机器学习分析租房价格的影响因素
本篇文章主要会讲如何从网站上爬取租房数据,清洗数据,聚合数据,并最后用机器学习来分析影响租房价格的主要因素有哪些。
目录
0、前言
1、爬取数据
2、清洗筛选数据
3、聚合分析
4、机器学习分析
0、前言
由于去年下半年开始的地产行业大整顿,导致整体的行业大环境并不理想,所以我,一个做了7年商办地产投资的从业者决定在30岁之际换个方向,主要方向还是在数据分析+机器学习这块,这篇也算是我在这段时间自学后做的小小的一个研究,希望能和大家多多交流。
1、爬取数据
我们希望能够取得上海市全市的租房数据,进行分析研究。
那选取的获取数据的网站当仁不让,还是万能的【链家网】,主要原因有两个:一是链家上的数据比较全面且相对比较真实,二是链家没有反爬机制,只要你请求时间设置一定间隔基本上没有风险(像我就前前后后完整的把链家租房数据爬了4、5次,没有碰到过反爬)。
打开链家网,进入到租房总览界面,可以看到目前(2022年6月17日)的租房数据共有20246条:

调出F12,会发现下面每个房源信息也不存在ajax动态请求,都是能够在当前页面源代码中呈现的,但是别开心的太早,再往下拉会发现,在总览界面中能看到的房源信息只有100页,每页30个房源,即如果直接从总览页面中爬取房源信息,总共只能获得3000个房源,远小于显示的2万条房源。

那么既然在总览页面中无法完整获取,就只好在“按区域”中分别获取房源。

经过探索还发现,如果仅仅通过行政区来分块获取房源,由于【浦东】房源数较多,仍超过了3000条,还是会有遗漏。那索性在每个区域下,再按版块进行分块获取,就能够做到获取全部的房源了。
目前的爬虫思路是:通过循环1获取所有【行政区】的总览url,再通过循环2获取所有的【版块】的总览url,再通过循环3获取到当前板块中所有【房源】的详情url。
进入到具体租房房源界面,可以观察到租房信息还是比较全面。
把我们认为有用的信息比如:小区名称,房租,朝向,面积,房型,精装修,总楼层等都可以爬下来。
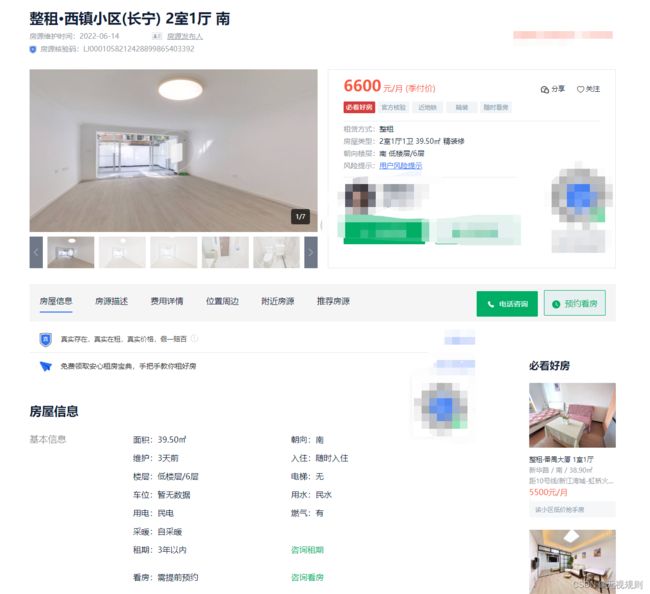
另外,链家也在房源详情界面上放了房源的位置,在源代码中也能找到房源的经纬度,且链家的地图也是用的百度地图,所以不需要进行地图编码的转换,把经纬度爬下来以作备用。至于周边有什么地铁线路,多少距离这些我们先放着不爬。

