主题论文总结1:structured text summarization(持续更新ing...)
诸神缄默不语-个人CSDN博文目录
最近更新时间:2022.6.4
最早更新时间:2022.5.16
文章目录
- 1. 对structured text summarization这一概念的定义
- 2. 典型任务类型
- 3. 训练集和测试集的原文和摘要都具有显式structure标签
- 4. 原文为显式structure,摘要为隐式structure。训练集原文有标签,测试集没有。摘要无标签
- 5. 原文和摘要都有显式structure。数据不自带标签
- 6. 原文训练集有显式structure,测试集没有。摘要没有structure
- 7. 原文训练集有显式structure,测试集没有。摘要有显式structure
- 8. 原文训练集和测试集都有显式structure,摘要没有
- 9. 原文训练集有隐式摘要,测试集没有。摘要有显式结构
- 10. 原文没有结构,摘要有显式structure
- 11. 一种不知道算什么总之差不多所以放到一起的aspect-based summarization
- 12. 单篇文档具有一个主题或者一个主题分布,因此不算结构化文本摘要任务,但是具有跟结构化文本摘要任务中相同的主题概念;或者具有结构概念或其他类似于结构化摘要任务的概念,因此光看名字易产生混淆,但事实上不是的
- 12. 没仔细看,所以没有列出
- 13. 可能相关,我还没看
1. 对structured text summarization这一概念的定义
此处的structure指将文本分割为不同的结构,将文本分为不同的部分(如论文将文本分为introduction、related work等部分)。可能是原文和摘要都有分割,也可能只有一方分割。这种分割可能是显式的,也可能是隐式的(“软的”)(可能是将section表示为一个多section的向量,也可能是section转移概率)。对这个“部分”的措辞可能是section、part、topic。本文将主要使用section这一名词,此外也会使用各论文自己使用的名词。
structured text summarization主要范式:
- 直接用全文对全文进行摘要生成(不使用文本结构。本文不考虑这种情况的论文)
- 用对应section的原文生成对应section的文本(也被称为divide-and-conquer范式,这一说法出自A Divide-and-Conquer Approach to the Summarization of Long Documents.)
- 使用全部原文作为上下文信息,用特定section的表征生成对应section文本
- 使用全部原文作为上下文信息,用特定section原文输入生成对应section文本
- 用section信息来做attention、鼓励出现或coverage等辅助任务,来生成对应section
- 将section表示为section segmentation embedding,作为额外的输入传入模型
原数据集没有section信息,需要生成section信息的常见范式:
- 显式分割:直接对文本进行sequence classification
- 隐式分割:作为中间变量直接产生一个向量,可能是人不可读的
注意:以下所说数据自带标签,可能是以某种无监督方式自动获取的标签,而非原始数据集就有的人工标注数据。这种情况我会在该论文部分说明。
以下论文以表格形式更简洁的呈现:
本来我在这里放的是一个Markdown表格,但是效果太差了,所以我现在直接给出石墨文档公开分享链接:structured text summarization
hierarchical document structure大概就是一篇文档的结构信息,包括文本元素、图表结构等1
这篇论文我觉得可能有助于我更加深刻地定义这一主题,但是他妈的有50页,而且我连摘要都没太看懂,总之是定义了文档结构,但是具体细节之理解于我而言我觉得可能需要亿点点语言学的知识,我先行放弃,以后再回来参战:Document Structure
2. 典型任务类型
- 维基百科生成:通过海量网页文本数据,生成维基百科内容,属于multi-document summarization。因为维基百科是自带section的,所以有些维基百科生成的论文就是分section来做的。
- 生成维基百科摘要:Re5:读论文 TWAG: A Topic-guided Wikipedia Abstract Generator
- 生成维基百科文章
- Automatically Generating Wikipedia Articles: A Structure-Aware Approach
- WikiAsp: A Dataset for Multi-domain Aspect-based Summarization
- Surfer100: Generating Surveys From Web Resources on Wikipedia-style
- 论文摘要:论文本身就是分成一个一个section的
Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents
Surveyor: A System for Generating Coherent Survey Articles for Scientific Topics
Generating a Structured Summary of Numerous Academic Papers: Dataset and Method:2022IJCAI论文,还没发出来 - 会议/对话摘要:对话内容往往围绕主题展开
- Topic-aware Pointer-Generator Networks for Summarizing Spoken Conversations
- How to Interact and Change? Abstractive Dialogue Summarization with Dialogue Act Weight and Topic Change Info
- Improving Abstractive Dialogue Summarization with Hierarchical Pretraining and Topic Segment
- Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
- Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders
- Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization
- Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
- Extracting Decisions from Multi-Party Dialogue Using Directed Graphical Models and Semantic Similarity
- Automatic analysis of multiparty meetings
- Improving Abstractive Dialogue Summarization with Graph Structures and Topic Words
- Dr.Summarize: Global Summarization of Medical Dialogue by Exploiting Local Structures
- A Finer-grain Universal Dialogue Semantic Structures based Model For Abstractive Dialogue Summarization
- Situation-Based Multiparticipant Chat Summarization: a Concept, an Exploration-Annotation Tool and an Example Collection
- 会议摘要
- Automatic meeting summarization and topic detection system
- Keep Meeting Summaries on Topic: Abstractive Multi-Modal Meeting Summarization
- Incremental temporal summarization in multiparty meetings
- 新闻摘要
- Inducing Document Structure for Aspect-based Summarization
- ASPECTNEWS: Aspect-Oriented Summarization of News Documents
- Detecting (Un)Important Content for Single-Document News Summarization
- Abstractive News Summarization based on Event Semantic Link Network
- NEWS: News Event Walker and Summarizer
- News Text Summarization Based on Multi-Feature and Fuzzy Logic
- End-to-End Segmentation-based News Summarization
- 电商:商品描述信息或评论的摘要生成
- CUSTOM: Aspect-Oriented Product Summarization for E-Commerce
- Extractive Opinion Summarization in Quantized Transformer Spaces
- Mining and summarizing customer reviews.
