手把手教你设计CPU-1
ISA众生相
1、x86架构
2、SPARC架构
3、MIPS
4、Power
5、Alpha
6、ARM
7、ARC
8、Andes
9、C-Sky
除了x86都是RISC
RISC-V架构的基本指令数目只有40多条,加上其他的模块化扩展指令总共几十条指令。
RISC-V 架构的整数通用寄存器组,包含 32 个 (I 架构)或者 16 个 (E 架构〉通用整数寄存器,其中整数寄存器 0 被预留为常数 0 , 其他的 31 个 (I 架构)或者 15 个 (E 架构)为普通的通用整数寄存器。
如果使用浮点模块 (F 或者 D ),则需要另外一个独立的浮点寄存器组,包含 32 个通用浮点寄存器。如果仅使用 F 模块的浮点指令子集,则每个通用浮点寄存器的宽度为 32 比特;如果使用了 D 模块的浮点指令子集,则每个通用浮点寄存器的宽度为 64 比特 。
与所有的 RISC 处理器架构一样,RISC-V 架构使用专用的存储器读( Load )指令和存储器写( Store )指令访问存储器( Memory〉,其他的普通指令无法访问存储器。
RISC-V有2条无条件跳转指令
跳转链接 jal(Jump and Link)指令一一jal 指令可用于进行子程序调用,同时将子程序返回地址存在链接寄存器( Link Register,由某一个通用整数寄存器担任〉中 。
跳转链接寄存器 jalr(Jump and Link-Register ) 指令一jalr 指令能够用于子程序返回指令,通过将 jal 指令(跳转进入子程序)保存的链接寄存器用于 jalr 指令的基地址寄存器,则可以从子程序返回。
RISC-V有6条带条件跳转指令
无条件码执行,RISC-V放弃使用“条件码”指令的方式,对于任何的条件判断都是用普通的带条件分支跳转指令。
无分支延迟槽,RISC-V放弃了分支延迟槽,因为现在的高性能处理器的分支预测算法精度已经非常高。
零开销硬件循环,RISC-V没有使用此类。
简洁的运算指令,很多 RISC 架构的处理器在运算指令产生错误之时,例如上溢( Overflow )、下溢(Underflow ),非规格化浮点数( Subnormal )和除零( Divide by Zero ),都会产生软件异常 。RISC-V 架构的一个特殊之处是对任何的运算指令错误(包括整数与浮点指令〉均不产生异常,而是产生某个特殊的默认值,同时设置某些状态寄存器的状态位。RISC-V 架构推荐软件通过其他方法来找到这些错误 。 再次清楚地反映了 RISC-V 架构力图简化基本的指令集,从而简化硬件设计的哲学 。
RISC-V架构定义了3种工作模式
• Machine Mode
• Supervisor Mode
• User Mode
其中Machine Mode为必选模式,另外两种为可选模式。
riscv-tools 的 源代码在 Github 上被维护成一个宏项目(详情请在 Github 中搜索" riscv-tools" ) , 其包含了所有 RISC-V 相关工具链 、 仿真器和测试套件等子项目

蜂鸟 E200 系列处理器的系统示意图如图
• 私有的 ITCM(指令紧相合存储)与 DTCM(数据紧祸合存储),实现指令与数据的分离存储同时提高性能。
• 中断接 口用于与 SoC 级别的中 断控制器连接。
• 调试接口用于与 soc 级别的 JTAG 调试器连接。
• 系统总线接口,用于访存指令或者数据。可以将系统主总线接到此接口上, E200可以通过该总线访问总线上挂载的片上或者片外存储模块 。
• 紧耦合的私有外设接口,用于访存数据。可以将系统中的私有外设直接接到此接口上,使得 E200 无须经过与数据和指令共享的总线便可访问这些外设 。