基本的爬虫代码我就不放了,但有个增加速度的方法的代码我放一下。
我会在每个请求url后面设定0.3-0.5秒不等的间隔,防止短时间内请求过快。但这样2万条的数据,爬下来会比较费时间,所以在此基础上做了一个线程池的设置,使得所有的行政区可以同时进行爬取,极大缩短了爬取时间,代码如下:
# 主程序中加线程池
with ThreadPoolExecutor(20) as t:
for i in range(2, 18):
t.submit(download_lianjia, i)在爬取信息的同时,我考虑到从直观角度上来说,影响房租的因素可能还有外部因素,比如:周边1公里内地铁站数量,周边商场数量,离最近地铁线路的距离。
这块数据可以通过申请百度地图开发者AK利用poi数据来获取,代码我摘取一块放在下面:
--这里需要注意下对于坐标查询功能,百度地图的每日限额是3万条/天,所以要爬“商场”和“地铁”2组关键词的2万条数据我花了2天
for i in range(0,len(lng_data)):
print(f'正在写入第{i}条数据')
loc = str(lat_data[i])+ ',' + str(lng_data[i])
#统计地铁情况
url = "https://api.map.baidu.com/place/v2/search?query=" + \
keyword1 + "&location=" + loc + "&radius=" + str(
radius) + "&output=json&ak=" + ak + "&scope=2" # 构造请求网址
resp = requests.get(url,verify=False)
answ = resp.json()
try:
rail_s = len(answ['results']) #地铁数量
railway_station.append(rail_s)
except:
rail_s = 0
railway_station.append('')
try:
rail_d = answ['results'][0]['detail_info']['distance'] #地铁距离
railway_distance.append(rail_d)
except:
rail_d = 0
railway_distance.append('')至此,我们获取了所有的所需数据如下:

2、清洗筛选数据
因为是自己爬下来的数据,所以内容也好,格式也好还算比较规整,也没有缺损值,来完整看下数据集情况:
(地铁距离在本文中暂没有作为特征项 )

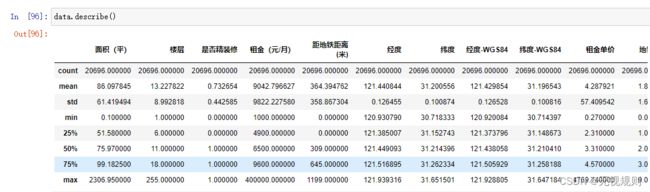
可以发现在面积的最小值(0.1平)和楼层(255层)的最大值都有一些常识型的错误,经过查看发现分别有2个数据和1个数据有误,应该是网站的输入型错误,直接删除即可。
将户型拆成卧室数和客厅数(本意是希望将字符串型数据转化为整型类数据,不想形成太多的独热编码矩阵,但之后发现面积与卧室数和客厅数存在高度相关,最终舍弃了)。

另外,将月租金除以面积,添加新的一列“租金单价”,并查看租金单价的曲线:

可以发现,租金单价存在非常极化的现象,近20700组数据中,只有177组租金单价超过了10元/平/天,且最高达到了41元/平/天。来看看单价前十的小区租金:

查看所有特征的分布情况:

可以看到有些数据存在明显的右偏态分布,比如面积,楼层,在后续需要对其进行取对数变化,以便于更好的进行机器学习。

3、聚合分析
查看各行政区平均租金,可以发现黄浦、静安、长宁平均租金位于前三:

查看各版块平均租金:

查看房源精装修比例,发现精装修的房子占到了75%左右:

查看周边1公里内各地铁站数量的房源平均租金,会发现平均租金最高的是周边地铁站为5个,反而周边有9个地铁站的小区租金单价仅为4.11,还低于3个地铁站的房源的平均租金。
经过具体查看,发现9个地铁站的小区主要位于像龙华版块的上海游泳馆站,和武宁板块的曹杨路站附近,本身小区位置并非处在核心,且虽然地铁站多,但通常只会去最近的地铁站进行换乘,所以地铁站数量与租金并不成完全正相关关系。

