下文或配置、执行作业。具体来说,Spark 程序员通常会将代码从应用程序导入到 iPython、Jupyter notebook 或 pyspark 交互式 shell 中,以便在对较大的数据集运行作业之前进行分析。
驱动程序定义了 Spark 执行过程的方方面面,例如程序员可以在代码中使用 sc.stop() 或 sys.exit(0) 停止或退出程序。这样的控制也可以扩展到执行环境——在这个模板中,Spark 集群的配置 local[*] 通过 setMaster 方法硬编码到 SparkConf 中,这告诉 Spark 在本地机器上运行尽可能多的进程(多进程,但不是分布式计算)。虽然你可以在命令行使用 spark-submit 来指定 Spark 执行的位置,但是驱动程序通常基于使用 os.environ 的环境变量来进行选择。因此,在开发 Spark 作业时,作业可以在本地运行;但是在生产环境中,作业在集群的较大数据集上运行。编写 Spark 应用程序肯定与编写 MapReduce 应用程序不同,因为转换和动作提供了灵活性,以及更灵活的编程环境。
注意:
- 与 Hadoop Streaming 一样,任何不属于 Python 标准库的第三方 Python 依赖都必须预先安装在集群中的每个节点上,或随作业一起提供。
- 与 Hadoop Streaming 不同的是,Spark 有两个上下文(即驱动程序上下文和 executor 上下文),这允许一些重量级库(特别是可视化库)可以只安装在驱动程序机器上——只要它们不被在集群上运行的 Spark 运算使用的闭包使用就可以。如果想要预防错误,可以使用 try/except 块包裹 import 语句来捕获 ImportError 。
6. 总结
Spark 不解决分布式存储问题(通常 Spark 从 HDFS 获取其数据,当与 YARN 结合时,Spark 用于增强(不是替换)现有的 Hadoop 集群),但它为分布式计算提供了丰富的函数式编程 API。这种框架建立在弹性分布式数据集(RDD)的理念上。RDD 是一种编程抽象,表示分区的对象集合,允许对它们执行分布式操作。RDD 是容错的(弹性部分),还可以存储在 worker 节点的内存中,以便快速重用。内存存储提供更快、更容易表达的迭代算法,还支持实时交互式分析。
八、分布式分析和模式
1. 前言
MapReduce 和 Spark 让开发人员和数据科学家能轻松进行数据并行运算。在这类运算中,数据被分发到多个处理节点同时计算,然后通过 reduce 产生最终输出。而 YARN 提供了简单的任务并行性,通过为每个任务分配自由计算资源,支持集群同时执行多个不同的操作。然而,大多数并行运算都比较简单。这也带来了一个问题:数据科学家如何进行大规模高级数据分析?
单个运算只对数据进行多个微小的处理,而要想得到更有意义的结果,必须将这些运算组成一个被称为数据流的分步序列。如果两个运算可以同时进行,则数据流可以分叉(fork)和合并(merge),支持任务和数据并行,但是必须保证序列的数据从输入数据源串行馈送到最终输出。因此,数据流被描述为有向无环图(DAG)。如果一种算法、分析或精心设计的计算可以表示为 DAG,则它可以在 Hadoop 上并行化。
但是,许多算法都不能轻易转换为 DAG,即不适合这种类型的并行化。不能被描述为有向数据流的算法有:在整个计算过程中维持或更新单个数据结构的算法(需要一些共享内存),或者依赖中间步骤计算结果的算法 (需要中间进程间通信)。引入循环的算法,特别是循环次数不限的迭代算法,也不容易描述为 DAG。
有一些工具和技术可以满足 MapReduce 和 Spark 中循环性、共享内存或进程间通信的需求。但是要利用这些工具,必须将算法重写为分布式形式。比起重写算法,更常采用的是一种技术要求更低但同样有效的方法:设计一种数据流,将输入域分解为适合单个机器内存的较小输出,对输出运行串行算法, 然后使用另一个数据流在集群上验证该分析。
正是因为这种方法被广泛采用,Hadoop 才被普遍认为是一个释放大数据集潜力的预处理器——它通过每个操作将数据集规约(reduce)成越来越容易管理的块。一种常见做法是,使用 MapReduce 或 Spark 将数据分解到一个可以载入 128GB 内存的计算空间中。这个规则通常被称为“最后一英里”(last-mile)计算,因为它将数据从极大的空间移动到足够近的地方(即最后一英里),从而能够进行准确的分析或特定于应用程序的计算。
2. 键计算
要理解数据流实际是如何工作的,第一步就是理解键值对和并行计算之间的关系。在 MapReduce 中,所有数据在 map 阶段和 reduce 阶段都被构造为键值对。关键需求主要与 reduce 有关,因为聚合是按键分组的,并行 reduce 需要对键空间进行分区,使每一个 reducer 任务都能收到一个键的所有值。如果没有用于分组的键,你就可以按单一的键进行 reduce,强制对所有映射值进行 reduce。然而在这种情况下,reduce 阶段无法从并行中受益。
键虽然经常被忽略(特别是在 mapper 中,键仅仅是文档标识符),但是它能让计算在数据集上同时进行。因此,数据流表达了一组值与另一组值之间的关系。MapReduce 和 Spark 计算采用了并行执行分组操作,如下图所示的按键分组的平均值计算。

此外,键可以保存在数据流的一个阶段中已经被 reduce 的信息,还能自动并行下一步计算所需的结果。这是通过复合键完成的,复合键的存在表明了键不一定是简单的、原始的值。事实上,键对于这些类型的计算非常有用,尽管它们在使用 Spark 的计算中不是必需品(RDD 可以是简单值的集合),但大多数 Spark 应用程序需要它们来进行分析,主要是使用 groupByKey 、 aggregateByKey 、sortByKey 和 reduceByKey 动作来收集和 reduce。
复合键
键不一定是简单的原始数据类型,如整型或字符串;相反,它们可以是复合类型或复杂类型,只要是可散列(hashable)且可比较(comparable)的即可。可比较的类型必须至少能暴露某种用于判断相等的机制(用于 shuffle)和某种排序方法(用于 sort)。一般通过将某种类型映射到一个数值(例如,将月份映射到整数 1~12),或通过词汇顺序来完成比较。Python 中的可散列类型是任意一种不可变类型,最典型的就是由不可变类型组成的元组。
用作复杂键的复合键支持在键空间的多个面上进行计算,这是复合键最常见的用例。另一个常见用例是将特定键的信息传播到下游计算,例如依赖于 reduce 或每个键的聚合值的计算。通过将 reducer 的计算与键(特别是类似计数或浮点数的值)相关联,这些信息能与键一起被维护,以用于更复杂的计算。
使用复合键(和复杂的值)的最后一步是理解复合数据的序列化和反序列化。序列化是指将内存中的对象转换成字节流,使其可以被写入磁盘或通过网络传输(反序列化是指相反的过程)。序列化过程必不可少,特别是在 MapReduce 中,因为键和值在 map 阶段和 reduce 阶段之间被写入磁盘(通常作为字符串写入)。然而,理解 Spark 中的序列化也非常重要——Spark 的中间作业要对数据进行预处理,供后续计算使用。
在 Spark 中,Python API 默认使用 pickle 模块进行序列化,这意味着你使用的任何数据结构都必须是可以 pickle 的。使用 MapReduce Streaming 时,必须将键和值序列化为字符串,并以指定的字符分隔,默认情况下为制表符( \t )。那么有没有更高效的办法,能将复合键(和值)序列化为字符串呢?
通常会简单地使用内置的 str 函数对不可变类型(例如元组)进行序列化,将该元组转换为可以轻松 pickle 或流式传输的字符串。然后问题转向反序列化——通过 Python 标准库中的 ast (抽象语法树)模块,使用 literal_eval 函数评估元组字符串得到 Python 元组类型,如下所示:
import ast
def map(key, val):
# 解析复合键,它是一个元组
key = ast.literal_eval(key)
# 以字符串写新的键
return (str(key), val)
随着键和值越来越复杂,你也得考虑使用其他序列化数据结构,尤其是那种更紧凑的、能减少网络流量或能转换为字符串值以确保安全性的数据结构。例如,结构化数据的常见表示形式是 Base64 编码的 JSON 字符串,因为它很紧凑,仅使用 ASCII 字符,并且很容易用标准库进行序列化和反序列化,如下所示:
import json
import base64
def serialize(data):
"""
返回数据(键或值)的Base64编码的JSON表示
"""
return base64.b64encode(json.dumps(data))
def deserialize(data):
"""
解码Base64编码的JSON数据
"""
return json.loads(base64.b64decode(data))
使用复杂的序列化表示时要小心,通常需要权衡序列化的计算复杂度与它所需的空间。许多类型的并行算法更适合使用元组字符串或制表符分隔格式,实现起来更快、更简单,如果能管理好键在计算中的传递过程更能事半功倍。
键空间模式
键也是计算的主要部分。因此,除了数据之外,键也必须被管理。本节将探讨影响键空间的几种模式,特别是爆炸(explode)、过滤、变换和恒等(identity)模式。这些常见模式通过键和值之间的关联关系来构造更大的模式并完成算法。
① 键空间变换
最常见的基于键的运算是输入键的域的变换,在 map 和 reduce 中均可进行。在 map 期间变换键空间会导致数据在聚合期间重新分区(划分),而在 reduce 期间变换键空间可用于重组输出(或后续计算的输入)。最常见的变换函数是直接赋值、复合、分割和键值换位。
直接赋值丢弃了输入的键(通常被完全忽略),从输入值或别的来源(例如随机的键)构造新键。思考一下从文本、CSV 或 JSON 加载原始或半结构化数据的情况。在这种情况下,输入键是行或文档 ID,通常因为某些特定于数据的值而被丢弃。
复合及其相反运算分割管理复合键。复合构建复合键,或向复合键添加新的元素,能增加键关系的面;分割拆分复合键,而只使用其中一小部分。通常,值也能被复合和分割,复合键从拆分值接收新的数据(反之亦然),以确保没有数据丢失。此外,也可以通过复合或分割,丢弃不需要的数据或删除无关的信息。
键值换位交换键和值,是一种常见模式,特别是在链式的 MapReduce 作业或依赖于中间聚合(特别是 groupby )的 Spark 操作中。例如,为了通过值而不是键对数据集进行排序,必须先在 map 中将键和值换位,执行 sortByKey 或者利用 MapReduce 中的 shuffle 和 sort,然后在 reduce 或另一个 map 中重新换位。
② 爆炸 mapper
爆炸 mapper 针对单个输入键生成多个中间键值对。一般来说,这是通过结合键移位(keyshift)和将值拆分为多个部分来实现的。正如单词计数示例,它根据空格拆分行,将输入 mapper 中的单个行号 / 行对输出为几个新的键值对,即单词 /1。通过将值按组成部分划分并且重新将键分配给它们,爆炸 mapper 还可以生成许多中间对。
在这种情况下,我们经常会碰到一个名为 flatMap 的操作函数,该函数一般的功能和 map 函数相同,但是比 map 函数多了一个扁平化的过程,而且传入的函数在处理完后返回值必须是 list 或者 sequence(该函数产生一个序列而不是单个项,然后该序列被链接成单个集合(而不是列表的 RDD))。在 MapReduce 和 Hadoop Streaming 中不存在这样的限制,一个 map 函数可以发射任意数量的对(或者根本不发送)。
③ 过滤器 mapper
过滤通常对限制 reduce 阶段执行的计算量至关重要,特别是在大数据环境中。它还可将同一数据流的计算划分为两条路径,这是专为超大数据集设计的一种大型算法,是面向数据的分支方法。mapper 什么也不发射也完全没问题。因此,用于过滤器 mapper 的逻辑是仅在满足条件时才发射。
④ 恒等模式
MapReduce 中的最后一个常用键空间模式(一般不用于 Spark 中)是恒等(identity)函数。它只是一个传递,能使恒等 mapper 或者恒等 reducer 返回与输入相同的值(就好像在恒等函数 f(x) = x 中一样)。恒等 mapper 通常用于在数据流中执行多个 reduce。当在 MapReduce 中使用恒等 reducer 时,该作业等同于在键空间上进行排序。恒等 mapper 和恒等 reducer 的简单实现如下所示:
class IdentityMapper(Mapper):
def map(self):
for key, value in self:
self.emit(key, value)
class IdentityReducer(Reducer):
def reduce(self):
for key, values in self:
for value in values:
self.emit(key, value)
因为 MapReduce 使用了最优的 shuffle 和 sort,因而恒等 reducer 通常更常见一些。不过恒等 mapper 也非常重要,特别是在链式 MapReduce 作业中,一个 reducer 的输出必须立即被第二个 reducer 再次 reduce。事实上,正是因为 MapReduce 的操作是分阶段的,所以才需要恒等 reducer。在 Spark 中,因为 RDD 被延迟评估,所以不需要恒等闭包。
pair 与 stripe
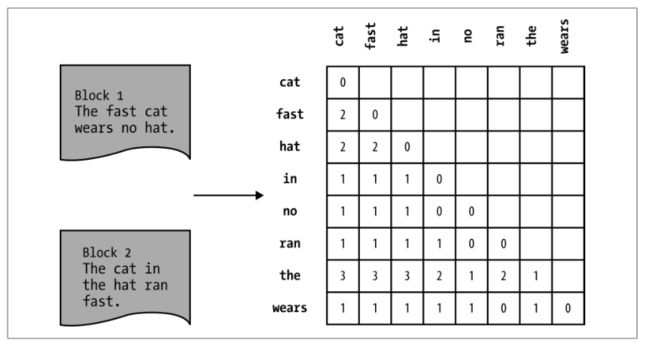
数据科学家习惯用表示为向量、矩阵或数据框的数据。线性代数计算往往针对单核机器进行了优化,而机器学习中的算法使用低级数据结构(如 numpy 库中的多维数组)来实现。这些结构虽然紧凑,但因为数据的量级实在太大,所以无法在大数据环境中使用。相反,矩阵通常有两种表示方式:pair 和 stripe。
pair 和 stripe 都是基于键的计算。为了理解这一点,试着为基于文本的语料库建立单词共现矩阵。如下图所示的单词共现矩阵是大小为 N×N 的矩阵,其中 N 是语料库的词汇量(单词的种数)。每个单元 W i,j 包含词 w i 和词 w j 同时出现在句子、段落、文档或其他固定长度窗口中的次数。这个矩阵很稀疏,特别是采用了积极的停用词过滤之后,因为大多数单词通常仅与非常少的其他词共现。
pair 方法将矩阵中的每个单元映射到特定值,其中词对是复合键 i,j 。因此,reducer 对每个单元的值进行处理,以产生最终的单元挨单元的矩阵。这是一种合理的方法,它产生的输出中的每个 W i,j 被单独计算并存储。使用求和 reducer,mapper 如下所示:
from itertools import combinations
class WordPairsMapper(Mapper):
def map(self):
for docid, document in self:
tokens = list(self.tokenize(document))
for pair in combinations(sorted(tokens), 2):
self.emit(pair, 1)
这个方法的重中之重是使用内置的 sorted 函数对令牌进行字典排序。在对称矩阵中,必须为词对排序,否则键 (b,a) 和 (a,b) 不会 reduce 在一起。请注意,itertools 库中的 combinations 函数保持其输入列表的排序。输入如下所示:
"See Spot run, run Spot, run!"
单词共现矩阵的词对聚合结果如下所示:
(run, run), 3
(run, see), 3
(run, spot), 6
(see, spot), 2
(spot, spot), 1
虽然 pair 方法易于理解和实现,但是它产生了许多中间对。这些中间对必须在网络上传输,这一过程在 MapReduce 的 shuffle 阶段和 sort 阶段,以及 groupByKey 操作将值 shuffle 到 RDD 各分区的期间均有发生。此外,pair 方法不太适用于需要整行(或列)数据的计算。
stripe 方法最初被设想为一种减少中间对的数量和网络通信的优化手段,从而让作业运行得更快。不过它很快也成为一种重要的工具,应用于许多需要针对一个元素执行快速计算(例如相对频率或其他统计运算)的算法中。stripe 方法没有使用词对,而是在 mapper 中为每个条目构造关联数组(Python 字典),并作为值发射:
from collections import Counter
class WordStripeMapper(Mapper):
def map(self):
for docid, document in self:
tokens = list(self.tokenize(document))
for i, term in enumerate(tokens):
# 为每个条目创建新的stripe
stripe = Counter()
for j, token in enumerate(tokens):
# 不计算该条目与本身的共现
if i != j:
stripe[token] += 1
# 发射条目和stripe
self.emit(term, stripe)
class StripeSumReducer(Reducer):
def reduce(self):
for key, values in self:
stripe = Counter()
# 将所有计数器相加
for value in values:
for token, count in value.iteritems():
# 为每一个令牌分别累加stripe
stripe[token] += count
self.emit(key, stripe)
现在的输出更紧凑:
run, ((run, 3), (see, 3), (spot, 6))
see, ((spot, 2), )
spot, ((spot, 1), )
stripe 方法不仅在其表示上更紧凑,而且也生成更少、更简单的中间键,从而优化了数据的 sort、shuffle 等方面。然而,stripe 对象更庞大,在处理时间和序列化方面的开销都更大,特别是当 stripe 非常大时。stripe 的大小有上限,尤其当共现矩阵非常密集时,可能需要大量的内存来记录一个条目的数据。
大多数大数据计算都靠基于键的计算来提供和维护数据集之间的关系,以确保数据能合理分布在不同的 mapper 和 reducer 上。在 Spark 和 MapReduce 上执行大规模计算需要我们换个角度思考标准计算的传统方法,因为数据的规模实在太大。
3. 设计模式
设计模式是指针对特定编程挑战的通用、可重用解决方案。设计模式通常不限定语言,不仅指模式的实现细节,更指设计或构造策略。我们可以探索函数式设计模式,用于解决 MapReduce 和 Spark 中的并行计算问题。这些模式展示了可用于更复杂或特定于领域的角色的通用策略和原则。事实上,我们已经在用于计算单词共现的 pair 和 stripe 模式中看过一个例子。pair 和 stripe 都可以应用于更一般的计算。
MapReduce 作业有 23 种常见的设计模式,大致分为如下几类:
- 概要
根据聚合、分组、统计度量、索引或数据的其他高级视图,提供大型数据集的摘要视图。 - 过滤
基于一组固定的条件创建数据的子集或样本,并且不以任何方式修改原始数据。 - 数据组织
将记录重组为有意义的模式,不一定使用分组。此任务适合作为后续计算的第一步。 - 连接
从不同来源将相关数据收集到一个统一的整体。 - 元模式
为复杂或优化过的计算实现作业链和作业合并。这类模式是与其他模式相关联的模式。 - 输入和输出
使用数据处理模式对输入源的数据进行转换,以输出到一个不同的输出源。输入源和输出源可以位于 HDFS,也可以是其他数据源。
这些技术通常将输入数据分解或转换成用于最后一英里计算的较小数据源。
概要
概要尝试用尽可能简单的方法描述尽可能多的关于数据集的信息。描述性统计数据试图通过测量观测数据的集中趋势(平均值、中值)、分散情况(标准差)、分布
形状(偏度)或变量之间的依赖关系(相关性)来概括观察数据之间的关系。
基于键的计算对数据进行分组(另一种形式的概要),聚合某个通常能描述键的值,然后概要计算就进入了下一步。在很多情况下,概要只是更大的概括和预测的第一步,例如作为语言模型的单词共现的计算,或描述概率分布的频率分析。
从原理上讲,MapReduce 和 Spark 是应用一系列的概要,将具体的数据形式(每个单独的记录)转换为更一般的形式。大体来说,我们最熟悉的概要具备以下操作特征:
- 聚合(集合到单个值,如平均值、总和或最大值)
- 索引(将值映射到值集合的函数映射)
- 分组(将集合选择或划分成多个集合)
通过之前讨论的基于键的技术可以轻松实现分组,我们接下来将探索聚合和索引的模式。具体来说,我们将探索数据集的并行统计描述;然后,将探索两种索引技术:倒排索引和通过词频 - 逆文档频率(term frequency-inverse document frequency,TF-IDF)的文档概要。
①聚合
MapReduce 和 Spark 上下文中的聚合函数拥有两个输入值并生成一个输出值,它也满足交换律和结合律,因此可以并行计算。交换律表明顺序对二元运算没有影响,例如对给定的运算 ✣ 来说, a ✣ b = b ✣ a ;结合律表示无论输入如何分组,计算都是相同的,即( a ✣ b)✣ c = a ✣ ( b ✣ c )。
聚合一般是对一个集合应用操作以创建较小集合(聚集在一起),而 reduce 通常被认为是将集合 reduce 为单个值的操作。聚合也可以被认为是一系列更小的 reduce 组成的应用程序。在这种情况下,为什么结合性和交换性是实现并行不可或缺的条件也就显而易见了:给定一个 reduce a ✣ b ✣ c ✣ d ,由于网络或其他物理约束导致 shuffle 的结果不确定,这意味着顺序不能有影响。结合性允许一个进程计算 a ✣ b ,另一个进程计算 c ✣ d ,其中一个进程发送它们的结果以执行最终的 ✣ 操作。
标准数据集描述量有平均值、中值、众值、最小值、最大值、总和。其中,总和、最小值和最大值都容易实现,因为它们都满足结合律和交换律;但平均值、中值和众值不是。对中值和众值来说,通常需要先进行某种排序,而由于涉及除法,分组计算平均值会产生精度损失,在执行这些类型的分析时应格外小心。我们将使用一个 MapReduce 作业来描述整个数据集,而不是单独讨论这些计算。
②统计概要
现在,可以通过两个关键概念来分析处理数据集。首先,使用键作为关系来定义有意义的数据子集;其次,使用多种方法,包括作业链、键空间管理或 pair、stripe 等机制,同时实现多个计算。通过将实例按键分组并描述属性,可以简化大型数据集并对其执行概要分析。
我们将在一个批次中一次性运行所有的 6 个作业,包括计算总数、总和、平均值、标准差和范围(最小值和最大值),而不是为每个描述性指标单独实现一个 MapReduce 作业(代价高昂)。这时的基本策略是,为所有按键进行的计算映射一个计数器值的集合。然后,reducer 将每个操作分别应用于值集合中的每个项目,使用每个项目来计算最终输出(例如平均值取决于总数和总和)。这样的 mapper 的基本结构如下所示:
class StatsMapper(Mapper):
def map(self):
for key, value in self:
try:
value = float(value)
self.emit(key, (1, value, value ** 2))
except ValueError:
# 无法解析,忽略
pass
在这种情况下,直接进行 reduce 的三种操作是计算总数、总和和平方和。因此,该 mapper 针对每个键发射一次,1 用于计数,值用于求和,值的平方用于平方和。reducer 使用总数及总和来计算平均值,使用值计算范围,使用总数、总和以及平方和计算标准差,如下所示:
from ast import literal_eval as make_tuple
class StatsReducer(Reducer):
def reduce(self):
for key, values in self:
# 解析mapper发送过来的值
values = make_tuple(values)
count = 0
delay = 0.0
square = 0.0
minimum = None
maximum = None
for value in values:
count += value[0]
delay += value[1]
square += value[2]
if minimum is None or value[1] < minimum:
minimum = value[1]
if maximum is None or value[1] > maximum:
maximum = value[1]
mean = delay / float(count)
stddev = math.sqrt((square-(delay**2)/count)/count-1)
self.emit(key, (count, mean, stddev, minimum, maximum))
MapReduce 中的 reducer 可以访问与单个键相关联的所有值的可迭代对象,而在 Spark 中,必须对这个计算稍作修改。Spark 中的 reduce 不能应用以集合作为输入的操作,因而你必须每一次将操作应用于输入中的一对元素。又因为第一次应用的结果是第二次应用的第一个输入,所以操作必须满足结合律和交换律。例如,对于给定输入 [5, 2, 7] ,你不能简单地将 sum 应用于集合,而要这样使用 add : add(add(5, 2), 7) 。因此,必须为 mapper 输出的值添加最小值和最大值计数器,以分别记录 reduce 过程中的最小值和最大值,如下所示:
def counters(item):
"""
将键值对解析为键和概要计数器
计数器格式: (count, total, square, minimum, maximum)
"""
key, value = item # 分解item元组
try:
value = float(value)
self.emit(key, (1, value, value ** 2, value, value))
except ValueError:
# 无法解析,忽略
pass
def aggregation(first, second):
"""
对两个(key, counter)执行概要聚合
"""
count1, total1, squares1, min1, max1 = first
count2, total2, squares2, min2, max2 = second
minimum = min((min1, min2))
maximum = max((max1, max2))
count = count1 + count2
total = total1 + total2
squares = squares1 + squares2
return (count, total, squares, minimum, maximum)
def summary(aggregate):
"""
根据聚合结果,计算概要统计
"""
(key, (count, total, square, minimum, maximum)) = aggregate
mean = total / float(count)
stddev = math.sqrt((square-(total**2)/count)/count-1)
return (key, (count, mean, stddev, minimum, maximum))
def main(sc):
"""
Spark应用程序的主要分析过程
"""
# 给定一个键值对数据集,映射到counters
dataset = dataset.map(counters)
# 根据键执行概要聚合
dataset = dataset.reduceByKey(aggregation)
dataset = dataset.map(summary)
# 将结果写入磁盘
dataset.saveAsTextFile("dataset-summary")
reduceByKey 函数的规则使得 Spark 作业中的数据流不太一样。我们无法通过迭代跟踪最小值和最大值,而只能在计算结果中标注出最后看到的最小值和最大值,并在继续 reduce 时传播它们。因此,我们不能在聚合期间简单地执行最终计算,而是需要另一个 map 在聚合后的 RDD(小得多)上完成概要计算。
索引
与基于聚合的概要技术不同,索引采用多对多的方法。聚合将多个记录收集到单个记录中,而索引将多个记录与一个或多个索引相关联。在数据库中,索引是用于快速查找的专用数据结构,通常是二叉树(binary-tree,B-Tree)。在 Hadoop/Spark 中,索引也能发挥类似的功能,但是它们不会被维护和更新,而通常会成为需要快速查找的下游计算的第一步。
文本索引在 Hadoop 算法“万神殿”中地位特殊,这是由于 Hadoop 最初被用于创建搜索应用程序。我们将介绍两种类型的基于文本的索引:常见的倒排索引以及词频 - 逆文档频率(TF-IDF)。
①倒排索引
倒排索引是从索引项到文档集合中的位置的映射(与从文档到索引项映射的前向索引相反)。在全文搜索中,索引项是搜索项,通常是去除了停用词的词或数字。大多数搜索引擎还采用了某种词干提取 stemming)和 词 形 还 原(lemmatization): 具 有 相 同 含 义 的 多 个 词 被 分 类 到 单 个 词 类( 例 如 “running”“ran”“runs” 由单个词语 “run” 索引)。
最常见的倒排索引用例是搜索:它让搜索算法能快速检索出要排列和返回的文档子集,而免于扫描每个文档。例如,要想查询“running bear”,可以用索引查找包含搜索项“running”和包含搜索项“bear”的文档的交集。然后采用简单的排名系统来返回搜索项紧挨着,而不是相距很远的文档。
来考虑某个预处理后的文本,其中文档 ID 和行号作为键,行文本作为值。我们将这种预处理方式用于莎士比亚戏剧全集。具体来说,我们要创建一个人物关联索引。因此,不能将人物映射到已有的行,而是要针对人物和起始行进行概要分析,以便看出人物的出场顺序。语料库中的每一行表示如下:
hamlet@15261 HAMLET O, that this too too solid flesh would melt
hamlet@15261 Thaw and resolve itself into a dew!
行的第一部分是“戏剧名 @ 行号”标识符,然后是一个 TAB 字符( \t )、人物的名字、第二个 TAB 字符和剧本中的一行文本。如果相同的人物连续说了多行,则用两个 TAB 字符将标识符与文本分开。为了创建一个人物的倒排索引,我们将使用一个恒等 reducer 和下面的 mapper:
class CharacterIndexMapper(Mapper):
def map(self):
for row in self:
row = row.split("\t") # 使用制表符拆分
if not len(row) >= 3: continue # 确保数据格式
if row[1] != "":
# 如果存在人物,发射名字和docid/lineno
self.emit(row[1], row[0])
这个莎士比亚人物索引示例说明了索引的几个关键点:
- 首先,索引项可以是任意的(这里是人物名称);
- 其次,这种算法虽然非常简单,但它高度依赖于输入数据的结构(例如,我们知道要搜索 TAB 分片以找到人物名称);
- 最后,这个示例还使用了我们之前看到的一些 map 和 reduce 模式——恒等 reducer。
- 人物索引作业的输出是人物名称的列表,每个人名对应该人物每次开始说话的行的列表,这可以当作查找表或作为其他类型分析的输入使用。
② TF-IDF
词频 - 逆文档频率(TF-IDF)可能是目前最常用的基于文本的概要形式,它是一种指标,定义词条(单词)和作为较大语料库一部分的文档之间的关系。具体来说,它给出该词在其他文档中的相对频率,从而试着定义该词对于特定文档的重要性。
词频 tf i,j 是给定词条 i 在文档 j 中出现的次数,通常用于衡量该词与该文档的相关性。以一份关于美国政治的文件为例:一方面,我们可能会说像“民主”(democracy)或“选举”(election)这样的词语比“鲁米那”(luminal)这样的词语出现得更频繁,因此它们与文档的整体论述更相关;另一方面,词频本身将过度强调常见的词语,如“说”(speaking)——在给定组合语料库中,该词会出现于科学和政治类文档中。因此,词条 i 的文档频率 df i ,即该词条在多少文档中出现过,用于弥补词频的片面性。也就是说,包含词条的文档数与文档总数 N 的比例的倒数的对数与词频相乘。TF-IDF 分数高,则给定词经常在目标文档中出现,但不常在语料库的其他位置出现。文档 j 中的词条 i 的 TF-IDF 如下所示:

这种方法最初用于文档的主题建模,这是一种试图将主题相同的文档相互关联的聚类形式。不难看出,若文档共享高 TF-IDF 值的词,它们则可能彼此相关,因为这些词条不常出现在语料库的其余部分。
在索引中加入该算法,原因和加入简单的倒排索引类似:它创建了通常用于下游计算和机器学习的数据结构。此外,这个更复杂的示例突出了“使用作业链实现单个算法”这一内容。考虑到这一点,让我们来看看 TF-IDF 的 MapReduce 实现。我们的策略是使用键空间模式在三个作业中传播所需的数据:第一个作业使用简单的单词计数来计算每个文档的词频,该单词计数还维护该词的文档 ID;第二个作业计算该词一共出现在多少文档中;最后一个作业使用前两个作业传播到最后的信息计算 TF-IDF。第一个作业如下所示:
class TermFrequencyMapper(Mapper):
def __init__(self, *args, **kwargs):
"""
初始化分词器和停用词
"""
super(TermFrequencyMapper, self).__init__(*args, **kwargs)
self.stopwords = set()
self.tokenizer = re.compile(r'\W+')
# 从文本文件读取停用词
with open('stopwords.txt') as stopwords:
for line in stopwords:
self.stopwords.add(line.strip())
def tokenize(self, text):
"""
对一行文本进行分词和规范化(只产生非数字、标点和空字符串的非停用词)
"""
for word in re.split(self.tokenizer, text):
if word and word not in self.stopwords and word.isalpha():
yield word
def map(self):
for docid, line in self:
# 对每一行分词,并发射每个(word, docid)
for word in self.tokenize(line):
self.emit((word, docid), 1)
class SumReducer(Reducer):
def reduce(self):
for key, values in self:
total = sum(int(count) for count in values)
self.emit(key, total)
为了计算文档中的词,不能简单地使用空格分割行,而是要使用正则表达式对文本进行分词。我们还从 stopwords.txt 文件中读取了停用词列表,该文件需要包含在作业中。因此,我们的分词方法简单地使用正则表达式进行拆分,并过滤掉停用词、数字和标点符号。更高级的分词器也可以提取词干,或者实现归一化(例如全部变为小写)。第一个作业发射 (term, docid) 为键、频率为值的元组。第二个作业由一个 mapper 和一个 reducer 组成,如下所示:
class DocumentTermsMapper(Mapper):
def map(self):
for line in self:
key, tf = line.split(self.sep) # 将每一行拆分成键值对
word, docid = make_tuple(key) # 解析元组字符串
self.emit(word, (docid, tf, 1)) # 发射词和带计数器的数据
class DocumentTermsReducer(Reducer):
def reduce(self):
for word, values in self:
# 将values加载到内存,进行多次处理和解析
values = [make_tuple(value) for value in values]
# 第一次处理:计算词条的文档频率
terms = sum(int(item[2]) for item in values)
# 第二次处理:为与docid关联的每一个word发射一个值
for docid, tf, num in values:
self.emit((word, docid), (int(tf), terms))
此作业的 mapper 又是一个计数 mapper,用于求词条的文档频率的和;它还改变了键空间,维护针对该文档的词频并将文档 ID 添加到值中。这样,我们可以按词 reduce,其中每个值都对应一个文档。因此,reducer 需要遍历数据两次:一次求和,另一次执行每个文档的键空间更改。为了做到这一点,必须将元组 (docid, tf, count) 缓存在内存中,使用列表推导从生成器加载数据。如果许多文档都包含该词(如“the”这样的高频词),这个计算也许不能在内存中进行。也正因如此,停用词列表对 TF-IDF 的计算才如此重要。其他解决方法包括:将中间数据临时存储到磁盘;再实现一个中间 MapReduce 作业,一个作业用于求词条的文档频率的和,另一个用于改变键空间。
第三个作业如下所示:
class TFIDFMapper(Mapper):
def __init__(self, *args, **kwargs):
self.N = kwargs.pop("documents") # 语料库中的文档数量
super(TFIDFMapper, self).__init__(*args, **kwargs)
def map(self):
for line in self:
key, val = map(make_tuple, line.split(self.sep))
tf, n = (int(x) for x in val)
if n > 0:
idf = math.log(self.N/n)
self.emit(key, idf*tf)
最后一个作业是一个只有 map 的作业,因为我们已经有了计算用的键——由上一个
reducer 发射的 (word, docid) 对。使用恒等 reducer 就完全能够搞定。我们简单地将行解析为 int 的元组,并且只要频率大于零,就计算 TF-IDF。请注意,需要一条额外的信息——语料库中的文档数量,它在这个过程中没有参与计算。
这个任务虽然看似很复杂,但是将执行过程设想为数据流就能好很多:随着计算结果片段的产生,它们被添加到数据流中。键 / 值选择由计算中的下一步骤激发。而且最重要的是,这个计算仅仅遍历了一次原始输入,所以它支持作业的线性依赖。TF-IDF 计算的 Spark 实现也需要这种数据流思维模式,如下所示:
def tokenize(document, stopwords=None):
"""
分词并返回(docid, word)和一个计数
"""
def line_tokenizer(lines):
"""
逐行分词的内部生成器
"""
for line in lines:
for word in re.split(tokenizer, line):
if word and word not in stopwords.value and word.isalpha():
yield word
docid, lines = document
return [((docid, word), 1) for word in line_tokenizer(lines)]
def term_frequency(v1, v2):
"""
拆分复杂的值,计算词频
"""
docid, tf, count1 = v1
_docid, _tf, count2 = v2
return (docid, tf, count1 + count2)
def tfidf(args):
"""
给定((word, docid), (tf, n))参数,计算TF-IDF
请注意,必须提前定义N_DOCS,它是语料库中的文档数(n是word的文档频率)
"""
(key, (tf, n)) = args
if n > 0:
idf = math.log(N_DOCS/n)
return (key, idf*tf)
def main(sc):
"""
Spark应用程序的主要分析过程
"""
# 从数据集加载停用词
with open('stopwords.txt', 'r') as words:
stopwords = frozenset([
word.strip() for word in words.read().split("\n")
]) # frozenset()创建一个元素不变的集合
# 将停用词广播到集群
stopwords = sc.broadcast(stopwords)
# 第一阶段: 分词并计算文档频率
# 请注意: 假设有一个包含(docid, text)对的语料库corpus
docfreq = corpus.flatMap(partial(tokenize, stopwords=stopwords))
docfreq = docfreq.reduceByKey(add)
# 第二阶段: 计算词频,然后执行键空间更改
trmfreq = docfreq.map(lambda (key, tf): (key[1], (key[0], tf, 1)))
trmfreq = trmfreq.reduceByKey(term_frequency)
trmfreq = trmfreq.map(
lambda (word, (docid, tf, n)): ((word, docid), (tf, n))
)
# 第三阶段:为每个(word,document)对计算TF-IDF
tfidfs = trmfreq.map(tfidf)
Spark 作业同样从磁盘加载停用词,然后将其广播到集群的剩余部分。然后,就可以对默认参数为停用词广播值的 tokenize 偏函数应用 flatMap 操作。最后,将 Spark 实现的 term_frequency 和 tfidif 函数映射到每个文档。请注意,因为 reduceByKey 被调用了两次,并且需要在 tfidfs RDD 上应用某个最后的动作,所以此 Spark 作业同样具有三个数据流,和 MapReduce 作业一样。
我在看这段程序时对函数 term_frequency 产生了疑惑,因为我认为如果函数参数 v1 和 v2 的位置不同,那么产生的结果也会不同。后来觉得,因为 Spark 的聚合函数是支持交换律的,因此是不应该出现这种情况的。所以个人认为调用该函数后应该产生了两组值。因此,在调用 reduceByKey 后,对于同一 key(word),应该为每一组 docid, tf 产生一个相应的值。
过滤
过滤是粗粒度地减少下游计算数据的主要方法之一。与聚合通过宏观概览分组来缩小输入空间不同,过滤意在通过去除不需要的记录来缩小计算空间。因为 mapper 非常适合执行过滤,所以许多过滤任务常使用只有 map 的作业(不需要 reducer)。
另外一些过滤任务使用 reducer,收集具有代表性的数据集或根据值进行过滤。这种过滤包括查找最大的 n 个值或最小的 n 个值、去重或子选择。分析中非常常见的过滤任务是抽样:创建一个较小的、具有代表性的数据集,该数据集相对于较大的数据集分布良好(取决于你期望实现的分布类型)。开发中使用面向数据的子样本验证机器学习算法(例如交叉验证)或者进行其他统计计算。
我们通常可以将过滤实现为一个函数,它接受一条记录作为输入。如果评估返回 true,则发射记录,否则丢弃记录。我们将探讨无序的最大 / 最小 n 个元素、抽样技术,以及经布隆过滤器提高性能后的高级过滤。
① top n 记录
top n 记录(以及相反的 bottom n 记录)方法是一个基数比较过滤器,它需要一个 mapper 和一个 reducer。其基本原理是让每个 mapper 产生其 top n 个项目,然后 reducer 将从 mapper 产生的项目中同样选择 top n 个项目。如果 n 相对较小(至少与数据集的其余部分相比),单个 reducer 应该能够轻松处理该计算,因为每个 mapper 最多产生 n 条记录:
import bisect
class TopNMapper(Mapper):
def __init__(self, n, *args, **kwargs):
self.n = n
super(TopNMapper, self).__init__(*args, **kwargs)
def map(self):
items = []
for value in self:
# 维护有序的items列表(将值value按照顺序插入升序数组items中)
bisect.insort(items, value)
for item in items[-self.n:]:
# 从mapper发射前n个值
self.emit(None, item)
class TopNReducer(object):
def __init__(self, n, *args, **kwargs):
self.n = n
super(TopNReducer, self).__init__(*args, **kwargs)
def reduce(self):
items = []
for _, values in self:
for value in values:
bisect.insort(items, value)
for item in items[-self.n:]:
# 从reducer发射前n个值
self.emit(None, item)
这里的 mapper 和 reducer 都使用了 bisect 模块将值按升序插入列表。为了获得最大的 n 个值,使用了负索引的切片,从而选择有序列表中的最后 n 个值。要得到最小的 n 个值,可以简单地分片取出列表中的前 n 个值。使用 None 作为键可确保仅使用单个 reducer。
注意:
- Spark 拥有丰富的 RDD API,你可以使用 top 和 takeOrdered 动作,而不必自己实现;
- 对于 Spark 和 MapReduce,为了能进行排序,需要记录是可比较的;
- 这种方法最大的好处是不需要对整个数据集进行完整的排序;相反,每个 mapper 对它们自己的数据子集进行排序, 而 reducer 仅看到 mapper 数量 n 倍的数据。
②简单随机抽样
简单随机抽样是数据集的子集,数据集的每条记录属于该子集的可能性相同。在这种情况下,评估函数不关心记录的内容或结构,而是利用某种随机数生成器来评估是否发射记录。但问题来了,如何确保每个元素被选中的可能性相同呢?
如果需要的样本不是必须大小为 n ,而是包含百分之多少的记录就好,第一种方法是简单地使用随机数生成器来产生数字,并将其与期望的阈值大小进行比较。随机数生成器可用值的范围与阈值将共同决定大约发射百分之多少的记录。一般来说,随机数生成器返回的值在 0~1,因此与百分比的直接比较将产生预期的结果!例如,如果想要从数据集中采样20%,可以写如下的 mapper:
import random
class PercentSampleMapper(Mapper):
def __init__(self, *args, **kwargs):
self.percentage = kwargs.pop("percentage")
super(PercentSampleMapper, self).__init__(*args, **kwargs)
def map(self):
for _, val in self:
if random.random() < self.percentage:
self.emit(None, val)
if __name__ == '__main__':
mapper = PercentSampleMapper(sys.stdin, percentage=0.20)
mapper.map()
此作业将返回原始数据集的 20%左右,因为每条记录产生的随机数小于 0.2 的可能性相同,所以随机数小于 0.2 发生的可能性只大约为调用次数的 20%。如果这个作业运行时只有 mapper 而没有 reducer,许多小文件将被写入到磁盘,文件的数量与mapper 的数量相同。使用一个恒等 reducer 将确保这些值都被收集到单个文件中。
然而,如果想要一个大小精确为 n 的样本呢?为了确保每种方法机会均等,必须进行 n 次随机选择,每次选择一个元素,而不进行替换,以确保每条记录被选中的机会均等。一种方法是打乱记录,选择 0~ N - 1 的一个随机数,其中 N 是记录数,并发射在该索引处的记录。然后再次打乱,选择 0~ N - 2 的随机数, 依此类推。
一般来说,当你在 mapper 中使用任何概率分布时,你都必须小心,因为不能保证 mapper 在多次运行中看到相同的数据,也不能保证每个 mapper 获得相同数量的数据,更不能保证映射过程保持一个特定的顺序。这些不确定性会导致一些 mapper 预期的可能性过高或过低。对此(正确)的反应应该是将工作移动到一个 reducer 或聚合上进行,但这样做的话,在集群上多进程执行的优势可能会不复存在!要谨记,同一算法的串行和并行实现往往可能迥然不同!
为了并行化打乱(shuffle)方法,我们可以想象将一幅扑克牌平均发给了四位玩家。如果想要抽取 4 张牌,并且让每张牌被选中的可能性相等,可以简单地让每位玩家洗他们各自手中的牌,然后每个人给你发 4 张牌;然后,你从这 16 张牌中选择前 4 张。但如果你把牌从空中掷给每位玩家,而不是平均发给他们,则每位玩家得到的牌数可能不均等,但这种方法仍然能确保每张牌被选中的可能性相等。这时问题就变成了:该如何使用 Hadoop 来打乱记录,以便获得更好的性能?
答案是在 mapper 中为每个记录分配一个 0~1 的随机浮点数。随后,mapper 会发射前 n 个记录。同样,reducer 也只会发射它从 mapper 接收的前 n 个记录。虽然此机制仍然只允许单个 reducer,但是该 reducer 获取的是数据的有限子集(例如 mapper 数量的 n 倍),子集应该能够放入 reducer 的内存中。因为每行拥有 n 个最大随机数之一的概率相等,所以能获得一个随机样本:
import random, heapq
class SampleMapper(Mapper):
def __init__(self, n, *args, **kwargs):
self.n = n
super(SampleMapper, self).__init__(*args, **kwargs)
def map(self):
# 将堆初始化成一个包含n个0的列表
heap = [0 for x in range(self.n)]
for value in self:
# 维护一个堆,只包含最大的n个值
heapq.heappushpop(heap, (random.random(), value))
for item in heap:
# 发射抽样数据
self.emit(None, item)
class SampleReducer(Mapper):
def __init__(self, n, *args, **kwargs):
self.n = n
super(SampleReducer, self).__init__(*args, **kwargs)
def reduce(self):
# 将堆初始化为一个包含n个0的列表
heap = [0 for x in range(self.n)]
for _, values in self:
for value in values:
heapq.heappushpop(heap, make_tuple(value))
for item in heap:
# 发射抽样数据
self.emit(None, item[1])
我们本可以像使用 top n 记录方法时一样使用 bisect 模块,但是为了获取多样性,我们使用堆数据结构在内存中维持一个只有 n 个最大随机值的列表。这进一步减小了 mapper 和 reducer 的内存需求(对 reducer 尤为明显),使每次只有 n 个值保存在内存中。我们的 mapper(reducer 也类似)初始化了一个长度 n 值为零的列表。 heapq.heappushpop 函数将新值压入到堆中,然后弹出最小值(而且还比顺序调用 heapq.push 和 heapq.pop 快得多)。
③ 布隆过滤
布隆过滤器可以简单解释如下:
- BloomFilter 是一个通过多哈希函数映射到一张表的数据结构,能够快速地判断一个元素在一个集合内是否存在,具有很好的空间和时间效率。

它的原理如下: - BloomFilter 会开辟一个 m 位的位数组,开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(h1,h2,h3…)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。
- 注意,多个哈希函数计算出来的值必须 [0,m) 之中。
- 当判断对应值是否在集合中时,同样通过哈希函数求值,再去寻找数组的下标,如果所有下标都为1时,元素存在。当然也存在错误率。
布隆过滤器是一种高效的概率型数据结构,用于执行集合成员资格测试。布隆过滤器必须进行预先计算以收集“热值”(排除集的成员)——需要过滤的值。布隆过滤器的好处在于,它很紧凑(方便将大集合传输到集群上的每个 mapper),并且能快速测试成员资格。但是,布隆过滤器可能会误判(false positive);换句话说,它会把不属于集合的元素判断为属于集合。不过,它能保证不会排除任何属于集合的元素——没有漏报(false negative)。
因此,表达式 x in bloom 就意味着“ x 可能在集合中”或“ x 绝对不在集合中”。这也决定了布隆过滤器的构造,因为你要在过滤器集合的大小、数据中可能有多少元素,以及 mapper 和 reducer 的内存容量之间进行权衡。通过权衡,你能采用不同程度的模糊性。在构造大多数布隆过滤器时,可以设置误判的概率阈值,这会使布隆过滤器增大或缩小。
使用布隆过滤器的第一步是构建它。布隆过滤器对输入数据应用几个散列函数,然后根据散列值设置位数组中的位。一旦构建了位数组,就可以将散列函数应用于测试数据并查看相关位是否为 1,从而测试成员资格。根据一定的规则将不同的值映射到构造布隆过滤器的 reducer,可以并行化位数组的构造过程。
在这个例子中,我们将使用第三方库 pybloomfiltermmap ,可以通过 pip 安装。虽然 Python 有很多第三方布隆过滤器库,但这个库提供了创建可配置过滤器的最好的 API。来思考一个例子:基于推文是否包含词条和用户名白名单中的标签(#)或者 @ 回复,决定是否包含推文。为了创建布隆过滤器,从磁盘加载数据,并将布隆过滤器保存到一个 mmap 文件,如下所示:
from pybloomfilter import BloomFilter
bloom = BloomFilter(1000000, 0.1, 'twitter.bloom')
for prefix, path in (('#', 'hashtags.txt'), ('@', 'handles.txt')):
with open(path, 'r') as f:
for word in f:
bloom.add(prefix + word.strip())
本示例创建了一个有 100 万元素、错误率为 0.1 的布隆过滤器。它在底层使用这些参数来选择最优数 k (所需散列函数的数量),以保证给定容量下的错误阈值。性能和空间也存在折中——容量越小且错误率越低,需要的散列函数就越多,计算也就越慢;容量越大,布隆过滤器就必须越大。从磁盘文件读取标签和 Twitter 句柄(并给它们加上适当的前缀)后,布隆过滤器将被写入磁盘上一个名为 twitter.bloom 的文件中。
在 Spark 中使用它:
ELEMS = re.compile(r'[#@][\w\d]+')
def tweet_filter(tweet, bloom=None):
for elem in ELEMS.findall(tweet['text']):
if elem in bloom.value:
return True
# 从磁盘加载布隆过滤器,进行并行化
bloom = sc.broadcast(BloomFilter.open('twitter.bloom'))
# 从磁盘加载JSON推文,进行解析
tweets = sc.textFile('tweets').map(json.loads)
tweets = tweets.filter(partial(tweet_filter, bloom=bloom))
我们的推文过滤器是使用 functools.partial 函数创建的,该函数创建了一个拥有布隆过滤器广播变量的闭包,而布隆过滤器是从驱动程序所处主机的磁盘加载的。 tweet_filter 函数使用一个正则表达式提取所有标签和 @ 回复,然后检查它们是否在布隆过滤器中;如果是,则返回 True ,从而保留 RDD 中与白名单匹配的所有元素。
布隆过滤器可能是常用于 Hadoop 分析的最复杂的数据结构。此处提到是为了表明性能和正确性的结合将如何影响分布式计算。作为实践大数据的数据科学家,你会发现随机方法能助力及时计算,这是进一步分析所需要的。
4.迈向最后一英里分析
以上,我们研究了许多数据分析模式,从键计算到聚合、过滤的常规模式。这里面有一个宏观主题:将数据从较大的输入分解为较小的、更易于管理的输入。使用我们讨论过的工具,本节将讨论端到端预测模型的计算策略。
许多机器学习技术在底层使用广义线性模型(generalized linear model,GLM)来估计给定输入数据和误差分布的响应值(response variable)。最常用的 GLM 是线性回归(还有逻辑回归和泊松回归),为模拟因变量 Y 和一个或多个自变量 X 之间的连续关系建模。该关系由一组系数和一个误差项表示如下:

系数 β 的计算是将模型拟合到现有数据的主要目标。这通常通过一个优化算法来完成——根据给定的某个数据集的 X 和 Y 的观察值,该算法能找到一组最小化错误量的系数。请注意,线性回归可以被认为是一种有监督机器学习方法,因为“正确”答案(拟合模型的 X 和 Y 变量)是预先已知的。
普通最小二乘法和随机梯度下降这样的优化算法是迭代的;也就是说,它们要多次遍历数据。在大数据环境中,每次优化迭代都多次读取完整数据集可能会非常耗时,在按需分析或开发中尤其明显。Spark 在 MLlib 中提供的分布式机器学习算法和内存计算让情况稍有好转。但如果碰上极大的数据集或极小的时间窗口,即使是 Spark 也需要花费很长时间;如果 Spark 没有你想要实现的模型或分布式算法,那么分析方法的选择范围将因分布式编程的诸多困难而受限。
通用的解决方案是:将输入数据集转换为更小的数据集,让它可以在内存中被处理,从而达到分解问题的目的。一旦数据集被缩小成内存计算,它就可以使用标准技术进行分析,然后在整个数据集中验证。对于线性回归,我们可以对数据集进行简单随机抽样,对样本执行特征提取,构建线性模型,然后通过计算整个数据集的均方误差来验证模型。
模型拟合
考虑一个具体的例子:我们有一个新闻报道或博文的数据集,现在要预测接下来的 24 小时内的评论数量。针对网络爬取的原始 HTML 页面,数据流应如下所示:
- 解析 HTML 页面获取元数据,并将主文本与评论分开。
- 创建一个从时间戳到博文评论 / 评论者的索引。
- 使用该索引为模型创建实例,实例是一篇博文以及 24 小时滑动窗口内的评论。
- 将实例与主文本数据(评论和博文)连接起来。
- 提取每个实例的特征(例如,前 24 小时的评论数、博文长度、从窗口到发布时间之间的时间、bag of words 特征、星期几,等等)。
- 对实例特征取样。
- 使用 Scikit-Learn 或 Statsmodels 在内存中构建一个线性模型。
- 计算整个数据集的实例特征的均方误差或者决定系数。
该数据流表明,许多预处理作业仅需要运行一次或几次(例如,特征提取需要在整个特征分析生命周期中反复运行)。然而,模型抽样和验证过程可以例行运行。一旦启动并运行这个模型,它甚至可以在线运行,当新的信息被馈送到数据流水线中时,该模型重新进行拟合和验证。
此时,假设我们已经成功得到一个具有所有特征的数据集。使用前面介绍过的抽样技术,可以获取更小的数据集,将其保存到磁盘,并使用 Scikit-Learn 构建一个线性模型:
import pickle
import numpy as np
from sklearn import linear_model
# 从磁盘的制表符分割文件加载数据
data = np.loadtxt('sample.txt')
# 目标是第一列(键),X是值
y = data[:,0]
X = data[:,1:]
# 实例化并拟合线性模型
clf = linear_model.Ridge(alpha=1.0, fit_intercept=True)
clf.fit(X, y)
# 将模型作为pickle写入磁盘
with open('clf.pickle', 'wb') as f:
pickle.dump(clf, f)
这段代码使用 np.loadtxt 函数从磁盘加载样本数据,在这个例子中是包含实例的制表符分隔文件,第一列是目标值,其余列是特征。这种类型的输出与 Spark 和 MapReduce 将键值对写入磁盘时的格式吻合,但是你必须将集群中的数据收集到单个文件,并确保文件格式正确。然后,数据被拟合到岭回归,这是一种使用正则化来防止过拟合的线性回归模型。
模型验证
为了在集群中评估这个模型的效果,我们有两个选择。第一种,将 Scikit-Learn 线性模型属性 clf.coef_ (系数)和 clf.intercept_ (错误项)写入磁盘,然后将这些参数加载到我们的 MapReduce 或 Spark 作业中,并自行计算误差。然而,这需要为每个模型实现一个预测函数。第二种,使用 pickle 模块将模型转储到磁盘,然后将其加载到集群中的每个节点供预测使用。现在就来编写 Scikit-Learn 模型误差估计模板。
要想验证模型,就必须计算整个数据集的均方误差(mean square error,MSE)。误差被定义为实际值和预测值之间的差值 y - ŷ。为了确保没有负值(这将减少误差),我们将计算平方误差的均值。为此,只需要一个计算平均值的 reducer 和一个加载模型并计算均方误差的 mapper 即可:
import pickle
class MSEMapper(Mapper):
def __init__(self, model, *args, **kwargs):
super(MSEMapper, self).__init__(*args, **kwargs)
# 从磁盘加载模型
with open(model, 'rb') as f:
self.clf = pickle.load(f)
def map(self):
for row in self:
# 解析行内浮点数值
row = map(float, row)
y = row[0]
X = row[1:]
yhat = self.clf.predict(x)
self.emit(_, (y-yhat) ** 2)
可以在 Spark 中使用一个累加器来求平方误差之和,并将模型广播到集群上,如下所示:
def cost(row, clf=None):
"""
计算给定行的平方误差
"""
return (row[0] - clf.predict(row[1:])) ** 2
def main(sc):
"""
Spark应用程序的主要分析过程
"""
# 从pickle文件加载模型
with open('clf.pickle', 'rb') as f:
clf = sc.broadcast(model.load(f))
# 创建累加器,求平方误差的和
sum_square_error = sc.accumulator(0)
# 加载和解析博客数据
blogs = sc.textFile("blogData").map(float)
# 映射cost函数,累加平方误差
error = blogs.map(partial(cost, clf=clf))
error.foreach(lambda cost: sum_square_error.add(cost))
# 计算平均平方误差并打印
print sum_square_error.value / error.count()
使用 pickle 模块来序列化 Scikit-Learn 模型是使用极大数据集进行机器学习的好开始。工作流通常是将经过序列化的模型存储在数据库 blob 字段中,然后根据需要在集群中进行加载和验证。更高级的大数据和扩展需要像 Mahout 和 Spark 的 MLlib 这样的机器学习库。无论采用哪种方式,抽样、训练、验证策略都是行之有效的分析方法。
九、数据挖掘和数据仓储
这一章我们将讨论数据挖掘和数据仓储,并就关系型和列式数据存储及查询分别介绍 Hive 和 HBase。
作为数据分析师,我们通常更愿意专注于能获取有意义见解的数据挖掘任务,或者对经过整理(curated)、清洗和分段(staging)的数据应用预测建模方法。然而,在大多数传统企业的数据环境中,在进行任何有意义的数据分析之前,都需要投入大量的工程和技术资源来收集这些数据,并将其组织到统一的数据仓库中。
因此,企业数据仓库(enterprise data warehouse,EDW)已经成为大多数企业处理和分析大规模数据的关键。然而,由于绝大多数 EDW 使用某种形式的关系数据库管理系统(RDBMS)作为主要的存储工具和查询引擎,因此在开展新的数据分析项目时,将在前期模式设计和 ETL(数据仓库技术,ETL 是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程)操作上花费大量精力。据估计,ETL 将占数据仓储成本、风险和实施时间的 70%~80%。 这种开销导致即使是最一般的数据分析原型设计或探索性分析也成本高昂。
当我们需要存储和分析的数据的数据类型急剧增加时——这些数据可以是非结构化的或半结构化的——RDBMS 就暴露了另一个局限性:数据的速度和多样性常常需要“即时”地演进模式,这要被传统的 DW 支持是件非常困难的事。
正是出于这些原因,Hadoop 成为了数据仓储和数据挖掘领域最具革命性的技术。它将存储与处理分离,使公司能够将其原始数据存储在 HDFS 中,而不需要通过 ETL 将数据整合到一个统一的数据模型中。此外,通过使用 YARN 的通用处理层,我们能够从多个角度直接访问和查询原始数据,还能根据特定用例使用不同的方法(SQL、NoSQL)。因此,Hadoop 不仅支持探索性分析和数据挖掘原型设计,还为数据和分析的新类型打开了大门。
1. Hive 结构化数据查询
Apache Hive 是一个建立在 Hadoop 之上的“数据仓储”框架。Hive 为数据分析人员提供了熟悉的、基于 SQL 的 Hadoop 接口,使他们能为 HDFS 中的数据添加结构化模式,并能使用 SQL 查询访问和分析该数据。Hive 使熟练使用 SQL 的开发人员能发挥 Hadoop 的可扩展性和弹性,而不需要他们学习 Java 或原生的 MapReduce API。
Hive 提供了自己的 SQL 方言,被称为 Hive 查询语言(Hive Query Language,HQL)。HQL 支持许多常用的 SQL 语句,包括数据定义语句(DDL,例如 CREATE DATABASE/SCHEMA/TABLE )、数据操作语句(DML,例如 INSERT、UPDATE 和 LOAD )和数据检索查询 (例如 SELECT )。Hive 还支持集成用户定义函数,这些函数可以由 Java 或 Hadoop Streaming 支持的任何语言编写,扩展了 HQL 的内置功能。
Hive 命令和 HQL 查询被编译成执行计划或一系列 HDFS 操作和 / 或 MapReduce 作业,然后在 Hadoop 集群上执行。因此,Hive 继承了 HDFS 和 MapReduce 的某些限制,无法提供传统数据库管理系统应有的关键联机事务处理(online transaction processing,OLTP)功
能。具体来说,因为 HDFS 是写一次,读多次(WORM)文件系统,并且不提供就地文件更新,因此 Hive 执行起行级插入、更新或删除不是非常高效。事实上,这些行级更新最近才被 Hive 的 0.14.0 版本支持。
此外,为了满足在集群上生成和启动编译的 MapReduce 作业所需的开销,Hive 查询需要更长的延迟;在传统 RDBMS 上几秒就能完成的小型查询在 Hive 中可能需要几分钟才能完成。好在 Hive 提供了所有基于 Hadoop 的应用程序都应有的高可扩展性和高吞吐量。因此,它
非常适用于联机分析处理(online analytical processing,OLAP)的批处理任务,处理 TB级甚至 PB 级的超大数据集。
Hive命令行接口(CLI)
Hive 的安装包里有一个方便的命令行接口(command-line interface,CLI),我们将使用它与 Hive 交互,并运行 HQL 语句。从 $HIVE_HOME 启动 Hive CLI:
~$ cd $HIVE_HOME
/srv/hive$ bin/hive
这将启动 CLI 并引导启动 logger(如果配置了)和 Hive 历史记录文件,并最终显示 Hive CLI 提示:
hive>
使用以下命令可以随时退出 Hive CLI:
hive> exit;
通过传递文件名选项 -f 和要执行的脚本的路径,Hive 也可以直接从命令行以非交互模式运行:
~$ hive -f ~/hadoop-fundamentals/hive/init.hql
~$ hive -f ~/hadoop-fundamentals/hive/top_50_players_by_homeruns.hql >>
~/homeruns.tsv
此外,带引号的查询字符串选项 -e 让你能从命令行运行内联命令:
~$ hive -e 'SHOW DATABASES;'
可以使用 -H 标志查看 CLI 的 Hive 选项的完整列表:
~$ hive -H
| usage: hive | |
|---|---|
| -d,–define |
Variable substitution to apply to hive commands. e.g. -d A=B or --define A=B |
| –database < databasename > | Specify the database to use |
| -e < quoted-query-string > | SQL from command line |
| -f < filename > | SQL from files |
| -H,–help | Print help information |
| -h < hostname > | connecting to Hive Server on remote host |
| –hiveconf < property=value > | Use value for given property |
| –hivevar < key=value > | Variable substitution to apply to hive commands. e.g. --hivevar A=B |
| -i < filename > | Initialization SQL file |
| -p < port > | connecting to Hive Server on port number |
| -S,–silent | Silent mode in interactive shell |
| -v,–verbose | Verbose mode (echo executed SQL to the console) |
非交互模式为运行已存脚本提供了方便,但是 CLI 使我们能够在 Hive 中轻松地调试和迭代查询。
Hive查询语言
在本节中,我们将通过编写 HQL 语句,创建 Hive 数据库、将 HDFS 中的数据加载到数据库,以及查询数据进行分析。
①创建数据库
在 Hive 中创建数据库与在基于 SQL 的 RDBMS 中创建数据库非常相似,使用 CREATE DATABASE 或 CREATE SCHEMA 语句:
hive> CREATE DATABASE log_data;
当 Hive 创建新数据库时,模式定义数据存储在 Hive Metastore 中。如果 Metastore 中已经有该数据库,Hive 将抛出错误。我们可以通过使用 IF NOT EXISTS 来检查数据库是否存在:
hive> CREATE DATABASE IF NOT EXISTS log_data;
然后运行 SHOW DATABASES 来验证数据库是否已被创建。Hive 将返回在 Metastore 中找到的所有数据库,以及默认的 Hive 数据库:
hive> SHOW DATABASES;
OK
default
log_data
Time taken: 0.085 seconds, Fetched: 2 row(s)
此外,可以使用 USE 命令设置工作数据库:
hive> USE log_data;
这样就可以在 Hive 中创建一个数据库。可以通过在数据库中创建表定义,描述数据的结构。
②创建表
Hive 提供了一个类似 SQL 的 CREATE TABLE 语句,最简单的形式由一个表名和一个列定义构成:
CREATE TABLE apache_log (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING
);
但是由于 Hive 数据存储在文件系统,通常在 HDFS 或本地文件系统中,所以 CREATE TABLE 命令还使用可选子句指定行格式,使用 ROW FORMAT 子句告诉 Hive 如何读取文件中的每一行并映射到我们的列。例如,可以指明数据位于由制表符分隔字段的文件中:
hive> CREATE TABLE shakespeare (
lineno STRING,
linetext STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
Apache 访问日志的每行根据通用日志格式进行结构化。好在 Hive 为我们提供了一种方法,能将正则表达式应用于已知格式的记录,从而将每行反序列化或解析为各个组成字段。我们将使用 Hive 的 serializer-deserializer 行格式选项 SERDE 和 RegexSerDe 库来指定反序列化,并将字段映射到表列的正则表达式。需要手动将 lib 文件夹中的 hive-serde JAR 添加到当前 hive 会话,以便使用 RegexSerDe 包:
hive> ADD JAR /srv/hive/lib/hive-serde-0.13.1.jar;
现在删除之前创建的 apache_log 表,并使用自定义序列化器重新创建它:
hive> DROP TABLE apache_log;
hive> CREATE TABLE apache_log (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\])([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?", "output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s")
STORED AS TEXTFILE;
创建之后就可以使用 DESCRIBE 来验证表定义:
hive> DESCRIBE apache_log;
OK
host string from deserializer
identity string from deserializer
user string from deserializer
time string from deserializer
request string from deserializer
status string from deserializer
size string from deserializer
referrer string from deserializer
agent string from deserializer
Time taken: 0.553 seconds, Fetched: 9 row(s)
请注意,在这个表中,所有列都使用 Hive 原始数据类型 string 定义。Hive 支持 SQL 用户熟悉的许多其他原始数据类型,下表列举了这些原始数据类型:
| 类型 | 描述 | 举例 |
|---|---|---|
| TINYINT | 8 位带符号整数,从 -128 到 127 | 127 |
| SMALLINT | 16 位带符号整数,从 -32768 到 32767 | 32767 |
| INT | 32 位带符号整数 | 2147483647 |
| BIGINT | 64 位带符号整数 | 9223372036854775807 |
| FLOAT | 32 位单精度浮点数 | 1.99 |
| DOUBLE | 64 位双精度浮点数 | 3.14159265359 |
| BOOLEAN | true 或 false | true |
| STRING | 最大 2GB 的字符串 | hello world |
| TIMESTAMP | 纳秒级时间戳 | 1400561325 |
除原始数据类型之外,Hive 还支持可以存储值集合的复杂数据类型,下表列举了这些类型:
| 类型 | 描述 | 举例 |
|---|---|---|
| ARRAY | 有序集合,数组中元素的类型必须相同 | recipients ARRAY < email:STRING > |
| MAP | 无序键值对集合,键必须是原始数据类型,但值可以是任意类型 | files MAP < filename:STRING,size:INT > |
| STRUCT | 任意类型元素集合 | address STRUCT < street:STRING,city:STRING,state: STRING,zip:INT > |
关系数据库通常不支持集合类型,而是将相关集合存储在单独的表中,以维持第一范式(一言以蔽之,第一范式的数据表必须是二维数据表),最小化数据重复和数据不一致的风险。然而,在像 Hive 这样的通过顺序扫描磁盘来处理大量非结构化数据的大数据系统中,读取嵌入集合能大大提高检索性能。
③加载数据
创建表和定义模式之后,就可以将数据加载到 Hive 了。请注意 Hive 和传统 RDBMS 在强化模式(schema enforcement)上有一个重要区别:Hive 不会对数据执行任何证明它是否符合表模式的验证,也不会在将数据加载到表中时执行任何转换。
传统的关系数据库通过拒绝写入不符合模式定义的数据,强制执行写时模式(schema on write);而 Hive 对查询只强制执行读时模式(schema on read)。在读取数据文件时,如果文件结构与定义的模式不匹配,Hive 通常会为缺失的或类型不匹配的字段返回 null 值,并尝试从错误中恢复。读时模式初始加载的速度非常快,因为数据不以数据库的内部格式读取、解析和序列化到磁盘。加载操作纯粹是将数据文件移动到 Hive 表中对应位置的复制 / 移动操作。
Hive 中的数据加载通过 LOAD DATA 命令批量完成,也可以使用 INSERT 命令插入另一个查询的结果完成。首先,将 Apache 日志数据文件复制到 HDFS,然后将其加载到之前创建的表中:
~$ hadoop fs –mkdir statistics
~$ hadoop fs –mkdir statistics/log_data
~$ hadoop fs –copyFromLocal ~/hadoop-fundamentals/data/log_data/apache.log statistics/log_data/
可以使用 tail 命令验证 apache.log 是否成功上传到了 HDFS:
~$ hadoop fs –tail statistics/log_data/apache.log
一旦文件上传到了 HDFS,就返回 Hive CLI 并使用 log_data 数据库:
~$ $HIVE_HOME/bin/hive
hive> use log_data;
OK
Time taken: 0.221 seconds
使用 LOAD DATA 命令,并指定日志文件的 HDFS 路径,将内容写入到 apache_log 表中:
hive> LOAD DATA INPATH 'statistics/log-data/apache.log' OVERWRITE INTO TABLE apache_log;
Loading data to table log_data.apache_log
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://localhost:9000/user/hive/warehouse/log_data.db/apache_log
Table log_data.apache_log stats: [numFiles=1, numRows=0, totalSize=52276758, rawDataSize=0]
OK
Time taken: 0.902 seconds
LOAD DATA 是 Hive 的批量加载命令。 INPATH 携带一个指向默认文件系统(本例中为 HDFS)中的路径的参数。我们还可以使用 LOCAL INPATH 来指定本地文件系统上的路径。Hive 将文件移动到仓库位置。如果使用 OVERWRITE 关键字,则目标表中的所有已有数据将被删除并由数据文件输入替换;否则,新数据将被添加到表中。
数据复制并加载后,Hive 输出了一些关于加载数据的统计信息;虽然报告的 num_rows 为 0,但你可以通过运行 SELECT COUNT 来验证实际行数(省略输出):
hive> SELECT COUNT(1) FROM apache_log;
Total MapReduce jobs = 1 # 执行了一个 MapReduce 作业来执行聚合
Launching Job 1 out of 1
...
OK
726739
Time taken: 34.666 seconds, Fetched: 1 row(s)
可以看到,这个 Hive 查询运行时,实际上执行了一个 MapReduce 作业来执行聚合。在 MapReduce 作业执行后,你可以看到 apache_log 表目前有 726739 行。
Hive数据分析
我们已经定义了一个模式并将数据加载到了 Hive 中,现在就可以对 Hive 数据库运行 HQL 查询,从而对数据进行实际的数据分析了。我们将编写和运行 HQL 查询,根据先前导入的 Apache 访问日志数据,确定远程流量访问的高峰月份。
①分组
我们已经将一份 Apache 访问日志文件加载到了名为 apache_log 的 Hive 表中,其中包含 Apache Common Log 格式的 Web 日志数据:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 2002326
考虑一个计算每个自然月访问数的 MapReduce 程序。尽管这是一个非常简单的分组计数问题,但是要实现这个 MapReduce 程序仍然需要耗费不少的精力——除了要编写 mapper 、reducer 和配置作业的 main 函数之外,还要编译和创建 JAR 文件。但有了 Hive 的话,这
个问题将与运行 SQL 的 GROUP BY 查询一样简单直观:
hive> SELECT
month,
count(1) AS count
FROM (SELECT split(time, '/')[1] AS month FROM apache_log) l
GROUP BY month
ORDER BY count DESC;
OK
Mar 99717
Sep 89083
Feb 72088
Aug 66058
Apr 64984
May 63753
Jul 54920
Jun 53682
Oct 45892
Jan 43635
Nov 41235
Dec 29789
NULL 1903
Time taken: 84.77 seconds, Fetched: 13 row(s)
Hive 查询和 MapReduce 程序都要对输入进行分词,并提取月份令牌作为聚合字段。不仅如此,Hive 还提供了简洁自然的查询接口来执行分组;又因为数据被结构化为 Hive 表,所以我们可以轻松地在其他任何字段上执行其他即时查询:
hive> SELECT host, count(1) AS count
FROM apache_log
GROUP BY host
ORDER BY count;
除了计数之外,Hive 还支持其他聚合函数来计算数字列的总和、平均值、最小值、最大值以及方差、标准差和协方差等统计聚合。使用这些内置聚合函数时,可以通过将以下属性设置为 true 来提高聚合查询的性能:
hive> SET hive.map.aggr = true;
这种设置告诉 Hive 在 map 阶段执行“顶层”(top-level)聚合,这与执行 GROUP BY 后再进行聚合不同。但请注意,此设置将需要更多内存。Hive 还提供了轻松存储计算结果的捷径。你可以创建新的表来存储这些查询返回的结果,以便进行记录保存和分析:
hive> CREATE TABLE
remote_hits_by_month
AS
SELECT
month,
count(1) AS count
FROM (
SELECT split(time, '/')[1] AS month
FROM apache_log
WHERE host == 'remote'
) l
GROUP BY month
ORDER BY count DESC;
CREATE TABLE AS SELECT (CTAS)操作非常有用,它能从现有 Hive 表过滤和聚合,从而派生并构建新表。
②聚合和连接
当在单个结构化的数据集中查询和聚合数据时,Hive 能提供一些便利。但在多个数据集之上执行更复杂的聚合时,Hive 才能真正物尽其用。我们曾开发过一个 MapReduce 程序,根据交通研究与创新技术管理局(RITA)收集的航班数据分析美国航空公司的准点情况。我们曾将该准点数据集进行了归一化,让单个数据文件包含所有必需的数据;但事实上,从 RITA 网站下载的数据包括航空公司和飞机的代码,它们必须分别参照单独的查找数据集。
ontime_flights.tsv 中的准点航班数据的每一行都包含一个表示航空公司代码(如 19805)的整数值和一个表示飞机代码(如“AA”)的字符串值。航空公司代码可以与 airlines.tsv 文件中相应的代码进行连接,该文件每行包含代码和相应的描述:
19805 American Airlines Inc.: AA
同理,飞机代码可以与 carriers.tsv 中对应的代码进行连接,该文件包含代码、相应的航空公司名称和生效日期:
AA American Airlines Inc. (1960 - )
要在 MapReduce 程序中实现这些连接,需要在 map 端加载查找表到内存中进行连接,或者在 reduce 端连接。这两种方法都需要耗费大量精力编写配置作业的 MapReduce 代码;但是通过 Hive,则可以简单地将这些附加的查找数据集加载到单独的表中,并在 SQL 查询中执行连接。
假设我们已经将数据文件上传到了 HDFS 或本地文件系统。首先,为航班数据创建一个新的数据库:
hive> CREATE DATABASE flight_data;
OK
Time taken: 0.741 seconds
然后,为准点数据和查找表定义模式并加载数据(出于可读性考虑,省略输出和添加换行):
hive> CREATE TABLE flights (
flight_date DATE,
airline_code INT,
carrier_code STRING,
origin STRING,
dest STRING,
depart_time INT,
depart_delta INT,
depart_delay INT,
arrive_time INT,
arrive_delta INT,
arrive_delay INT,
is_cancelled BOOLEAN,
cancellation_code STRING,
distance INT,
carrier_delay INT,
weather_delay INT,
nas_delay INT,
security_delay INT,
late_aircraft_delay INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
hive> CREATE TABLE airlines (
code INT,
description STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
hive> CREATE TABLE carriers (
code STRING,
description STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
hive> CREATE TABLE cancellation_reasons (
code STRING,
description STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
hive> LOAD DATA LOCAL INPATH '${env:HOME}/hadoop-fundamentals/data/flight_data/ontime_flights.tsv'
OVERWRITE INTO TABLE flights;
hive> LOAD DATA LOCAL INPATH '${env:HOME}/hadoop-fundamentals/data/flight_data/airlines.tsv'
OVERWRITE INTO TABLE airlines;
hive> LOAD DATA LOCAL INPATH '${env:HOME}/hadoop-fundamentals/data/flight_data/carriers.tsv'
OVERWRITE INTO TABLE carriers;
hive> LOAD DATA LOCAL INPATH '${env:HOME}/hadoop-fundamentals/data/flight_data/cancellation_reasons.tsv'
OVERWRITE INTO TABLE cancellation_reasons;
要获取航空公司及其各自的平均起飞延误时间列表,只需要基于航空公司代码对航班和航空公司执行 SQL JOIN ,然后使用聚合函数 AVG() 计算按航空公司描述分组的平均 depart_delay:
hive> SELECT
a.description,
AVG(f.depart_delay)
FROM airlines a
JOIN flights f ON a.code = f.airline_code
GROUP BY a.description;
AirTran Airways Corporation: FL 8.035840978593273
Alaska Airlines Inc.: AS 4.746143501305276
American Airlines Inc.: AA 10.085038790027395
American Eagle Airlines Inc.: MQ 11.048787878787879
Delta Air Lines Inc.: DL 8.149843785719728
ExpressJet Airlines Inc.: EV 15.762459814292642
Frontier Airlines Inc.: F9 12.319591084296967
Hawaiian Airlines Inc.: HA 2.872051586628203
JetBlue Airways: B6 12.090553084509766
SkyWest Airlines Inc.: OO 10.086447897294379
Southwest Airlines Co.: WN 14.722817981677437
US Airways Inc.: US 7.363223345079652
United Air Lines Inc.: UA 11.124291343587137
Virgin America: VX 9.98681228106326
Time taken: 22.786 seconds, Fetched: 14 row(s)
如你所见,与在 MapReduce 中执行连接相比,在 Hive 中执行连接可以显著减少编码工作量。更重要的是,我们定义的结构化 Hive 数据模式使我们能够轻松添加或更改查询。让我们来修改查询,返回按飞机分组的平均起飞延误时间:
hive> SELECT
c.description,
AVG(f.depart_delay)
FROM carriers c
JOIN flights f ON c.code = f.carrier_code
GROUP BY c.description;
Aces Airlines (1992 - 2003) 9.98681228106326
AirTran Airways Corporation (1994 - ) 8.035840978593273
Alaska Airlines Inc. (1960 - ) 4.746143501305276
American Airlines Inc. (1960 - ) 10.085038790027395
American Eagle Airlines Inc. (1998 - ) 11.048787878787879
Atlantic Southeast Airlines (1993 - 2011) 15.762459814292642
Delta Air Lines Inc. (1960 - ) 8.149843785719728
ExpressJet Airlines Inc. (2012 - ) 15.762459814292642
Frontier Airlines Inc. (1960 - 1986) 8.035840978593273
Frontier Airlines Inc. (1994 - ) 12.319591084296967
Hawaiian Airlines Inc. (1960 - ) 2.872051586628203
JetBlue Airways (2000 - ) 12.090553084509766
Simmons Airlines (1991 - 1998) 11.048787878787879
SkyWest Airlines Inc. (2003 - ) 10.086447897294379
Southwest Airlines Co. (1979 - ) 14.722817981677437
US Airways Inc. (1997 - ) 7.363223345079652
USAir (1988 - 1997) 7.363223345079652
United Air Lines Inc. (1960 - ) 11.124291343587137
Virgin America (2007 - ) 9.98681228106326
Time taken: 22.76 seconds, Fetched: 19 row(s)
Hive 可能比较适用于这些使用场景:使用的数据集的格式是结构化的、基于表格的;要进行的计算是面向批处理的 OLAP 查询,而不是实时的、面向行的 OLTP 事务。
2. HBase
使用 Hive 可以对存储在 HDFS 中的大型结构化数据集执行基于 SQL 的分析。虽然 Hive 在 Hadoop 中提供了一个熟悉的数据操作范式,但它并不会改变存储和处理模式,而是仍然以批处理方式使用 HDFS 和 MapReduce。
由于 HDFS 被设计为写一次、读多次(WORM)的文件系统,因此它针对顺序读取进行了优化,处理起需要对数据进行频繁或快速的行级更新的用例效率低下。这种数据访问模式通常被称为“随机访问”,需要采用这种实时、低延迟读 / 写访问的应用程序也越来越多。对于需要对数据进行随机、实时读 / 写访问的用例,需要在标准的 MapReduce 和 Hive 之外寻找数据持久层和处理层技术。
对许多数据分析应用程序来说,使用传统的关系方法建模还存在挑战。像 Facebook 的实时分析应用程序 “Insights for Websites” 平台(每秒跟踪超过 20 万个事件)和 StumbleUpon 的实时推荐系统,它们需要同时记录来自许多数据源的大量数据事件。这些类型的实时应用程序需要记录大量基于时间的事件,这些事件往往有许多种可能的结构。数据可能以某个特定值为键(如用户),但值通常表示为任意元数据的集。以“Like”和“Share”两个事件为例,它们需要不同的列值,如下表所示:
| 事件ID | 事件时间戳 | 事件类型 | 用户ID | 文章ID | 评论 | 接收用户ID |
|---|---|---|---|---|---|---|
| 1 | 1370139285 | Like | jjones | 521 | ||
| 2 | 1370139285 | Share | smith | 237 | This is hilarious! | 342 |
| 3 | 1370139285 | Share | emiller | 963 | Great article |
这些类型的数据应用程序有存储稀疏数据的需求。在关系模型中,行是稀疏的,但列不是;也就是说,在将新行插入表后,数据库将为每个列分配存储空间,不管该字段是否有值。然而,在数据被表示为任意字段或稀疏列的集合的应用程序中,每行可能只使用可用列的一部分,这让标准关系模式既浪费资源又别扭。
NoSQL与列式数据库
如今,许多现代应用程序都面临着规模和敏捷的挑战,NoSQL 数据库也因此应运而生。NoSQL 是一个广泛的概念,通常指非关系数据库,涵盖广泛的数据存储模型,包括图形数据库、文档数据库、键 / 值数据存储和列族数据库。
HBase 被归类为列族或列式数据库,模型建立在 Google 的 BigTable 架构之上。这种架构让 HBase 具有如下特性:
- 随机(行级)读 / 写访问;
- 强大的一致性;
- “无模式”或灵活的数据建模。
HBase 处理数据建模的方式引入了无模式的特点,它与关系数据库处理数据建模的方式非常不同。HBase 将数据组织到包含行的表中。在表中,行由唯一的行键标识,行键没有数据类型,而是作为字节数组被存储和处理。行键与关系数据库中主键的概念类似,都被自动编入索引。在 HBase 中,表行按照行键进行排序;因为行键是字节数组,所以字符串、long 的二进制表示,乃至序列化的数据结构等几乎一切都可以作为行键。HBase 将其数据存储为键值对,所有表查找都是通过表的行键或存储记录数据的唯一标识符执行的。
一行中的数据被分组成列族,它们由相关列组成。可以画出一个 HBase 表,让它包含给定人口的人口普查数据,其中每行代表一个人,通过唯一的 ID 行键进行访问;每行包含个人数据和人口信息的列族,个人数据的列族包含姓名列和地址列,人口信息的列族包含出生日期列和性别列。该示例如下图所示:

数据仓库和分析数据库的聚合都是在大量数据上进行的,这些数据可能是稀疏的,即不是所有列值都存在,因而按列存储数据比按行存储的优势更明显。尽管列族非常灵活,但列族在实践中并不完全是无模式的。在可以开始将数据插入特定行和列之前,列族就已经被定义了,因为它们会影响 HBase 存储数据的物理格局。然而,可以根据需要确定和创建组成行的实际列。事实上,每行可以包含不同的列。下图展示了一个有两行的 HBASE 表,第一个行键使用了三列族,第二个行键仅使用一列。

HBase 和基于 BigTable 的列式数据库还有一个有趣的特征,那就是表的单元格或行、列坐标的交集由时间戳进行版本控制;时间戳存储为一个自 1970 年 1 月 1 日 UTC 以来的长整数,用毫秒表示。因此,HBase 也被描述为一个多维的 map,其中时间提供第三维度,如下图所示。时间维度以递减顺序索引,因此从 HBase 读取时会先找到最新的值。单元格的内容可以由 {rowkey, column, timestamp} 元组引用,或者可以按时间范围扫描一系列单元格值。

HBase实时分析
为了概述 HBase,我们定义并使用 HBase shell 设计了一个链接共享跟踪器,用来跟踪一个链接被共享的次数。
①生成模式
在 HBase 中设计模式时,要着重考虑数据模型的列族结构以及它对数据访问模式的影响。定义传统关系数据库的模式主要是要准确表示实体和实体间的关系,以及考虑连接和索引等方面的性能,但成功的 HBase 模式定义往往取决于应用程序的预期用例。此外,由于HBase 不支持连接并且只提供一个索引的行键,所以必须要小心,确保模式可以完全支持所有用例。这通常涉及使用嵌套实体的去规范化和数据重复。幸运的是,由于 HBase 支持在运行时进行动态列定义,所以即便在创建表之后,也依然有很大的灵活性来修改和扩展模式。
②命名空间、表和列族
那么模式的哪些方面值得仔细考虑呢?首先,需要在定义表时声明表名和至少一个列族名;还可以声明自己的可选命名空间作为表的逻辑分组,与关系数据库系统中的数据库类似。 如果没有声明命名空间,HBase 将使用 default 命名空间:
hbase> create 'linkshare', 'link'
0 row(s) in 1.5740 seconds
我们刚刚在 default 命名空间中创建了一个名为 linkshare 的表,它有一个名为 link 的列族。要想在创建表后再更改表,例如更改或添加列族,需要先禁用该表,以便客户端在 alter 操作期间无法访问该表:
hbase> disable 'linkshare'
0 row(s) in 1.1340 seconds
hbase> alter 'linkshare', 'statistics'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.1630 seconds
然后,使用 enable 命令重新启用该表:
hbase> enable 'linkshare'
0 row(s) in 1.1930 seconds
使用 describe 命令验证该表包含两个带有默认配置的预期列族:
hbase> describe 'linkshare'
Table linkshare is ENABLED
COLUMN FAMILIES DESCRIPTION
{NAME => 'link', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '1', TTL => 'FOREVER', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'statistics', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
2 row(s) in 0.1290 seconds
这样就创建了一个有两个列族( link 和 statistics )的 HBase 表( linkshare ),但是这个
表还不包含任何行。在插入行数据之前,需要确定如何设计行键。
③行键
良好的行键设计不仅会影响查询表的方式,也会影响数据访问的性能和复杂性。默认情况下,HBase 根据行键按顺序存储行,因此类似的键存储在同一个 RegionServer 中。虽然这样可以更快地进行扫描范围,但在读 / 写操作期间,它也可能导致个别服务器的负载不均匀(称为“RegionServer hotspotting”)。因此,除了要实现我们的数据访问用例之外,还需要考虑各个 region 之间的行键分布。对于当前示例,我们使用唯一的反向链接 URL 作为行键。
④使用 put 插入数据
现在这个表可以存储数据了——我们想在 linkshare 应用程序中存储关于链接的描述性数据(例如其标题),同时维护一个跟踪链接共享次数的频率计数器。我们可以在指定的表 / 行 / 列和可选时间戳坐标的单元格中插入或 put 一个值。要将一个单元格值放入 linkshare 表、行键为 org.hbase.www 的行、 link 列族下的当前时间戳的title 列,可以执行以下操作:
hbase> put 'linkshare', 'org.hbase.www', 'link:title', 'Apache HBase'
hbase> put 'linkshare', 'org.hadoop.www', 'link:title', 'Apache Hadoop'
hbase> put 'linkshare', 'com.oreilly.www', 'link:title', 'O\'Reilly.com'
put 操作在插入单个单元格的值时非常有用,而对于增加频率计数器的值,HBase 提供了一种将列作为计数器来处理的特殊机制。否则,在负载较重的情况下,我们可能会遇到针对这些行的激烈竞争,因为我们需要锁定行,读取值,增加值,写回,最后再解锁该行,让其他写入过程能够访问该单元格。
使用 incr 命令,而不是 put 来增加计数器的值:
hbase> incr 'linkshare', 'org.hbase.www', 'statistics:share', 1
(COUNTER VALUE is now 1)
hbase> incr 'linkshare', 'org.hbase.www', 'statistics:like', 1
(COUNTER VALUE is now 1)
最后一个被传递的选项是增量值,在这个例子中为 1。增加计数器的值将返回更新后的计数器值,但你也可以随时使用 get_counter 命令访问计数器的当前值,指定表名、行键和列即可:
hbase> incr 'linkshare', 'org.hbase.www', 'statistics:share', 1
(COUNTER VALUE is now 2)
hbase> get_counter 'linkshare', 'org.hbase.www', 'statistics:share', 'dummy'
COUNTER VALUE = 2
get_counter 方法用于解码计数器的字节数组值,并返回整数值。不幸的是,最新版本的 HBase 在获取计数器值的 shell 命令中引入了一个 bug——该命令的第 4 个参数没有作用。因此,需要传递哑值作为第 4 个参数:
hbase> get_counter 'linkshare', 'org.hbase.www', 'statistics:share', 'dummy'
COUNTER VALUE = 2
HBase 提供了从表中检索数据的两种通用方法:
- get 命令通过行键执行查找,从而检索特定行的属性;
- scan 命令接受一组过滤器规范,并根据指定的规范进行多行迭代 。
⑤获取行或单元格值
最简单的形式是, get 命令接受表名与行键,返回行中所有列的最新版本的时间戳和单元格值:
hbase> get 'linkshare', 'org.hbase.www'
COLUMN CELL
link:title timestamp=1422145743298, value=Apache HBase
statistics:like timestamp=1422153344211, value=\x00\x00\x00\x00\x00\x00\x00\x1F
statistics:share timestamp=1422153337498, value=\x00\x00\x00\x00\x00\x00\x00\x02
3 row(s) in 0.0310 seconds
请注意, statistics:share 列返回它的字节数组表示的值,并将每个字节打印为十六进制值。要显示计数器值的整数表示,可以使用上一节中提到的 get_counter 命令。get 命令还接受可选的参数字典,用来指定要检索的单元格值的列、时间戳、时间范围(timerange)和版本。例如,可以指定感兴趣的列:
hbase> get 'linkshare', 'org.hbase.www', {COLUMN => 'link:title'}
hbase> get 'linkshare', 'org.hbase.www', {COLUMN => ['link:title', 'statistics:share']}
还有一种在 get 中指定列参数的快捷方式,就是在行键之后加上以逗号分隔的列名称:
hbase> get 'linkshare', 'org.hbase.www', 'link:title'
hbase> get 'linkshare', 'org.hbase.www', 'link:title', 'statistics:share'
hbase> get 'linkshare', 'org.hbase.www', ['link:title', 'statistics:share']
为了指定感兴趣的值的时间范围,传入一个有开始时间戳和结束时间戳(以毫秒为单位)的 TIMERANGE 参数:
hbase> get 'linkshare', 'org.hbase.www', {TIMERANGE => [1399887705673, 1400133976734]}
如果希望获取一定数量的先前版本的单元格值,而不是显式的时间戳范围,可以指定感兴趣的列,并使用 VERSIONS 参数指定要检索的版本数:
hbase> get 'linkshare', 'org.hbase.www', {COLUMN => 'statistics:share', VERSIONS => 2}
虽然这种类型的范围查询似乎对递增为 1 的计数器值意义不大,但它为我们提供了确定分享计数器递增速率的方法,可以用它来确定链接是否为病毒。此外,这些类型的范围过滤器在执行“即时”查询时尤其有用,例如检查在一定时间范围内的指标。
⑥扫描行
scan 操作类似于数据库游标或迭代器,利用底层顺序存储机制,根据 scanner 规格迭代行数据。可以使用 scan 扫描整个 HBase 表或指定范围的行。scan 的用法和 get 类似,它也接受 COLUMN 、 TIMESTAMP 、 TIMERANGE 和 FILTER 参数。但是,你不能指定单个行键,而是要指定一个可选的 STARTROW 和 / 或 STOPROW 参数,将扫描限制在特定的行范围内。如果不提供 STARTROW 和 STOPROW , scan 操作将扫描整个表。
事实上,你可以将表名称作为参数调用 scan ,从而显示表的所有内容:
hbase> scan 'linkshare'
ROW COLUMN+CELL
com.oreilly.www column=link:title, timestamp=1422153270279, value=O'Reilly.com
org.hadoop.www column=link:title, timestamp=1422153262507, value=Apache Hadoop
org.hbase.www column=link:title, timestamp=1422145743298, value=Apache HBase
org.hbase.www column=statistics:like, timestamp=1422153344211, value=\x00\x00\x00\x00\x00\x00\x00\x1F
org.hbase.www column=statistics:share, timestamp=1422153337498, value=\x00\x00\x00\x00\x00\x00\x00\x02
3 row(s) in 0.0290 seconds
请记住,HBase 中的行以字典顺序存储。例如,1~100 将按如下顺序排序:
1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,...,9,91,92,93,94,95,96,97,98,99
扫描 org.hbase.www 行的 link:title 列(因为未指定 ENDROW,所以其与 STARTROW 相同):
hbase> scan 'linkshare', {COLUMNS => ['link:title'], STARTROW => 'org.hbase.www'}
ROW COLUMN+CELL
org.hbase.www column=link:title, timestamp=1453184861236, value=Apache HBase
1 row(s) in 0.0250 seconds
但是 STARTROW 和 ENDROW 的值不需要行键的完全匹配。它将匹配大于等于给定起始行且小于等于结束行的第一个行键;因为这些参数是包含端点的(inclusive),所以如果 ENDROW 的值与 STARTROW 相同,就不需要指定 ENDROW 了:
hbase> scan 'linkshare', {COLUMNS => ['link:title'], STARTROW => 'org'}
ROW COLUMN+CELL
org.hadoop.www column=link:title, timestamp=1422153262507, value=Apache Hadoop
org.hbase.www column=link:title, timestamp=1422145743298, value=Apache HBase
2 row(s) in 0.0210 seconds
⑦过滤器
HBase 提供了一些过滤器类,可以进一步过滤 get 或 scan 操作返回的行数据。这些过滤器可以提供更有效的手段来限制 HBase 返回的行数据,并将行过滤操作的负担从客户端转移到服务器。HBase 可用的一些过滤器包括:
- RowFilter:基于行键值进行数据过滤。
- ColumnRangeFilter:支持高效的行内扫描,可用于获取非常宽的行的部分列(也就是说,当一行有 100 万列时,你只想查看列 bbbb-bbdd)。
- SingleColumnValueFilter:基于列值过滤单元格。
- RegexStringComparator:用于检验给定正则表达式是否与列中的单元格值匹配。
HBase 的 Java API 提供了一个 Filter 接口、一个 FilterBase 抽象类,以及一些专用的 Filter 子类。也可以通过继承 FilterBase 抽象类并实现关键抽象方法来创建自定义过滤器。
最好在 Java 程序中使用 HBase API 来应用 HBase 过滤器,因为它们通常需要导入多个依
赖的过滤器和比较器类,但是我们可以在 shell 中演示一个过滤器的简单示例。
首先,导入必需的类,包括用于将列族、列和值转换为字节的 org.apache.hadoop.hbase.
util.Bytes 、过滤器和比较器类:
hbase> import org.apache.hadoop.hbase.util.Bytes
hbase> import org.apache.hadoop.hbase.filter.SingleColumnValueFilter
hbase> import org.apache.hadoop.hbase.filter.BinaryComparator
hbase> import org.apache.hadoop.hbase.filter.CompareFilter
接下来,创建一个过滤器,筛选出 statistics:like 列值≥ 10 的行:
hbase> likeFilter = SingleColumnValueFilter.new(Bytes.toBytes('statistics'), Bytes.toBytes('like'), CompareFilter::CompareOp.valueOf('GREATER_OR_EQUAL'), BinaryComparator.new(Bytes.toBytes(10)))
因为不是所有行的该列都有值,所以需要设置一个标志,告诉过滤器跳过该列没有值的行:
hbase> likeFilter.setFilterIfMissing(true)
此时就可以使用配置好的过滤器运行 scan 操作了:
hbase> scan 'linkshare', { FILTER => likeFilter }
ROW COLUMN+CELL
org.hbase.www column=link:title, timestamp=1422145743298, value=Apache HBase
org.hbase.www column=statistics:like, timestamp=1422153344211, value=\x00\x00\x00\x00\x00\x00\x00\x1F
org.hbase.www column=statistics:share, timestamp=1422153337498, value=\x00\x00\x00\x00\x00\x00\x00\x02
1 row(s) in 0.0470 seconds
这段代码应该返回 statistics:like 的列值≥ 10 的所有行;本示例可能包括行键 com.oreilly.www 。
⑧ HBase 的拓展阅读
HBase 在存储大量结构灵活的流式数据时非常有用,它还能一次查询该数据的一小块,同时确保:
- 数据“完整”(如销售或财务数据);
- 数据会随时间变化;
- 可以查询和更新单行和部分行和列。
HBase 并不是 RDBMS、HDFS 或者 Hive 的替代品,而是提供了一种方法,在利用 Hadoop 的数据可扩展性的同时,实现对数据的随机访问。HBase 可以与传统的 SQL 或 Hive 结合,以支持需要的查询快照、范围和聚合数据。
十、数据采集
这一章将阐明对能将数据采集到 HDFS 的采集工具的需求,研究如何使用 Sqoop 采集结构化数据,以及如何使用 Flume 采集非结构化数据。
Hadoop 最突出的一个优点在于它天生就是无模式的。只要实现 Hadoop 的 Writable 接口或 DBWritable 接口并编写正确解析数据的 MapReduce 代码,Hadoop 就可以使用任何来源、任何类型或任何格式的数据,不管其结构如何(或是否缺少结构)。然而,如果输入数据驻留在关系数据库中且已结构化,使用数据已知的模式可以更方便地将数据导入 Hadoop;这种方法也比将 CSV 上传到 HDFS 并手动解析更高效。
Sqoop 用于在关系数据库管理系统和 Hadoop 之间传输数据。它依靠 RDBMS 为要导入的数据提供模式描述,让大部分数据转换过程自动化。对于将关系数据库作为主要或中间数据存储的数据基础设施来说,Sqoop 是分析流程中一个非常有用的环节。虽然用 Sqoop 将已经驻留在关系数据库中的数据大批量加载到 Hadoop 中并无不妥,但许多新的应用程序和系统涉及快速流动的数据,如应用程序日志、GPS 追踪、社交媒体动态和传感器数据。我们需要将这些数据直接加载到 HDFS 中,从而在 Hadoop 中进行处理。为了应对高吞吐量并处理由这些系统生成的基于事件的数据,就需要支持从多个源持续采集数据到 Hadoop 中。
Apache Flume 旨在从大量不同来源高效地采集、聚合和移动大量日志数据到集中的数据存储中。虽然 Flume 通常用于将流式日志数据引入 Hadoop(通常是 HDFS 或 HBase),但实际上 Flume 的数据源非常灵活,可以通过自定义向它兼容的任何消费者传输各种类型的事件数据,包括网络流量数据、社交媒体生成的数据和传感器数据。我们将介绍如何使用 Flume 从自定义日志中采集流式数据并将其传输到 Hadoop。
1. 使用Sqoop导入关系数据
Sqoop(SQL-to-Hadoop)是关系数据库导入 / 导出工具,Sqoop 的设计初衷是在关系数据库(例如 MySQL 或 Oracle)和 Hadoop 数据存储(例如 HDFS、Hive 和 HBase)之间传输数据。它通过直接从 RDBMS 读取模式信息,自动执行大部分数据传输过程,然后使用 MapReduce 将数据导入和导出 Hadoop。 Sqoop 在将数据维持在生产状态的同时,将其复制到 Hadoop 中,从而进行进一步分析,避免修改生产数据库。我们将介绍几种使用 Sqoop 将数据从 MySQL 数据库导入 Hadoop 数据存储(例如 HDFS、Hive 和 HBase)的方法。
从MySQL导入HDFS
从关系数据库(如 MySQL)导入数据时,Sqoop 会从源数据库读取导入数据所需的元数据,然后提交一个仅有 map 的 Hadoop 作业,根据上一步捕获的元数据,传输实际的表数据。该作业会生成一组序列化文件,比如以符号分隔的文本文件、二进制格式文件,或包含导入的表或数据集副本的 SequenceFile 文件。默认情况下,文件以逗号分隔,并保存在 HDFS 目录中,目录名称与源表名称相对应。我们将使用这些默认设置将数据从 MySQL 导入 HDFS。
首先创建一个名为 energydata 的数据库和一个名为 average_price_by_state 的表:
~$ mysql -u root -p ***
mysql> CREATE DATABASE energydata;
Query OK, 1 row affected (0.00 sec)
-- 授予特权的格式:GRANT ALL PRIVILEGES ON database_name.* TO 'username'@'localhost';
mysql> GRANT ALL PRIVILEGES ON energydata.* TO '%'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON energydata.* TO ''@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> USE energydata;
mysql> CREATE TABLE average_price_by_state(
year INT NOT NULL,
state VARCHAR(5) NOT NULL,
sector VARCHAR(255),
residential DECIMAL(10,2),
commercial DECIMAL(10,2),
industrial DECIMAL(10,2),
transportation DECIMAL(10,2),
other DECIMAL(10,2),
total DECIMAL(10,2)
);
Query OK, 0 rows affected (0.02 sec)
mysql> quit;
加载到 average_price_by_state 表中的数据是 1990 年至 2012 年期间各年各州和各供应商每千瓦时(KwH)的平均电价。将对应的数据文件加载到刚刚创建的 MySQL 表中(只是加入 MySQL 表中,不是从表中读入HDFS):
~$ mysql -h localhost -u root -p energydata --local-infile=1
mysql> LOAD DATA LOCAL INFILE '/home/hadoop/hadoop-fundamentals/data/avgprice_kwh_state.csv'
INTO TABLE average_price_by_state
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n' IGNORE 1 LINES;
Query OK, 3272 rows affected, 6 warnings (0.03 sec)
Records: 3272 Deleted: 0 Skipped: 0 Warnings: 6
mysql> quit;
在运行 Sqoop 的 import 命令之前,使用 jps 命令验证 HDFS 和 YARN 是否已启动:
~$ sudo su hadoop
hadoop@ubuntu:~$ jps
4051 NodeManager
31134 Jps
3523 DataNode
3709 SecondaryNameNode
3375 NameNode
3921 ResourceManager
此时,使用 import 命令将表 average_price_by_state 中的数据导入 HDFS。可以分别通过–connect 选项、 --username 选项和 --table 选项来指定源数据库的连接字符串、用户名和表名。将可选的 -m 标志设置为 1,表示该作业使用单个 map 任务:
/srv/sqoop$ sqoop import --connect jdbc:mysql://localhost:3306/energydata
--username root --table average_price_by_state -m 1
15/01/20 22:47:35 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
15/01/20 22:47:35 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
15/01/20 22:47:35 INFO tool.CodeGenTool: Beginning code generation
15/01/20 22:47:36 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `average_price_by_state` AS t LIMIT 1
(output truncated)
15/01/25 22:47:53 INFO mapreduce.ImportJobBase: Transferred 200.4287 KB in
15.3718 seconds (13.0387 KB/sec)
15/01/25 22:47:53 INFO mapreduce.ImportJobBase: Retrieved 3272 records.
在本例中,因为表不包含主键,而主键是分割和合并多个 map 任务所必需的,所以需要指定 import 命令使用单个 map 任务。因为指定了导入任务使用一个 map 任务,所以 HDFS 中只有一个文件:
/srv/sqoop$ hadoop fs -head average_price_by_state/part-m-00000 | head
2012,AK,Total Electric Industry,17.88,14.93,16.82,0.00,null,16.33
2012,AL,Total Electric Industry,11.40,10.63,6.22,0.00,null,9.18
2012,AR,Total Electric Industry,9.30,7.71,5.77,11.23,null,7.62
2012,AZ,Total Electric Industry,11.29,9.53,6.53,0.00,null,9.81
2012,CA,Total Electric Industry,15.34,13.41,10.49,7.17,null,13.53
2012,CO,Total Electric Industry,11.46,9.39,6.95,9.69,null,9.39
2012,CT,Total Electric Industry,17.34,14.65,12.67,9.69,null,15.54
2012,DC,Total Electric Industry,12.28,12.02,5.46,9.01,null,11.85
2012,DE,Total Electric Industry,13.58,10.13,8.36,0.00,null,11.06
2012,FL,Total Electric Industry,11.42,9.66,8.04,8.45,null,10.44
我们现在已经成功将数据从 MySQL 导入 HDFS 了!至此,就可以对导入的数据进行后续的 MapReduce 处理,或将数据加载到另一个 Hadoop 数据源中(例如 Hive、HBase 或 HCatalog)。
从MySQL导入Hive
因为关系数据库中的数据已经是结构化的,所以将这些数据导入 Hive 中与源数据库类似的模式也大有用处,尤其当你打算对数据运行关系查询时。Sqoop 提供了两种方法:一种是先将数据导出到 HDFS,再在 Hive shell 中使用 LOAD DATA HQL 命令将其加载到 Hive 中;另一种是使用 Sqoop 直接创建表,并将关系数据库数据加载到相应的 Hive 表中。
使用 import 命令,Sqoop 可以根据源数据库定义的模式生成 Hive 表,并将源数据库表中的数据加载进来。但由于 Sqoop 实际上仍然使用 MapReduce 来实现数据加载操作,因此在运行导入工具之前,必须删除所有与输出名称相同的已有数据目录:
/srv/sqoop$ hadoop fs –rm -r /user/hadoop/average_price_by_state
然后运行 Sqoop 的 import 命令,将数据库的 JDBC 连接字符串、表名、字段分隔符、行终止符和 null 字符串值传递给它:
/srv/sqoop$ sqoop import --connect jdbc:mysql://localhost:3306/energydata
--username root --table average_price_by_state
--hive-import --fields-terminated-by ','
--lines-terminated-by '\n' --null-string 'null' -m 1
(output truncated)
15/01/20 00:14:37 INFO hive.HiveImport: Table default.average_price_by_state stats:
[numFiles=2, numRows=0, totalSize=205239, rawDataSize=0]
15/01/20 00:14:37 INFO hive.HiveImport: OK
15/01/20 00:14:37 INFO hive.HiveImport: Time taken: 0.435 seconds
15/01/20 00:14:37 INFO hive.HiveImport: Hive import complete.
15/01/20 00:14:37 INFO hive.HiveImport: Export directory is empty, removing it.
Hive 会将 double 类型的列转换为 float 类型,并去掉所有 NOT NULL 字段约束。除此之外,Hive 表的结构与 MySQL 的 average_price_by_state 表的初始定义一模一样,名字也一样。
在本地模式下,Hive 将在它运行的文件系统中创建一个 metastore_db 目录;在上一个示例中,metastore_db 是在 SQOOP_HOME(/srv/sqoop)下创建的。打开 Hive shell 并验证表 average_price_by_state 是否已被创建:
/srv/sqoop$ hive
hive> DESC average_price_by_state;
OK
year int
state string
sector string
residential double
commercial double
industrial double
transportation double
other double
total double
Time taken: 0.858 seconds, Fetched: 9 row(s)
你还可以通过运行 COUNT 查询来验证是否已导入了 3272 行;由于该数据集相对较小,因此也可以通过运行 SELECT * FROM average_price_by_state 来验证数据。将数据和模式导入Hive 之后,就可以通过 Hive 命令行接口或其他 Hive 接口对数据进行后续分析了。
从MySQL导入HBase
HBase 旨在为需要实时访问行级数据的大量并发客户端处理大量数据。尽管在大多数小规模和中等规模的数据应用程序中,关系数据库也能很好地满足这一要求,但如果应用程序需要扩展性更强的存储解决方案,我们就得考虑将一些大规模和重负载的数据组件转移到分布式数据库,比如 HBase。
Sqoop 的导入工具能将数据从关系数据库导入 HBase。与 Hive 一样,有两种导入方法:一种是先导入 HDFS,然后使用 HBase CLI 或 API 将数据加载到 HBase 表中;另一种是使用--hbase-table选项指示 Sqoop 直接将数据导入 HBase 表。在这个示例中,要转移到 HBase 的数据是一个博客统计数据表,其中每条记录都包含一个主键(由竖线分隔的 IP 地址和年份)和每个月对应的列(每一列表示该年该 IP 在该月的访问数)。
先将 CSV 文件加载到 MySQL 表中:
~$ mysql –u root -p ***
mysql> CREATE DATABASE logdata;
mysql> GRANT ALL PRIVILEGES ON logdata.* TO '%'@'localhost';
mysql> GRANT ALL PRIVILEGES ON logdata.* TO ''@'localhost';
mysql> USE logdata;
mysql> CREATE TABLE weblogs (ipyear varchar(255) NOT NULL PRIMARY KEY,
january int(11) DEFAULT NULL,
february int(11) DEFAULT NULL,
march int(11) DEFAULT NULL,
april int(11) DEFAULT NULL,
may int(11) DEFAULT NULL,
june int(11) DEFAULT NULL,
july int(11) DEFAULT NULL,
august int(11) DEFAULT NULL,
september int(11) DEFAULT NULL,
october int(11) DEFAULT NULL,
november int(11) DEFAULT NULL,
december int(11) DEFAULT NULL);
mysql> quit;
mysql> LOAD DATA LOCAL INFILE '/home/hadoop/hadoop-fundamentals/data/weblogs.csv'
INTO TABLE weblogs FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n' IGNORE 1 LINES;
Query OK, 27300 rows affected (0.20 sec)
Records: 27300 Deleted: 0 Skipped: 0 Warnings: 0
mysql> quit;
与之前一样,需要验证 Hadoop 和 HBase 守护进程是否正在运行:
~$ cd $HBASE_HOME
/srv/hbase$ bin/start-hbase.sh
然后,运行 Sqoop 的 import 命令,将数据库的 JDBC 连接字符串、表名、HBase 表名、列族名称和行键名称传递给它:
sqoop import --connect jdbc:mysql://localhost:3306/logdata
--table weblogs --hbase-table weblogs --column-family traffic
--hbase-row-key ipyear --hbase-create-table -m 1
(output truncated)
15/01/20 00:33:01 INFO mapreduce.ImportJobBase: Transferred 0 bytes in 19.0716 seconds (0 bytes/sec)
15/01/20 00:33:01 INFO mapreduce.ImportJobBase: Retrieved 27300 records.
导入的 MapReduce 作业完成后,你应该会看到控制台消息INFO mapreduce.ImportJobBase: Retrieved 27300 records。可以在 HBase shell 中使用 list 和 scan 命令验证 HBase 表和行是否已被成功导入:
/srv/sqoop$ cd $HBASE_HOME
/srv/hbase$ bin/hbase shell
hbase(main):001:0> list
TABLE
linkshare
weblogs
2 row(s) in 1.2900 seconds
=> ["linkshare", "weblogs"]
hbase(main):002:0> scan 'weblogs', {'LIMIT' => 50}
(output truncated)
我们已经使用 Sqoop 的导入工具成功将关系数据从 MySQL 导入 HDFS、Hive 和 HBase。实际上,这种工具生成了一个 Java 类,它封装了导入表的行模式。该类在导入过程中被 Sqoop 使用,但也可用于后续的 MapReduce 数据处理。因此,除了自动交换 Hadoop 和关系数据库的数据之外,Sqoop 还有助于快速开发与 Hadoop 兼容的其他数据源的处理流水线。
2. 使用Flume获取流式数据
Flume 的设计初衷是从多个数据流中采集和获取大量数据到 Hadoop。Flume 的一个非常常见的用例是采集日志数据,例如采集 Web 服务器上由多个应用服务器发射的日志数据,将其聚合在 HDFS 中,供后续搜索或分析使用。但是,Flume 并不仅限于简单地消费和获取日志数据源,它还可以被自定义为从任何事件源传输大量的事件数据。在这两种情况下,Flume 使我们能够在数据写入 Hadoop 后增量且持续地获取流式数据,而不用编写自定义的客户端应用程序将数据批量加载到 HDFS、HBase 或其他 Hadoop 数据槽中。Flume 提供了一种统一而灵活的方法,将数据从大量不同且快速流动的数据流推送到 Hadoop。
Flume 的灵活性源自其固有的可扩展式数据流架构。除灵活性以外,Flume 旨在通过其分布式架构来保持容错性和可扩展性。尽管一般推荐使用默认的“端到端”可靠性模式(保证所有接收的事件最终都能发送出去)设置 ,但 Flume 还是提供了多种冗余和恢复机制。我们介绍了 Flume 的总体特征,但为了了解如何构建 Flume 数据流,我们需要查看它的基本构建单元:Flume 代理。
Flume数据流
Flume 将从起点到目的地的数据采集路径表示为数据流。在数据流中,一个数据单元(又称事件,例如一条日志)从源流经一系列跃点(hop)到达下一个目的地。就连 Flume 数据流最简单的实体——Flume 代理,也体现了数据流这一概念。Flume 代理(实际上是一个 JVM 进程)是 Flume 数据流中的一个单元,一旦外部源发出事件,事件就通过代理传播。代理由三个可配置的组件构成:源、通道和数据槽,如下图所示:

Flume 源用于监听并消费来自一个或多个外部数据源(不要与 Flume 源混淆)的事件,通过为每个数据源设置名称、类型和额外的可选参数进行配置。例如,通过运行 tail -f etc/httpd/logs/access_log命令,可以将 Flume 代理的源配置为接受来自 Apache 访问日志的事件。这种类型的源称为 exec 源,因为它需要 Flume 执行 Unix 命令来检索事件。
当代理消费一个事件时,Flume 源将其写入通道。该通道作为存储队列,存储和缓冲事件,直到它们可以被读取。事件以事务性方式写入通道,这意味着直到事件被消费并且相应的事务被明确地关闭,通道都将把所有事件保存在队列中。因此,即便一个代理停止,Flume 也能够保持数据事件的持久性。
Flume 数据槽最终从通道中读取和移除事件,并将其转发到下一个跃点或最终目的地。因此,可以将数据槽配置为将其输出作为流式数据源写入另一个 Flume 代理或数据存储(例如 HDFS 或 HBase)。Flume 支持多种内置数据槽,在 Apache Flume User Guide 中均有记录。
通过使用这种源 - 通道 - 数据槽模式,可以轻松构建一个简单的 Flume 单代理数据流,从 Apache 访问日志中消费事件,并将日志事件写入 HDFS,如下图所示:
但是由于 Flume 代理的适配性很强,它甚至可以被配置为多个源、通道和数据槽,因此,可以通过将多个 Flume 代理链接在一起来构建多代理数据流,如下图所示:
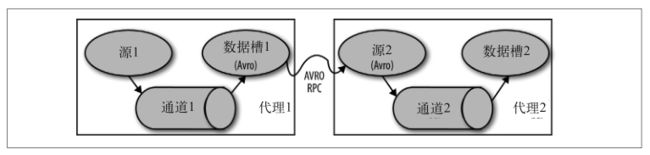
尽管在解决流式数据处理架构时,Flume 有一些处理常见场景的数据流拓扑模式,但是将 Flume 代理组织成复杂数据流的方式绝不仅限于此。以日志采集中的一个常见场景为例,生成日志的大量客户端将事件写入多个 Flume 代理,这被称为“第一层”代理,因为它们消费外部数据源层的数据。如果要将这些事件写入 HDFS,可以将每个第一层代理的数据槽设置为写入 HDFS;但在第一层扩展时,这可能会引起一些问题。由于几个不同的代理分别写入 HDFS,因此该数据流将无法处理周期性暴增的存储系统数据写入,从而可能引发负载和延迟的峰值。
通过添加第二层代理,可以汇总和缓冲来自第一层的事件,从而更好地将第一层代理与数据槽(HDFS)隔离。因此,第二层代理一方面可以聚合接收到的事件,降低调试难度;另一方面,它又可以控制对存储系统的写入速率,使得整个数据流可以吸收更长、更大的负载峰值。这种拓扑模式称为 fan-in 流,如下图所示。随着产生数据的服务器的增加,第一层代理、后续代理以及层的数量通常也会相应地增加。
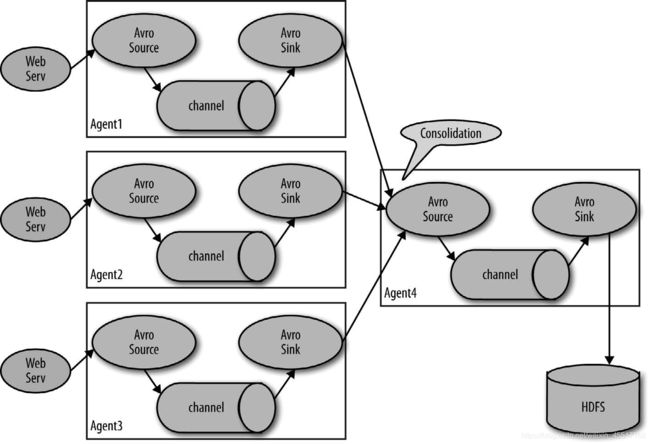
使用Flume获取产品印象数据
能获取 Apache 访问日志之类的标准日志数据或 Twitter firehose 流式数据的 Flume 单代理数据流比比皆是,但 Flume 其实也非常适用于获取自定义数据流,例如自定义应用程序生成的实时分析数据。
本小节的例子将使用 Flume 来消费某虚构在线商店生成的流式用户交互数据。许多电子商务公司都在找寻测量其在线商店微转化率的方法,追踪在线营销的效果。以下指标可用于衡量在线商店的整体效能:
- 点击率
产品印象转化为点击(或点击链接 / 图片浏览产品详情页面的操作)的次数。 - 加入购物车率
点击转化为加入购物车的次数。 - 购物车购买率
加入购物车转化为购买行为的次数。 - 购买率
产品印象最终转化为购买行为的百分比。
通常,要获取这些指标,就需要捕获细粒度的产品印象,也就是在电子商务 Web 应用程序中插桩,记录访问者与产品的每个交互。这些交互包括查看产品链接、点击进入产品详情页面、向 / 从购物车添加 / 移除产品以及购买产品。在写入数据后,以一定的间隔提取和分析数据,从而生成报表、调整产品特征、驱动个性化体验等。
我们将模拟一个电子商务印象日志,以如下 JSON 格式记录用户与产品的交互信息:
{
"sku": "T9921-5",
"timestamp": 1453167527737,
"cid": "51761",
"action": "add_cart",
"ip": "226.43.51.25"
}
其中,动作类型包括 view、click、add_cart、remove_cart 和 purchase。
本示例模拟了一个简单的 Flume 双代理数据流,我们在其中建立了一个客户端代理,它在Web 服务器上运行,获取日志数据文件中的记录并将这些事件发送到一个 Avro 数据槽。Avro 是一种轻量级的 RPC 协议,也提供了简单的数据序列化功能。它使我们能轻松地设置 RPC 协议,将客户端代理的数据槽中的数据发送到采集代理的源。然后,采集代理将这些事件写入 HDFS。最终的流程如下图所示:
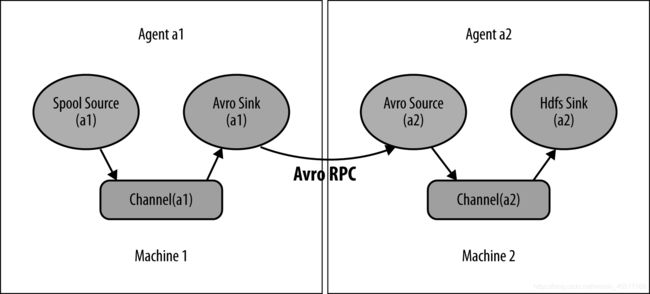
设置 Flume 代理从编写配置文件开始。如前所述,所有 Flume 代理都由源、通道和一个或
多个数据槽组成。首先将客户端代理的源配置为印象日志的位置:
# 定义spooling目录源
client.sources=r1
client.sources.r1.channels=ch1
client.sources.r1.type=spooldir
client.sources.r1.spoolDir=/tmp/impressions
将源名称设置为 r1 ,稍后将使用它来引用和设置源的其他属性。然后,为源指定一个已命名的通道,本例将其命名为 ch1 。另外,将 r1 的源配置为 spooldir 类型,用于从磁盘指定的“假脱机”目录中获取数据。这个源将会监视指定目录中的新文件,当新文件出现时,从中解析出事件。在给定的文件被完全读入通道之后,它会被重命名,表明已被 Flume 完全获取。
接着,来配置客户端代理的通道,它会缓冲从源到数据槽的数据。设置一个名为 ch1 的通道,并将其类型设置为 FILE 。默认情况下,文件通道通过将数据写入用户主目录下名为 checkpoint 和 data 的目录下的文件来缓存数据。可以通过配置 checkpointDir 和 dataDirs 值来覆盖特定通道的这些文件路径:
# 定义一个文件通道
client.channels=ch1
client.channels.ch1.type=FILE
最后,需要为客户端代理配置数据槽。在这个示例中,客户端代理将其数据写入 Avro 数据槽。我们将其命名为 k1 ,并将其配置为从 ch1 通道获取数据。Avro 数据槽需要一个主机名和端口:
# 定义一个Avro数据槽
client.sinks=k1
client.sinks.k1.type=avro
client.sinks.k1.hostname=localhost
client.sinks.k1.port=4141
client.sinks.k1.channel=ch1
接下来,配置采集代理,它从之前配置的 Avro 源消费事件,并将这些事件写入 HDFS。源、通道和数据槽的配置如下所示:
#定义一个Avro源
collector.sources=r1
collector.sources.r1.type=avro
collector.sources.r1.bind=0.0.0.0
collector.sources.r1.port=4141
collector.sources.r1.channels=ch1
#定义一个文件通道,为了可靠性,使用多个磁盘
collector.channels=ch1
collector.channels.ch1.type=FILE
collector.channels.ch1.checkpointDir=/tmp/flume/checkpoint
collector.channels.ch1.dataDirs=/tmp/flume/data
#定义HDFS数据槽,将事件持久化为文本
collector.sinks=k1
collector.sinks.k1.type=hdfs
collector.sinks.k1.channel=ch1
请注意,只要类型、绑定主机和端口的配置一致,源名称不需要与客户端代理的数据槽名称相匹配。我们也为此代理配置了一个文件通道,但是覆盖了检查点和数据目录,避免与客户端代理的通道发生冲突;此外,还声明了一个名为 k1 、类型为 hdfs 的数据槽,它从为此代理配置的 ch1 通道消费事件。
HDFS 数据槽需要一个 path 配置,用于指定代理写入数据的 HDFS 位置。此外,我们还指定了其他一些可选配置参数,比如预期文件名的前缀和后缀、文件格式,以及每一批次写入的最大事件数:
# HDFS数据槽配置
collector.sinks.k1.hdfs.path=/user/hadoop/impressions
collector.sinks.k1.hdfs.filePrefix=impressions
collector.sinks.k1.hdfs.fileSuffix=.log
collector.sinks.k1.hdfs.fileType=DataStream
collector.sinks.k1.hdfs.writeFormat=Text
collector.sinks.k1.hdfs.batchSize=1000
客户端和采集代理都已完全配置好,可以运行 Flume 代理来执行完整的数据流了。在终端打开三个选项卡。在第一个选项卡中,导航到 Flume 配置文件并运行如下命令:
$ flume-ng agent -n collector --conf . -f collector.conf
采集代理启动,等待从客户端代理接收事件。现在,在第二个选项卡中启动客户端代理:
$ flume-ng agent -n client --conf . -f client.conf
一旦客户端代理完全处理了日志数据文件 impressions.log,你就会看到一条控制台消息,表明 impressions.log 文件已被完全处理并重命名为 impressions.log.COMPLETED:
INFO avro.ReliableSpoolingFileEventReader: Preparing to move file
/tmp/impressions/impressions.log to
/tmp/impressions/impressions.log.COMPLETED
然后检查第一个选项卡,验证采集代理是否已处理所有事件并将其写入了 HDFS。确认日志已写入配置指定的 HDFS 源目录:
$ hadoop fs -ls /user/hadoop/impressions/
$ hadoop fs -cat /user/hadoop/impressions/impressions.1453085307781.log | head
文件前缀为 impressions,后缀为 .log 扩展名,但中间的时间戳会随你运行 Flume 数据流的日期和时间而变。虽然这个双代理数据流演示的 Flume 多代理数据流非常简单,但是 Flume 为许多其他类型和配置的源、通道和数据槽提供了丰富的支持,以实现更复杂和可扩展的数据流。
十一、使用高级API进行分析
这一章我们将探讨用于分析的高级 API:Apache Pig 和 Spark DataFrame。
前面我们解释了为什么要放弃原生 MapReduce,转而使用 Hive 这样的较高级语言的部分原因——因为前者实现起相对简单的操作也可能十分困难、笨拙和冗长。大多数严谨的 Hadoop 应用程序的开发周期都很长,需要编写多个 mapper 和 reducer 并将它们链接起来,形成复杂的作业链或数据处理工作流。
此外,由于 MapReduce 旨在以批处理方式运行,因此它在运行需要响应反馈的迭代处理(包括许多机器学习算法)和交互式数据挖掘的数据分析时,会有许多限制。原生 MapReduce 在开发效率、维护和运行时表现出的性能方面的不足引发了对 Hadoop 更高层次的抽象,甚至是扩展 MapReduce 范式的新处理引擎的需求。
本章将介绍 Pig,它是 MapReduce 的一种编程抽象,有助于构建基于 MapReduce 的数据流;此外,还将介绍一些扩展核心 RDD API 的新 Spark API,让开发人员能使用他们熟悉的基于 SQL 的概念和语法,降低计算结构化数据的难度。这些项目将提供表达力强大的 API,使分析人员仅凭几行代码就能构建复杂的应用程序,从而提高 MapReduce 和 Spark 应用程序的开发效率。
1. Pig
和 Hive 一样,Pig 也是一种 MapReduce 抽象。它允许用户用更高级的语言去表达数据处理和分析操作,然后这些操作被编译成一个 MapReduce 作业。Pig 通过将脚本表示为数据流,使研究人员和工程师能更轻松地编写数据挖掘 Hadoop 脚本。
Pig 包含两个主要平台组件:
- Pig Latin,用于表达数据流的过程式脚本语言。
- 运行 Pig Latin 程序的 Pig 执行环境,可以在本地或 MapReduce 模式下运行,包含 Grunt 命令行接口。
Hive 的 HQL 充分继承了 SQL 的声明式风格,但 Pig Latin 不同,它本质上是过程式的,旨在让程序员能轻松实现一系列应用于数据集的数据操作和转换,从而形成数据流水线。虽然 Hive 非常适用于能很好转换为基于 SQL 的脚本的用例 ,但要转换多重复杂数据时,SQL 就显得力不从心了。Pig Latin 是实现这类多级数据流的理想选择,特别是需要从多个源聚合数据,并在数据处理流程的每个阶段执行后续转换的情况下。
Pig Latin 脚本从数据开始,对数据应用转换,最后描述所需结果,并将整个数据处理流程作为已优化的 MapReduce 作业执行。此外,Pig 支持使用由 Java、Python、JavaScript 及其他支持的语言编写的用户定义函数(UDF)集成自定义代码。因此,我们可以使用相对简单的构造对大数据进行几乎所有的转换和临时分析。
一定要记住,Pig 和 Hive 一样,最终将编译成 MapReduce 作业,无法突破 Hadoop 批处理方法的局限性。不过 Pig 也确实为我们提供了强大的工具,可以轻松、简便地编写复杂的数据处理流程,以及在 Hadoop 上构建真实业务应用程序所需的细粒度控制。
Pig Latin
先来研究一个 Pig 脚本,探讨探讨 Pig Latin 提供的命令和表达式。以下脚本将加载一个星期内带有标签 #unitedairlines 的 Twitter 推文。数据文件 united_airlines_tweets.tsv 提供了 tweet ID、固定链接、发布日期、推文和 Twitter 用户名。该脚本加载字典文件 dictionary.tsv,该文件包含已知的“正面的”(positive)和“负面的”(negative)词,以及与每个词相关联的情绪评分(分别为 1 和 -1)。然后,该脚本执行一系列 Pig 变换,生成每个推文的情绪评分和分类(POSITIVE 或 NEGATIVE):
grunt> tweets = LOAD 'united_airlines_tweets.tsv' USING PigStorage('\t')
AS (id_str:chararray, tweet_url:chararray, created_at:chararray,
text:chararray, lang:chararray, retweet_count:int, favorite_count:int,
screen_name:chararray);
grunt> dictionary = LOAD 'dictionary.tsv' USING PigStorage('\t')
AS (word:chararray, score:int);
grunt> english_tweets = FILTER tweets BY lang == 'en';
grunt> tokenized = FOREACH english_tweets GENERATE id_str,
FLATTEN( TOKENIZE(text) ) AS word;
grunt> clean_tokens = FOREACH tokenized GENERATE id_str,
LOWER(REGEX_EXTRACT(word, '[#@]{0,1}(.*)', 1)) AS word;
grunt> token_sentiment = JOIN clean_tokens BY word, dictionary BY word;
grunt> sentiment_group = GROUP token_sentiment BY id_str;
grunt> sentiment_score = FOREACH sentiment_group
GENERATE group AS id, SUM(token_sentiment.score) AS final;
grunt> classified = FOREACH sentiment_score
GENERATE id, ( (final >= 0)? 'POSITIVE' : 'NEGATIVE' ) AS classification,
final AS score;
grunt> final = ORDER classified BY score DESC;
grunt> STORE final INTO 'sentiment_analysis';
让我们将脚本分解成数据处理流程的单个步骤:
-
关系和元组
脚本的前两行将数据从文件系统加载到关系 tweets 和 dictionary 中:tweets = LOAD 'united_airlines_tweets.tsv' USING PigStorage('\t') AS (id_str:chararray, tweet_url:chararray, created_at:chararray, text:chararray, lang:chararray, retweet_count:int, favorite_count:int, screen_name:chararray); dictionary = LOAD 'dictionary.tsv' USING PigStorage('\t') AS (word:chararray, score:int);Pig 中的关系在概念上类似于关系数据库中的表,但它不是有序集合或行,而是一系列无序的元组。元组是一个有序的字段集合。一定要注意,虽然关系声明在赋值的左侧,与典型编程语言中的变量很像,但关系不是变量。给关系别名是为了引用,但它们其实代表的是数据处理流程中的检查点数据集。
首先,使用 LOAD 运算符指定文件的文件名(在本地文件系统或 HDFS 上),将它加载到 tweets 和 dictionary 关系中;然后,使用 USING 子句与 PigStorage 加载函数指定文件由制表符分隔;最后,使用 AS 子句定义每个关系的模式,并为每个字段指定列别名和相应的数据类型,但这步不是必需的。即使没有定义模式,仍然可以通过使用 Pig 的位置列(第一个字段为 $0 ,第二个字段为 $1 ,依此类推)引用关系中每个元组的字段。如果加载的数据有许多列,但你仅想引用其中几列时,不定义模式可能效果更好。
-
过滤
下一行对 tweets 关系执行了简单的 FILTER 数据转换,以过滤掉所有不是英文的元组:english_tweets = FILTER tweets BY lang == 'en';FILTER 运算符根据某种条件从关系中选择元组,通常用它来选择所需的数据,或者过滤掉(删除)不想要的数据。因为“lang”字段类型为 chararray ,所以使用 == 比较运算符来筛选出值为 en(English)的记录。结果存储在一个名为 english_tweets 的新关系中。
-
投影
过滤数据而只保留英文推文之后,我们需要将推文分成单词令牌,这样就可以将单词令牌与字典进行匹配,并可对单词进行一些额外的数据清理 ,删除 # 和 @:tokenized = FOREACH english_tweets GENERATE id_str, FLATTEN( TOKENIZE(text) ) AS word; clean_tokens = FOREACH tokenized GENERATE id_str, LOWER(REGEX_EXTRACT(word, '[#@]{0,1}(.*)', 1)) AS word;Pig 提供了
FOREACH ... GENERATE操作来处理关系或集合中的数据列,并将一组表达式应用于集合中的每个元组。 GENERATE 子句包含值和 / 或评估表达式,评估表达式将导出一个新的元组集合并将其传递到流水线的下一步。在此示例中,我们从 english_tweets 关系中投影 id_str 键,并使用 TOKENIZE 函数将 text 字段分割成单词令牌(使用空格分割)。FLATTEN 函数将生成的元组集合中的每个单词提取出来, id_str 与其中每一个单词构成一个元组。
我们生成的元组集合实际上是 Pig 中的一种特殊数据类型,被称为 bag。它代表一个无序的元组集合,类似于关系。但关系被称为“outer bag”,因为关系不能嵌套在另一个bag 中。在 FOREACH 命令中,结果产生一个叫作 tokenized 的新关系,它的第一个字段是 stock_tweet ID( id_str ),第二个字段是由单个单词元组组成的 bag。
然后,对 tokenized 关系再进行投影,取得 id_str 和删除了开头的 # 和 @ 的小写的 word 。我们对数据进行了很多转换,所以现在正是验证关系结构是否良好的好时机。你可以随时使用 ILLUSTRATE 运算符来查看基于简明样本数据集生成的每个关系的模式(为减少输出而截断了输出):
grunt> ILLUSTRATE clean_tokens; ------------------------------------------------------------------ | tweets | id_str:chararray | tweet_url:chararray | ------------------------------------------------------------------ | | 474415416874250240 | https://.../474415416874250240 | ------------------------------------------------------------------在设计 Pig 流时,定期使用 ILLUSTRATE 命令有助于了解查询的状态,并验证流水线中的每个检查点。
-
分组和连接
我们已经对所选的推文进行了分词,也清洗了单词令牌,现在希望 JOIN 得到的令牌和字典,根据单词令牌进行匹配:token_sentiment = JOIN clean_tokens BY word, dictionary BY word;Pig 提供 JOIN 命令,基于公共字段值对两个或多个关系执行连接。虽然默认情况下使用内连接,但是内连接和外连接都是被支持的。示例基于 word 字段对 clean_tokens 关系和 dictionary 关系执行内连接,这将生成一个名为 token_sentiment 的新关系,它包含两个关系的字段:
----------------------------------------------------------------------- | token_sentiment | clean_tokens::id_str:chararray |clean_tokens::word:chararray |dictionary::word:chararray | dictionary::score:int | ----------------------------------------------------------------------- | | 473233757961723904 | delayedflight | delayedflight | -1 | -----------------------------------------------------------------------现在,通过 Tweet ID(即 id_str ) GROUP 这些行,这样稍后才能计算每条推文的总分:
sentiment_group = GROUP token_sentiment BY id_str;GROUP 运算符将组键( id_str )相同的元组分到一起。这个操作会产生一个关系,每个组包含一个元组,每个元组包含两个字段:
- 第一个字段名为“group”(不要将它与 GROUP 运算符弄混了),与组键的类型相同。
- 第二个字段采用原先关系的名称( token_sentiment ),类型为 bag。
现在可以进行数据的最终聚合,计算按 ID 分组的每条推文的总分了:
sentiment_score = FOREACH sentiment_group GENERATE group AS id, SUM(token_sentiment.score) AS final;然后根据分数,将每条推文分类为“正面”或“负面”:
classified = FOREACH sentiment_score GENERATE id, ( (final >= 0)? 'POSITIVE' : 'NEGATIVE' ) AS classification, final AS score;最后,将结果按分数降序排列:
final = ORDER classified BY score DESC;至此,我们定义了情绪分析所需的所有操作和预测。接下来我们将把这些数据保存在 HDFS 上的一个文件中,可供之后查看、分析结果使用。
-
存储和输出数据
我们已经对数据应用了所有必要的转换,现在想在某处写出结果。为了实现这一操作,Pig 提供了 STORE 语句。它能获取某个关系,并将结果写入指定位置。默认情况下, STORE 命令将使用 PigStorage 将数据写入 HDFS 上制表符分隔的文件中。在此示例中,我们将 final 关系的结果转储到 Hadoop 用户目录中名为 sentiment_analysis 的文件夹中:STORE final INTO 'sentiment_analysis';该目录将包括一个或多个 part 文件:
$ hadoop fs -ls sentiment_analysis Found 2 items -rw-r--r-- 1 hadoop supergroup 0 2015-02-19 00:10 sentiment_analysis/_SUCCESS -rw-r--r-- 1 hadoop supergroup 7492 2015-02-19 00:10 sentiment_analysis/part-r-00000在本地模式下,只能创建一个 part 文件;但是在 MapReduce 模式下,part 文件的数量将取决于存储前最后一个作业的并行性。Pig 提供了几个功能,能设置生成的 MapReduce 作业的 reducer 数量。当使用较小的数据集时,使用 grunt shell 将结果快速输出到屏幕,比将结果存储起来更方便。 DUMP 命令使用关系的名称将其内容打印到控制台:
grunt> DUMP sentiment_analysis;DUMP 命令适用于快速测试和验证 Pig 脚本的输出。但面对大型数据集的输出时,你通常会将结果存储到文件系统供后续分析使用。
数据类型
我们已经介绍了一些 Pig 中的可用嵌套数据结构,比如字段、元组和 bag。Pig 还提供了 map 结构,其中包含键值对集合。键始终是 chararray 类型,但是值的数据类型不定。在定义推文数据的模式时,我们看到了 Pig 支持的一些原生标量类型。下表展示了所有 Pig 支持的标量类型:
| 类别 | 类型 | 描述 | 示例 |
|---|---|---|---|
| Numeric | int | 32 位带符号整数 | 12 |
| long | 64 位带符号整数 | 34L | |
| float | 32 位浮点数 | 2.18F | |
| double | 64 位浮点数 | 3e-17 | |
| Text | chararray | string 或字符数组 | hello world |
| Binary | bytearray | blob 或字节数组 | N/A |
关系运算符
Pig 通过 Pig Latin 中的关系运算符提供数据操作命令。在之前的示例中,我们使用过其中几个来加载、过滤、分组、投影和存储数据。下表展示了 Pig 支持的关系运算符:
| 分类 | 运算符 | 描述 |
|---|---|---|
| 加载和存储 | LOAD | 从文件系统或其他存储源加载数据 |
| STORE | 将关系存入文件系统或其他存储系统 | |
| DUMP | 将关系打印到控制台 | |
| 过滤和投影 | FILTER | 基于某种条件从关系中选择元组 |
| DISTINCT | 移除关系中重复的元组 | |
| FOREACH…GENERATE | 基于数据列生成数据转换 | |
| MAPREDUCE | 在 Pig 脚本内执行本地 MapReduce 作业 | |
| STREAM | 将数据发送给外部脚本或程序 | |
| SAMPLE | 选择一个指定大小的随机样本数据 | |
| 分组和连接 | JOIN | 连接两个或多个关系 |
| COGROUP | 将两个或多个关系的数据进行分组 | |
| GROUP | 将一个关系的数据进行分组 | |
| CROSS | 创建两个或多个关系的向量积 | |
| 排序 | ORDER | 根据一个或多个字段对关系进行排序 |
| LIMIT | 限制关系返回的元组数量 | |
| 合并与分割 | UNION | 合并两个或多个关系 |
| SPLIT | 把一个关系切分成两个或多个关系 |
用户定义函数
Pig 最强大的功能之一在于,它能够让用户将 Pig 的原生关系运算符与自己的自定义处理相结合。Pig 为用户定义函数(user-defined function,UDF)提供了广泛的支持,目前为 6 种语言提供了集成库,分别是 Java、Jython、Python、JavaScript、Ruby 和 Groovy。然而,Java 仍然是最广泛支持的编写 Pig UDF 的语言,并且通常更高效——因为它与 Pig 是相同的语言,可以与 Pig 接口(例如 Algebraic 接口和 Accumulator 接口)集成。
来演示一个之前写过的脚本的简单 UDF。在这种场景下,我们想编写一个自定义的评估 UDF,将分数分类评估转换为一个函数。这样的话,就不需要写:
classified = FOREACH sentiment_score GENERATE id, ( (final >= 0)? 'POSITIVE' : 'NEGATIVE' ) AS classification, final AS score;
而是写:
classified = FOREACH sentiment_score GENERATE id, classify(final) AS classification, final AS score;
在 Java 中,我们需要扩展 Pig 的 EvalFunc 类并实现 exec() 方法。该方法需要一个元组,并返回一个 String:
package com.statistics.pig;
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.backend.executionengine.ExecException;
import org.apache.pig.data.Tuple;
public class Classify extends EvalFunc {
@ Override
public String exec(Tuple args)throws IOException {
if (args == null || args.size() == 0) {
return false;
}
try {
Object object = args.get(0);
if (object == null) {
return false;
}
int i = (Integer)object;
if (i >= 0) {
return new String("POSITIVE");
} else {
return new String("NEGATIVE");
}
} catch (ExecException e) {
throw new IOException(e);
}
}
}
要使用此函数,就需要先编译它,将它打包成 JAR 文件,然后使用 REGISTER 运算符将它注册到 Pig:
grunt> REGISTER statistics-pig.jar;
然后通过命令调用该函数:
grunt> classified = FOREACH sentiment_score GENERATE id, com.statistics.pig.Classify(final) AS classification, final AS score;
对偏爱过程式编程模型的用户来说,Pig 是一个强大的工具。它能控制流水线中的数据检查点,更提供了对每个步骤如何处理数据的细粒度控制。当你需要更灵活地控制数据流中的操作顺序(例如提取、转换、加载或 ETL 过程),或者面对不适合使用 Hive 的 SQL 语法的半结构化数据时,Pig 都是一个很好的选择 。
2. Spark高级API
现在的许多项目和工具都围绕着 MapReduce 和 Hadoop 构建,以支持常见的数据任务并提供更高效的开发人员体验。例如我们已经见过的,使用 Hadoop Streaming 这样的框架以非 Java 语言(如 Python)编写和提交 MapReduce 作业。我们还介绍了为 MapReduce 提供更高级别抽象的工具——Hive 和 Pig。Hive 提供了关系型接口和声明式的基于 SQL 的语言来查询结构化数据,而 Pig 提供了一个在 Hadoop 中编写面向数据流程序的过程式接口。
但在实际工作中,典型的分析工作流将结合关系查询、过程式编程和自定义处理三者。这意味着大多数端到端 Hadoop 工作流都要集成多个不同组件,并在不同编程 API 之间切换。与以 MapReduce 为中心的 Hadoop 栈相比,Spark 在编程上有两大优势:
- 内置表达力强大的 API,以标准的通用语言(例如 Scala、Java、Python 和 R)提供。
- 包含若干内置高级库的统一编程接口,支持广泛的数据处理任务,比如复杂的交互式分析、结构化查询、流处理和机器学习。
前面我们使用 Spark 的基于 Python 的 RDD API 编写了一个程序,在不使用工具类的大约 10 行代码中,对数据集进行了加载、清洗、连接、过滤和排序。如你所见,Spark 的 RDDAPI 提供了更丰富的功能操作,代码量远远小于在 MapReduce 中编写的类似程序。然而,因为 RDD 是一种通用的、与类型无关的数据抽象,而且 RDD 固定的模式只有你知道,所以处理结构化数据的过程非常繁琐;这通常将迫使你必须编写大量重复代码才能访问内部数据类型,以及将简单查询操作转换为 RDD 操作的函数语义。考虑下图所示的操作,该操作试图计算各学科教授的平均年龄。

