R语言机器学习mlr3:模型评价和比较
获取更多R语言和生信知识,请关注公众号:医学和生信笔记。
公众号后台回复R语言,即可获得海量学习资料!
目录
-
- 二分类变量和ROC曲线
- 重抽样
- benchmark
前面一篇介绍了如何使用
mlr3创建任务和学习器、拟合模型、预测和简单的评价,本篇将模型评价的一些细节问题,展示 mlr3如何使得这些步骤变得更加简单!
二分类变量和ROC曲线
对于二分类变量,结果有阴性和阳性两种,而且判定阴性和阳性的阈值是可以认为设定的。ROC曲线可以很好的帮助我们确定最佳的分割点。
首先看一下如何获取一个分类变量的混淆矩阵:
library(mlr3verse)
## 载入需要的程辑包:mlr3
data("Sonar", package = "mlbench")
task <- as_task_classif(Sonar, target = "Class", positive = "M") # 指定阳性
learner <- lrn("classif.rpart", predict_type = "prob") # 指定预测类型
prediction <- learner$train(task)$predict(task)
conf <- prediction$confusion
print(conf)
## truth
## response M R
## M 95 10
## R 16 87
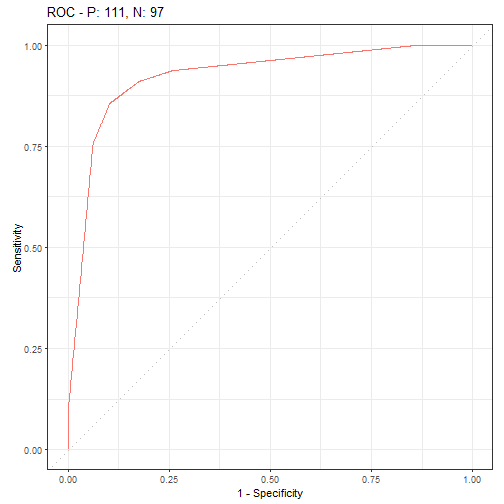
绘制ROC曲线也是非常方便:
autoplot(prediction, type = "roc")
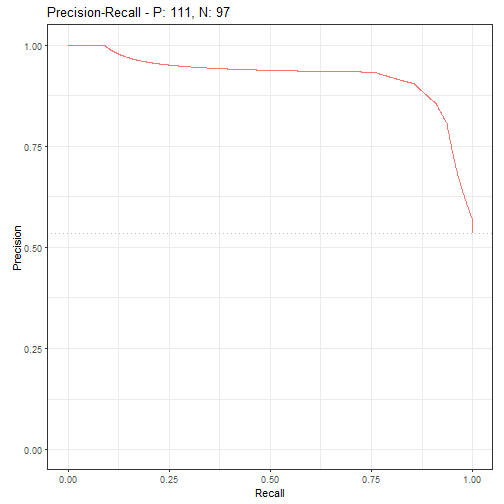
也可以非常方便的绘制PRC曲线:
autoplot(prediction, type = "prc")
重抽样
mlr3支持的重抽样方法:
- cross validation (“cv”),
- leave-one-out cross validation (“loo”),
- repeated cross validation (“repeated_cv”),
- otstrapping (“bootstrap”),
- subsampling (“subsampling”),
- holdout (“holdout”),
- in-sample resampling (“insample”),
- custom resampling (“custom”).
