Python计算机视觉编程 第四章 照相机模型与增强现实
第四章 照相机模型与增强现实
- 4.1针孔照相机模型
-
- 4.1.1 照相机矩阵
- 4.1.2三维点的投影
- 4.1.3照相机矩阵的分解
- 4.1.4计算照相机中心
- 4.2照相机标定
- 4.3以平面和标记物体进行姿态估计
- 4.4增强现实
4.1针孔照相机模型
针孔照相机模型(有时称为射影照相机模型)是计算机视觉中广泛使用的照相机模型。对于大多数应用来说,针孔照相机模型简单,并且具有足够的精确度。在针孔照相机模型中,在光线投影到图像平面之前,从唯一一个点经过,也就是照相机中心C。下图为照相机中心前画出图像平面的图解。

4.1.1 照相机矩阵
照相机矩阵可以分解为:
P = K [ R ∣ t ] P=K\left [ R\mid t \right ] P=K[R∣t]
其中, R R R是描述照相机方向的旋转矩阵, t t t是描述照相机中心位置的三维平移向量, 内标定矩阵 K K K描述照相机的投影性质。
标定矩阵仅和照相机自身的情况相关,通常情况下可以写成:
K = [ α f s c x 0 f c y 0 0 1 ] K=\begin{bmatrix} \alpha f & s& c_{x}\\ 0 & f& c_{y}\\ 0 & 0& 1 \end{bmatrix} K=⎣ ⎡αf00sf0cxcy1⎦ ⎤
图像平面和照相机中心间的距离为焦距 f f f。当像素数组在传感器上偏斜的时候,需要用到倾斜参数 s s s。在大多数情况下, s s s可以设置成0。也就是说:
K = [ f x 0 c x 0 f y c y 0 0 1 ] , 其中 f x = α f y K=\begin{bmatrix} f_{x} & 0& c_{x}\\ 0 & f_{y}& c_{y}\\ 0 & 0& 1 \end{bmatrix},其中f_{x}=\alpha f_{y} K=⎣ ⎡fx000fy0cxcy1⎦ ⎤,其中fx=αfy
纵横比例参数 α 是在像素元素非正方形的情况下使用的。通常情况下,我们可以默认设置 α = 1 \alpha =1 α=1。经过这些假设,标定矩阵变为:
K = [ f 0 c x 0 f c y 0 0 1 ] K=\begin{bmatrix} f & 0& c_{x}\\ 0 & f& c_{y}\\ 0 & 0& 1 \end{bmatrix} K=⎣ ⎡f000f0cxcy1⎦ ⎤
除焦距之外,标定矩阵中剩余的唯一参数为光心(有时称主点)的坐标 c = [ c x , c y ] c=[c_{x},c_{y}] c=[cx,cy]也就是光线坐标轴和图像平面的交点。因为光通常在图像的中心,并且图像的坐标是从左上角开始计算的,所以光心的坐标常接近于图像宽度和高度的一半。特别强调一点,在这个例子中,唯一未知的变量是焦距 f f f。
4.1.2三维点的投影
下面来创建照相机的类,用于处理我们对照相机和投影建模所需要的全部操作。
创建一个Camera.py文件,并添加下列代码:
from scipy import linalg
import numpy as np
class Camera(object):
"""表示针孔照相机的类"""
def __init__(self, P): # 注意:需要左右各需要两个下划线
"""初始化P=K[R|t]照相机模型"""
self.P = P
self.K = None # 标定矩阵
self.R = None # 旋转
self.t = None # 平移
self.c = None # 照相机中心
def project(self, X):
"""X(4*n的数组)的投影点,并且进行坐标归一化"""
x = np.dot(self.P, X)
for i in range(3):
x[i] /= x[2]
return x
def rotation_matrix(a):
""" Creates a 3D rotation matrix for rotation
around the axis of the vector a. """
R = np.eye(4)
R[:3, :3] = linalg.expm([[0, -a[2], a[1]], [a[2], 0, -a[0]], [-a[1], a[0], 0]])
return R
# 该函数是一种矩阵因子分解方法,称为RQ因子分解。其结果不是唯一的,结果存在符号二义性。
def factor(self):
"""将照相机矩阵分解为K、R、t,其中,P=K[R|t]"""
# 分解前3*3的部分
K, R = linalg.rq(self.P[:, : 3])
# 将K的对角线元素设为正值
T = np.diag(np.sign(np.diag(K)))
if linalg.det(T) < 0:
T[1, 1] *= -1
self.K = np.dot(K, T)
self.R = np.dot(T, R) # T的逆矩阵为其自身
self.t = np.dot(linalg.inv(self.K), self.P[:, 3])
return self.K, self.R, self.t
# 计算照相机的中心
def center(self):
"""计算并返回照相机的中心"""
if self.c is not None:
return self.c
else:
# 通过因子分解计算c
self.factor()
self.c = -np.dot(self.R.T, self.t)
return self.c
我们使用牛津多视图数据集中的“Model Housing”数据集,可以从https://www.robots.ox.ac.uk/~vgg/data/dunster/3D.tar.gz下载,下载完成后将需要使用的house.p3d复制到项目中即可。
为了研究照相机的移动会如何改变投影的效果,可以使用rotation_matrix()函数创建一个向量进行三维旋转的旋转矩阵。
测试代码:
from Camera import *
from pylab import *
from numpy import *
points = loadtxt('house.p3d').T
points = vstack((points, ones(points.shape[1])))
# 设置相机参数
P = hstack((eye(3), array([[0], [0], [-10]])))
cam = Camera(P)
x = cam.project(points)
# 创建变换
r = 0.05 * random.random(3)
rot = Camera.rotation_matrix(r)
"""
# 绘制投影
figure()
plot(x[0], x[1], 'k.')
axis('off')
show()
"""
# 旋转矩阵和投影
figure()
for t in range(20):
cam.P = dot(cam.P, rot)
x = cam.project(points)
plot(x[0], x[1], 'k.')
show()
结果:



分析:
图像依次为样本图像、图像视图中投影后的点、照相机旋转后投影点的轨迹。多运行代码几次,进行不同的随机旋转之后,对点在投影中如何旋转有一些感觉。
在实验过程中,产生了如下图所示的错误:

搜索发现linalg模块不只在scipy中包含,同样也在numpy中包含。而我对scipy和numpy的调用方式如下如所示:

不过scipy中的linalg包括了numpy的线性代数求解模块,而且expm函数是scipy中特有的,因此在调用linalg最好用scipy中的。因此将调用方式改为:
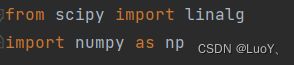
这样对numpy中的模块单独调用,此时linalg即为scipy中的模块。
4.1.3照相机矩阵的分解
如果给定如方程 P = K [ R ∣ t ] P=K\left [ R\mid t \right ] P=K[R∣t]所示的照相机矩阵 P P P,我们需要恢复内参数 K K K以及照相机的位置 t t t和姿势 R R R,将矩阵分块操作称为因子分解。这里我们将使用 R Q RQ RQ因子分解。
测试代码:
from Camera import *
from numpy import *
K = array([[1000,0,500],[0,1000,300],[0,0,1]])
tmp = Camera.rotation_matrix([0,0,1])[:3,:3]
Rt = hstack((tmp,array([[50],[40],[30]])))
cam = Camera(dot(K, Rt))
print(K, Rt)
print(cam.factor())
结果:

分析:
RQ 因子分解的结果并不是唯一的。在该因子分解中,分解的结果存在符号二义性。 由于我们需要限制旋转矩阵 R 为正定的(否则,旋转坐标轴即可),所以如果需要, 我们可以在求解到的结果中加入变换 T 来改变符号。
4.1.4计算照相机中心
给定照相机投影矩阵 P,我们可以计算出空间上照相机的所在位置。照相机的中心 C,是一个三维点,满足约束 PC=0。对于投影矩阵为 P = K [ R ∣ t ] P=K\left [ R\mid t \right ] P=K[R∣t]的照相机,有:
K [ R ∣ t ] C = K R C + K t = 0 K\left [ R\mid t \right ]C=KRC+Kt=0 K[R∣t]C=KRC+Kt=0
照相机的中心可以由下述式子来计算:
C = − R T t C=-R^{T}t C=−RTt
照相机的中心与内标定矩阵 K K K无关。
4.2照相机标定
相机标定的目的:获取摄像机的内参和外参矩阵(同时也会得到每一幅标定图像的选择和平移矩阵),内参和外参系数可以对之后相机拍摄的图像就进行矫正,得到畸变相对很小的图像。
但是标定工具需要有极高的精度,包括不同平面的角度、特征点的物理距离等,因此制作标定工具十分困难。在2000年华人科学家张正友发现了一种不需要高精度标定板就可以标定出相机参数的很有效的方式。下面对张正友标定法的原理做一些介绍。
一些形式化描述:
2D图像点: m = [ u , v ] T \pmb m=[u,v]^{T} mm=[u,v]T
3D空间点: M = [ X , Y , Z ] T \pmb M=[X,Y,Z]^{T} MM=[X,Y,Z]T
齐次坐标: m ~ = [ u , v , 1 ] T , M ~ = [ X , Y , Z , 1 ] T \widetilde{\pmb m}=[u,v,1]^{T},\widetilde{\pmb M}=[X,Y,Z,1]^{T} mm =[u,v,1]T,MM =[X,Y,Z,1]T
描述空间坐标到图像坐标的映射:
s m ~ = K [ R ∣ r ] M ~ , M = [ α γ u 0 0 β v 0 0 0 1 ] s\widetilde{\pmb m}=\pmb K[\pmb R\mid \pmb r]\widetilde{\pmb M},\pmb M=\begin{bmatrix}\alpha & \gamma & u_{0}\\ 0& \beta & v_{0}\\0 & 0 &1 \end{bmatrix} smm =KK[RR∣rr]MM ,MM=⎣ ⎡α00γβ0u0v01⎦ ⎤
其中 s s s表示世界坐标系到图像坐标系的尺度因子, K \pmb K KK表示相机内参数矩阵, ( u 0 , v 0 ) (u_{0},v_{0}) (u0,v0)表示主点坐标, α 和 β \alpha和\beta α和β表示焦距与像素横纵比的融合, γ \gamma γ表示径向畸变参数。
计算过程:
不放假设棋盘格位于 Z = 0 Z=0 Z=0,定义旋转矩阵 R \pmb R RR的第 i i i列为 r i \pmb r_{i} rri,则有:
s [ u v 1 ] = K [ r 1 r 2 r 3 t ] [ X Y 0 1 ] = K [ r 1 r 2 t ] [ X Y 1 ] s\left[\begin{array}{l} u \\ v \\ 1 \end{array}\right]=K\left[\begin{array}{llll} \mathbf{r}_{1} & \mathbf{r}_{2} & \mathbf{r}_{3} & \mathbf{t} \end{array}\right]\left[\begin{array}{c} X \\ Y \\ 0 \\ 1 \end{array}\right]=K\left[\begin{array}{lll} \mathbf{r}_{1} & \mathbf{r}_{2} & \mathbf{t} \end{array}\right]\left[\begin{array}{c} X \\ Y \\ 1 \end{array}\right] s⎣ ⎡uv1⎦ ⎤=K[r1r2r3t]⎣ ⎡XY01⎦ ⎤=K[r1r2t]⎣ ⎡XY1⎦ ⎤
于是空间到图像的映射可改为: s m ~ = H M ~ , H = K [ r 1 , r 2 , t ] s\widetilde{\pmb m}=\pmb H\widetilde{\pmb M},\pmb H=\pmb K[\pmb r_{1},\pmb r_{2},\pmb t] smm =HHMM ,HH=KK[rr1,rr2,tt],其中 H \pmb H HH是单应性变换Homographic矩阵,可通过最小二乘,从角点世界坐标到图像坐标的关系求解。
令H为 H = [ h 1 , h 2 , h 3 ] \pmb H=[\pmb h_{1},\pmb h_{2},\pmb h_{3}] HH=[hh1,hh2,hh3], [ h 1 , h 2 , h 3 ] = λ K [ r 1 , r 2 , t ] [\pmb h_{1},\pmb h_{2},\pmb h_{3}]=\lambda \pmb K[\pmb r_{1},\pmb r_{2},\pmb t] [hh1,hh2,hh3]=λKK[rr1,rr2,tt],Homography有8个自由度,由 r 1 和 r 2 \pmb r_{1}和\pmb r_{2} rr1和rr2正交且模相等,可以得到如下约束: K − 1 [ h 1 , h 2 , h 3 ] = λ [ r 1 , r 2 , t ] \pmb K^{-1}[\pmb h_{1},\pmb h_{2},\pmb h_{3}]=\lambda[\pmb r_{1},\pmb r_{2},\pmb t] KK−1[hh1,hh2,hh3]=λ[rr1,rr2,tt]
r 1 T r 2 = 0 ⇒ h 1 T K − T K − 1 h 2 = 0 \pmb r_{1}^{T}\pmb r_{2}=0 \Rightarrow\pmb h_{1}^{T}\pmb K^{-T}\pmb K^{-1}\pmb h_{2}=0 rr1Trr2=0⇒hh1TKK−TKK−1hh2=0
∥ r 1 ∥ = ∥ r 2 ∥ ⇒ h 1 T K − T K − 1 h 1 = h 2 T K − T K − 1 h 2 \left \| \pmb r_{1} \right \|=\left \| \pmb r_{2} \right \|\Rightarrow\pmb h_{1}^{T}\pmb K^{-T}\pmb K^{-1}\pmb h_{1}=\pmb h_{2}^{T}\pmb K^{-T}\pmb K^{-1}\pmb h_{2} ∥rr1∥=∥rr2∥⇒hh1TKK−TKK−1hh1=hh2TKK−TKK−1hh2
定义 B = K − T K − 1 = [ B 11 B 21 B 31 B 12 B 22 B 32 B 13 B 23 B 33 ] \pmb B=\pmb K^{-T}\pmb K^{-1}=\left[\begin{array}{lll} B_{11} & B_{21} & B_{31} \\ B_{12} & B_{22} & B_{32} \\ B_{13} & B_{23} & B_{33} \end{array}\right] BB=KK−TKK−1=⎣ ⎡B11B12B13B21B22B23B31B32B33⎦ ⎤