• 紧耦合的快速 IO 接口,用于访存数据。可以将系统中的快速 IO 模块直接接到此接口上,使得 E200 无须经过与数据和指令共享的总线便可访问这些模块。
• 所有的 ITCM 、 DTCM 、 系统总线接口 、私有外设接口以及快速 IO 接口均可以配置地址区间 。
蜂鸟E200流水线介绍
处理器经典的五级流水线模型:取值、译码、执行、访存、写回。
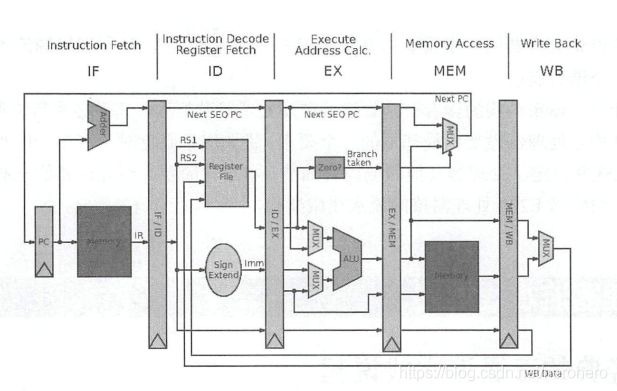
取指
指令取指 Cinstruction Fetch )是指将指令从存储器中读取出来的过程。
译码
指令译码( Instruction Decode )是指将从存储器中取出的指令进行翻译的过程。经过译码之后得到指令需要的操作数寄存器索引,可以使用此索引从通用寄存器组(Register File, Regfile )中将操作数读出。
执行
指令译码之后所需要进行的计算类型都己得知,并且己经从通用寄存器组中读取出了所需的操作数,那么接下来便进行指令执行( Instruction Execute ) 。指令执行是指对指令进行真正运算的过程。 譬如,如果指令是一条加法运算指令,则对操作数进行加法操作;如果是减法运算指令,则进行减法操作。
在“执行”阶段的最常见部件为算术逻辑部件运算器( Arithmetic Logical Unit, ALU),作为实施具体运算的硬件功能单元 。
访存
存储器访问指令往往是指令集中最重要的指令类型之一, 访存( Memory Access )是指存储器访问指令将数据从存储器中读出,或者写入存储器的过程 。
写回
写回 (Write-Back )是指将指令执行的结果写回通用寄存器组的过程 。 如果是普通运算指令,该结果值来自于“执行”阶段计算的结果:如果是存储器读指令,该结果来自于“访存”阶段从存储器中读取出来的数据。
处理器流水线中的冲突
处理器的流水线设计中另外一个问题便是流水线中的冲突( Hazards ),主要分为资源冲突和数据冲突。
资源冲突:
资源冲突是指流水线中硬件资源的冲突,最常见的是运算单元的冲突,譬如触发器需要多个时钟周期才能完成运算。因此在前一个除法指令完成之前,新的触发命令如果也需要触发器,则会存在着资源冲突。
解决资源冲突可以通过复制硬件资源或者流水线停顿等待硬件资源的方法解决。
数据冲突
数据冲突指不同的指令之间的操作数存在着数据相关性造成的冲突,常见的数据相关性如下。
WAR/WAW/RAW
蜂鸟E200处理器的流水线
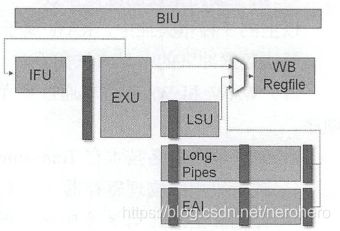
蜂鸟E200处理器核的流水线结构
1、流水线的第一级为“取指(由IFU完成)”
2、“译码(EXU中完成)”“执行(EXU中完成)”“写回(EXU中完成)”均处于同一个时钟周期,位于流水线的第二级。
3、“访存(由LSU完成)”处于EXU之后的第三级流水线,但是LSU写回的结果仍然需要通过WB模块写回通用寄存器组。
取指
每条指令在存储器空间中所处的地址称为他的指令PC。
取指(Instruction Fetch)是指处理器核将指令从存储器中读取出来的过程(按照其指令PC值对应的存储器地址)。

PC值为0x8002150至PC值为0x8000215e处之间都是非分支跳转指令,处理器需要按顺序执行这些指令,指令PC值逐条指令连续增加
PC值为0x80002160出的bne指令,如果操作数a6和a3寄存器中的值不相等,则需要发生跳转去执行PC为0x80002150处的指令。
有的指令编码宽度是16位,而有的指令编码宽度是32位的。对于宽度为32位的指令,其对应的PC地址可能与32位地址边界不对齐,譬如PC值为0x8000217a处的32位指令所处的存储器地址(0x8000217a)便与32位地址边界不对齐(无法被4整除)。
如何快速取指
通常使用ITCM和I-Cache的方法,保证存储器的读延时尽量小。