4、机器学习分析
最开始是想用多元线性回归进行分析,出于数据集比较简单,且最后呈现的结果可解释性高的考虑,但跑完发现最后的拟合效果只有并不是很理想(r2只有0.4+),目前还在尝试采用不同的特征组合,看是否能够提高拟合效果。
在本文中最终选择了随机森林(RandomForest)模型进行回归分析,随机森林相当于是决策树的进化版本,通过选取多个“树”形成“森林”,具体的原理大家可以上网查看,有太多的教学视频,我这边就不展开了。随机森林模型的优点是拟合度较高,但容易产生过拟合。
这边先简单展示下线性回归的过程:
首先用corr()看下各特征间的相关性,可以看到面积和卧室数的相关性达到了0.8,属于高度相关了,且面积和客厅数的相关性也达到了0.7,那么鉴于此,暂时先放弃卧室数和客厅数两个特征,而选用面积作为特征。其余的特征之间的相关度都在可以接受的范围内。

之后选定特征X和标签y(月度租金),并对X进行归一标准化,以便于归因分析
切分训练集和测试集,并恢复索引,之后进行实例化建模,并且得出测试集的score


可以看到score只有0.45,属于比较不理想的拟合,通过绘图,查看y预测值和ytest实际值,发现在y的最大最小段,预测值和实际值有着相当大的差距,导致了整体结果的不理想。

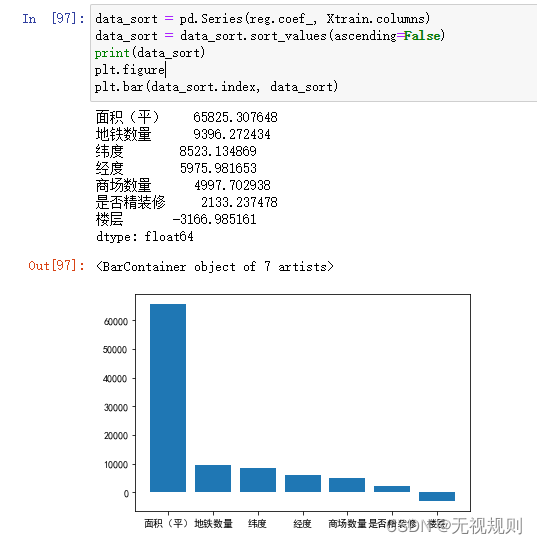
查看各特征影响程度,可以发现对租金总价的影响因素中,面积占比最大且远远大于其他因素,当然是这样的,其次是地铁数量以及经度和纬度,即所谓的区位。
【随机森林】
我们先取n_estimators,即森林里的树的数量=20,采用交叉验证的方法来求得score

可以看到,明显的精准度比线性回归高了许多,但是否还有提升的空间呢?于是用学习曲线来寻找一下(见下图),当i=4,即树的数量取41颗时,score相对有了最优值。

于是,根据学习曲线的结果,我们来做影响房租的因素分析:

通过最后的图表可以看到,用随机森林模型得出面积仍旧是影响房租总价的最重要因素,其次是经纬度(区位)和楼层。
显而易见,房屋月租金的总价由于是单价与面积的相乘,所以面积是影响房租的最大因素从直观上是可以认同的。
那么,如果把标签换为租金单价,会是什么结果呢?
什么因素对房租单价影响最大呢?这才是我们真正想要了解的。
当我们把标签作为y时,再一次用随机森林作出归因分析:

可以看到地铁数量在影响房租单价的因素占比中占据了大头,达到了27%,其次才是经纬度(区位),这也比较符合我们日常的理解,地铁和位置也是通常人们租房最先考虑的两个因素。
以上就是本文对于房租影响因素的所有内容。还是有比较多的内容有待改进,比如如何通过特征选取进一步提高线性回归和随机森林的预测精确度,如果加入“地铁距离”特征又会对结果产生什么影响等等。