= [ 1 α 2 − γ α 2 β v 0 γ − u 0 β α 2 β − γ α 2 β γ 2 α 2 β 2 + 1 β 2 − γ ( v 0 γ − u 0 β ) α 2 β 2 − v 0 2 β 2 v 0 γ − u 0 β α 2 β − γ ( v 0 γ − u 0 β ) α 2 β 2 − v 0 2 β 2 ( v 0 γ − u 0 β ) 2 α 2 β 2 + v 0 2 β 2 + 1 ] =\left[\begin{array}{ccc} \frac{1}{\alpha^{2}} & -\frac{\gamma}{\alpha^{2} \beta} & \frac{v_{0} \gamma-u_{0} \beta}{\alpha^{2} \beta} \\ -\frac{\gamma}{\alpha^{2} \beta} & \frac{\gamma^{2}}{\alpha^{2} \beta^{2}}+\frac{1}{\beta^{2}} & -\frac{\gamma\left(v_{0} \gamma-u_{0} \beta\right)}{\alpha^{2} \beta^{2}}-\frac{v_{0}^{2}}{\beta^{2}} \\ \frac{v_{0} \gamma-u_{0} \beta}{\alpha^{2} \beta} & -\frac{\gamma\left(v_{0} \gamma-u_{0} \beta\right)}{\alpha^{2} \beta^{2}}-\frac{v_{0}^{2}}{\beta^{2}} & \frac{\left(v_{0} \gamma-u_{0} \beta\right)^{2}}{\alpha^{2} \beta^{2}}+\frac{v_{0}^{2}}{\beta^{2}}+1 \end{array}\right] =⎣ ⎡α21−α2βγα2βv0γ−u0β−α2βγα2β2γ2+β21−α2β2γ(v0γ−u0β)−β2v02α2βv0γ−u0β−α2β2γ(v0γ−u0β)−β2v02α2β2(v0γ−u0β)2+β2v02+1⎦ ⎤
B \pmb B BB是对称阵,其未知量科表示为6D向量 b \pmb b bb, b = [ B 11 , B 12 , B 22 , B 13 , B 23 , B 33 ] T \pmb b=[B_{11},B_{12},B_{22},B_{13},B_{23},B_{33}]^{T} bb=[B11,B12,B22,B13,B23,B33]T
设H中的第 i i i列为 h i \pmb h_{i} hhi, h i = [ h i 1 , h i 2 , h i 3 ] T \pmb h_{i}=[h_{i1},h_{i2},h_{i3}]^{T} hhi=[hi1,hi2,hi3]T,根据 b \pmb b bb的定义,可以推导出公式: h i T B h j = v i j T b \pmb h_{i}^{T}\pmb B\pmb h_{j}=\pmb v_{ij}^{T}\pmb b hhiTBBhhj=vvijTbb
其中 v i j = [ h i 1 h j 1 , h i 1 h j 2 + h i 2 h j 1 , h i 2 h j 2 , h i 3 h j 1 + h i 1 h j 3 , h i 3 h j 2 + h i 2 h j 3 , h i 3 h j 3 ] T \pmb v_{ij}=[h_{i1}h_{j1},h_{i1}h_{j2}+h_{i2}h_{j1},h_{i2}h_{j2},h_{i3}h_{j1}+h_{i1}h_{j3},h_{i3}h_{j2}+h_{i2}h_{j3},h_{i3}h_{j3}]^{T} vvij=[hi1hj1,hi1hj2+hi2hj1,hi2hj2,hi3hj1+hi1hj3,hi3hj2+hi2hj3,hi3hj3]T
可以推导出 [ v 12 T ( v 11 − v 22 ) T ] b = 0 \left[\begin{array}{c} \mathbf{v}_{12}^{T} \\ \left(\mathbf{v}_{11}-\mathbf{v}_{22}\right)^{T} \end{array}\right] \mathbf{b}=0 [v12T(v11−v22)T]b=0,如果有 n n n组观察图像,则 v \pmb v vv是 2 n × 6 2n\times 6 2n×6的矩阵 v b = 0 \pmb v\pmb b=0 vvbb=0,根据最小二乘定义, v b = 0 \pmb v\pmb b=0 vvbb=0的解是 v T v \pmb v^{T}\pmb v vvTvv最小特征值对应的特征向量。因此可以直接估算出 b \pmb b bb,后续可以通过 b \pmb b bb求解出内参。
内部参数可通过如下公式计算(cholesky分解):
v 0 = ( B 12 B 13 − B 11 B 23 ) / ( B 11 B 22 − B 12 2 ) v_{0}=(B_{12} B_{13}-B_{11} B_{23}) /(B_{11} B_{22}-B_{12}^{2}) v0=(B12B13−B11B23)/(B11B22−B122)
λ = B 33 − [ B 13 2 + v 0 ( B 12 B 13 − B 11 B 23 ) ] / B 11 \lambda=B_{33}-\left[B_{13}^{2}+v_{0}\left(B_{12} B_{13}-B_{11} B_{23}\right)\right] / B_{11} λ=B33−[B132+v0(B12B13−B11B23)]/B11
α = λ / B 11 \alpha=\sqrt{\lambda / B_{11}} α=λ/B11
β = λ B 11 / ( B 11 B 22 − B 12 2 ) \beta=\sqrt{\lambda B_{11} /\left(B_{11} B_{22}-B_{12}^{2}\right)} β=λB11/(B11B22−B122)
γ = − B 12 α 2 β / λ \gamma=-B_{12} \alpha^{2} \beta / \lambda γ=−B12α2β/λ
u 0 = γ v 0 / α − B 13 α 2 / λ u_{0}=\gamma v_{0} / \alpha-B_{13} \alpha^{2} / \lambda u0=γv0/α−B13α2/λ
外部参数可通过Homography求解,由 H = [ h 1 , h 2 , h 3 ] = λ K [ r 1 , r 2 , t ] \pmb H=[\pmb h_{1},\pmb h_{2},\pmb h_{3}]=\lambda \pmb K[\pmb r_{1},\pmb r_{2},\pmb t] HH=[hh1,hh2,hh3]=λKK[rr1,rr2,tt]可推出:
r 1 = λ K − 1 h 1 \pmb r_{1}=\lambda \pmb K^{-1}\pmb h_{1} rr1=λKK−1hh1, r 2 = λ K − 1 h 2 \pmb r_{2}=\lambda \pmb K^{-1}\pmb h_{2} rr2=λKK−1hh2, r 3 = r 1 × r 2 \pmb r_{3}=\pmb r_{1}\times \pmb r_{2} rr3=rr1×rr2, t = λ K − 1 h 3 \pmb t=\lambda\pmb K^{-1}\pmb h_{3} tt=λKK−1hh3, λ = 1 / ∥ K − 1 h 1 ∥ = 1 / ∥ K − 1 h 2 ∥ \lambda=1/\left \| \pmb K^{-1}\pmb h_{1} \right \|=1/\left \| \pmb K^{-1}\pmb h_{2} \right \| λ=1/∥ ∥KK−1hh1∥ ∥=1/∥ ∥KK−1hh2∥ ∥。
下面通过实验来实现张正友标定法对照相机进行标定。我准备的是下图这种格子数为9×6,内角点为8×5的棋盘格图片,手机型号为oneplus9pro。

