一文搞懂sarsa和Q-Learning的区别
好久没写这个系列了,主要是最近在忙其他事情,也在看一些其他的闲书,也是荒废了,有点可惜,后面还是得慢慢更新。
1、sarsa是个什么
强化学习的基础算法QLearning 上次写了下,写了一些伪代码,希望可以看的懂,这篇文章继续写一下sarsa,也是基础算法,所以即使不懂也无所谓,别太难为自己。
SARSA(State-Action-Reward-State-Action)是一种基于强化学习的算法,与Q-Learning一样,都是在智体的行为过程中迭代式地学习,但SARSA采用了和Q-Learning不同的迭代策略。
0基础入门强化学习,非程序也能看得懂|Qlearning_香菜+的博客-CSDN博客
1.1 简单说下几个概念
A:行动,也就是行为,比如棋盘中的一次落子
R:奖励,也就是对整个游戏的进程是否有利,有利则为正,不利则为负
S:状态,表示当前当前棋盘的状态
Q:整体的奖励值,表示记录每一个状态(state)上进行的每一个动作(action)计算出最大的未来奖励(reward)的期望。
γ:学习率,也就是当前的行为有多少影响整个行为。
1.2 sarsa的公式
说真的,反正也看不明白,真不想贴,但是还是贴一下,万一有些人能看明白呐
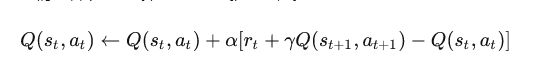
不想多解释了,重要的话等会再说,你能看懂算你牛逼,反正我没懂
2、Q-Learning 和Sarsa的区别
再贴一下Q-Learning的公式,这玩意我也看不懂
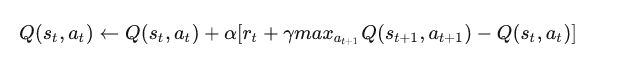
咱们先看两个公式的区别,区别在大括号内,是否选择最大的下一个Q值
2.1 整点类比吧

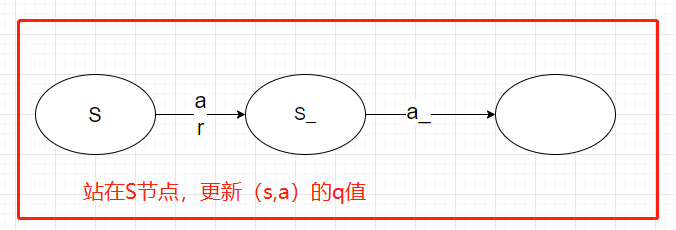
先看下这个游戏吧,要求用最小的消耗走到终点,看起来很简单对吧,走到A之后直接到终点。
当我站在A点的时候,我需要做决策,也就是选择action,更新 在A状态下的Q值
有两种选择方法:
第一种,根据历史经验,Q(A)最小值是2,但是我的action直接选择B ,更新A处的Q 值选择的消耗是1,也就是max的用处。(注,有一定的概率会存在探索,这种情况下虽然经过B点,但是依然使用的是消耗1 的奖励,这里是最大的区别)这是Qlearning 的做法。
第二种,我直接走,站在A点的时候,直接走向B点,这时候更新Q值需要依赖下一步的选择,根据索下一步的Q值更新当前A点的Q值,这是Sarsa的做法。
不知道上面有没有说情况,简单的说就是Qlearning只选择最大的奖励,但是可能没选择那个行为,但是Sarsa是选哪个就是哪个,也就是其他文章说的实战派。
第二个解释:

首先我们基于状态S,用ϵ−贪婪法选择到动作A, 然后执行动作A,得到奖励R,并进入状态S′,此时,
如果是SARSA,会继续基于状态S′,用ϵ−贪婪法选择A′,然后来更新价值函数。但是Q-Learning则不同。
对于Q-Learning,它基于状态S′,没有使用ϵ−贪婪法选择A′,而是使用贪婪法选择A′,也就是说,选择使Q(S′,a)最大的a作为A′来更新价值函数。用数学公式表示就是:
Q(S,A)=Q(S,A)+α(R+γmaxaQ(S′,a)−Q(S,A))
对应到上图中就是在图下方的三个黑圆圈动作中选择一个使)Q(S′,a)最大的动作作为A′。
此时选择的动作只会参与价值函数的更新,不会真正的执行。价值函数更新后,新的执行动作需要基于状态S′,用ϵ−贪婪法重新选择得到。这一点也和SARSA稍有不同。对于SARSA,价值函数更新使用的A′会作为下一阶段开始时候的执行动作。
3、搞个代码
这个代码我之前也没写过,还是参考吧。
import pandas as pd
import numpy as np
class RLBrain(object):
def __init__(self, actions, lr=0.1, gamma=0.9, epsilon=0.9):
self.actions = actions
self.q_table = pd.DataFrame(
[],
columns=self.actions
)
self.lr, self.gamma, self.epsilon = lr, gamma, epsilon
def check_state(self, s):
if s not in self.q_table.index:
self.q_table = self.q_table.append(
pd.Series(
[0] * len(self.actions),
index=self.actions,
name=s
)
)
def choose_action(self, s):
self.check_state(s)
state_table = self.q_table.loc[s, :]
if (np.random.uniform() >= self.epsilon) or (state_table == 0).all():
return np.random.choice(self.actions)
else:
return np.random.choice(state_table[state_table == np.max(state_table)].index)
def learn(self, s, s_, a, r, done, a_):
self.check_state(s_)
q_old = self.q_table.loc[s, a]
if done:
q_new = r
else:
q_new = r + self.gamma * self.q_table.loc[s_, a_]
self.q_table.loc[s, a] += self.lr * (q_new - q_old)
这个代码来自网上,重点代码时learn 这个函数
至于环境没有深究,这里放下
原链接:强化学习——Sarsa算法_CarveStone的博客-CSDN博客_sarsa算法
4、总结
这个算法的理解在事后看来是不难的,但是理解还是花了点功夫,总结几点
4.1 这个算法不会也罢,不影响
4.2 重点理解更新的部分,主要是下一个动作的选择,QLearning 默认选择了最大的,而Sarsa 是通过策略选择的动作
4.3 代码没有细究是否正确,但是算法是理解的。