查看重抽样的方法:
library(mlr3verse)
as.data.table(mlr_resamplings)
## key params iters
## 1: bootstrap ratio,repeats 30
## 2: custom NA
## 3: custom_cv NA
## 4: cv folds 10
## 5: holdout ratio 1
## 6: insample 1
## 7: loo NA
## 8: repeated_cv folds,repeats 100
## 9: subsampling ratio,repeats 30
还有一些特殊类型的重抽样方法可以通过扩展包实现,比如mlr3spatiotemporal包。
默认的方法是holdout:
resampling <- rsmp("holdout")
print(resampling)
## with 1 iterations
## * Instantiated: FALSE
## * Parameters: ratio=0.6667
可以通过以下方法改变比例:
resampling$param_set$values <- list(ratio = 0.8)
# 或者
rsmp("holdout", ratio = 0.8)
## with 1 iterations
## * Instantiated: FALSE
## * Parameters: ratio=0.8
下面一个例子使用5折交叉验证方法,建立一个决策树模型:
library(mlr3verse)
task <- tsk("penguins") # 创建任务
learner <- lrn("classif.rpart", predict_type = "prob") # 创建学习器,设定预测的结果是概率
resampling <- rsmp("cv", folds = 5) # 选择重抽样方法
rr <- resample(task, learner, resampling, store_models = T) # 1行代码搞定
## INFO [20:47:12.966] [mlr3] Applying learner 'classif.rpart' on task 'penguins' (iter 5/5)
## INFO [20:47:12.996] [mlr3] Applying learner 'classif.rpart' on task 'penguins' (iter 1/5)
## INFO [20:47:13.010] [mlr3] Applying learner 'classif.rpart' on task 'penguins' (iter 2/5)
## INFO [20:47:13.019] [mlr3] Applying learner 'classif.rpart' on task 'penguins' (iter 4/5)
## INFO [20:47:13.029] [mlr3] Applying learner 'classif.rpart' on task 'penguins' (iter 3/5)
print(rr)
## of 5 iterations
## * Task: penguins
## * Learner: classif.rpart
## * Warnings: 0 in 0 iterations
## * Errors: 0 in 0 iterations
获得平均的模型表现
rr$aggregate(msr("classif.acc"))
## classif.acc
## 0.9448423
获得单个模型的表现
rr$score(msr("classif.acc"))[,7:9]
## iteration prediction classif.acc
## 1: 1 0.9710145
## 2: 2 0.8985507
## 3: 3 0.9130435
## 4: 4 0.9710145
## 5: 5 0.9705882
检查警告或者错误:
rr$warnings
## Empty data.table (0 rows and 2 cols): iteration,msg
rr$errors
## Empty data.table (0 rows and 2 cols): iteration,msg
取出单个模型
rr$learners[[5]]$model
## n= 276
##
## node), split, n, loss, yval, (yprob)
## * denotes terminal node
##
## 1) root 276 158 Adelie (0.427536232 0.206521739 0.365942029)
## 2) flipper_length< 206.5 170 54 Adelie (0.682352941 0.311764706 0.005882353)
## 4) bill_length< 43.35 117 4 Adelie (0.965811966 0.034188034 0.000000000) *
## 5) bill_length>=43.35 53 4 Chinstrap (0.056603774 0.924528302 0.018867925) *
## 3) flipper_length>=206.5 106 6 Gentoo (0.018867925 0.037735849 0.943396226)
## 6) bill_depth>=17.2 8 4 Chinstrap (0.250000000 0.500000000 0.250000000) *
## 7) bill_depth< 17.2 98 0 Gentoo (0.000000000 0.000000000 1.000000000) *
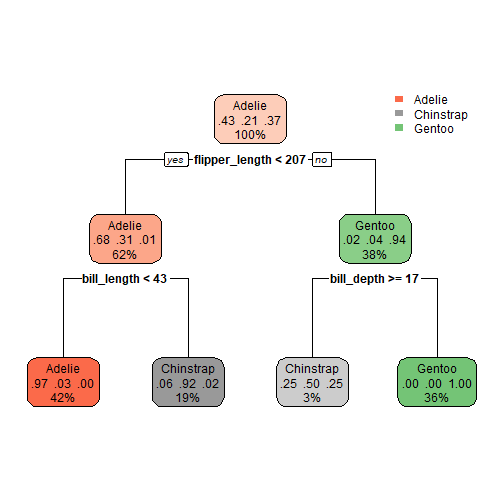
这个包也可以和其他决策树可视化R包无缝衔接,比如非常画图非常好看的rpart.plot:
library(rpart.plot)
## 载入需要的程辑包:rpart
rpart.plot(rr$learners[[5]]$model)
查看预测结果:
rr$prediction()
## for 344 observations:
## row_ids truth response prob.Adelie prob.Chinstrap prob.Gentoo
## 1 Adelie Adelie 0.96969697 0.03030303 0.00000000
## 4 Adelie Adelie 0.96969697 0.03030303 0.00000000
## 26 Adelie Adelie 0.96969697 0.03030303 0.00000000
## ---
## 333 Chinstrap Chinstrap 0.05660377 0.92452830 0.01886792
## 334 Chinstrap Chinstrap 0.05660377 0.92452830 0.01886792
## 335 Chinstrap Chinstrap 0.05660377 0.92452830 0.01886792
# 查看单个预测结果
rr$predictions()[[1]]
## for 69 observations:
## row_ids truth response prob.Adelie prob.Chinstrap prob.Gentoo
## 1 Adelie Adelie 0.96969697 0.03030303 0.00000000
## 4 Adelie Adelie 0.96969697 0.03030303 0.00000000
## 26 Adelie Adelie 0.96969697 0.03030303 0.00000000
## ---
## 338 Chinstrap Chinstrap 0.08888889 0.88888889 0.02222222
## 342 Chinstrap Chinstrap 0.08888889 0.88888889 0.02222222
## 344 Chinstrap Chinstrap 0.08888889 0.88888889 0.02222222
提取特定iteration的结果
rr$filter(c(3,5))
print(rr)
## of 2 iterations
## * Task: penguins
## * Learner: classif.rpart
## * Warnings: 0 in 0 iterations
## * Errors: 0 in 0 iterations
可视化结果:
task <- tsk("pima") # 非常著名的糖尿病数据集
task$select(c("glucose","mass"))
learner <- lrn("classif.rpart", predict_type = "prob")
resampling <- rsmp("cv")
rr <- resample(task, learner, resampling, store_models = T)
## INFO [20:47:13.436] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 5/10)
## INFO [20:47:13.449] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 6/10)
## INFO [20:47:13.461] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 9/10)
## INFO [20:47:13.473] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 8/10)
## INFO [20:47:13.488] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 3/10)
## INFO [20:47:13.501] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 1/10)
## INFO [20:47:13.513] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 10/10)
## INFO [20:47:13.524] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 4/10)
## INFO [20:47:13.536] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 7/10)
## INFO [20:47:13.548] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 2/10)
autoplot(rr, measure = msr("classif.auc"))
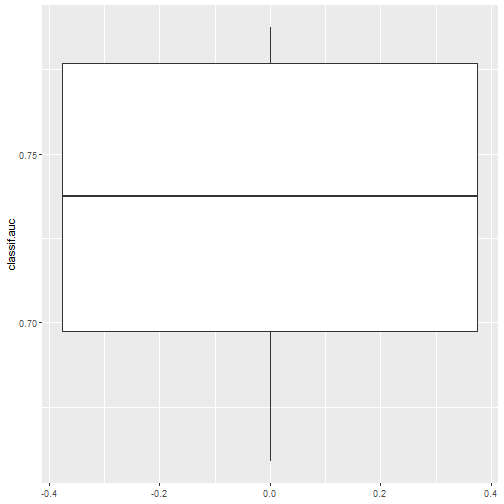
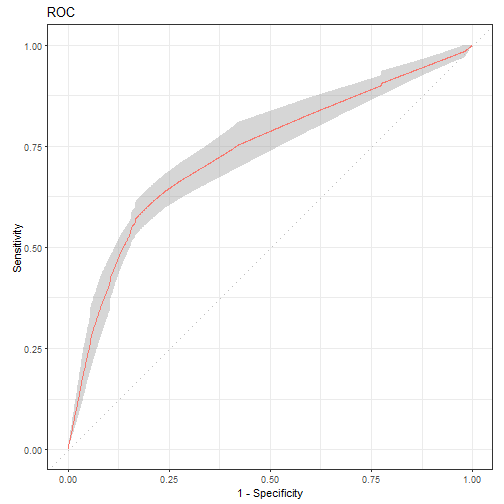
ROC曲线:10折交叉验证平均后的:
autoplot(rr, type = "roc")
树状图:
autoplot(rr, type = "prediction")

可视化单个模型:
rr1 <- rr$filter(1)
autoplot(rr1, type = "prediction")

所有支持的可视化类型可在此处找到:autoplot.ResampleResult
benchmark
用于比较多个模型,比如多个模型在单个任务的表现、多个模型在多个任务的表现等,使用不同的预处理进行的多个模型的表现等!