代码:
import cv2
import numpy as np
import glob
# 设置寻找亚像素角点的参数,采用的停止准则是最大循环次数30和最大误差容限0.001
criteria = (cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS, 30, 0.001)
# 获取标定板角点的位置
objp = np.zeros((5 * 8, 3), np.float32)
objp[:, :2] = np.mgrid[0:8, 0:5].T.reshape(-1, 2) # 将世界坐标系建在标定板上,所有点的Z坐标全部为0,所以只需要赋值x和y
obj_points = [] # 存储3D点
img_points = [] # 存储2D点
images = glob.glob("imageqipan/*.jpg")
i=0;
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
size = gray.shape[::-1]
ret, corners = cv2.findChessboardCorners(gray, (8, 5), None)
#print(corners)
if ret:
obj_points.append(objp)
corners2 = cv2.cornerSubPix(gray, corners, (5, 5), (-1, -1), criteria) # 在原角点的基础上寻找亚像素角点
#print(corners2)
if [corners2]:
img_points.append(corners2)
else:
img_points.append(corners)
cv2.drawChessboardCorners(img, (8, 5), corners, ret) # 记住,OpenCV的绘制函数一般无返回值
i+=1;
cv2.imwrite('conimg'+str(i)+'.jpg', img)
cv2.waitKey(1500)
print(len(img_points))
cv2.destroyAllWindows()
# 标定
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(obj_points, img_points, size, None, None)
print("ret:", ret)
print("mtx:\n", mtx) # 内参数矩阵
print("dist:\n", dist) # 畸变系数 distortion cofficients = (k_1,k_2,p_1,p_2,k_3)
print("rvecs:\n", rvecs) # 旋转向量 # 外参数
print("tvecs:\n", tvecs ) # 平移向量 # 外参数
print("-----------------------------------------------------")
img = cv2.imread(images[2])
h, w = img.shape[:2]
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx,dist,(w,h),1,(w,h))#显示更大范围的图片(正常重映射之后会删掉一部分图像)
print (newcameramtx)
print("------------------使用undistort函数-------------------")
dst = cv2.undistort(img,mtx,dist,None,newcameramtx)
x,y,w,h = roi
dst1 = dst[y:y+h,x:x+w]
cv2.imwrite('calibresult3.jpg', dst1)
print ("方法一:dst的大小为:", dst1.shape)
结果:


畸变矫正前的图像:

畸变矫正后的图像:

分析:
从实验结果中可以看到成功计算出了照相机内部参数和外部参数。但是畸变矫正的结果很不理想。这是因为现在手机相机已经做的很好了,拍摄的图片基本没有畸变。而由于棋盘格的精度不足以及拍摄的照片的因素导致畸变矩阵偏离实际,使得畸变矫正反而产生了不好的结果。
同时在实验过程中也体会到了张正友标定法的优点和一些问题:首先张正友标定法克服了传统标定法需要的高精度标定物、算法复杂的缺点,而仅需使用一个打印出来的棋盘格就可以。而且使用方便,标定简单,相机和标定板可以任意放置,只需要计算出几个参数就可以得到标定数据。
但是该方法标定结果的好坏和输入标定图像相关,会导致多次标定结果不一致。同时如果相机镜头存在非径向和切向的非线性畸变,该方法并不能进行处理。大畸变镜头需要手动进行内参初始化,因为这时用H矩阵求初值不准。
4.3以平面和标记物体进行姿态估计
如果图像中包含平面状的标记物体,并且以对照相机进行了标定,那么我们可以计算出照相机的姿态(旋转和平移)。这里的标记物可以为对任何平坦的物体。
首先要提取两幅图像的SIFT特征,然后使用RANSAC算法稳健地估计单应性矩阵。定义相应的三维坐标系,是标记物在X-Y平面上,原点在标记物的某个位置上。这样就有了单应性矩阵和照相机的标定矩阵,这样就可以得出两个视图间的相对变换。最后可视化投影后的点。
完整代码如下:
from pylab import *
from PIL import Image
from PCV.geometry import homography, camera
from PCV.localdescriptors import sift
"""
This is the augmented reality and pose estimation cube example from Section 4.3.
"""
def cube_points(c, wid):
""" Creates a list of points for plotting
a cube with plot. (the first 5 points are
the bottom square, some sides repeated). """
p = []
# bottom
p.append([c[0] - wid, c[1] - wid, c[2] - wid])
p.append([c[0] - wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] - wid, c[2] - wid])
p.append([c[0] - wid, c[1] - wid, c[2] - wid]) # same as first to close plot
# top
p.append([c[0] - wid, c[1] - wid, c[2] + wid])
p.append([c[0] - wid, c[1] + wid, c[2] + wid])
p.append([c[0] + wid, c[1] + wid, c[2] + wid])
p.append([c[0] + wid, c[1] - wid, c[2] + wid])
p.append([c[0] - wid, c[1] - wid, c[2] + wid]) # same as first to close plot
# vertical sides
p.append([c[0] - wid, c[1] - wid, c[2] + wid])
p.append([c[0] - wid, c[1] + wid, c[2] + wid])
p.append([c[0] - wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] + wid, c[2] + wid])
p.append([c[0] + wid, c[1] - wid, c[2] + wid])
p.append([c[0] + wid, c[1] - wid, c[2] - wid])
return array(p).T
def my_calibration(sz):
"""
Calibration function for the camera (iPhone4) used in this example.
"""
row, col = sz
fx = 2555 * col / 2592
fy = 2586 * row / 1936
K = diag([fx, fy, 1])
K[0, 2] = 0.5 * col
K[1, 2] = 0.5 * row
return K
# compute features
sift.process_image('book0.jpg', 'im0.sift')
l0, d0 = sift.read_features_from_file('im0.sift')
sift.process_image('book1.jpg', 'im1.sift')
l1, d1 = sift.read_features_from_file('im1.sift')
# match features and estimate homography
matches = sift.match_twosided(d0, d1)
ndx = matches.nonzero()[0]
fp = homography.make_homog(l0[ndx, :2].T)
ndx2 = [int(matches[i]) for i in ndx]
tp = homography.make_homog(l1[ndx2, :2].T)
model = homography.RansacModel()
H, inliers = homography.H_from_ransac(fp, tp, model)
# camera calibration
K = my_calibration((747, 1000))
# 3D points at plane z=0 with sides of length 0.2
box = cube_points([0, 0, 0.1], 0.1)
# project bottom square in first image
cam1 = camera.Camera(hstack((K, dot(K, array([[0], [0], [-1]])))))
# first points are the bottom square
box_cam1 = cam1.project(homography.make_homog(box[:, :5]))
# use H to transfer points to the second image
box_trans = homography.normalize(dot(H, box_cam1))
# compute second camera matrix from cam1 and H
cam2 = camera.Camera(dot(H, cam1.P))
A = dot(linalg.inv(K), cam2.P[:, :3])
A = array([A[:, 0], A[:, 1], cross(A[:, 0], A[:, 1])]).T
cam2.P[:, :3] = dot(K, A)
# project with the second camera
box_cam2 = cam2.project(homography.make_homog(box))
# plotting
im0 = array(Image.open('book0.jpg'))
im1 = array(Image.open('book1.jpg'))
figure()
imshow(im0)
plot(box_cam1[0, :], box_cam1[1, :], linewidth=3)
title('2D projection of bottom square')
axis('off')
figure()
imshow(im1)
plot(box_trans[0, :], box_trans[1, :], linewidth=3)
title('2D projection transfered with H')
axis('off')
figure()
imshow(im1)
plot(box_cam2[0, :], box_cam2[1, :], linewidth=3)
title('3D points projected in second image')
axis('off')
show()
结果:


4.4增强现实
增强现实(Augmented Reality,AR)是将物体和相应信息放置在图像数据上的一 系列操作的总称。最经典的例子是放置一个三维计算机图形学模型,使其看起来属于该场景;如果在视频中,该模型会随着照相机的运动很自然地移动。如上一节所示,给定一幅带有标记平面的图像,我们能够计算出照相机的位置和姿态,使用这些信息来放置计算机图形学模型,能够正确表示它们。
首先要安装用到两个的工具包:pygame和PyOpenGL。
在文件所在目录,利用shift+鼠标右键,打开powershell窗口,输入pip debug可以查看自己的Python可以支持下载的的版本。选择合适的版本下载。

1、pygame:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pygame
2、PyOpenGL:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyopengl
下载好了以后,将文件复制到项目文件夹中,利用shift+鼠标右键,打开powershell窗口,输入pip install 文件名进行安装。但是在实验过程中总是发生如下错误:

找了很久才发现,在Python Interpreter中并没有我们安装的这两个包,而在终端中输入pip list发现我们确实已经成功安装了这两个包。
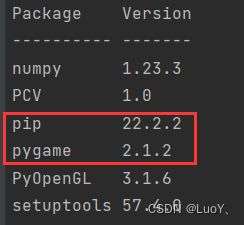
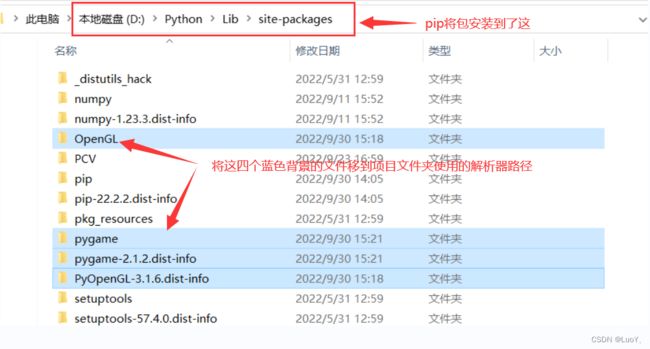
查找资料后发现,windows环境下,pip会将下载的第三方包存放在python的安装位置下。只需要在这个文件夹下,找到我们要引用的包,复制到项目文件夹使用的解释器路径下,即可使用。如下图所示:
我们可以通过下面的代码检测是否成功安装:
from OpenGL.GL import *
from OpenGL.GLUT import *
def drawFunc():
glClear(GL_COLOR_BUFFER_BIT)
glutWireTeapot(0.5)
glFlush()
glutInit()
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA)
glutInitWindowSize(400, 400)
glutCreateWindow(b"First")
glutDisplayFunc(drawFunc)
glutMainLoop()
结果输出了下图所示的茶壶就说明成功了!