- Movie review mining and summarization
- A joint model of text and aspect ratings for sentiment summarization.
- Rated aspect summarization of short comments
- Aspect-based sentence segmentation for sentiment summarization
- Aspect-Aware Multimodal Summarization for Chinese E-Commerce Products
- Summarizing Opinions: Aspect Extraction Meets Sentiment Prediction and They Are Both Weakly Supervised
- Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
- Mining Opinion Features in Customer Reviews
- Comprehensive Review of Opinion Summarization
- A Hybrid Approach to Multi-document Summarization of Opinions in Reviews
- Modeling content and structure for abstractive review summarization
- Aspect and Sentiment Aware Abstractive Review Summarization
- topic-focused summarization / aspect-based summarization:根据全文和特定topic的信息,产生特定topic的摘要(用aspect来表示这个structure粒度的就叫aspect-based summarization,也划分为这一类)
- Overview of duc 2005.
- Overview of duc 2006.
- Measuring Importance and Query Relevance in Topic-focused Multi-document Summarization
- Beyond sumbasic: Task-focused summarization with sentence simplification and lexical expansion.
- Manifold-Ranking Based Topic-Focused Multi-Document Summarization
- Using only cross-document relationships for both generic and topic-focused multi-document summarizations
- Graph-based multi-modality learning for topic-focused multidocument summarization
- Diversity driven attention model for query-based abstractive summarization
- Summary Cloze: A New Task for Content Selection in Topic-Focused Summarization
- Rewards with Negative Examples for Reinforced Topic-Focused Abstractive Summarization
- Unsupervised Abstractive Opinion Summarization by Generating Sentences with Tree-Structured Topic Guidance
- Generating Topic-Oriented Summaries Using Neural Attention
- Inducing Document Structure for Aspect-based Summarization
- WikiAsp: A Dataset for Multi-domain Aspect-based Summarization
- Summarizing Text on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach
- CUSTOM: Aspect-Oriented Product Summarization for E-Commerce
- Aspect-Controllable Opinion Summarization
- Extractive Opinion Summarization in Quantized Transformer Spaces
- Mining and summarizing customer reviews.
- Movie review mining and summarization
- A joint model of text and aspect ratings for sentiment summarization.
- Rated aspect summarization of short comments
- Aspect-based sentence segmentation for sentiment summarization:讲的是在句子里分single-aspect and single-polarity的单元们,任务是aspect-based sentence segmentation
- ASPECTNEWS: Aspect-Oriented Summarization of News Documents
- Mining Opinion Features in Customer Reviews
- A Hybrid Approach to Multi-document Summarization of Opinions in Reviews:虽然也是关于aspect那一挂的,但是每个review输入就是一个
- Modeling content and structure for abstractive review summarization
- conditional text generation:感觉本博文列出的大多数论文都能算这一类。更多论文可参考 Conditional Text Generation | Papers With Code
3. 训练集和测试集的原文和摘要都具有显式structure标签
- Automatically Generating Wikipedia Articles: A Structure-Aware Approach:任务是生成维基百科文章(从网上直接抓取的信息中生成综合性的textual overview)。
原文的获取过程是:首先有百科标题,然后根据topic来从网上爬取信息,通过这些信息来生成文章。因此这些信息都自带topic。
摘要也有划分(就是维基百科的小标题),如果验证集上没有自动划分则通过文中给出的划分方式来先行划分,即用一些传统的统计学方法区分句子的主题/section(同样的数据分布等传统特征),select relevant material for an article using a domain-specific automatically generated content template(template包含一些词,就是类似维基百科section标题的那种东西)。
分topic用各自的原文生成各自的摘要,最后合并到一起组合为总的摘要。
大致的摘要生成方式是通过传统统计学方法来实现原文的排序、抽取。第一步:首先对每个domain建立一个template(automatic template creation),这个template是通过训练集摘要聚类得到的,形式是所有小标题(topic)。第二步:对每个小标题从原文中对应的topic里选择句子:用了perceptron algorithm、ILP之类的东西。用很多手动抽取的特征,来排序、打分excerpts,然后合并。具体的训练方法还没有看(Joint parameter estimation for content selection),看讲解博文说类似自制的反向传播算法。大致来说是对文档里面的excerpt进行打分,排序,然后返回表示向量。