在实践中,使用关系型数据的通用语言 SQL 来处理这样的结构化表格数据要更自然一些。好在 Spark 提供了一个集成的模块,让我们仅用一行简单的代码就表达了前面的聚合,如下图所示:
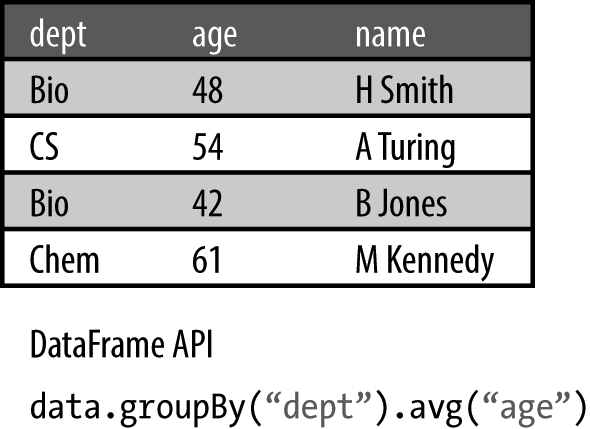
Spark SQL
Spark SQL 是 Apache Spark 中的一个模块,它提供了一个关系型接口,让你在 Spark 中使用熟悉的基于 SQL 的操作来处理结构化数据。可以通过 JDBC/ODBC 连接器、内置的交互式 Hive 控制台或其内置的 API 访问 Spark SQL。最后一种访问方式是其中最有趣,也是最强大的,因为实际上,Spark SQL 是作为库在 Spark 的 Core 引擎和 API 之上运行的。所以,可以使用与 Spark 的 RDD API 相同的编程接口访问 Spark SQL 的 API,如下图所示:

这让我们能在一个编程环境中,将关系查询的优势、Spark 过程式处理的灵活性和 Python 分析库的强大功能充分结合并付诸实践。来写一个简单的程序,用 Spark SQL API 加载 JSON 数据并进行查询。你可以在运行着的 pyspark shell 中直接输入这些命令,也可以在使用 pyspark 内核的 Jupyter notebook 中输入这些命令;无论使用哪种方法,都要确保有一个运行着的 SparkContext,因为假定变量 sc 将引用它。
-
首先,从 pyspark.sql 包导入 SQLContext 类。 SQLContext 类是 Spark SQL API 的入口,通过包装活动的 SparkContext 对象创建:
from pyspark.sql import SQLContext sqlContext = SQLContext(sc) -
在此示例中,我们将从 SF Open Data 加载一个 JSON 格式的数据集,该数据集列出了 2011 年 9 月旧金山公开可用的路边停车位。
与 Hadoop 一样,Spark SQL 也要求将 JSON 数据格式化。所以,要删除第一个和最后一个大括号或中括号,让每个 JSON 对象都包含在一行中,后跟换行符(即没有跨越多行的 JSON 对象)。对于极大的数据集,你可以使用 Spark 来执行格式化。例如,如果需要手动删除 JSON 文件的第一个和最后一个方括号,可以这样加载和格式化文件:
input = sc.wholeTextFiles(input_path).map(lambda (x,y): y) data = input.flatMap(lambda x: json.loads(x)) data.map(lambda x: json.dumps(x)).saveAsTextFile(output_path)wholeTextFiles 函数创建了一个 PairRDD ,其中键是拥有完整路径的文件名(是按照文件读不是按行读),值是整个文件内容的字符串。使用 map 操作提取内容作为输入,然后使用 flatMap 将字符串内容读取为 JSON 格式。
-
调整文件至正确格式后,通过调用 sqlContext.read.json 并将文件的路径传递给它,就可以轻松加载文件内容了:
parking = sqlContext.read.json('../data/sf_parking/sf_parking_clean.json')也可以将一个目录的路径传递给 sqlContext , sqlContext 会将其中所有的文件加载到parking 对象中。Spark SQL 自动推断 JSON 数据集的模式,可以使用 printSchema 方法以漂亮的树形式来显示它:
parking.printSchema() root |-- address: string (nullable = true) |-- garorlot: string (nullable = true) |-- landusetyp: string (nullable = true) |-- location_1: struct (nullable = true) | |-- latitude: string (nullable = true) | |-- longitude: string (nullable = true) | |-- needs_recoding: boolean (nullable = true) |-- mccap: string (nullable = true) |-- owner: string (nullable = true) |-- primetype: string (nullable = true) |-- regcap: string (nullable = true) |-- secondtype: string (nullable = true) |-- valetcap: string (nullable = true)还可以查看第一行数据:
parking.first() Row(address=u'2110 Market St', garorlot=u'L', landusetyp=u'restaurant', location_1=Row(latitude=u'37.767378', longitude=u'-122.429344', needs_recoding=False), mccap=u'0', owner=u'Private', primetype=u'PPA', regcap=u'13', secondtype=u' ', valetcap=u'0') -
为了对数据集运行 SQL 语句,必须先将其注册为临时命名表:
parking.registerTempTable("parking")这才允许我们运行额外的表和 SQL 方法,比如用表格形式显示前 20 行数据的 show :
parking.show() ...output truncated... -
如果要在 parking 表上执行 SQL 语句的话,就需要使用 sql 方法,并将完整的查询语句传递给它。来运行一个聚合,按照主要类型和次要类型对停车场地进行分组,获得停车场地的数量以及普通停车位的平均个数。将其存储在 aggr_by_type 中,并调用 show() 来查看完整的结果:
aggr_by_type = sqlContext.sql("SELECT primetype, secondtype, count(1) AS count, round(avg(regcap), 0) AS avg_spaces " + "FROM parking " + "GROUP BY primetype, secondtype " + "HAVING trim(primetype) != '' " + "ORDER BY count DESC") aggr_by_type.show()
除了 JSON 之外,Spark SQL 还支持其他几种数据源,比如本地文件系统、HDFS 或 S3 中的文件(例如文本文件、parquet 文件、CSV 文件等)、JDBC 数据源(例如 MySQL)和 Hive。此外,Spark 甚至可以作为 Hive 的底层执行引擎使用,只需在活动的 Hive 会话中设置 hive.execution.engine=spark 即可。
但 Spark SQL 模块可不仅仅是一个 SQL 接口而已,它的强大归根到底来源于其底层的数据抽象——DataFrame。
DataFrame
DataFrame 是 Spark SQL 中 的 底 层 数 据 抽 象,事实上,Spark 的 DataFrame 与 原 生 的 Pandas( 使 用 pyspark ) 和 R 数 据 框( 使 用 SparkR)是可以互操作的。DataFrame 在 Spark 中也表示已定义模式的数据的表。Spark 的 DataFrame 和 Pandas、R 的数据框的关键区别是,前者实际上是一个包装了 RDD 的分布式集合;你可以将其视为行对象的 RDD。
此外,DataFrame 操作在底层进行了许多优化,不仅将查询计划编译为可执行代码,而且与硬编码的 RDD 操作相比,性能有显著提升,内存占用的空间也大幅减少。事实上,如果在一个基准测试中,将聚合了 1000 万整数对的 DataFrame 代码和与之等效的 RDD 代码进行运行时间上的对比,你会发现 DataFrame 不仅速度快 4~5 倍,而且还消除了 Python 和 JVM 实现的性能差距,如下图所示:
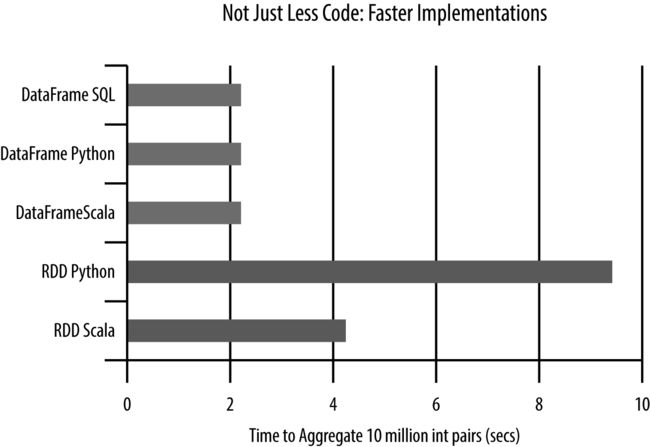
DataFrame API 简洁直观的语义,加上它计算引擎提供的性能优化,促使 DataFrame 成为了 Spark 所有模块(包括 Spark SQL、RDD、MLlib 和 GraphX)的主要接口。通过这种方式,DataFrame API 提供了统一的引擎,跨越了 Spark 的所有数据源、工作负载和环境,如下图所示:

在上一个例子中,我们使用 Spark SQL 的 read 接口加载了 SF 停车场地数据。但实际上,我们创建了一个叫作 parking 的 DataFrame。在那个例子中,我们将 DataFrame 注册为临时表来执行原始 SQL 查询,在 parking DataFrame 上也有很多可以调用的关系运算符和窗口函数。事实上,通过将几个简单的 DataFrame 操作连接起来,就可以重写上一个例子中的 SQL 查询:
from pyspark.sql import functions as F
aggr_by_type = parking.select("primetype", "secondtype", "regcap") \
.where("trim(primetype) != ''") \
.groupBy("primetype", "secondtype") \
.agg(
F.count("*").alias("count"),
F.round(F.avg("regcap"), 0).alias("avg_spaces")
) \
.sort("count", ascending=False)
与原始 SQL 相比,这种方法可以通过连续链接和测试操作,轻松迭代复杂查询,这是它的优势。此外,我们还可以使用 DataFrame API 访问大量的内置函数集合,比如之前使用的 count 、 round 和 avg 聚合函数。 pyspark.sql.functions 模块还包含一些数学和统计工具,其中包含的函数可用于:
- 随机数据的生成
- 总结和描述性数据
- 样本协方差和相关性
- 交叉表(亦称列联表)
- 频率计算
- 数学函数
来使用一个这样的函数计算一些描述性的总结统计数据,以便对可用停车场地数据的分布和频率有更好的了解。 describe 函数返回一个 DataFrame,其中包含每个指定数字列的非空条目计数、平均值、标准差、最小值和最大值:
parking.describe("regcap", "valetcap", "mccap").show()
+-------+------------------+------------------+------------------+
|summary| regcap | valetcap | mccap |
+-------+------------------+------------------+------------------+
| count| 1000 | 1000 | 1000 |
| mean| 137.294 | 3.297 | 0.184 |
| stddev|361.05120902655824 |22.624824279398823 |1.9015151221485882|
| min| 0 | 0 | 0 |
| max| 998 | 96 | 8 |
+-------+------------------+------------------+------------------+
也许我们想确定停车场地所有者和停车场主要类型(“primetype”)之间的联合频率分布。在统计学中,这通常通过计算列联表或交叉表完成,这两种表以矩阵格式显示两个变量之间的共现频率。使用 stat 接口中的 crosstab 方法就可以轻松为 Spark DataFrame 计算该分布了:
parking.stat.crosstab("owner", "primetype").show()
+-------------------+---+---+---+---+---+
| owner_primetype |PPA|PHO|CPO|CGO| |
+-------------------+---+---+---+---+---+
| Port of SF | 7 | 7 | 0 | 4 | 0 |
| SFPD | 0 | 3 | 0 | 6 | 0 |
| SFMTA | 42| 14| 0 | 0 | 0 |
|GG Bridge Authority| 2 | 0 | 0 | 0 | 0 |
| SFSU | 2 | 6 | 0 | 0 | 0 |
| SFRA | 2 | 0 | 0 | 0 | 0 |
..output truncated..
数据整理DataFrame
请注意,因为“owner”列看上去是高基数维度,因此结果被截断为前 20 行数据。虽然 Pandas 和 R 的用户应该能很好地理解 Spark DataFrame API 中的许多操作和功能,但由于 DataFrame 本质上的不可变性和分布式特性,所以它的一些有别于 Pandas/R 的地方应该被注意。例如,尽管 Spark 在加载时尽可能推断数据类型,但默认的回退类型(fallback type)还是字符串,这一点在 SF 停车示例中的“regcap”列有所体现。在 Pandas 中,可以通过选择该列并使用 astype 轻松转换该列值的类型:
parking['regcap'].astype(int)
但由于 DataFrame 实际上只是 RDD 的封装,是不可变的集合,因此需要执行几个步骤才能将此列转换为 int 类型。这种解决方法会根据现有列创建一个新列,将其值转换为正确的类型,最后删除旧列。为了保留列名,首先使用 withColumnRenamed 方法将现有列重命名为“regcap_old”,然后使用 withColumn 方法添加新的“regcap”列,该列包含 regcap_old 中转换类型后的值:
parking = parking.withColumnRenamed('regcap', 'regcap_old')
parking = parking.withColumn('regcap', parking['regcap_old'].cast('int'))
parking = parking.drop('regcap_old')
因为其他数值列也需要进行这个转化,所以来定义一个工具函数,为任意列和数据类型执行这种转换:
def convert_column(df, col, new_type):
old_col = '%s_old' % col
df = df.withColumnRenamed(col, old_col)
df = df.withColumn(col, df[old_col].cast(new_type))
df.drop(old_col)
return df
parking = convert_column(parking, 'valetcap', 'int')
parking = convert_column(parking, 'mccap', 'int')
parking.printSchema()
虽然这里使用的是 Spark 的 cast 方法,但是从 Spark 1.4 起也可以使用 astype ,它是 cast 方法的 Pandas 友好别名。
不幸的是,这个函数不能处理“latitude”和“longitude”,因为它们实际上是“location_1”结构中的字段。我们可以进行一些改良,定义另一个参数为“location_1”结构类型的函数,使用 Google 的 Geocoding API 执行经纬度查找,以返回邻域名称。使用 requests 库来发送请求:
import requests
def to_neighborhood(location):
"""
使用Google的Geocoding API执行经纬度的逆向查找
"""
name = 'N/A'
lat = location.latitude
long = location.longitude
r = requests.get('https://maps.googleapis.com/maps/api/geocode/json?latlng=%s,%s' % (lat, long))
if r.status_code == 200:
content = r.json()
# results是匹配地址的列表
places = content['results']
neighborhoods = [p['formatted_address'] for p in places if 'neighborhood' in p['types']]
if neighborhoods:
# 地址格式为Japantown, San Francisco, CA
# 所以根据逗号分割,返回邻域名称
name = neighborhoods[0].split(',')[0]
return name
to_neighborhood 函数接受一个 location 结构并返回一个字符串类型,但是如何在列表达式中使用这个函数呢? pyspark.sql.functions 模块提供了用于注册 UDF 的 udf 函数。通过向 UDF 传递一个可调用的 Python 函数和该函数的返回类型对应的 Spark SQL 数据类型,我们声明了一个内联UDF;在这个示例中,返回的是一个字符串,所以使用 pyspark.sql.types 中的 StringType 数据类型。注册后,可以使用该 UDF 通过一个 withColumn 表达式重新格式化“location_1“列:
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
location_to_neighborhood=udf(to_neighborhood, StringType())
sfmta_parking = parking.filter(parking.owner == 'SFMTA') \
.select("location_1", "primetype", "landusetyp", "garorlot", "regcap", "valetcap", "mccap") \
.withColumn("location_1", location_to_neighborhood("location_1")) \
.sort("regcap", ascending=False)
sfmta_parking.show()
+-------------------+-----------+-----------+-----------+-------+-----------+-------+
| location_1 |primetype |landusetyp |garorlot |regcap |valetcap |mccap |
+-------------------+-----------+-----------+-----------+-------+-----------+-------+
| South of Market | PPA | | G | 2585 | 0 | 47 |
| N/A | PPA | | G | 1865 | 0 | 0 |
|Financial District | PPA | | G | 1095 | 0 | 0 |
| Union Square | PPA | | G | 985 | 0 | 0 |
.. output truncated ..
在 Spark 本地模式下,由于 Python 的全局解释器锁(global interpreter lock,GIL)的线程限制,我们无法并行化对 API 的 HTTP 请求。因此,在本地模式下使用此实用程序将需要串行运行整个 RDD,这可能需要相当长的时间。因此,为了让操作在合理的时间内完成,此示例将 DataFrame 过滤到了合适的大小。
如你所见,使用 Spark 的 DataFrame API 定义、注册 UDF 的过程比使用 Pig 和 Hive 容易得多。一旦注册,UDF 不仅可以被同一个 Spark 集群上的其他程序使用,也可以被通过 JDBC/ODBC 接口连接到 Spark SQL 上的 BI 工具使用。这使得 udf 函数轻松成为了 DataFrame API 提供的最强大的函数,因为它向 SQL 用户展现了应用高级计算或操作的无限可能性。
3. 总结
在本章中,我们了解了 Pig 如何大大简化了 MapReduce 数据流水线的构建过程。Pig 的主要使用场景是传统的 ETL 数据流水线过程,但它也是一种很好的工具,非常适用于执行临时分析,并从大批量数据中构建迭代处理或预测模型,当分析越来越复杂时尤其如此。
我们还介绍了 Spark SQL 模块和 DataFrame API。Spark 提供了内置集成,支持对结构化数据集的关系处理,并允许用户在单个编程环境中将关系处理和复杂的分析相结合。DataFrame 为 Hadoop 或 Spark 的 Python 程序员提供了广泛的、前所未有的分析可能性。
十二、机器学习
这一章我们将讨论使用 Spark MLlib 的机器学习和计算方法。
机器学习计算旨在从当前和历史数据中推导出预测模型。它作出了一个固有假设,即经历越多训练或获取越多经验,学习获得的算法将改进越多。通过从大数据集训练出来的模型,机器学习算法可以在非常小的领域实现非常好的预测效果。
因此,大多数机器学习算法都涉及大规模计算。出于这个原因,机器学习计算非常适用于 Spark 等分布式计算范式,利用大型训练集生成有意义的结果。本章将介绍 Spark 内置的机器学习库——Spark MLlib。它由许多常见的学习算法和实用程序组成,比如分类、回归、聚类、协同过滤、降维以及一个新的“机器学习流水线”框架——spark.ml。spark.ml 提供了一套统一的高级 API,可以帮助用户创建和优化实际的机器学习流水线。
1. 使用Spark进行可扩展的机器学习
在前面章节中,我们将 Spark 作为一个可在 Hadoop 集群上运行的内存分布式计算引擎进行了介绍。而且,Spark 平台还附带了几个使用 Spark 处理引擎的内置组件,来支持其他类型的分析工作,这些功能都受益于 Spark 的计算优化。本章将仔细研究 Spark 的内置机器学习库——MLlib。该库包含一套通用的统计和机器学习算法和实用程序,它们都被设计为能在集群中扩展。
有些人可能对数据挖掘和机器学习的编程库很熟悉,比如 Python 的 Weka 或者 Scikit-Learn。虽然用这些库能游刃有余地应对可以在单个机器上处理的中小型数据集,但对于要求分布式存储和并行处理的大型数据集,我们不仅需要可以处理分布式数据集的计算引擎,还需要为并行平台设计的算法。Spark MLlib 仅仅包含并行算法,使用 Spark 的 RDD 操作跨节点并行应用操作。好在有许多机器学习技术和算法都非常适合并行化。但一定要记住,与 Spark API 一样,使用 Spark MLlib 时要注意创建数据(作为 RDD),并以分布式并行化的方式对数据进行操作。例如,对一个原始类型的小数据集(Python 字典或列表)调用 parallelize() ,以便将其提供给集群中的所有节点。
Spark MLlib 包括一些统计和机器学习技术,比如采样、相关计算、假设检验等。而我们将主要关注 MLlib 的机器学习算法。这类算法基于训练数据寻找算法行为的数学最优解,从而作出预测和决策。Spark MLlib 学习算法集中在机器学习的三个关键领域,通常被称为机器学习的 3C:
- 协同过滤(collaborative filtering)
也被称为推荐引擎。它基于过去的行为、偏好或与已知实体 / 用户的相似性产生推荐。 - 分类(classification)
也被称为有监督学习。它从监督训练集中学习,并根据该训练集对未分类项进行分类。 - 聚类(clustering)
也被称为无监督学习。它基于类似特征,将数据分组为集群。
一般来说,要想实现这些算法,得先从数据中定义和提取一组特征作为特征的数值表示。例如,如果我们要设计一个能推荐具有相似属性(价格、颜色、品牌等)产品的推荐系统,就可以定义由每个产品属性的加权数值组成的特征向量。或者,当我们想提取非结构化文本的特征(即基于垃圾邮件,检测过滤电子邮件)时,则可以用每个词在每个分类类别(即是垃圾邮件或不是垃圾邮件)的词频 - 逆文档频率(TF-IDF)的向量来表示它。
一旦从数据中提取了特征向量,就可以将它们作为训练数据提供给机器学习算法,该算法将返回表示预测的训练模型。在训练有监督学习模型时,通常会保留一部分训练数据作为“测试数据”,将模型应用于测试数据,并通过比较测试数据的预测结果与实际结果来量化模型的准确性。这使我们能评估模型的准确性并优化其精度。机器学习流水线的概览图如下图所示:

我们将把这种常见的机器学习流水线应用于接下来的几个例子中,并使用 MLlib 内置的一些评估工具来评估我们的学习模型。假设你已经安装了 Spark 并符合运行 Spark MLlib 的要求。
2. 协同过滤
协同过滤(或推荐系统)应该最常见于电子商务领域,比如亚马逊和 Netflix 等公司通过挖掘用户行为数据(如浏览、评分、点击和购买)来推荐其他产品。 广义上,协同过滤算法分为两种:
- 基于用户的推荐系统
查找与目标用户相似的用户,使用其协同评分为目标用户提供推荐。 - 基于物品的推荐系统
查找并推荐与目标用户相关联物品相似或相关的物品。
MLlib 的协同过滤库专注于基于用户的推荐,使用交替最小二乘法(alternating least squares,ALS)算法的实现。MLlib 的协同过滤方法将用户的偏好表示为用户物品关联矩阵,其中每位用户和物品的点积通过将偏好评分(或评级)与加权因子相乘获取。这样,我们就能接收用户的显式反馈(例如正评分、购买)和隐式反馈(例如浏览、点击),并将它们并入模型中,作为二元偏好和置信度值的组合。然后,该模型将去寻找可用于预测物品的预期偏好的隐语义因子。
示例:一个基于用户的推荐系统
试着用 MLlib 的 ALS 算法为在线约会服务生成推荐(或潜在)对象。我们将根据已有的交友网站的个人资料评分数据集为特定用户生成推荐内容。我们将利用包含数据集的两个 CSV 文件:168791份用户个人资料,以及一百万条以上关于他们的用户评分数据。评分数据遵从以下格式:UserID、ProfileID、Rating。UserID 是提供评分的用户,ProfileID 是被评分的用户,Rating 是 1~10 的评分,其中 10 是最高分。
UserID 的范围介于 1 ~ 135359,ProfileID 的范围介于 1~220970(并非每份用户资料都被评过分)。只有至少提供了 20 条评分的用户才会被纳入,一直打同样分数的用户将被排除。用户的性别信息遵从以下格式:UserID、Gender,其中男性为“M”、女性为“F”、未知为“U”。
使用 spark-submit 命令,并向它传递两个参数:UserID(要为谁生成推荐)以及 M 或 F(对伴侣的性别偏好),该程序就可以在 Spark 上运行了。建议将此输出通过管道写入到一个文件中:
$ $SPARK_HOME/bin/spark-submit \
~/hadoop-fundamentals/mllib/collaborative_filtering/als/matchmaker.py 1 M \
> ~/matchmaking_recs.txt
我们将分析该程序的每个主要步骤。首先,使用应用程序的名称配置 SparkContext,并将每个 executor 使用的内存大小设置为 2GB,因为 ALS 算法处理这个数据量需要大量内存:
# 配置Spark
conf = SparkConf().setMaster("local") \
.setAppName("Dating Recommender") \
.set("spark.executor.memory", "2g")
sc = SparkContext(conf=conf)
接下来,读取 UserID 参数以及用户的性取向,并对评分文件中的每条记录调用自定义的 parse_rating 方法:
def parse_rating(line, sep=','):
"""
解析评分行
返回:元组(随机整数, (user_id, profile_id, rating))
"""
fields = line.strip().split(sep)
user_id = int(fields[0]) # 将user_id转换为int
profile_id = int(fields[1]) # 将profile_id转换为int
rating = float(fields[2]) # 将rated_id转换为int
return random.randint(1, 10), (user_id, profile_id, rating)
给定一个评分行, parse_rating 方法返回一个元组,其中第一项是一个随机整数,第二项是另一个元组 (user_id, profile_id, rating) :
matchseeker = int(sys.argv[1])
gender_filter = sys.argv[2]
# 创建评分RDD (随机整数, (user_id, profile_id, rating))
ratings = sc.textFile(
"/home/hadoop/hadoop-fundamentals/data/dating/ratings.dat")\
.map(parse_rating)
为元组中的第一项生成一个随机数,之后它将作为键将此 RDD 分解为训练集和测试集。ALS 要求将 Rating 对象表示为 (UserId, ItemId, Rating) 元组。在这个示例中, ItemId 实际将映射到其他用户资料的用户 ID。
接下来,通过将自定义的 parse_user 方法映射到 gender.dat 的每一行,读取用户个人资料数据:
def parse_user(line, sep=','):
"""
解析用户行
返回:元组(user_id, gender)
"""
fields = line.strip().split(sep)
user_id = int(fields[0]) # 将user_id转换为int
gender = fields[1]
return user_id, gender
给定一个用户行, parse_user 方法返回一个元组 (user_id, gender) 。一旦用户元组的RDD 生成,就调用 collect() 将 RDD 转换为列表:
# 创建用户RDD
users = dict(sc.textFile(
"/home/hadoop/hadoop-fundamentals/data/dating/gender.dat")\
.map(parse_user).collect())
现在来将评分数据分为训练集和验证集,训练集用于训练模型,验证集用于评估模型。通过对添加到每个元组的随机整数键进行过滤,保留 60%的训练数据和 40%的验证数据。将分区数设置为 4(或计算机支持的处理器内核数)并缓存结果,提高 RDD 的并行性。
# 基于时间戳的最后一位,创建训练集(60%)和验证集(40%)
num_partitions = 4
training = ratings.filter(lambda x: x[0] < 6) \
.values() \
.repartition(num_partitions) \
.cache()
validation = ratings.filter(lambda x: x[0] >= 6) \
.values() \
.repartition(num_partitions) \
.cache()
num_training = training.count()
num_validation = validation.count()
print "Training: %d and validation: %d\n" % (num_training, num_validation)
可以通过设置和调整 ALS 提供的这些训练参数来优化模型:
- rank
使用的特征向量的大小,由隐语义因子的数量决定; rank 越大,产生的模型越好,但计算的代价也更大(默认值为 10)。 - num_iterations
迭代次数(默认值为 10)。 - lambda
正则化参数(默认值为 0.01)。 - alpha
常数(默认值为 1.0),用于计算隐式反馈 ALS 的置信度。
因为此例只捕获显式评分,所以将忽略 alpha 并使用默认值。其他参数中, rank 使用 8,将迭代次数设置为 8, lambda 为 0.1。由于对数据还不够了解,无法确定隐语义因子的数量或合适的正则化值,所以这些初始训练参数设置得有些随意。然而,可以先从这个组合开始,将它与使用其他训练参数组合的模型进行对比来评估结果,确定最佳拟合模型:
# rank是模型中隐语义因子的数量
# num_iterations是迭代次数
# lambda指定ALS中的正则化参数
rank = 8
num_iterations = 8
lambda = 0.1
现在使用 ALS.train() 方法创建模型,该方法接受评分元组的训练 RDD 和我们的训练参数:
# 使用训练数据、已配置的rank和迭代参数训练模型
model = ALS.train(training, rank, num_iterations, lambda)
# 使用验证集评估经过训练的模型
print "The model was trained with rank = %d, lambda = %.1f, and %d iterations.\n" %(rank, lambda, num_iterations)
模型一旦被创建,就使用均方根误差(root mean squared error,RMSE)来计算每个模型的误差。RMSE 是拥有实际评分的所有用户的(实际评分 - 预测评级)2 的平均值的平方根:
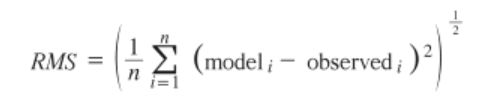
我们的推荐程序也可以相应地实现 RMSE 计算:
def compute_rmse(model, data, n):
"""
计算RMSE,或者(实际评分 - 预测评分)^2的平均值的平方根
"""
predictions = model.predictAll(data.map(lambda x: (x[0], x[1])))
predictions_ratings = predictions.map(lambda x: ((x[0], x[1]), x[2])) \
.join(data.map(lambda x: ((x[0], x[1]), x[2]))) \
.values()
return sqrt(predictions_ratings.map(lambda x: (x[0] - x[1]) ** 2).reduce(add) / float(n))
RMSE 表示模型对数据的绝对拟合(观察数据点与模型预测值的接近程度),并且与评分值的单位相同。RMSE 值越小,拟合度越高。但由于它与评分值相关,所以应该按 1~10 进行评估。根据结果,可以通过调整训练参数,或者提供更多或更好的训练数据,来优化模型:
# 打印模型的RMSE
validation_rmse = compute_rmse(model, validation, num_validation)
print "The model was trained with rank=%d, lambda=%.1f, and %d iterations." %(rank, lambda, num_iterations)
print "Its RMSE on the validation set is %f.\n" % validation_rmse
假设我们对 RMSE 值反映出来的模型拟合程度很满意,就可以用它来为给定用户生成推荐了。通过根据给定用户的性取向进行过滤,先生成一组符合条件的用户。这是推荐候选人 RDD:
# 根据性取向进行过滤
partners = sc.parallelize([u[0] for u in filter(lambda u: u[1] == gender_filter, users.items())])
现在使用模型的 predictAll() 方法,向它传递一个二元元组 RDD,RDD 的 key 是 user_id ,其中 user_id 是给定的要为之生成推荐的用户(matchseeker)。这样,模型就能生成推荐。我们会将结果收集到一个列表中,按照评分值降序排序,取前 10 名推荐用户:
# 使用经过训练的模型进行预测
predictions = model.predictAll(partners.map(lambda x: (matchseeker, x))).collect()
# 对推荐进行排序
recommendations = sorted(predictions, key=lambda x: x[2], reverse=True)[:10]
最后,打印完整的推荐列表并停止 SparkContext:
print "Eligible partners recommended for User ID: %d" % matchseeker
for i in xrange(len(recommendations)):
print ("%2d: %s" % (i + 1, recommendations[i][1])).encode('ascii', 'ignore')
# 清理
sc.stop()
如果使用前面的命令将此作业提交到 Spark,并将输出保存到一个结果文件中,应该会看到类似于以下内容的输出:
$ cat matchmaking_recs.txt
Training: 542953 and validation: 542279
The model was trained with rank = 8, lambda = 0.1, and 8 iterations.
Its RMSE on the validation set is 3.580347.
Eligible partners recommended for User ID: 1
1: 100939
2: 70020
3: 109013
4: 54998
5: 132170
6: 3843
7: 170778
8: 51378
9: 8849
10: 118595
RMSE 是评估模型性能的重要指标。与大多数机器学习算法一样,协同过滤模型中的数据和迭代次数越多,模型表现越好。建议你尝试对 ALS 使用不同的 rank 、迭代次数和正则化( lambda )参数的组合,比较 RMSE 以找到最佳拟合的参数组合。
3. 分类
分类试图通过有监督训练方法将数据(通常是文本或文档)分类,这些方法使用带标注的训练集来发现模式,使机器学习程序能快速标记新记录。例如,一个简单的分类算法可能会记录与类别相关联的特征和词,以及该词出现在给定类别中的次数。一旦机器学习程序从训练数据中提取出了特征,它就可以生成特征向量并应用统计模型构建预测模型,然后将预测模型应用于新的数据。
MLlib 提供了一些用于二分类、多分类以及回归分析的算法。在二分类中,我们希望将实体分为两个不同的类别或标签(例如确定电子邮件是否为垃圾邮件);在多分类中,我们希望将实体分类为两个以上的类别(例如确定新闻报道属于哪个类别);回归分析算法的目标是,使用连续函数估计因变量(例如身体活动水平)与一个或多个自变量(例如心脏病的风险)之间的关系和依赖性。
在这些类型的算法中,MLlib 实现都要对一组带标签的例子(example)应用算法。这些例子被表示为 LabeledPoint 对象,包括一个数值(用于二分类)或特征向量(用于多分类)以及类别标签。已经分类的 LabeledPoints 中的训练数据用于训练模型,然后用模型去预测新实体的类别。本节将通过随机梯度下降的逻辑回归过程(也被称为 LogisticRegressionWithSGD )创建一个简单的二分类器。
示例:一个逻辑回归分类
在这个示例中,我们将构建一个简单的垃圾邮件分类器,使用已经分类(垃圾邮件和非垃圾邮件)的电子邮件数据进行训练。此垃圾邮件分类器将使用两个 MLlib 算法: HashingTF 和 LogisticRegressionWithSGD ,前者从训练文本提取词频向量作为特征向量,后者使用随机梯度下降实现逻辑回归。
可以使用以下命令运行程序:
$ $SPARK_HOME/bin/spark-submit \
/home/hadoop/hadoop-fundamentals/mllib/classification/spam_classifier.py \
/home/hadoop/hadoop-fundamentals/data/spam_classifier/spam.txt \
/home/hadoop/hadoop-fundamentals/data/spam_classifier/ham.txt
我们将讲解每个主要步骤。
首先配置 SparkContext,设置应用程序名称,并将 executor 内存增加到 2GB:
# 配置Spark
conf = SparkConf().setMaster("local") \
.setAppName("Spam Classifier") \
.set("spark.executor.memory", "2g")
sc = SparkContext(conf=conf)
接下来读取命令行参数,获取训练数据文件的路径。读取这些文件,创建垃圾邮件(spam)和非垃圾邮件(ham)RDD:
spam_file = sys.argv[1]
ham_file = sys.argv[2]
spam = sc.textFile(spam_file)
ham = sc.textFile(ham_file)
现在,实例化 HashingTF 对象,将要提取的特征数量设置为 10 000:
tf = HashingTF(numFeatures=10000)
将 HashingTF 的 transform() 方法应用于 spam 和 ham 数据,首先将内容分成单词令牌。这将从 spam 和 ham RDD 中提取出词频向量,并将其投影为新的特征向量 RDD:
spam_features = spam.map(lambda email: tf.transform(email.split(" ")))
ham_features = ham.map(lambda email: tf.transform(email.split(" ")))
现在将 RDD 中的每个特征向量转换为 LabeledPoint 。因为这是一个二分类器,因此用 1 表示垃圾邮件,用 0 表示非垃圾邮件。 LabeledPoint 对象的第二个值将包含该特征。将这些 RDD 的并集作为训练数据集并缓存它,因为逻辑回归是一种迭代算法:
positive_examples = spam_features.map(lambda features: LabeledPoint(1, features))
negative_examples = ham_features.map(lambda features: LabeledPoint(0, features))
training = positive_examples.union(negative_examples)
training.cache()
现在使用 SGD 算法和训练数据运行逻辑回归:
model = LogisticRegressionWithSGD.train(training)
现在创建测试数据,包括应分类为垃圾邮件的文本内容,以及应分类为非垃圾邮件的文本内容。然后使用训练模型来预测测试数据是否被视为垃圾邮件。回想之前对 LabeledPoints 的设置,1 表示垃圾邮件,0 表示非垃圾邮件:
# 创建测试数据,测试模型
positive_test = tf.transform("Guaranteed to Lose 20 lbs in 10 days Try FREE!".split(" "))
negative_test = tf.transform("Hi, Mom, I'm learning all about Hadoop and Spark!".split(" "))
print "Prediction for positive test example: %g" % model.predict(positive_test)
print "Prediction for negative test example: %g" % model.predict(negative_test)
至此,就可以将预测结果与数据的分类进行比较,评估分类器模型的准确性,或者将该模型应用于未标记的数据集。MLlib 的分类算法针对大型监督训练数据进行了优化。因此,比起少而精,更多的数据通常会产生更好的效果。然而,分析数据并应用最合适的算法和评估方法仍然很重要。
3. 聚类
与协同过滤和分类算法不同,聚类利用无监督学习技术来构建模型。聚类算法尝试将数据集合组织成类似项目的分组,比如寻找具有相似特征或兴趣的客户群体,或将动植物按常见物种分组。聚类的目标是将数据分成多个簇,使每个簇内的数据彼此之间比与其他簇中的数据更相似。
Spark MLlib 提供了一些流行的聚类模型,但其中最简单也是最流行的聚类算法恐怕还得属 k-means。k-means 算法需要将所有对象表示为一组数值特征,并事先指定想要的目标簇数(k 个簇)。
MLlib 的 k-means 聚类的实现也从向量化数据集开始,将每个对象表示为 n 维空间中的特征向量,其中 n 用于描述要聚类的对象的所有特征的数量。算法首先在该向量空间随机选择 k 个点作为簇的初始中心或质心,然后将每个对象分配给最接近的质心,使用簇中所有点的坐标的平均值重新计算质心点,并根据需要将对象重新分配到最近的簇。分配对象和重新计算中心的过程不断重复,直到过程收敛,如下图所示。

