深圳进化动力机器视觉算法岗面试题
来源:投稿 作者:LSC
编辑:学姐
基础题
1.介绍自己,课内情况,能实习多长等。
2.介绍自己做过的两个项目。
3.介绍图像分类的知识。
我讲了AlexNet、VggNet、ResNet、DenseNet、EffiencientNet等,以及里面用到的tricks
AlexNet:
- (1)使用GPU训练,
- (2) 使用了数据增强
- (3) 使用了LRN(BN的前身,也是标准化的一种)
- (4) 使用了Dropout
VggNet网络深度更加大,进一步扩展,用2个33的卷积核代替了55的卷积核。
ResNet的残差结构,使得网络深度可以进一步加深。
InceptionNet使用了并行分支的方法,将不同尺度的特征信息进行融合,提取更多有效的特征,减少信息损失。
DenseNet将所有特征连接起来,尽可能做到特征信息的不浪费。
EfficientNet在网络深度、宽度、分辨率3个维度对模型进行强化。
4.介绍一下BN(批标准化),BN是在哪个维度进行的
BN对当前batch数据进行标准化后,再进行线性映射,训练scale与shift参数。是在batch这个维度上对每个批次的数据进行求均值、方差并标准化。
5.介绍一下Dropout
随机失活,让神经元或者网络层以一定的概率在每轮训练中不参与训练。
6.Dropout是怎么实现神经元失活的
每个神经元或者网络层以一定的概率不参与训练,也就是让其输出为0。
7.为什么Dropout可以减少过拟合
这个问题我回答的不好,面试结束后查阅了一些资料。
在较大程度上减小了网络的大小: 在这个“残缺”的网络中,让神经网络学习数据中的局部特征(即部分分布式特征),但这些特征也足以进行输出正确的结果。
每次训练随机dropout掉不同的隐藏神经元,网络结构已经不同,这就类似在训练不同的网络,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
减少神经元之间共适应关系: 因为dropout导致两个神经元不一定每次都在一个网络中出现,这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况,迫使网络去学习更加鲁棒的特征。
8.为什么BN可以减少过拟合
这个问题我也回答的不好,后续查阅了一些资料,网上说BN不能防止过拟合。
BN的核心思想不是为了防止梯度消失或者是防止过拟合,其核心思想是通过系统参数搜索空间进行约束来增加系统鲁棒性,这种约束压缩了搜索空间,约束也改善了系统的结构合理性,这会带来一些列的性能改善,比如加速收敛、保证梯度、缓解过拟合等等。
9.介绍一下目标检测
我讲了RCNN系列和Yolo系列。主要详细讲了Yolo系列,从v1到v5,讲了好多,资料可以上网详查。
推荐以下知乎文章: https://zhuanlan.zhihu.com/p/143747206 https://zhuanlan.zhihu.com/p/172121380 https://zhuanlan.zhihu.com/p/183261974 https://zhuanlan.zhihu.com/p/183781646 https://zhuanlan.zhihu.com/p/186014243 https://zhuanlan.zhihu.com/p/483446554 https://zhuanlan.zhihu.com/p/485059645
10.如果神经网络模型在训练过程中只能调整两个参数,会选择调整哪两个?
batch_size和learning_rate
11.神经网络训练过程中是不是必须使用激活函数,可以不用吗?常用的激活函数有哪些?
必须使用。不使用的话就神经网络本质上就等价于线性关系式,只有使用激活函数神经网络才能无限逼近于任何函数。sigmoid、tanh、relu、leaky relu、logistic函数等。
场景题
(1) 怎么做一个上班门禁的人脸识别模型,需要什么数据,假设这个公司30个人,可以满足你提出的任何条件。
答:需要这30人每个人的人脸数据,在不同的条件、环境下的包含人脸正脸的照片,包含了各种不同条件比如光照不同、角度不同、背景不同等。每人需要拍10万张左右。
(2) 对数据怎么处理
- 进行标注,划分每张照片属于的类别,对应哪个员工,后续分类
- 抠图,对图像中的人脸画框,因为要检测人脸
- 按照一定的比例划分训练集和测试集,我们取8 : 2
- 使用目标检测模型进行对人脸检测,把目标框的人脸抠出来后续进行分类
- 读取数据,使用数据增强等操作,选取合适的模型进行分类训练
- 使用合适的指标评判模型效果,这里采用准确率,查看准确率,达到99%以上才停止优化。否则继续调整参数、收集更多的人脸数据等。
(3) 如果不是公司的人进来,怎么识别,需要什么数据
收集公司的30个人以外的其他人的人脸图像,每个人1-5张即可,尽可能多收集多个人的人脸图像,多建立一个类别作为第31类进行分类。
(4) 假如没有标签数据,怎么设置损失函数最合适,使得同一个人的人脸图像相差尽可能小,不是同一个人的人脸图像相差尽可能大?
简化问题,把员工A的两张照片a1,a2的特征提取出来,为va1,va2, 员工B的两张照片b1,b2的特征提取出来,为vb1, vb2,写出其损失函数。
我写了一下,大概是这样的:
![]()
d(x, y)表示特征张量x和y的距离,为了使loss满足条件,所以d(va1, va2)和d(vb1, vb2)要尽可能小,其余的值尽可能大,所以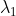 取大一些,比如令
取大一些,比如令![]() ,
, 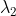 的绝对值取小一些,而且要为负数,因为loss是要减小的,比如令
的绝对值取小一些,而且要为负数,因为loss是要减小的,比如令![]() 。
。
如有更好的解决方案可以评论区交流
AI前沿技术资讯&岗位面经&干货分享
点击卡片关注持续更新中