同时学习关于主题的内容选择和模板生成(用人工撰写的文本的high-level的结构,对新的overview的topic structure自动生成domain-specific template),用a global integer linear programming formulation增强standard perceptron algorithm,以优化both local fit of information into each topic和global coherence across the entire overview。topic-specific extractors:用于content selection jointly across the entire template(单个:分类任务)(互相依赖。同时学可以explicitly model these inter-topic connections)
content planning是啥我没看懂。
算法步骤:
①预处理,生成模板,从互联网上找candidate excerpts(小标题聚类,用类的代表性的标题来做最终标题)(搜索:用的是title+topic)
②在训练数据上训练content selection algorithm的参数(选excerpt)
③选candidate excerpts然后合并
介绍了structured classification的参考文献。
文中所给例子的维百网页版本:3-M syndrome - Wikipedia
这篇文章的参考笔记博文:
①Automatically generating wikipedia articles: A structure-aware approach笔记_涂卡的博客-CSDN博客
②研一一年论文总结(下) | Glacier’s Blog - Topic-aware Pointer-Generator Networks for Summarizing Spoken Conversations:任务是对话摘要。
原文上的结构是用rule-based lexical algorithm然后用人工验证得到的,摘要自带结构。认为话题转换有个概率。
做法是取hidden state在topic划分边界token上的embedding。感觉类似于用topic作为一个粒度来做pooling(类似于我认为BertSum2是用句作为粒度来做pooling这种理解) - Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents:任务是科学文献摘要,提出FacetSum数据集。
文中给出的baseline使用原文中的小标题或原文中的所有文本,来分别训练每个section的摘要生成模型。效果最好的baseline就是用Bart以全文为输入、分别预测每一个section的摘要训练出来的模型。 - CUSTOM: Aspect-Oriented Product Summarization for E-Commerce:aspect-based summarization(比较离谱的是这篇论文的GitHub项目链接是404,论文通讯作者的邮箱也不存在,我给论文的一作发邮件去问了)
输入是a product with substantial product information and a set of corresponding aspects for this category,生成产品描述。
先抽取后生成范式(extraction-enhanced generation framework)。抽取的是与aspect相关的原文。
EXT框架
①extractor:找原文中与对应aspect最相关的句子(模型使用heuristic rule、以最长子字符串的overlap rate大于特定阈值作为标准得到的)。用交叉熵损失函数。
②generator:seq2seq+attention:encoder阶段用extractor计算得分来计算word层面的attention。
EXT+PGN输入: word embedding和aspect embedding直接相加。
EXT+UniLM输入:把三个嵌入(word embedding, position embedding,
and segment embedding)加起来,然后用transformer隐藏层表示向量作为句子表征。 - End-to-End Segmentation-based News Summarization

- Semantic Self-segmentation for Abstractive Summarization of Long Legal Documents in Low-resource Regimes:任务是法律文书摘要。
原文分割为语义连续chunks,每句摘要都与最相关的chunk匹配。
4. 原文为显式structure,摘要为隐式structure。训练集原文有标签,测试集没有。摘要无标签
- Re5:读论文 TWAG: A Topic-guided Wikipedia Abstract Generator:任务是生成维基百科摘要。
使用训练集原文标签训练段落分类模型,以在测试集上分类topic。逐句生成摘要,在生成每一句摘要之前预测该句摘要所属topic(测试了硬topic和软topic的做法,最后发现软topic下效果更好)。
5. 原文和摘要都有显式structure。数据不自带标签
- Automatic meeting summarization and topic detection system:任务是会议摘要生成(原文是会议内容语音转文字)和会议原文中的topic发现。
这篇论文写得奇烂无比,希望作者不要因为我说了这句话来告我。
原文是用LDA和TextTiling先将原文进行分块(先找出边界,然后找出每一块对应的topic),然后对每一块学出topic。总之是一些传统统计学的方法。(在文中提及了2种主流的划分原文的方式:①hierarchical:Yaari (1997) developed agglomerative clustering approaches with cosine similarity(全文相似度,划分粗且不准确)②linear text segmentation:TextTiling算法segments text in linear time by calculating the similarity between two blocks of words based on the cosine similarity (Hearst, 1997))
用基于特征的方法TextTeaser来进行抽取式摘要。摘要是经由segmented summary合成的。 - Topic Modeling Based Extractive Text Summarization
烂刊3出烂文了属于是。
基于latent topics(用topic modeling techniques得到)(LDA)聚类,然后对每一类生成抽取式摘要(sub-summaries)。生成结果是多个主题的生成结果的合并。
它用的是WikiHow数据集,是有123这种显式顺序的,但是没有用这个,而是用自己学的主题。
6. 原文训练集有显式structure,测试集没有。摘要没有structure
- Keep Meeting Summaries on Topic: Abstractive Multi-Modal Meeting Summarization:任务是会议摘要,考虑到了多模态数据(文本+音视频)。
topic的组成单位是utterance。
topic segmentation and summarization是同时训练的:用transcript embeeding的一部分维度过Topic Segmentation Decoder得到topic segmentation,然后用它和transcript embeeding一起通过multi-modal hierarchical attention生成摘要。
multi-modal hierarchical attention机制,三层(topic segment, utterance and word)。
除传统文本特征外,还用了visual focus of attention VFOA中得到的多模态特征(假设受attention越多的utterance越重要)(这个attention就是由多模态来获得,应该是原数据就有的内容)。 - Summarizing Opinions: Aspect Extraction Meets Sentiment Prediction and They Are Both Weakly Supervised:同时做aspect extraction和sentiment prediction两个任务,而且都是弱监督范式。
用主题模型发现aspect,而且不需要aspect annotation。
原文自带的划分称为segment,比较类似sentence或者sequence这种无语义意义的自然划分。
任务是opinion summarization:输入是多个特定商品的review,对该商品的整体评论情况做总结。
