论文阅读|Embedding-based Retrieval in Facebook Search
该论文是facebook发表在KDD2020上的一篇关于搜索召回的paper。这篇文章提到的大多trick对于做过召回的同学比较熟悉了,可贵之处在于全面,包括了特征、样本、模型、全链路等各种细节知识。
1. 整体思路与框架
本文的出发点是搜索只做到query关键词匹配的程度是远远不够的,还要结合用户信息及上下文提供个性化搜索服务,比如一个热爱数码的大学生和农村卖水果的果农搜索【苹果】得到的结果应该分别是手机和水果。
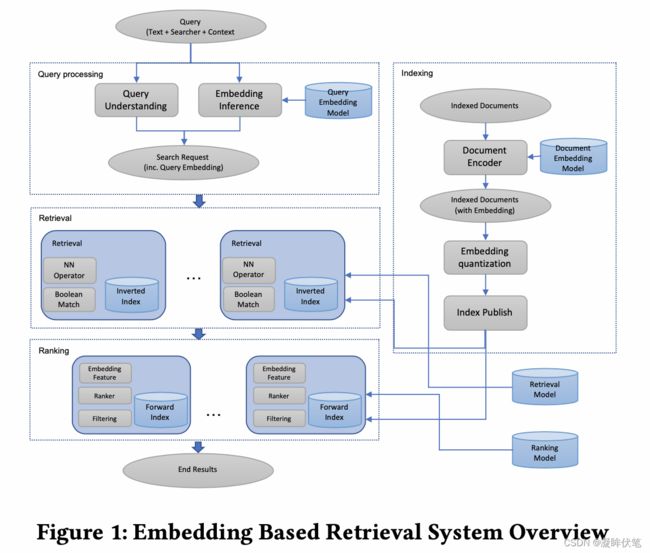
通常的搜索分为召回和排序两个阶段,基于embedding的语义召回主要在第一阶段,它要解决的问题是如何从千万个文本中找到相关的topK个,难点一个是【准】,一个是【快】,准要求和用户+query高度的匹配,快要求从海量候选中搜索的延时低。
模型是双塔模型,当然这里做了一些特征和样本的trick,后面会提。整个架构如下:
- 左边采用了query understanding+embedding inference两部分,即向量表征是补充而非替换
- 在构建index时采用了embedding quantization
- retrieval包括NN operator和Boolean Match
评估的时候为了快速迭代验证,采用了离线topk命中作为评估。我个人认为从召回的本质出发,本就没办法离线去准确评估一个召回的价值,当然迫于迭代效率+搜索场景,这个指标阐述一些feature的价值是可以接受的。下面就围绕这个指标的提升,阐述一下本文的各种工业界trick经验总结
2. 模型
模型结构是双塔,为了优化triple loss, 我们模型包含三个部分:提供query embedding的query encoder f(Q),document encoder g(D),相似度计算function S() 采用cosine similarity。在我们的模型中,f(),g()是拥有一些共享参数的两个独立的network。
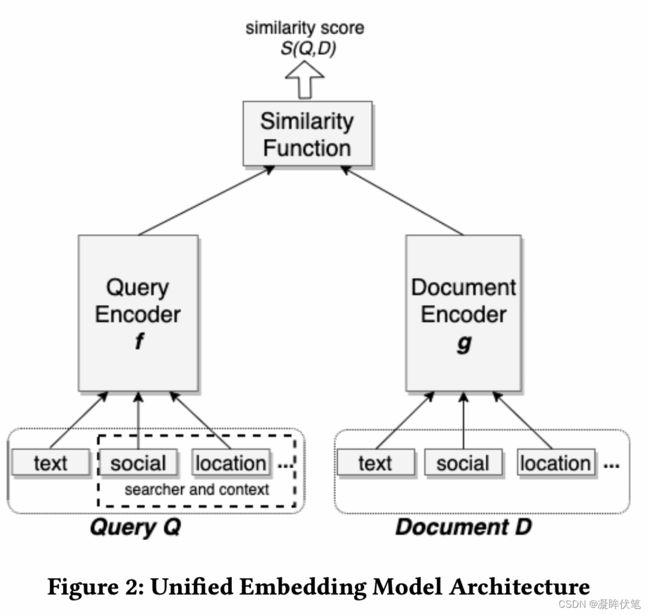
unified embedding encodes 文字,社交,以及其他的上下文特征来分别表示query和document。举例来说,对于query,可能包含了地理位置以及社交关系,而document侧,可能包含聚合位置信息以及社交群组信息。
很多特征是高维离散特征,one-hot multi-hot的vector。我们使用embedding look-up layer学习得到一个dense的vector输入encoder。multi-hot的vector,我们将multiple的embedding做一个weighted combination 作为最终的feature-level的embedding。图2是我们unified embedding model,在section3中,我们将讨论更多的feature engineering。
2.1 损失函数
本文将搜索相关性以pair-wise的角度建模,采用的是triplet loss,形式如下:
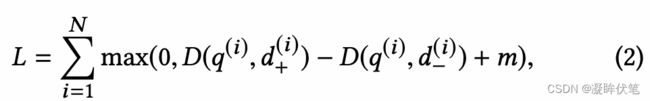
margin是很重要的,说白了这个参数是划分样本难度的,如果特别大没办法收敛,如果特别小又没区分度,虽然对于m本文没讲怎么设置。我们认为使用random samples去构建负例可以更好的approximate recall optimization task。因为如果我们为每一个正例去采样n个负例,那我们模型就是在size n中优化召回在top one position。假设真实的candidate pool大小是N, 我们近似最优化召回 K 约等于 N/n。在2.4我们验证我们这个假设。
2.2 Training Data Mining (重点)
hard negative mining
本文提出了online和offline两种mining方式