1、ITCM(Instruction Tightly Coupled Memory)
指令紧耦合存储。实现简单,容易理解,且能保证实时性。
使用地址区间寻址,因此无法像Cache那样映射无限大的存储器空间。
2、I-Cache(Instruction Cache)
指令缓存,将容量巨大的外部指令存储空间动态映射到容量优先的指令缓存中。
访问缓存存在着相当大的不确定性。
如何处理非对其指令
1、普通指令非对齐
使用剩余缓存保存上次取指令后没有用完的比特位,供下次使用。
2、分支跳转指令非对齐
使用多体化的SRAM进行指令存储。使用两块32位宽的SRAM交错的进行存储。
对于地址不与32位对齐的指令,则一个周期可以同时访问两块SRAM取出两个连续的32位指令字,然后各取其一部分进行拼接成真正需要的32位指令。
如何处理分支指令
1、分支指令的类型:
(1)无条件跳转/分支:无条件直接跳转/分支指令、无条件间接跳转/分支指令。
•无条件直接跳转/分支,跳转的目标地址从指令编码的立即数可以直接计算而得。如jal
•无条件间接跳转/分支,间接是指跳转的目标地址需要从寄存器索引的操作数中计算出来。如jalr
(2)带条件跳转/分支:带条件直接跳转/分支、带条件间接跳转/分支
•无条件直接跳转/分支,跳转的目标地址从指令编码中的立即数可以直接计算而得。如6条带条件分支指令
•无条件间接跳转/分支,间接是指跳转的目标地址需要从寄存器索引的操作数中计算出来。RISC-V架构没有此命令。
为了提高性能,现代处理器的取指单元一般会采用分支预测技术。
2、预测方向
(1)静态预测,仅依靠这条分支指令本身的信息进行预测。
(2)动态预测,依赖已经执行过得指令的历史和分支指令本身的信息综合进行“方向“预测。
3、预测地址
(1)分支目标缓存BTB
(2)返回地址堆栈RAS
(3)间接BTB
RISC-V取指简化
(1)规整指令编码长度
(2)指令长度指示码放在低位
(3)简单的分支跳转指令
(4)没有分支延迟槽指令
(5)提供明确的静态分支预测依据
(6)提供明确的RAS依据
蜂鸟E200处理器的取指实现
(1)IFU总体设计思路,包括如下功能:
1、对取回的地址进行简单译码
2、简单的分支预测
3、生成取值的PC
4、根据PC的地址访问ITCM或BIU
蜂鸟E200处理器的执行实现
EXU,蜂鸟E200是两级流水线架构,“译码”“执行”“写回”均处于第二级流水,功能如下:
1、将IFU通过IR寄存器发送给EXU的指令进行译码和派遣
2、通过译码出的操作数寄存器索引读出Regfile
3、维护指令的数据相关性
4、将指令派遣给不同的运算单元执行
5、将指令交付
6、将指令运算的结果写回Regfile
蜂鸟E200处理器的交付实现
流水线中的指令被“交付”,是指该指令不再是预测执行状态。它被判定为可以真正地在处理器中被执行,可以对处理器状态产生影响。
“交付”“取消”“冲刷”。当处理器流水线需要将没有“交付”的后续指令全部“取消”掉时,就会造成“流水线冲刷”
RISC-V可大幅简化“交付”硬件实现
1、指令没有条件码,所以不需要处理单挑指令“取消”情况
2、所有的运算指令都不会产生异常。大多指令集规定“除以0”为错误异常,浮点指令也会有若干错误异常。但RISC-V规定这些运算指令一概不产生错误异常。
综上所述,RISC-V架构的处理器只需要处理如下两类流水线冲刷情形:
1、分支预测指令错误在成的后续指令流取消。
2、中断和异常造成的后续指令流取消。
蜂鸟E200处理器的写回
从不同的运算单元执行完毕后的指令也最终都会将其计算结果写回通用寄存器组。
将指令划分为单周期指令和长指令两大类。
将长指令的“交付”和“写回”分开,是的即便执行了多周期长指令,仍然不回阻塞流水线,让后续的单周期指令仍然能够顺利低写回和交付。