大部分这个任务的工作都是entity-centric。将其分解为三个子任务:
①aspect extraction
②sentiment prediction
③summary generation
经典范式就是那种aspects列个表,然后每个写正负面情感有多少评论那种。也就是本文第11节5篇论文那种做法。但是本文是会真的给出文本形式的摘要的。
这篇论文里说评论是knowledge-lean的,这一点我没看懂。
a few aspect-denoting keywords
本文提出的弱监督范式只需:product domain labels and user-provided ratings
识别salient opinions,从多reviews中生成extractive summaries
两个弱监督组成部分:
①aspect extractor:多任务目标函数
②sentiment predictor:multiple instance learning4
ipeline生成结果:aspects, extraction accuracy, final summaries
发现aspect:用aspect做aspect matrix,然后取原文的segment匹配到aspect上。预先标记属于某一aspect的关键词,原文得到segment embedding、计算属于各类aspect的概率;各aspect的关键词形成seed matrices合并为aspect matrics;二者最后实现segment reconstruction
对不同aspect抽取对应文本(对原文的segment进行排序,用贪心算法降低冗余度),分析情感倾向
7. 原文训练集有显式structure,测试集没有。摘要有显式structure
- Inducing Document Structure for Aspect-based Summarization:文中的aspect举例为商品属性:

训练集数据原文的structure标签是自制的(scalable synthetic setup)。在测试集上原文没有标签,用模型中的attention在原文中划分aspect是学习目标之一。
将表示为独热编码的input aspect向量与word embedding嵌入到同一向量空间:
实验效果最好的做法:将topic segmetation embedding直接与word embedding concat
其他做法:- decoder对target summary aspect实现注意力机制
- encoder对aspect实现注意力机制
- WikiAsp: A Dataset for Multi-domain Aspect-based Summarization:aspect-based summarization
不同域的aspects差别很大。
维基百科的小标题是aspect名,内容就是摘要。训练集原文有显式structure但不是单标签的,测试集原文通过roberta-base实现multi-label分类模型得到structure(aspect identification)。
摘要生成阶段的baseline:- 抽取式摘要:TextRank(长度根据平均摘要长度做调整)
- 生成式摘要:对每个域重新训练PreSumm模型,encoder用pre-trained BERT权重初始化,decoder从0开始学习
- Aspect-Controllable Opinion Summarization:可以生成general的或控制aspect数目的aspect-specific summarization(focusing on creating summaries based on opinions that are popular or redundant across reviews )
训练集原文的aspect生成(aspect extraction)用了aspect-specific关键词。
在测试集原文上分token、sentence、document三个粒度来预测其aspect。然后用indicator的方式来生成aspect(以query的方式)对应的keywords和句子。
具体来说:
①从评论语料库里建一个synthetic training dataset of (review, summary),包含aspect controllers(通过multi-instance learning model生成,从不同粒度预测一篇文档的aspects)(伪摘要)(aspect-related keywords, review sentences, and document-level aspect codes)
②用这个人造数据集微调预训练模型,通过调整aspect controllers(3种)生成aspect-specific summaries

- Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization:对比学习+多任务学习
摘要每一句话视为一个sub-summary,原文中与每个sub-summary对应的snippet是用rouge算出来的。(做法应该比较类似SPACES模型5的抽取阶段)
文献综述部分讲了一些topic和inter-topic snippet主题的内容:Two-level transformer and auxiliary coherence modeling for improved text segmentation. 以及topic segment features。对之前一些需要topic segmentation算法的论文总结了一下,说这样会引起误差传播问题。
topic-aware contrastive learning是辅助任务。
coherence detection和sub-summary generation objectives(topic change和information scattering)
希望其能用来隐式建模topic change和information scattering - Surfer100: Generating Surveys From Web Resources on Wikipedia-style:维基百科生成任务
从每个section里抽取原文(content selection使用了聚类的方法),生成对应section的摘要。
训练过程是生产前导段落,测试阶段直接生成全文。
8. 原文训练集和测试集都有显式structure,摘要没有
- How to Interact and Change? Abstractive Dialogue Summarization with Dialogue Act Weight and Topic Change Info
topic change info 暗示dialogue中哪个utterance(utterance embedding就是word embedding平均值)重要、topic是否已改变。每个sentence改变主题的概率。
关注多主题和不同对话者之间关系(interactions)
Dialogue Act Weight: the weight of each sentence calculated by dialogue act and use this approach to make the model pay more attention to important sentences(encoder:better interaction)(是个权重)(不重要的句子可能是切换topic的位置)
topic change info(decoder:utterrance是否是turning point)
使用AMI Meeting Corpus(dialogue acts, topic descriptions, named entities, hand gestures, and gaze direction都是标注好的。然后本文对原数据进行了重构,所以事实上没用到原数据集这些信息,输入模型的topic不是这个topic)
模型:sentence-gated mechanism+seq2seq+attention
topic change info是一个直接用dialogue act weight算出来的值(因为假设句子越不重要越可能是topic转折点)
将topic change info与utterance embedding(类似普通document中的sentence embedding)相乘后,直接加到decoder输入中:

- Improving Abstractive Dialogue Summarization with Hierarchical Pretraining and Topic Segment