首先创建一个design
mlr3通过design进行比较多个模型,这个design是包含Task、Learner、Resampling的组合。
library(mlr3verse)
# 使用benchmark_grid函数创建
design <- benchmark_grid(
tasks = tsks(c("spam", "german_credit", "sonar")),
learners = lrns(c("classif.ranger", "classif.rpart", "classif.featureless"), predict_type = "prob"),
resamplings = rsmps(c("holdout", "cv"))
)
print(design)
## task learner resampling
## 1:
## 2:
## 3:
## 4:
## 5:
## 6:
## 7:
## 8:
## 9:
## 10:
## 11:
## 12:
## 13:
## 14:
## 15:
## 16:
## 17:
## 18:
然后进行比较,也是1行代码即可!
bmr <- benchmark(design, store_models = T)
## INFO [20:47:16.049] [mlr3] Running benchmark with 99 resampling iterations
## INFO [20:47:16.053] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 1/10)
## INFO [20:47:16.070] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 10/10)
## INFO [20:47:16.280] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 3/10)
## INFO [20:47:16.290] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 6/10)
## INFO [20:47:16.300] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 9/10)
## INFO [20:47:16.309] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 2/10)
## INFO [20:47:16.506] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 8/10)
## INFO [20:47:18.070] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 8/10)
## INFO [20:47:18.149] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 1/10)
## INFO [20:47:18.159] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 7/10)
## INFO [20:47:18.176] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 3/10)
## INFO [20:47:18.193] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 1/1)
## INFO [20:47:18.203] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 8/10)
## INFO [20:47:18.400] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 4/10)
## INFO [20:47:18.410] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 4/10)
## INFO [20:47:18.486] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 5/10)
## INFO [20:47:19.873] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 6/10)
## INFO [20:47:19.950] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 5/10)
## INFO [20:47:19.967] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 10/10)
## INFO [20:47:19.976] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 1/10)
## INFO [20:47:19.994] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 8/10)
## INFO [20:47:20.002] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 10/10)
## INFO [20:47:20.019] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 4/10)
## INFO [20:47:20.027] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 9/10)
## INFO [20:47:20.103] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 8/10)
## INFO [20:47:20.113] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 3/10)
## INFO [20:47:20.189] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 1/10)
## INFO [20:47:20.379] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 4/10)
## INFO [20:47:20.397] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 6/10)
## INFO [20:47:20.423] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 7/10)
## INFO [20:47:20.440] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 5/10)
## INFO [20:47:20.448] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 10/10)
## INFO [20:47:20.456] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 6/10)
## INFO [20:47:20.473] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 3/10)
## INFO [20:47:20.703] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 3/10)
## INFO [20:47:20.714] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 6/10)
## INFO [20:47:20.731] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 1/1)
## INFO [20:47:20.738] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 7/10)
## INFO [20:47:20.748] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 9/10)
## INFO [20:47:20.794] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 5/10)
## INFO [20:47:20.989] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 1/1)
## INFO [20:47:21.006] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 2/10)
## INFO [20:47:21.024] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 4/10)
## INFO [20:47:21.225] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 1/10)
## INFO [20:47:21.234] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 9/10)
## INFO [20:47:22.618] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 1/10)
## INFO [20:47:22.695] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 9/10)
## INFO [20:47:22.704] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 1/10)
## INFO [20:47:24.109] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 4/10)
## INFO [20:47:24.117] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 2/10)
## INFO [20:47:25.675] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 8/10)
## INFO [20:47:25.726] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 3/10)
## INFO [20:47:27.115] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 1/1)
## INFO [20:47:28.155] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 5/10)
## INFO [20:47:28.165] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 3/10)
## INFO [20:47:28.186] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 6/10)
## INFO [20:47:28.233] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 10/10)
## INFO [20:47:28.458] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 7/10)
## INFO [20:47:29.832] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 6/10)
## INFO [20:47:29.841] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 5/10)
## INFO [20:47:29.859] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 3/10)
## INFO [20:47:29.878] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 2/10)
## INFO [20:47:29.898] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 7/10)
## INFO [20:47:29.950] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 10/10)
## INFO [20:47:31.332] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 9/10)
## INFO [20:47:31.342] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 8/10)
## INFO [20:47:31.360] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 10/10)
## INFO [20:47:31.439] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 2/10)
## INFO [20:47:31.513] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 4/10)
## INFO [20:47:32.917] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 7/10)
## INFO [20:47:32.994] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 8/10)
## INFO [20:47:33.003] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 3/10)
## INFO [20:47:33.194] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 1/10)
## INFO [20:47:33.212] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 2/10)
## INFO [20:47:33.221] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 10/10)
## INFO [20:47:33.495] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 8/10)
## INFO [20:47:33.512] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 9/10)
## INFO [20:47:33.704] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 4/10)
## INFO [20:47:33.753] [mlr3] Applying learner 'classif.ranger' on task 'spam' (iter 6/10)
## INFO [20:47:35.136] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 10/10)
## INFO [20:47:35.147] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 6/10)
## INFO [20:47:35.332] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 5/10)
## INFO [20:47:35.380] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 7/10)
## INFO [20:47:35.581] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 1/1)
## INFO [20:47:35.643] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 2/10)
## INFO [20:47:35.653] [mlr3] Applying learner 'classif.ranger' on task 'german_credit' (iter 1/1)
## INFO [20:47:35.826] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 7/10)
## INFO [20:47:35.835] [mlr3] Applying learner 'classif.ranger' on task 