- online:在线一般是batch内其他用户的正例当作负例池随机采,本文提到选相似度最高的作为hard样本,同时强调了最多不能超过两个hard样本。
- offline:在线batch内池子太小了不一定能选出来很好的hard样本,离线则可以从全量候选里选。具体做法是对每个query的top-k结果利用hard selection strategy找到hard样本加入训练,然后重复整个过程。这里提到要从101-500中采,太靠前的也许根本不是hard负例,压根就是个正例。以及两个很好的经验,第一个是样本easy:hard=100:1,第二个是先训练easy再训练hard效果<先hard后easy
hard positive mining
本文认为有一些用户未点击但是也能被认为是正样本,做法就是从日志中挖掘潜在的正样本,这也能解释为什么上面hard负样本是101-500了,因为这里可能1-10就是正样本了。
如果定义召回任务的正例和负例是一个很重要的问题。下面我们对于几种选择进行了一个比较。对于负例,我们最初采取了以下两个选择,选用点击为正例:
- 随机sample:对于每个query,在document池子中sample document作为负例。
- 未点击impression:对于每个query,impressed但是没有点击的结果作为负例。
使用未点击impression作为负例的得到显著的更差的model recall: 55% regression在people embedding model recall。我们相信这些negative bias来自 hard cases在一个或者几个factor上可以match query,而大多数的情况下都是完全不能match query的easy cases。当我们所有的负例是这样的hard case的时候,相比真实的召回任务将改变我们training data和真实之间的一致性,导致我们学习到的embedding存在很大的 bias。
The model trained using non-click impressions as negative has significantly worse model recall compared to using random negative: absolute 55% regression in recall for people embedding model. We believe it is because these negatives bias towards hard cases which might match the query in one or multiple factors, while the majority of documents in index are easy cases which do not match the query at all. Having all negatives being such hard negatives will change the representativeness of the training data to the real retrieval task, which might impose non-trivial bias to the learned embeddings.
我们也做了一些正例的尝试:
- 点击:直觉的使用点击作为正例,用户的点击表示了用户认为这个结果契合他的搜索意图。
- 展现:这个想法是我们将召回想做一个计算更快的排序的近似,所以我们的目标是设计一个召回模型返回的结果同样可以被排序模型排在前面。使用这个思想,我们将给用户展现出的结果都作为召回模型的正例。
我们实验表明以上两种方法都是一样有效的;使用点击和展现训练出的模型,给出相似的数据量与相似的召回结果。我们试着使用展现训练数据扩充到点击训练数据中,但是没有给点击训练数据的模型带来额外的收获。证明添加展现训练数据没有提供出额外的数据信息,模型也没有从添加的更多数据量上获得新的好处
我们实验告诉我们使用点击作为正例,随机负例的方式可以带来不错的模型效果。我们还做了一些可以帮助增加模型区分相似结果的尝试在6.1.