做预训练和topic segmentation。多任务预训练,word-level mask句子(Gap Sentences Generation (GSG) pretraining task,选的是每个utterance中的重要句),uterrance-leve mask role(context + role),uterrance-leve mask的input还加入topic segmentation
用topic segmetation embedding做attention(限制在topic内互相attend)。 - Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization
利用对话文本的specific conversational structures

联合各种view:①topic view ②stage view (stage: conversation progression perspective) ③视为整体:global view ④视为各segmentation:discrete view(差不多就是指每个utterance之间加专门的token作为分隔符)
仅用topic view来做的话,会忽略nuanced conversational structures,还会使编码阶段的误差cascade到解码阶段。
topic view和stage view是自动抽取的:先用sentence-bert得到句子表征,然后用C99算法将句子分为多个block(topic)
就是它每种view类似一种section划分,topic view划分topic, stage view划分stage
encoder:自动抽取每种view,用LSTM编码
decoder:用各个view的表征来作为attention
模型:multi-view seq2seq ①从不同views抽取unstructured daily chats的conversational structures来做表征 ②用multi-view decoder聚合不同views以生成摘要


这个感觉是直接抽取view,然后用它来计算attention,得到最后结果 - Aspect and Sentiment Aware Abstractive Review Summarization
原文的sentiment/aspect word是用词典和topic model直接找出来的。
对context/sentiment/aspect分别学习到表示向量,互相attention,用encoder-decoder架构,在encoder和decoder都添加attention机制。
需要文档级别的分类标签。
encoder:用mutual注意力机制来找context, sentiment, aspect words的表示向量(捕获其间关系)
decoder:用上面的表示向量,用attention fusion network生成aspect/sentiment-aware review summaries
multi-task learning setup:同时训练文本分类任务(category-specific text encoder)
Multi-factor attention fusion network
训练方法:强化学习
9. 原文训练集有隐式摘要,测试集没有。摘要有显式结构
- Generating Topic-Oriented Summaries Using Neural Attention
训练集有原文的topic标签,但是非显式的(即没有明确划分开不同topic所属原文)(是自制的,平均每篇文档1-4个aspects)。
使用基于attention的RNN架构,用topic表征做attention:
表现最好的做法:将topic表示为独热编码,然后concat到每个低维嵌入向量后。
其他表现较差的做法:直接concat到encoder或decoder的初始向量上,对每个topic用不同的attention matrix。
10. 原文没有结构,摘要有显式structure
- Rewards with Negative Examples for Reinforced Topic-Focused Abstractive Summarization:topic-focused summarization。使用了强化学习方法。
negative example是不属于该topic的summary。做了一些rewards上的更新(rewards with a novel negative example (a sentence that contains information that the summarization model should not focus on) baseline)。原文和topic表征concat输入模型(用一个separator token隔开)。
假设是如果给模型看不需要focus之处,会提高模型效果。 - Extractive Opinion Summarization in Quantized Transformer Spaces:可以生成general的,也可以作为aspect-based summarization
摘要有general的,也有aspect-specific的。
基于popular或特定的aspects抽取句子。
用3个头嵌入,然后聚类,用以采样(与聚类样本数成比例,有放回取样(与距离成比例))、抽取。
前作是前作:Vector-Quantized Variational Autoencoders
任务是popularity-driven summarization
a clustering interpretation of the quantized space和一个新的抽取方法
生成摘要从general变aspect-specific,利用:Transformer’s multi-head sentence representations
(对这一论文的这一描述来自Aspect-Controllable Opinion Summarization)mitigate this problem(指opinion summarization应该是aspect-specific而非general的) with an extractive approach that produces both general and aspect-specific opinion summaries.
clustering opinions through a discrete latent variable model and extracting sentences based on popular aspects or a particular aspect. By virtue of being extractive, their summaries can be incoherent, and verbose containing unnecessary redundancy. And although their model creates summaries for individual aspects, it is not clear how to control the number of aspects in the output (e.g., to obtain summaries that mention multiple rather than a single aspect of an entity)
11. 一种不知道算什么总之差不多所以放到一起的aspect-based summarization
对这一部分进行概括的这一说法来自 Extractive Opinion Summarization in Quantized Transformer Spaces:numerically aggregate customer satisfaction across different aspects of the entity under consideration,对输入量flexible,对输出量controllable with respect to the scope of the output。
原文是电商用户评论,摘要是用户对这些feature的opinion情感倾向(opinion orientation)正负各自的个数和对应的原评论。
抽取原文中的features of the product。传统统计学的做法:原文中属于每种feature的句子是模型找出来的。
步骤:1. 挖掘商品评论中的product features。2. 识别其中的opinion sentences,判断每一句的情感倾向。3. 总结。
- Mining and summarizing customer reviews.
