一文聊“图”,从图数据库到知识图谱

作者 | 穆琼
责编 | 晋兆雨
头图 | 付费下载于视觉中国
随着知识图谱的发展,图数据库一词被越来越多的提到。那么到底什么是图数据库,为什么要用图数据库,如何去建设一个图数据库应用系统,图数据库与知识图谱到底是什么关系。今天为大家揭开神秘面纱,以Neo4j为例,浅析图数据库相关技术。
作者介绍:穆琼 中国农业银行研发中心,致力于AIOps的落地。
 图数据库简介
图数据库简介
谈到图数据库,首先要聊聊“图”,这里的图不是计算机视觉、图像处理领域的图,而是图论中的图,它由节点和节点间的线组成,通常用来描述某些实体与它们之间的特定关系。下图就是一个典型的图示例,某企业网络设备拓扑和报警管理应用方案的示意图。

现实世界中的图无处不在,社交领域人与人的关系挖掘、零售领域商品购买的关联推荐、金融领域的反欺诈反洗钱,都是图技术的典型应用。但是图的存储在过去一直没有特别好的方案。历史的方案可以概括为两类,第一类基于传统关系型数据库,将图中的关系用外键或关联表来表示,这种方式对于某些查询场景需要好几个昂贵的表连接,增加了复杂性。在这种存储中,业务数据与外键元数据混杂起来,增加了开发和维护的成本。第二类采用键值或文档型的NoSQL数据库,键值型如Redis、DynanoDB 等、文档数据库如MongoDB,这些NoSQL都难以表示关联关系,为技术人员带来了开发成本和理解上的壁垒。
因此,专门用于图的存储和查询技术是非常必要的。图技术根据应用方式的不同可以分为两个方向,第一个方向是图数据库,它用于图数据的存储和联机事务查询,具备实时性,面向OLTP,支持CRUD和事务。第二个方向是图计算引擎,它用于图数据的离线查询分析,更适合海量数据的挖掘,面向OLAP。
图领域已经有很多的技术和产品,下图截取自VLDB2019 keynote《Graph Processing: APanaromic View and Some Open Problems》,除了其中所列之外还有很多其他的技术。

图数据库有很多成熟的产品,根据底层存储和处理引擎是否原生,图数据库可以分为四类。为了便于后面理解图数据库处理图的优势,我们解释一下这两个分类维度的含义。
存储方式
原生图存储:数据存储模式为存储和管理图而设计,为图进行过优化。
非原生图存储:将图数据序列化,采用关系型数据库、面向对象数据库、或是其他通用数据存储。
处理方式
原生图处理:使用免索引邻接,关联节点在物理层面指向彼此,这种方式不同于传统关系型数据库的树形全局索引,为查询图的关联节点带来了巨大的性能优势。
非原生图处理:不采用免索引邻接保存关系。
根据这两个维度,图数据库产品可以分为四类:

 Neo4j实践
Neo4j实践
我们以Neo4j为例,直观地感受一下图数据库的强大和便捷之处。Neo4j采用Cypher查询语言(CQL)进行数据的增删改查,下面的Cypher语句创建了三个Person节点和他们之间的关注关系:
CREATE (Billy:Person {name:'Billy',born:1990, sex:'male'})
CREATE (Ruth:Person {name:'Ruth',born:1989, sex:'female'})
CREATE (Harry:Person {name:'Harry',born:1992, sex:'male'})
CREATE (Billy)-[:FOLLOWS]->(Harry)
CREATE (Harry)-[:FOLLOWS]->(Billy)
CREATE (Ruth)-[:FOLLOWS]->(Billy)
CREATE (Ruth)-[:FOLLOWS]->(Harry)
CREATE (Harry)-[:FOLLOWS]->(Ruth)

查询关注了Billy的人:
MATCH (Billy:Person{name:'Billy'})<-[:FOLLOWS]-(followers:Person)RETURN followers