接下来实现在图像中放置茶壶。
完整代码:
import math
import pickle
from PIL import Image
from pylab import *
from OpenGL.GL import *
from OpenGL.GLU import *
from OpenGL.GLUT import *
import pygame, pygame.image
from pygame.locals import *
from PCV.geometry import homography, camera
from PCV.localdescriptors import sift
def cube_points(c, wid):
""" Creates a list of points for plotting
a cube with plot. (the first 5 points are
the bottom square, some sides repeated). """
p = []
# bottom
p.append([c[0] - wid, c[1] - wid, c[2] - wid])
p.append([c[0] - wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] - wid, c[2] - wid])
p.append([c[0] - wid, c[1] - wid, c[2] - wid]) # same as first to close plot
# top
p.append([c[0] - wid, c[1] - wid, c[2] + wid])
p.append([c[0] - wid, c[1] + wid, c[2] + wid])
p.append([c[0] + wid, c[1] + wid, c[2] + wid])
p.append([c[0] + wid, c[1] - wid, c[2] + wid])
p.append([c[0] - wid, c[1] - wid, c[2] + wid]) # same as first to close plot
# vertical sides
p.append([c[0] - wid, c[1] - wid, c[2] + wid])
p.append([c[0] - wid, c[1] + wid, c[2] + wid])
p.append([c[0] - wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] + wid, c[2] - wid])
p.append([c[0] + wid, c[1] + wid, c[2] + wid])
p.append([c[0] + wid, c[1] - wid, c[2] + wid])
p.append([c[0] + wid, c[1] - wid, c[2] - wid])
return array(p).T
def my_calibration(sz):
row, col = sz
fx = 2555 * col / 2592
fy = 2586 * row / 1936
K = diag([fx, fy, 1])
K[0, 2] = 0.5 * col
K[1, 2] = 0.5 * row
return K
def set_projection_from_camera(K):
glMatrixMode(GL_PROJECTION)
glLoadIdentity()
fx = K[0, 0]
fy = K[1, 1]
fovy = 2 * math.atan(0.5 * height / fy) * 180 / math.pi
aspect = (width * fy) / (height * fx)
near = 0.1
far = 100.0
gluPerspective(fovy, aspect, near, far)
glViewport(0, 0, width, height)
def set_modelview_from_camera(Rt):
glMatrixMode(GL_MODELVIEW)
glLoadIdentity()
Rx = np.array([[1, 0, 0], [0, 0, -1], [0, 1, 0]])
R = Rt[:, :3]
U, S, V = np.linalg.svd(R)
R = np.dot(U, V)
R[0, :] = -R[0, :]
t = Rt[:, 3]
M = np.eye(4)
M[:3, :3] = np.dot(R, Rx)
M[:3, 3] = t
M = M.T
m = M.flatten()
glLoadMatrixf(m)
def draw_background(imname):
bg_image = pygame.image.load(imname).convert()
bg_data = pygame.image.tostring(bg_image, "RGBX", 1)
glMatrixMode(GL_MODELVIEW)
glLoadIdentity()
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
glEnable(GL_TEXTURE_2D)
glBindTexture(GL_TEXTURE_2D, glGenTextures(1))
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, bg_data)
glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST)
glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST)
glBegin(GL_QUADS)
glTexCoord2f(0.0, 0.0);
glVertex3f(-1.0, -1.0, -1.0)
glTexCoord2f(1.0, 0.0);
glVertex3f(1.0, -1.0, -1.0)
glTexCoord2f(1.0, 1.0);
glVertex3f(1.0, 1.0, -1.0)
glTexCoord2f(0.0, 1.0);
glVertex3f(-1.0, 1.0, -1.0)
glEnd()
glDeleteTextures(1)
def draw_teapot(size):
glEnable(GL_LIGHTING)
glEnable(GL_LIGHT0)
glEnable(GL_DEPTH_TEST)
glClear(GL_DEPTH_BUFFER_BIT)
glMaterialfv(GL_FRONT, GL_AMBIENT, [0, 0, 0, 0])
glMaterialfv(GL_FRONT, GL_DIFFUSE, [0.5, 0.0, 0.0, 0.0])
glMaterialfv(GL_FRONT, GL_SPECULAR, [0.7, 0.6, 0.6, 0.0])
glMaterialf(GL_FRONT, GL_SHININESS, 0.25 * 128.0)
glutInit()
glutSolidTeapot(size)
width, height = 850, 1100
def setup():
pygame.init()
pygame.display.set_mode((width, height), OPENGL | DOUBLEBUF)
pygame.display.set_caption("OpenGL AR demo")
sift.process_image('book0.jpg', 'im0.sift')
l0, d0 = sift.read_features_from_file('im0.sift')
sift.process_image('book1.jpg', 'im1.sift')
l1, d1 = sift.read_features_from_file('im1.sift')
# match features and estimate homography
matches = sift.match_twosided(d0, d1)
ndx = matches.nonzero()[0]
fp = homography.make_homog(l0[ndx, :2].T)
ndx2 = [int(matches[i]) for i in ndx]
tp = homography.make_homog(l1[ndx2, :2].T)
model = homography.RansacModel()
H, inliers = homography.H_from_ransac(fp, tp, model)
K = my_calibration((747, 1000))
cam1 = camera.Camera(hstack((K, dot(K, array([[0], [0], [-1]])))))
box = cube_points([0, 0, 0.1], 0.1)
box_cam1 = cam1.project(homography.make_homog(box[:, :5]))
box_trans = homography.normalize(dot(H, box_cam1))
cam2 = camera.Camera(dot(H, cam1.P))
A = dot(linalg.inv(K), cam2.P[:, :3])
A = array([A[:, 0], A[:, 1], cross(A[:, 0], A[:, 1])]).T
cam2.P[:, :3] = dot(K, A)
Rt = dot(linalg.inv(K), cam2.P)
setup()
draw_background("book0.jpg")
set_projection_from_camera(K)
set_modelview_from_camera(Rt)
draw_teapot(0.05)
pygame.display.flip()
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
sys.exit()
结果1:
结果2:

分析:
实验过程中,程序再一次报错,freeglut ERROR: Function glutSolidTeapot called without first calling ‘glutInit’,如下图所示:

这个错误是freeglut和glut共存的缘故,它们俩定义了相同的方法,这个是动态链接库的重叠问题,网上很多解决办法都是在OpenGL\DLLS文件夹里面,删除一个文件就行,但是一直没有解决问题。尝试了很久,在调用glutSolidTeapot之前再调用一次glutinit,只不过glutinit的两个参数设为空值,终于解决了问题,并且得到了结果1。

出现结果1的原因是因为没有将窗口设置为图像的大小,修改一下width, height的参数就可以得到结果2了。