'sonar' (iter 5/10)
## INFO [20:47:35.910] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 1/1)
## INFO [20:47:35.951] [mlr3] Applying learner 'classif.rpart' on task 'german_credit' (iter 9/10)
## INFO [20:47:35.969] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 5/10)
## INFO [20:47:35.980] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 1/1)
## INFO [20:47:35.997] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 4/10)
## INFO [20:47:36.257] [mlr3] Applying learner 'classif.featureless' on task 'sonar' (iter 1/1)
## INFO [20:47:36.264] [mlr3] Applying learner 'classif.featureless' on task 'spam' (iter 2/10)
## INFO [20:47:36.274] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 1/10)
## INFO [20:47:36.322] [mlr3] Applying learner 'classif.rpart' on task 'spam' (iter 2/10)
## INFO [20:47:36.366] [mlr3] Applying learner 'classif.featureless' on task 'german_credit' (iter 7/10)
## INFO [20:47:36.375] [mlr3] Applying learner 'classif.rpart' on task 'sonar' (iter 9/10)
## INFO [20:47:36.414] [mlr3] Finished benchmark
查看模型的表现,使用多种度量指标:
measures <- msrs(c("classif.acc", "classif.mcc"))
tab <- bmr$aggregate(measures)
print(tab)
## nr resample_result task_id learner_id resampling_id
## 1: 1 spam classif.ranger holdout
## 2: 2 spam classif.ranger cv
## 3: 3 spam classif.rpart holdout
## 4: 4 spam classif.rpart cv
## 5: 5 spam classif.featureless holdout
## 6: 6 spam classif.featureless cv
## 7: 7 german_credit classif.ranger holdout
## 8: 8 german_credit classif.ranger cv
## 9: 9 german_credit classif.rpart holdout
## 10: 10 german_credit classif.rpart cv
## 11: 11 german_credit classif.featureless holdout
## 12: 12 german_credit classif.featureless cv
## 13: 13 sonar classif.ranger holdout
## 14: 14 sonar classif.ranger cv
## 15: 15 sonar classif.rpart holdout
## 16: 16 sonar classif.rpart cv
## 17: 17 sonar classif.featureless holdout
## 18: 18 sonar classif.featureless cv
## iters classif.acc classif.mcc
## 1: 1 0.9445893 0.8835453
## 2: 10 0.9495723 0.8943582
## 3: 1 0.8917862 0.7725102
## 4: 10 0.8934967 0.7765629
## 5: 1 0.6069100 0.0000000
## 6: 10 0.6059511 0.0000000
## 7: 1 0.7567568 0.4358851
## 8: 10 0.7670000 0.3927548
## 9: 1 0.6996997 0.2847394
## 10: 10 0.7290000 0.2984376
## 11: 1 0.6516517 0.0000000
## 12: 10 0.7000000 0.0000000
## 13: 1 0.7971014 0.6247458
## 14: 10 0.8221429 0.6390361
## 15: 1 0.6956522 0.3981439
## 16: 10 0.6545238 0.3098052
## 17: 1 0.4782609 0.0000000
## 18: 10 0.5340476 0.0000000
可视化结果
library(ggplot2)
autoplot(bmr) + theme_bw() +
theme(axis.text.x = element_text(angle = 45,hjust = 1))

上面的图给出了多个模型在不同数据集中的平均表现,我们也可以查看多个模型在某一个特定数据集中的表现:
bmr_german <- bmr$clone(deep = T)$filter(task_ids = "german_credit",resampling_ids = "holdout")
autoplot(bmr_german, type = "roc")
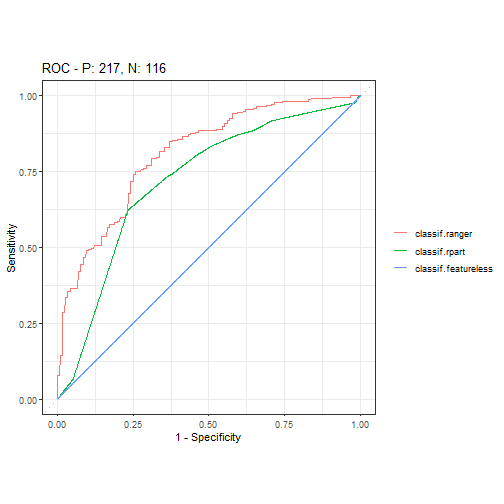
当然也可以只提取其中一个结果:
tab <- bmr$aggregate(measures)
rr <- tab[task_id == "german_credit" & learner_id == "classif.ranger"]$resample_result[[1]]
print(rr)
## of 1 iterations
## * Task: german_credit
## * Learner: classif.ranger
## * Warnings: 0 in 0 iterations
## * Errors: 0 in 0 iterations
查看一个结果的表现:
rr$aggregate(msr("classif.auc"))
## classif.auc
## 0.8085969
合并多个BenchmarkResult,比如在2台电脑上做了2个不同的benchmarks,可以直接合并成一个更大的对象:
task <- tsk("iris")
resampling <- rsmp("holdout")$instantiate(task)
rr1 <- resample(task, lrn("classif.rpart"), resampling)
## INFO [20:47:40.585] [mlr3] Applying learner 'classif.rpart' on task 'iris' (iter 1/1)
rr2 <- resample(task, lrn("classif.featureless"), resampling)
## INFO [20:47:40.606] [mlr3] Applying learner 'classif.featureless' on task 'iris' (iter 1/1)
# 通过以下代码合并结果
bmr1 <- as_benchmark_result(rr1)
bmr2 <- as_benchmark_result(rr2)
bmr1$combine(bmr2)
bmr1
## of 2 rows with 2 resampling runs
## nr task_id learner_id resampling_id iters warnings errors
## 1 iris classif.rpart holdout 1 0 0
## 2 iris classif.featureless holdout 1 0 0
获取更多R语言和生信知识,请关注公众号:医学和生信笔记。
公众号后台回复R语言,即可获得海量学习资料!