为Billy做个简单的好友推荐,推荐策略是把Billy好友(互关者)关注的人推荐给他:
MATCH(Billy:Person{name:'Billy'})-[:FOLLOWS]->(friend:Person)-[:FOLLOWS]->(Billy:Person{name:'Billy'}),(friend)-[:FOLLOWS]->(newFriend)
WHERE NOT(Billy)-[:FOLLOWS]->(newFriend)
RETURN newFriend
上面的推荐查询得到Ruth。

可以看到,相较SQL的关联查询,Cypher查询的语法具有更强的语义性。
Neo4j也提供了shortestPath方法来获取节点间的最短路径关系,下面这个查询基于Neo4j官方提供的电影和演员数据:

我们的历史数据大多都存储在关系型数据库中,neo4j也很好的支持了关系型数据表CSV文件的导入,CSV文件的导入有两种方式:
1.直接用Cypher LOACCSV:
LOAD CSV WITH HEADERS FROM"file:///categories.csv" AS row
CREATE (n:Category)
SET n = row
2.用neo4j-import工具,更适用于数据量较大的场景,支持并行、可扩展的CSV数据导入。
在查询性能优化方面,Neo4j也做了较好的支持:
Cypher支持对节点的某个属性上创建索引,使得检索数据效率更高,但是跟关系型数据库类似,索引同样会增加存储成本、影响写入效率。
在用Cypher查询时,我们也可以通过EXPLAIN或PROFILE对查询语句进行分析,辅助查询调优。
Neo4j监控工具可以记录和显示服务器的各项指标,Neo4j提供了HTTP web界面实时查看监控数据,包括存储容量、ID分配、页面缓存和事务数据。
 Neo4j系统建设
Neo4j系统建设
Neo4j开发
Neo4j分别提供Java接口和REST API,对应的,使用Neo4j也有两种开发模式:Java API嵌入式开发和HTTP API调用开发。

Neo4j天然支持Java,Spring也提供了Spring Data Neo4j,便于我们在Spring应用系统中使用Neo4j。Spring Data Neo4j除了提供Spring Data模块的实体映射、分页、事务等功能以外,还针对Neo4j提供了以下附加功能:
支持Neo4j属性图模块;
支持Neo4j Lucence索引;
支持Neo4j Cypher查询(CQL);
Neo4jTemplate
Spring Data Neo4j体系结构如下图:
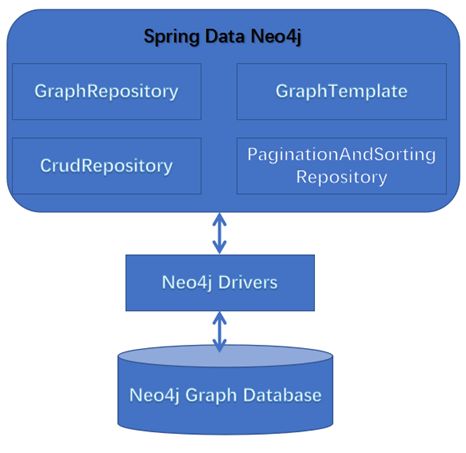
Spring Data Neo4j提供了不同的API来支持不同的场景,下表给出了对应的Java类和其用法:
Spring Data Neo4j类 |
用法 |
GraphRepository |
用于执行basic Neo4j DB操作 |
GraphTemplate |
类似其他Spring Data模块的Template,是执行Neo4j DB操作的Spring模板 |
CrudRepository |
用于使用Cypher查询语言(CQL)执行Neo4j CRUD操作 |
PaginationAndSortingRepository |
用于执行Neo4j CQL查询结果的分页和排序 |
 Neo4j集群搭建
Neo4j集群搭建
考虑到系统实施时大规模生产环境和容错问题,Neo4j企业版提供高可用集群和因果集群两种集群功能,实现高可用性和水平读扩展,有效提高系统整体性能、可靠性、灵活性和可扩展性。
在使用图数据库集群时,我们需要考虑集群的负载均衡,提升吞吐量并减少延迟时间。Neo4j自身没有负载均衡功能,需要依赖网络基础设施的负载均衡能力。以下是三种我们常用的负载均衡方式:
1.分离读写流量,将绝大部分写入操作直接在集群主节点上进行,将读请求和写请求完全分离开,通过负载均衡器将写流量定向到主节点,读流量平衡地分散到整个集群,避免写操作影响查询效率。
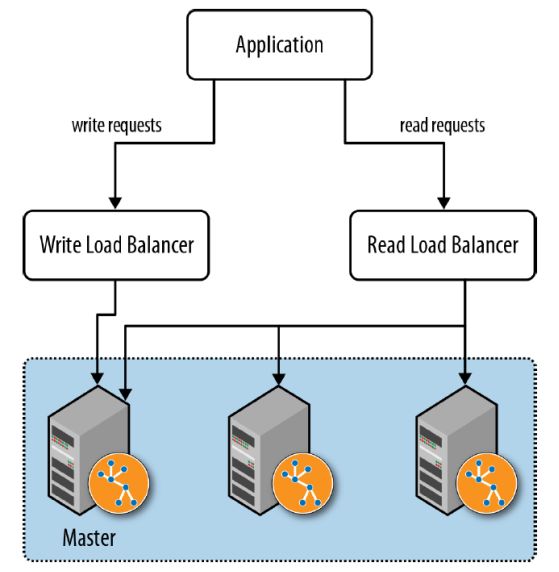
2.高速缓存分片,这种方式利用了主存储器中的数据查询执行最快,如下图所示,高可用集群中的节点实例将图的部分数据放在自己的主存储器,负载均衡器将请求路由到对应的节点实例上,提升查询效率。