- Movie review mining and summarization
- A joint model of text and aspect ratings for sentiment summarization.
在线评论(文本)+针对特定aspects的打分(数值)
本文提出一个统计学模型,找出文本中对应的topics,从文本中提取支持对应ratings的textual evidence
这个模型general而且可以用来做分割(就是,这个模型就是还是那种老的,提取情感、每种aspect对应一些内容的那种传统统计学的划分方式)
aspect identification and mention extraction
sentiment classification
Multi-Aspect Sentiment model (MAS) - Rated aspect summarization of short comments:rated aspect summary
- Aspect-based sentence segmentation for sentiment summarization
- Mining Opinion Features in Customer Reviews
- Comprehensive Review of Opinion Summarization:这是一篇综述,其中aspect-based opinion summarization与前几条类似,提取feature,然后对每个feature计算情感倾向、拿出对应的原句
分模块会用topic modeling(LDA)什么的
分成aspect-based和non-aspect-based

12. 单篇文档具有一个主题或者一个主题分布,因此不算结构化文本摘要任务,但是具有跟结构化文本摘要任务中相同的主题概念;或者具有结构概念或其他类似于结构化摘要任务的概念,因此光看名字易产生混淆,但事实上不是的
常用的概念:topic model
Topic model - Wikipedia
- Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization:用预训练的LDA学习到文章的主题,以生成超短的单主题摘要。用单词和文档的相似度来对其打分。
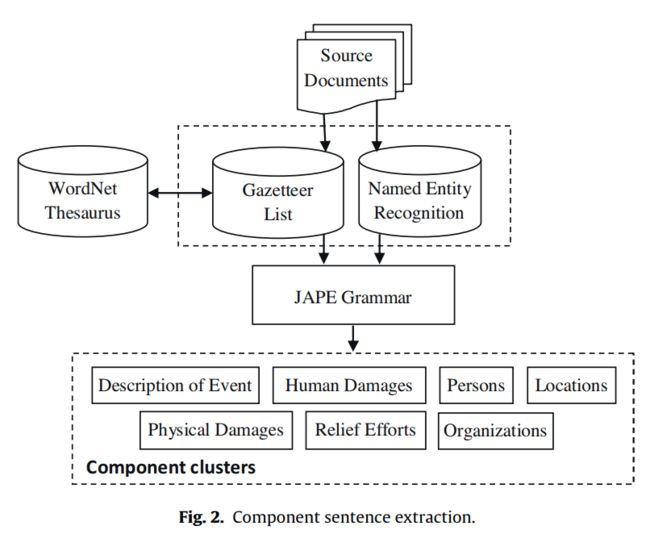
- Multi document summarization based on news components using fuzzy cross-document relations:基于同一事件的多篇报道写新闻。
基于主题的新闻元素,提取component sentence(NER。用同义词典来抓概念的近义词),聚类(JAPE),去重,(识别跨文档的CST关系),用fuzzy reasoning排序句子。

自然灾害新闻的元素:
- Friendly Topic Assistant for Transformer Based Abstractive Summarization
背景:transformers模型有大优势,加上topic models(更擅长学习explicit document semantics)(Global semantics)
重排、探索topic model学到的semantics
TA的3个模块:
①Semantic-informed attention (SIA)(显式的attention)
②Topic embedding with masked attention (TEMA)(token embeddings的混合?)