2.3 Feature Engineering
unified embedding model可以关注不仅是文字的多种特征,给模型带来更好的效果。在events search场景上带来了18%的召回提升,groups search带来16%提升。下面列出了我们认为带来重要提升的几个特征。
Text Features: Character n-gram 是一个常用的text embedding的方式,跟 word n-gram 相比有两个优势,第一,因为他拥有limited vocabulary size,训练更容易;第二,对out-of-vocabulary 的词鲁棒性更好(单词拼写错误或者单词变化)。我们对 Character n-grams 和 word n-grams 分别实验发现前者有更好的效果。但是,character trigrams上面,加入 word n-grams 提供了微小但是持续的提升(+1.5% recall gain)。 word n-grams 的基数一般很大 (e.g. 352M for query trigrams) ,哈希可以帮助减小embedding 查找表。即使有hash collision 这样的缺点, word n-grams 还是可以额外的提升。
Facebook 提取text feature的主要场景是人名或者title。对比 Boolean term matching techniques ,使用单纯的text feature训练出来的embedding 有以下两个优势:
- 模糊文字匹配。模型可以学习去匹配 query “kacis creations” 与 kacis的页面,term-based match 是做不到的。
- 选配。当query是"mini cooper nw"时,模型可以学习召回 Mini cooper owner/drivers club ,丢掉 “nw”进行可选字词匹配。
Location features: location 匹配在很多场景带来好处比如在搜索local business/groups/events的时候。为了让embedding model可以考虑上location的信息,我们在query侧和document侧都加入了location feature。在query侧,我们取出了城市地区国家和语言。document侧,我们加入了一些公开信息如,group location tagged by admin。加入了text feature,模型可以学习到了一些内在的location match。Table2 对比了text embedding 模型和 text+ location模型,我们可以看到location feature的模型,将相同location的排在了前面。
Social embedding feature:我们使用一个单独的模型通过social graph 学习user 和 entity的embedding。
2.4 SERVING
(这边开始我简要写一下)
文章使用 ANN(approximate near neighbor) 倒排索引。使用他们自家的Faiss组建。
Faiss 中有几个重要的参数:Coarse quantization,Product quantization,nprobe。文章使用离线实验调试线上测试效果。给出一些调参注意事项:1.cluster间的数据存在很不平衡的情况,下图是一个scanned document和1-recall@10的结果。2.当有重大的模型变化时一定要调整ANN parameters。3.使用OPQ。4.pq_bytes 最好是 dimension/4。5.还是要线上调整参数看一下效果。
2.5 ADVANCED TOPICS
文章发现tok K 的结果存在target result和其他result没有区分度的问题,认为是random sampling导致模型太容易了,所以尝试加入一些hard的数据。
online hard negative mining: 在每个batch的query在batch中选择highest similarity当作hardest negatives,每个positive配两个hard negatives最好。
offline hard negative mining:不使用最hard的当作negative,使用rank在101-500的带来最好的recall效果。仍要保持easy negative的选项,毕竟实际的状况中还是easy选项多。
最好的选择:easy和hard的混合。实验结果是easy:hard = 100:1 最好。使用Transfer learning from hard to easy.
需要注意的一点是使用ANN在一个random shard上面搜索的时候,hard negative的选择,文章选择使用semi-hard negatives。
3.总结
本文有一些经验值得借鉴和思考,但比起结论更重要的是思维的方法,比如为什么要做hard mining,自己的场景哪些数据值得hard mining,自己系统中召回问题最关键的是样本、架构还是数据流,只有先定义了问题才能做ROI最高的优化。
4.code解读
github:UnifiedEmbeddingModel/main.py at main · liyinxiao/UnifiedEmbeddingModel · GitHub
loss部分:
# Triplet loss
triplet_loss = nn.TripletMarginWithDistanceLoss(
distance_function=lambda x, y: 1.0 - F.cosine_similarity(x, y), margin=margin)
调用:
def train(self, data_loader, epoch):
self.query_encoder.train()
self.document_encoder.train()
running_loss = 0
for _, (query_inputs, positive_document_inputs, negative_document_inputs) in enumerate(data_loader):
# Forward pass
anchor = query_encoder(query_inputs)
positive = document_encoder(positive_document_inputs)
negative = document_encoder(negative_document_inputs)
loss = triplet_loss(anchor, positive, negative)
# Backward and optimize
query_optimizer.zero_grad()
document_optimizer.zero_grad()
loss.backward()
query_optimizer.step()
document_optimizer.step()
running_loss += loss.item()
print('Epoch [{}], Loss: {:.4f}'.format(
epoch+1, running_loss / len(data_loader)))
self.training_loss.append(running_loss / len(data_loader))参考:
1.将embedding作为排序模型的特征:《Deep Match to Rank Model for Personalized Click-Through Rate Prediction》
2.《Embedding-based Retrieval in Facebook Search》论文精读 - 知乎
3.Embedding-based Retrieval in Facebook Search 阅读笔记 - 知乎