3.集群实例节点读取自己的写入,减少查询开销。
 知识图谱与图数据库
知识图谱与图数据库
图数据库虽然强大且易用,但是它并不是完美的适用于所有场景。图数据库可以存储海量数据,但并不适合直接用来进行海量数据的分析计算,而更适合用来进行某个实体及其关联关系的查询。因此,仅靠图数据库显然无法解决图计算领域的所有问题,在知识图谱的构建和应用方面还有很多需要利用其他图计算技术来解决的问题。
下图是一个典型的图计算技术架构,包括图数据建模、存储系统和图数据计算三个部分。

图数据建模:对于关系型数据库的数据,关系和实体已知,建模成图数据相对简单。但是对于文本这样的非结构化数据,将其建模成为图数据需要应用自然语言处理、机器学习技术,来解决知识抽取、知识融合和知识推理等问题。斯坦福大学Infolab实验室开源的DeepDive提供了知识抽取的框架,是构建知识图谱的利器。
存储系统:图数据有多种存储方式,图数据库当然是最适应图的关系存储的,但在不同的应用场景下,也可以考虑将图数据以RDF三元组、关系型数据库、ES或其他NoSQL方式进行存储。
图数据应用:在构建好的图数据基础之上,通过图计算引擎对海量图数据进行离线的计算分析,针对不同的应用场景,也可以在内存处理或工作存储中对图数据进行查询分析。
图数据库非常适用于图数据的存储和实时查询,是知识图谱的基石,但它并非知识图谱的全部。在应用时,我们需要针对具体的场景去进行选型,结合不同的图计算技术进行分析计算。
目前图数据库产品很多,国内各大互联网公司如阿里、腾讯等也自研了自己的图数据库,图数据库未来能否像关系型数据库一样有统一的查询语法,目前还是一个未知数。但可预见的是,随着数据的爆炸式增长,在追求数据驱动运营和决策的潮流下,图数据库在社交关系、实时推荐、主数据管理、在线反欺诈、IT网络管理、地理信息系统等领域都将占据重要的一席之地。

更多阅读推荐
云原生应用Go语言:你还在考虑的时候,别人已经应用实践
一文告诉你雾计算与云计算的区别及对物联网的价值!
你可能也会掉进这个简单的 String 的坑
教你如何用 Python 三行代码做动图!
Ethereum2.0:深入了解Lego Money、Sharding、PoS和TPS的真相