③Document-related modulation (DRM):Conditional biasing
topic-proportion vector是文档的表示向量
Transformer+TA
bidirectional self-attention (SA)(提取document-token features)
cross attention (CA)

旧transformers模型的缺陷:
①local tokens之间的关系而不是整体的
②position index所限因此input tokens容量有限,因此需要截断
topic models: LDA, PFA
①将每个文档表示为bag-of-word (BOW) vector,然后factor the count vector as a product of topics and topic proportions
②topics是global variables,描述tokens在词表中的分布
③Topic proportions:local(document-specific)特征,描述每个文档中对应topics的权重
④word co-occurrence patterns - Document Summarization with VHTM: Variational Hierarchical Topic-Aware Mechanism:多粒度topic嵌入/分布
结合topic model实现文本摘要(体现了文档的特征或用户的偏好)
嵌入topic inference(端到端topic inference+summarization)
latent topics融入多粒度(topic embedding and attention)
抽取+生成式,结合topic information,深度学习
文献综述部分介绍了:传统方法使用外部生成的topics(如LDA),LDA的假设是:topics are drawn from multinomial distributions across an article; this apparently does not hold for all of the articles fetched from diverse domains. 摘要任务只关心最informative的topics,但LDA会提取所有隐topics。topics是提取自文档级别的(也就是说我们其实既需要文档级别的topics,也需要自然段级别的subtopics)(multi-scale topics)fusion effect遭到质疑。Unified models。
topic embedding model→文档级别的topic vector→将其融入bert得到的传统word embedding→对文档分段
然后用这些多粒度的结合topic的东西来进行文本生成 - Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks:topic modeling for summarization
以全topic表征加权求和为一文档的整体topic表征
topical information
joint neural topic model (NTM)(提供句子选择的document-level features)
document graph
①用预训练的bert建模全文档,用NTM找latent topics。②用句子和topic节点建立heterogeneous document graph,同时用修改后的GAT优化其表征。③抽取句子表征,计算最后标签。 - Topic-Guided Abstractive Text Summarization: a Joint Learning Approach:neural topic modeling + Transformer-based sequence-to-sequence (seq2seq)
- Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
customer-service
role-specific information
multi-role information
topic-augmented two-stage dialogue summarizer (TDS)
saliency-aware neural topic model (SATM) - TransSum: Translating Aspect and Sentiment Embeddings for Self-Supervised Opinion Summarization
aspect and sentiment embeddings在低维的这个空间向量上
对比学习:2个contrastive objectives学习评论的crucial aspect and sentiment embeddings(intra- and inter-group invariances)
2个模块:
①translation-based review modeling module(用review对应的aspect和sentiment嵌入来表示review)
②multi-input opinion summarization module(用reviews with similar aspects (embeddings)来构建高相关性的reviews-summary对,来有监督地训练一个multi-input summarization model) - Topic-Guided Abstractive Multi-Document Summarization:topic modeling for text summarization,多文档摘要(MDS)
联合训练,multi-task
学习documents之间的关系,将documents构建为heterogeneous graph,考虑不同粒度的semantic nodes,用graph-to-sequence框架生成摘要。用topic model联合发现隐topics作为cross-document semantic units来作为documents间的桥梁并给摘要生成提供global information - Abstractive Cross-Language Summarization via Translation Model Enhanced Predicate Argument Structure Fusing
是一些谓词对应,概念对应之类的方法。
这个predicate-argument structures (PAS) 虽然不太懂具体是什么东西,但是显然不是我所想要的那种结构。 - Bringing Structure into Summaries: Crowdsourcing a Benchmark Corpus of Concept Maps
我不确定这个concept map是不是这个东西:概念图(Concept-Map)及其应用 – 知识管理中心KMCenter - Structured Neural Summarization:用了GNN
- Unsupervised Neural Single-Document Summarization of Reviews via Learning Latent Discourse Structure and its Ranking:构建树
- Earlier Isn’t Always Better:Sub-aspect Analysis on Corpus and System Biases in Summarization:摘要的sub-aspect指的是:position, importance, and diversity
- Improving Abstractive Dialogue Summarization with Graph Structures and Topic Words:以utterance和topic word为节点,用GNN方法
- Dr.Summarize: Global Summarization of Medical Dialogue by Exploiting Local Structures:病人用药历史得到的unique and independent local structures。PGN变体
- Stepwise Extractive Summarization and Planning with Structured Transformers:看题目,很明显这个结构是模型的结构,而不是数据的结构
- A Finer-grain Universal Dialogue Semantic Structures based Model For Abstractive Dialogue Summarization
semanttic structure具体是啥我还没看,反正不是我所说的那种结构:
Semantic Structures | The MIT Press
The Semantic Structure of Language - Sparsity and Sentence Structure in Encoder-Decoder Attention of Summarization Systems:和上上个论文相似,结构是模型的结构
- Structure-Aware Abstractive Conversation Summarization via Discourse and Action Graphs:图论。直接建模对话中的structure。它这个结构是有点动作关系的感觉
- Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization:结构指模型
- Capturing Relations between Scientific Papers: An Abstractive Model for Related Work Section Generation:生成related work
- Situation-Based Multiparticipant Chat Summarization: a Concept, an Exploration-Annotation Tool and an Example Collection
- Incremental temporal summarization in multiparty meetings:提出了一个新数据集
12. 没仔细看,所以没有列出
- Aspect-Aware Multimodal Summarization for Chinese E-Commerce Products:aspect是一个产品的属性(如冰箱的电量)。生成方法用了关键词直接抽取(数据集Aspect Keywords Mining部分)
- A Hybrid Approach to Multi-document Summarization of Opinions in Reviews
- Modeling content and structure for abstractive review summarization:总之也是传统统计学的做法。

consider discourse and topical structure to abstractively summarize product reviews using a micro planning pipeline for text generation rather than building on recent advances in end-to-end modeling.(Inducing Document Structure for Aspect-based Summarization)
不需要handcrafted feature taxonomy或训练数据 - HiStruct+: Improving Extractive Text Summarization with Hierarchical Structure Information:反正也是这种花式embedding叠叠乐,具体的内容我还没看。

13. 可能相关,我还没看
- Overview of duc 2005.
- Overview of duc 2006.