聚类中最重要的问题就是确定如何量化要聚类的对象的相似度。加权方法可以从 TF-IDF 获得,这对于文本文档特别有用;另一种加权方法是通过数据中的其他自定义属性(使用计算指标衡量的平均占比)的函数来确定(例如基于以美元为单位的总购买金额划分顾客)。对于 MLlib 的 k-means 聚类的输入,需要指出对特征向量使用的加权方法。例如,如果确定要根据总购买金额、平均购买频率和每次平均购买金额这三个特征对所有客户进行聚类,那么客户样本可能如下表所示:
| 姓名 | 总购买金额(美元) | 每月平均购买次数 | 每次平均购买金额 | 特征向量 |
|---|---|---|---|---|
| Jane | 825 | 5 | 115 | [825,5,115] |
| Bob | 201 | 1 | 45 | [201,1,45] |
| Emma | 649 | 2 | 65 | [649,2,65] |
有多个特征时一定要注意,维度值是以不同单位表示的,或者尚未进行归一化。如果使用简单的、基于距离的指标来确定这些向量之间的相似性,总购买金额将主导结果。通过给不同的维度加权,可以解决这个问题。
示例:一个k-means聚类
在这个例子中,我们将应用 k-means 聚类算法来确定截至今年美国哪些区域发生地震的次数最多。用到的 CSV 文件的列如下所示:
- time
- latitude
- longitude
- depth
- magnitude
- magnitudeType
- nst
- gap
- dmin
- rms
- net
- jd
- updated
- place
从这些记录中提取纬度(latitude)和经度(longitude),并用其训练模型。在这个迭代过程中,我们将尝试生成 6 个簇。完整的程序可以使用以下命令运行:
$ $SPARK_HOME/bin/spark-submit \
/home/hadoop/hadoop-fundamentals/mllib/clustering/earthquakes_clustering.py \
/home/hadoop/hadoop-fundamentals/data/earthquakes.csv \
6 > clusters.txt
首先,配置 Spark 并创建 SparkContext:
# 配置Spark
conf = SparkConf().setMaster("local") \
.setAppName("Earthquake Clustering") \
.set("spark.executor.memory", "2g")
sc = SparkContext(conf=conf)
接下来,从地震数据文件创建训练 RDD,解析每一行的纬度和经度,并将其转化为一个NumPy 数组:
# 创建用于训练的(lat, long) RDD向量
earthquakes_file = sys.argv[1]
training = sc.textFile(earthquakes_file).map(parse_vector)
使用第二个参数设置 k 个簇,在本示例中为 6:
k = int(sys.argv[2])
调用 KMeans.train() ,将训练集和 k(设置为 6)传递给它。这将生成模型,我们也可以访问簇的中心:
# 基于训练数据和k-clusters训练模型
model = KMeans.train(training, k)
print "Earthquake cluster centers: " + str(model.clusterCenters)
sc.stop()
如果检查输出的 clusters.txt 文件,就会看到类似如下的输出:
Earthquake cluster centers: [array([ 38.63343185, -119.22434212]),
array([ 13.9684592 , 142.97677391]),
array([ 61.00245376, -152.27632577]),
array([ 35.74366346, 27.33590769]),
array([ 10.8458037, -158.656725 ]),
array([ 23.48432962, -82.3864285 ])]
现在,就可以根据训练数据绘制结果输出,对结果执行“眼球”评估,并通过优化簇数(k)和迭代次数来调整簇中心了。为了获取更精确的评估指标,还可以计算“集内平方误差的总和”(Within Set Sum of Squared Errors),它衡量每个中心点周围簇点的紧凑度:
def error(point):
center = model.centers[model.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
WSSSE = training.map(lambda point: error(point)).reduce(lambda x, y: x + y)
print("Within Set Sum of Squared Error = " + str(WSSSE))
十三、总结:分布式数据科学实战
这一章对以上各章讨论过的工作流进行总结,并对数据科学进行全面回顾。
通过以上章节,我们领略了 Hadoop 生态系统的具体组成部分。先是讨论了如何与集群进行交互以及如何使用集群。如前所述,Hadoop 是一种分布式计算的操作系统;和本地计算机上提供文件系统和进程管理的操作系统一样,Hadoop 通过 HDFS 以及 YARN 形式的资源和调度框架提供分布式数据存储和访问。HDFS 和 YARN 一起构成了一种在极大数据集上进行分布式分析的机制。
编写分布式作业的原始方法是使用 MapReduce 框架,它让你能指定 mapper 和 reducer 任务。将这些任务链接在一起,可以进行更庞大的计算。由于 Python 是数据科学最流行的工具之一,所以我们专门探讨了如何通过 Hadoop Streaming 执行使用 Python 脚本的 MapReduce 作业。我们还探索了一种更纯粹的解决方案:使用 Spark 的 Python API 在使用了 YARN 的 Hadoop 集群中执行 Spark 作业。最后,介绍了在集群上常用的分布式分析和设计模式,结束了对低级工具的讨论。
接下来我们从低级编程细节完全转移到了数据挖掘、数据采集、数据流和机器学习所用的高级工具上。这一部分主要针对通过 Hadoop 的各种现有工具进行分布式数据分析的日常情形,以及如何根据大数据流水线(数据采集、数据整理 /staging、计算和分析、工作流管理)组织这些工具。
数据产品是构建的消费品(不一定完全是软件),它从数据中获取价值并生成新数据。要实现该定义,必然需要应用机器学习技术。数据驱动的应用程序只是使用数据的应用程序(包括每个软件产品),例如博客、网上银行、电子商务等。即使数据驱动的应用程序从数据中获取了价值,它也不一定会生成新的数据。
本章将详细介绍如何使用我们前面讨论过的所有工具来构建数据产品,并在此过程中,回答如何将分布式计算的低级操作和高级生态系统工具拟合在一起。希望通过将整个数据产品和机器学习生命周期进行语境化,你能更轻松地识别和了解对工作流至关重要的工具和技术。
1. 数据产品生命周期
构建数据产品需要建立和维护活动的数据工程流水线。流水线包括采集、整理、仓储、计算和探索性分析等多个步骤,这些步骤一同构成了数据工作流管理系统。它的主要目标是建立和实施拟合的(经过训练的)模型,其核心过程包括提取、转换和加载(ETL)过程——从应用程序上下文中提取数据,将其加载到 Hadoop 中,在 Hadoop 集群中处理数据,然后将数据 ETL 回应用程序。如下图所示,可以将这个简单的流程图看作是一个活动的或者常规的生命周期。在这个周期内,通过新的数据和交互,为用户调整和使用机器学习模型。
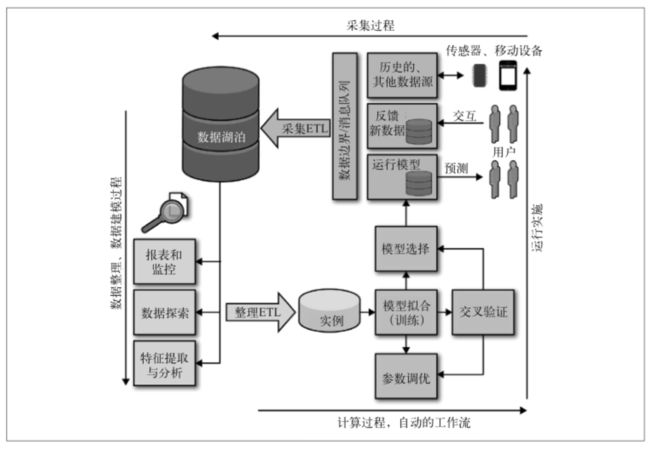
如果想充分运用机器学习算法,数据产品生命周期就需要使用大数据分析和 Hadoop。拥有大量用户的应用程序必然将产生大量数据。尽管通过 128GB 内存和多个内核的强大服务器进行有效的抽样和分析后,这些数据可以被处理,但数据的多样和高速才是需要 Hadoop 和基于集群的方法的灵活性的主要原因。
灵活性确实是基于集群的系统的关键。Web 日志记录(点击流式数据)、用户交互和流式数据集(例如传感器数据)形式的输入数据源源不断地涌入应用程序。这些数据源被写入各处,比如日志文件、NoSQL 数据库,以及 Web API 后端的关系数据库。此外,来自网络爬取、数据服务和 API、调查及其他业务来源的数据等信息也不断被生成。这些额外的数据必须与现有应用程序数据被一道分析,从而确定能改进数据产品模型的特征是否存在。
因此,数据产品生命周期通常围绕一个或多个中心数据存储。数据存储极其灵活,没有约束(不像关系数据库中存在约束),但持久性强。这样的中心数据存储是 WORM 系统,即“写一次,读多次”,是向下游分析提供可靠数据的关键所在,支持历史分析和可重复的 ETL 生成(这对科学至关重要)。WORM 存储系统对数据科学非常重要,它们也因此收获了一个新名字——数据湖泊。
数据湖泊
传统上,我们会使用数据仓库模型来执行业务环境中的常规聚合分析。数据仓库是关系数据库的扩展,通常将数据规一化为星型模式——将多个维表连接到一个中心事实表(所以关系图看起来像星型)的模式。事务通常发生在维表上,它们的解耦使组织的各个方面在读写上有了一些性能优势。ETL 过程通过一个大连接构建“数据(超)立方”来加载事实表,我们可以在数据立方上应用枢纽分析(pivot)和其他分析方法。
为了有效利用传统的数据仓库,必须先设计一个清晰的模式,经历冗长周期的 ETL 过程,完成数据库管理、数据转换和加载后,才可以分析数据。不幸的是,当你将数据产品视为需要新数据和新数据源的、有生命的、活动的引擎时,这种传统的数据分析模型可能既费时又有限制。对应用程序的简单改动(例如新的历史数据源,或新的日志记录和提取技术)就可能改变数据立方的结构,需要重新设计星型模式的范式。这种结构调整不仅费时费力,而且还迫使我们作出一个业务决策:是否值得为这些数据增加机器,来处理新的数据量?
我们知道所有数据至少有潜在价值,但却很难回答数据价值及其相对成本效益的问题。因此,许多公司不仅在数据仓库上有所投入,而且还开发数据湖泊作为主要的数据收集和同步策略。
数据湖泊支持从各种源(结构化和非结构化的)中流入未处理的原始数据,它将整个数据集合存储在一起,无须太多的组织,如下图所示。结构化数据可以从关系数据库、结构化文件(如 XML 或 JSON)和符号分隔文件(如日志文件)中获取,并且通常以基于文本的格式或某种类型的序列化二进制格式(如 SequenceFiles、Avro 或 Parquet)加载到系统。
半结构化和非结构化数据包括传感器数据、二进制数据(如图像)和不是面向记录而是面向文档的文本文件(如电子邮件)。数据湖泊模式允许任何类型的数据自由流入存储,然后通过在处理时施加所需模式的 ETL 过程流出。根据分析需求进行提取和转换后,数据被加载到一个或多个数据仓库进行例行分析或紧急分析。数据湖泊模式提供了在线访问整套原始的源格式数据的功能,并将模式定义延迟到处理时,让公司能在需求变化时敏捷地执行新的处理和分析。

HDFS 是 Hadoop 的默认文件系统,也是构建数据湖泊非常有效的方式。HDFS 将数据分发到许多机器,支持用许多小容量的硬盘存储数据;同时,使数据可用于分布式框架中的计算,而不会产生存储区域网络(storage area network,SAN)的网络流量。此外,HDFS 会复制数据块,提供持久性和容错性,确保数据不会丢失。NameNode 以分层文件系统的形式组织数据命名空间,而不设计每个字段数据的模式。
与其使用负载过重又容量有限的单个主数据仓库,还不如将数据存储在 HDFS 数据湖泊中,通过 MapReduce 或 Spark 作业进行灵活分析,然后被提取并加载到目标系统中,例如需要特定类型分析的业务部门的企业数据仓库。此外,通常可以将在磁带上存档的、无法分析的旧历史数据转移到 Hadoop 上,进行探索性分析。如此看来,Hadoop 可以减轻传统数据仓库的沉重维护负担、突破后者在可扩展性上的限制,甚至补充了现有的数据仓库架构,如下图所示:

数据采集
深入了解数据产品生命周期的中心对象——数据湖泊之后,就可以将注意力转移到数据采集和数据仓储,以及数据科学家通常如何看待这些流程了。首先从数据采集开始。一般来说,大多数数据采集从应用程序上下文获取数据,也就是和用户交互的软件产品的业务单元,或者实时收集信息的逻辑单元。例如,一个规模可观的电子商务平台可能有一个只处理客户评论的软件应用程序,和一个只收集用于安全和日志的网络流量信息的单元。这两个数据源对于异常检测(欺诈)或推荐系统等数据产品非常有价值,但必须分别采集进入数据湖泊。本节将介绍 Sqoop 和 Flume 这两种工具,它们都支持这两种上下文采集。
Sqoop 可以利用 JDBC(Java database connector)库连接到任何关系数据库系统,并将其导出到 HDFS。关系数据库几乎是目前所有 Web 应用程序和串行(非分布式)分析的后端服务器。由于关系数据库是小规模分析的着力点,在 Web 应用程序中无处不在,因此 Sqoop
是将数据从大多数大型数据源提取到 HDFS 中的重要工具。此外,由于 Sqoop 从关系上下文中提取数据,因此只要稍作整理,确保主键在数据库之间保持一致,Hive 和 SparkSQL 几乎可以马上使用从这些数据源采集的数据。在我们的示例中,Sqoop 是提取存储在关系数据库中的客户评价数据的理想工具。
另一方面,Flume 是用于采集日志记录的工具,但也可以从任何 HTTP 源中采集。Sqoop 用于结构化数据,而 Flume 主要用于非结构化数据,例如包含网络流量数据的日志。日志记录一般被认为是半结构化的,因为它们是需要解析的文本,但通常每一行都拥有相同的标准格式。Flume 还可以从 Web 请求中采集 HTML、XML、CSV 或 JSON 数据,因此能行之有效地处理特定的半结构化数据和非结构化数据的包装数据,如评论、评价或其他文本数据。因为 Flume 比 Sqoop 更通用,因此它不一定与下游数据仓储产品保持一致,并且一般要求采集过程和分析之间有 ETL 机制。
我们没有讨论消息队列服务。例如,Kafka 是一种分布式队列系统,可在现实世界、数据系统中的应用程序、数据湖泊三者之间创建数据边界。请求数据可以放在 Kafka 队列中,然后按需采集,而无须用户向应用程序发送请求数据,然后采集到 Hadoop 中。消息队列使得数据采集过程变得更加实时,或者至少变成了一次处理一小片,而不是像 Sqoop 那样进行大批量作业。
然而,为了获取实时数据源,还需要其他工具来处理流式数据。流式数据是指在线不断进入系统的无界的、可能无序的数据。Twitter 的 Storm(现在的 Heron)、MillWheel 和 Timely 等工具支持分布式的、容错的实时数据集处理。这些工具可以在 YARN 上运行,并在处理结束时将 HDFS 作为存储工具。与之类似,Spark Streaming 提供了流式数据集的微批次分析,允许以固定的间隔(例如每秒)将记录收集成一个批次,并一次性分析或使用它们。
许多现代分析架构将这些采集和处理工具组合,使其同时支持批处理和流式任务,这也被称为 lambda 架构,如下图所示:

当你将这些工具作为一个整体考虑时,可以清楚地看到,从直接将数据馈入数据仓储以进行分析的大规模批处理,到需要 ETL 和处理才能进行大规模分析的实时流中有一种连续性。至于具体采用哪种处理方式,主要由数据的具体速度和及时性(立即或在特定时间限制内完成分析)或完整性(近似与精确)共同决定。
计算数据存储
随着我们不断接近数据产品生命周期中更正式的仓储和分析阶段,分布式存储的需求被再一次唤醒。正如之前讨论的,通过将 Hadoop 作为数据湖泊来存储未处理的原始数据,我们可以获得相当灵活、敏捷的分析能力。然而,在很多使用场景中,结构和顺序也是必需的,在数据仓储中尤其如此——数据希望驻留在共享存储库中,维度模式为分析任务提供更简单、经过优化的查询。对于这些类型的应用程序,仅仅使用 HDFS 的文件系统接口与作为文件集合的数据进行交互是不够的;我们需要一个更高层次的接口,可以原生地理解 SQL 的结构化表语义。
关系方法:Hive
Hive 是 Hadoop 中执行数据仓储任务的主要方法。Hive 项目包括许多组件,比如 Hive Metastore、Hive 驱动程序和执行引擎、Hive Metastore 服务和 HCatalog。其中,Hive Metastore 作为 HDFS 之上的存储管理器,存储元数据(数据库 / 表实体、列名称、类型等);Hive 驱动程序和执行引擎将 SQL 查询编译成 MapReduce 或 Spark 作业;Hive Metastore 服务和 HCatalog 使其他 Hadoop 生态系统工具能与 Hive Metastore 进行交互。还有许多其他分布式的 SQL 或 SQL-on-Hadoop 技术,它们是 Impala、Presto、Hive on Tez,等等。上述所有组件其实可以直接与 Hive Metastore 交互,或通过HCatalog 与它交互。解决方案的选择应由数据仓储和性能要求决定,但 Hive 通常是耗时长、需要容错的查询的好选择。
在 HDFS 和 Hive 中存储数据时,一定要考虑如何以有意义且有效的方式对数据进行分区。要存储到 Hive 的话,确定分区策略时应该考虑在查询数据集时最常应用的谓词。例如,如果要分析 WHERE year = 2015或 WHERE updated > 2016-03-15形式的 WHERE 子句,很明显,按日期过滤记录将是一个重要的访问模式,因此可以按天(例如 2016-03-01)将数据分区。这让 Hive 能只读取所需的特定分区,从而减少 I/O 量并显著缩短查询时间。
不幸的是,大多数 SQL 查询都非常复杂,针对分析使用的各种谓词可能会导致大量不同的分区。这要么导致数据极度碎片化,要么会降低数据存储的灵活性。除了对分布式数据执行复杂查询之外,还有第二个选择——在主要转换和过滤之后,使用 Sqoop 将数据从Hadoop 采集出来,然后存入关系数据库中,以便能更直接地应用正常报告或 Tableau 可视化。因此,了解数据如何从许多较小的系统,流入较大的数据湖泊系统,再流回到较小的系统,是数据仓储的关键所在。
NoSQL方法:HBase
这里讨论的数据仓储的非关系选项是 HBase,一个列式的 NoSQL 数据库。列式数据库是 OLAP(online analytical processing,联机分析处理)类数据库访问的主力军。这类访问通常扫描大多数或所有数据库表,但只选择可用列的一部分。思考这样一个问题:每个地区每周有多少订单?这个订单表查询需要两列,分别是地区和订单日期。列式数据库只将这两列以紧凑、压缩的格式流入计算,而不采取每张表都逐行扫描(包括不需要的连接和列)的面向行的方法。因此,列式(也被称为以顶点为中心)计算为这些类型的聚合带来了巨大的性能提升。
在考虑使用哪种非关系工具和 NoSQL 数据库时,通常会有特定的要求帮你作出选择。例如,如果查询需要快速查找一个值,则应考虑键 / 值存储;如果数据访问需求涉及稀疏数据的行级写入,并且分析主要关注聚合,那么 HBase 是很好的备选工具;如果数据是实体(顶点)之间有许多关系(边)的图,则应考虑 Titan 这样的图数据库;如果你正在使用传感器或时间序列数据,那么应该考虑 InfluxDB 这样的原生了解时间序列数据的数据库。
NoSQL 数据库的数量令人惊讶,这是因为它们通常都只针对特定的使用场景进行优化。在大多数情况下,这些数据存储后端是更大、更复杂的分布式存储和计算架构的一部分。
2. 机器学习生命周期
前面我们探索了分解数据集的抽样技术,将样本放在单个计算机上,然后使用 Scikit-Learn 来生成模型。可以序列化模型并通过分布式方法使用整个数据集对模型进行交叉验证。一般来说,这是一种非常有效的技术,被称为“最后一英里计算”。它使用 MapReduce 或 Spark 过滤、聚合或汇总数据,使数据可以加载到单个计算机的内存(例如 64GB)中,并能通过更容易获得的技术计算。此外,这也是执行没有分布式实现的计算或分析的唯一方法。
上一章探讨了如何使用 SparkML 库在分布式环境中执行分类、回归和聚类。过去,大数据机器学习依赖于 Mahout 库和图分析库(例如 Pregel);而现在,SparkML 和 GraphX 库被广泛应用于分析上下文中。在一定程度上,将强大工具转换为分布式形式的趋势已经出现;但在其他情况下,分布式算法的出现比单进程版本还要早。
鉴于之前已经定义了数据产品,所以希望大家明确一点:本博客讨论的所有数据管理技术都是趋向机器学习的,以特征工程的形式为主。特征工程是分析创建决策空间的过程;也就是为了创建一个有效的模型,需要什么维度(列或字段)? 其实这个过程是数据科学家的主要工作;数据产品的最终目标是如何使用前面章节讨论的工具,而如何设计或开发它们。
因此,了解清楚机器学习算法在期望什么,可能比直接讨论机器学习更有用。几乎所有机器学习算法都在单个实例表上运行,每一行都是学习的实例,每一列都是决策空间中的一个维度。这对在数据产品生命周期中如何选择工具有很大影响。
在关系上下文中,这意味着数据集必须在分析之前去规一化(例如将多个表连接成一个表)。这可能会给系统带来冗余数据,但这正是算法所需要的。几乎所有机器学习系统都是迭代的,这意味着系统会多次处理数据。在大数据环境中,这将导致大量开销,因此我们会使用 Spark 替代 MapReduce 来进行机器学习——Spark 将数据保存在内存中,加快每次处理的速度。
去规一化、冗余和迭代算法也对数据生命周期有影响。如果我们经常生成单个表,那么就必须问问自己,为什么最初要从数据湖泊中规一化数据。难道就不能简单地将非规一化数据直接发送到机器学习模型中吗?在实践中,Hadoop 中的模式设计高度依赖于具体的分析过程或机器学习模型的输入需求。在许多情况下,可能有多个差异很小的数据模式需求,例如所需的分区或分桶模式。虽然使用不同的物理结构存储相同的数据集通常在传统数据仓库中被认为是一种反模式,但这种方法在 Hadoop 中是有意义的——数据针对一次写入优化,存储重复数据的开销也很小。
考虑过机器学习构建阶段的数据存储后,第二件要思考的事是如何将模型从数据产品生命周期转移到生产中,以便将其用于识别模式、作出预测或适应用户行为!模型拟合数据,从而广泛应用于新的输入数据。拟合过程通常会产生一些模型的表示,可用于预测。例如,如果你使用朴素贝叶斯模型系列,那么拟合模型实际上是一组概率。通过这些概率中包含的实例特征的概率,我们可以计算类别的条件概率。如果你使用线性模型,那么拟合模型表示的是一组系数和一个截距,截距与自变量(特征)的线性组合产生一个因变量(目标)。
无论如何,这种表示必须从系统中导出才能运行和评估。线性模型的表示非常小,只是一组系数而已。贝叶斯模型的拟合模型可能更大一点——它是系统中每个特征和类的一组概率,因此模型表示的大小与特性数量直接相关。随机森林是多个决策树的集合,使用基于规则的方法分割决策空间。虽然每个决策树只是一个较小的树状数据结构,但是在大数据环境中,决策空间可能又大又复杂,随机森林中决策树的数量也可能带来存储问题。模型表示越来越大,一直到 k 最近邻方法——它需要存储每个用于距离计算的训练实例来作出决策。
到目前为止,我们已经知道了导出拟合模型的两个主要机制:使用 Python 和 Scikit-Learn 序列化数据和将 Spark 模型写回 HDFS。但如果模型表示管理过程是数据产品生命周期的一部分,你会发现其他分析任务(规范化、删除重复数据、抽样等)也很有必要。
3. 总结
大数据科学就是使用分布式计算技术进行描述性分析和推断性分析,希望这些需要分布式计算的数据的数量、多样性和速度将带来更深入或更有针对性的见解。此外,数据科学的产出是数据产品——从数据中获取价值并生成新数据的产品。因此,各种生态系统工具的集成通常围绕数据产品生命周期进行架构。
数据产品生命周期中有一个内部机器学习生命周期,它又包含两个主要阶段:构建阶段和运行阶段。构建阶段需要特征分析和数据探索;运行阶段旨在将产品的数据生成方面暴露给与数据产品交互的真实用户,生成可用于调整模型的数据,使模型更准确或更通用。通过提供数据采集、数据整理、数据探索和计算框架,数据产品生命周期提供了构建和运行模型的工作流。大多数生产架构结合了人工(由数据科学家驱动计算)分析和自动数据处理工作流,这些工作流由 Hadoop 技术生态系统提供和管理。