- Measuring Importance and Query Relevance in Topic-focused Multi-document Summarization
- Beyond sumbasic: Task-focused summarization with sentence simplification and lexical expansion.:抽取式摘要系统+topic+句子简化+topic词的语义延伸
- Manifold-Ranking Based Topic-Focused Multi-Document Summarization
- Using only cross-document relationships for both generic and topic-focused multi-document summarizations
- Graph-based multi-modality learning for topic-focused multidocument summarization
- Diversity driven attention model for query-based abstractive summarization
- Summary Cloze: A New Task for Content Selection in Topic-Focused Summarization:提出一种新的任务范式summary cloze:给定summary开头、topic和参考文档,预测下一句。需要考虑参考文档中哪些信息与topic和部分summary有关。对不同的topic和summary开头建立多个encoder。
- Unsupervised Abstractive Opinion Summarization by Generating Sentences with Tree-Structured Topic Guidance
- Summarizing Text on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach
- Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders
- Extracting Decisions from Multi-Party Dialogue Using Directed Graphical Models and Semantic Similarity
- Automatic analysis of multiparty meetings
- Social action and human nature
- Discourse segmentation of multi-party conversation:提出一种划分对话中topic的方法
- Unsupervised Modeling of Twitter Conversations:建模dialogue acts / speech acts做文本分块用的
- Exploiting Conversation Structure in Unsupervised Topic Segmentation for Emails
- Mixed Membership Markov Models for Unsupervised Conversation Modeling:将文本分块用HMM来实现
- Large-scale Analysis of Counseling Conversations: An Application of Natural Language Processing to Mental Health
- Neural Network-Based Abstract Generation for Opinions and Arguments:多个输入样本作为一个topic
attention-based neural network model
importance-based sampling method:让encoder从一个重要的subset of input中引入信息(计算文本重要性)
所有输入属于同一topic
Pre-trained Embeddings and Features.(有用一些传统NLP特征的) - Detecting (Un)Important Content for Single-Document News Summarization:用句级别特征(以前都是拿来做query-focused or topic-based summaries的)实现抽取式摘要
- Hierarchical Transformers for Multi-Document Summarization:抽取式摘要。对自然段进行排序,然后选一些作为输入
- Hamshahri: A standard Persian text collection
- 华东师范大学硕论 基于内容与结构的论文作者分析
- 学术文本的结构功能识别——功能框架及基于章节标题的识别
- 上海交通大学博论 基于内容相关度计算的文本结构分析方法研究:文本结构有两种,一种是物理结构,一种是逻辑结构(我家门前有两棵树)
- Evaluation of Automatic Text Summarizations based on Human Summaries
- Surveyor: A System for Generating Coherent Survey Articles for Scientific Topics
- Abstractive News Summarization based on Event Semantic Link Network
- Selective encoding for abstractive sentence summarization:用gate机制实现
- COSUM: Text summarization based on clustering and optimization:基于聚类和优化的两阶段句子选择模型,第一阶段用K-means聚类发现文本中的所有topics,第二阶段提出一优化模型从簇中选显著句,该优化模型的目标函数是使强制被选择句的coverage and diversity的目标函数的调和平均值。控制长度以维持可读性。优化方法是adaptive differential evolution algorithm with novel mutation strategy
- Interpretable Structure Induction via Sparse Attention
- NEWS: News Event Walker and Summarizer
- Abstract Text Summarization with a Convolutional Seq2seq Model:hierarchical CNN framework(1个在单词层面,1个在句子层面)+copy机制+hierarchical attention mechanism(也是两层)
- Recent Trends in Deep Learning Based Abstractive Text Summarization
- Unsupervised Neural Single-Document Summarization of Reviews via Learning Latent Discourse Structure and its Ranking:把评论文本变成discourse tree
- Persian Automatic Text Summarization Based on Named Entity Recognition
- News Text Summarization Based on Multi-Feature and Fuzzy Logic
- Template-aware Attention Model for Earnings Call Report Generation:这篇感觉做法跟Re3Sum6比较类似
- Abstractive Summarization of Spoken and Written Instructions with BERT
- From Standard Summarization to New Tasks and Beyond: Summarization with Manifold Information
- NEWTS: A Corpus for News Topic-Focused Summarization
- DialogLM: Pre-Trained Model for Long Dialogue Understanding and Summarization
- Generating a Structured Summary of Numerous Academic Papers: Dataset and Method:论文还没公开呢我看个锤子啊
这个术语我看到常用于PDF解析类的文献。我直接参考的是这篇文献的摘要:DocParser: Hierarchical Document Structure Parsing from Renderings 是做PDF渲染的。 ↩︎
Fine-tune BERT for Extractive Summarization ↩︎
说IJITEE是烂刊的证据可见:Are these journals indexed by Scopus: IJEAT, IJRTE, and IJITEE? ↩︎
Multiple instance learning - Wikipedia:我看了一眼没看懂,以后有机会去了解一下。 ↩︎
SPACES:“抽取-生成”式长文本摘要(法研杯总结) - 科学空间|Scientific Spaces ↩︎
Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization ↩︎