机器学习-概率图模型:条件随机场(CRF)【前提假设:隐层状态序列符合马尔可夫性、枚举整个隐状态序列全部可能】【MEMM--枚举整个隐状态序列全部可能-->CRF】【判别模型:条件概率】
一、概述
CRF(全称Conditional Random Fields), 条件随机场. 是给定输入序列的条件下, 求解输出序列的条件概率分布模型,在自然语言处理中得到了广泛应用。
CRF的优点:克服了HMM的输出独立性假设问题以及MEMM的标注偏置问题。
可以将 HMM 模型看作 CRF 模型的一种特殊情况,即所有能用 HMM 解决的问题,基本上也都能用 CRF 解决,并且 CRF 还能利用更多 HMM 没有的特征。
CRF 可以用前一时刻和当前时刻的标签构成的特征函数,加上对应的权重来表示 HMM 中的转移概率,可以用当前时刻的标签和当前时刻对应的词构成的特征函数,加上权重来表示 HMM 中的发射概率。
所以 HMM 能做到的,CRF 都能做到。
1、什么样的问题需要CRF模型
首先我们来看看什么样的问题解决可以用CRF模型。使用CRF模型时我们的问题一般有这两个特征:
- 我们的问题是基于序列的,比如时间序列,或者状态序列。
- 我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。
和HMM类似,在讨论CRF之前,我们来看看什么样的问题需要CRF模型。这里举一个简单的例子:
- 场景一:
- 假设我们有Bob一天从早到晚的一系列照片,Bob想考考我们,要我们猜这一系列的每张照片对应的活动,比如: 工作的照片,吃饭的照片,唱歌的照片等等。一个比较直观的办法就是,我们找到Bob之前的日常生活的一系列照片,然后找Bob问清楚这些照片代表的活动标记,这样我们就可以用监督学习的方法来训练一个分类模型,比如逻辑回归,接着用模型去预测这一天的每张照片最可能的活动标记。
- 这种办法虽然是可行的,但是却忽略了一个重要的问题,就是这些照片之间的顺序其实是有很大的时间顺序关系的,而用上面的方法则会忽略这种关系。比如我们现在看到了一张Bob闭着嘴的照片,那么这张照片我们怎么标记Bob的活动呢?比较难去打标记。但是如果我们有Bob在这一张照片前一点点时间的照片的话,那么这张照片就好标记了。如果在时间序列上前一张的照片里Bob在吃饭,那么这张闭嘴的照片很有可能是在吃饭咀嚼。而如果在时间序列上前一张的照片里Bob在唱歌,那么这张闭嘴的照片很有可能是在唱歌。
- 场景二:
- 假设有分好词的句子, 我们要判断每个词的词性, 那么对于一些词来说, 如果我们不知道相邻词的词性的情况下, 是很难准确判断每个词的词性的. 这时, 我们也可以用到CRF.
为了让我们的分类器表现的更好,可以在标记数据的时候,可以考虑相邻数据的标记信息。这一点,是普通的分类器难以做到的。而这一块,也是CRF比较擅长的地方。
在实际应用中,自然语言处理中的词性标注(POS Tagging)就是非常适合CRF使用的地方。词性标注的目标是给出一个句子中每个词的词性(名词,动词,形容词等)。而这些词的词性往往和上下文的词的词性有关,因此,使用CRF来处理是很适合的,当然CRF不是唯一的选择,也有很多其他的词性标注方法。
2、CRF模型的前提
马尔科夫假设:当前隐层状态仅与上一个状态有关;
无观测独立性假设: 任意时刻的观察状态不仅仅依赖于当前时刻的隐藏状态,也依赖于前面时刻的隐藏状态;由于限制更少,CRF利用了更多的信息,如观测序列上下文信息,以及观测序列元素本身的特征(是否是数字,是否大写,是否以某字符串开头或结尾)
枚举整个隐状态序列全部可能:枚举了整个隐状态序列 x 1 … x n x_1…x_n x1…xn的全部可能,从而解决了局部归一化带来的标注偏置问题。
3、CRF三个典型问题
-
概率计算问题【评估观察序列概率: 前向-后向算法(动态规划)】
-
解码问题 / 预测问题【维特比(Viterbi)算法-动态规划】
-
模型参数学习问题:梯度下降法算法
4、HMM、MEMM、CRF对比
HMM(Hidden Markov Moel)模型:是一个有向图模型,为简化求解多随机变量的联合概率分布,做了两个假设:
- 齐次马尔科夫假设
- 观测独立假设。
这两个假设都具有局限性。
MEMM(Maximum Entropy Markov Model)模型舍弃了HMM的观测独立假设,使用了所有上下文的观测值。因此具有更强的表达能力。同时使用最大熵模型对条件概率建模。每个条件概率在局部进行了归一化,这又带来了“label bias”问题。
CRF(Conditional Random Fields)模型去除了HMM的另一个假设“齐次马尔科夫假设”,使用全局归一化计算联合概率,避免了局部归一化带来的“label bias”的问题。

| 建模对象 | 图类型 | 学习算法 | 预测算法 | 存在问题 | |
|---|---|---|---|---|---|
| HMM | 联合概率,生成式模型 | 有向图 | 1.极大似然估计 2.Baum-Welch(前向-后向) |
viterbi | 强假设导致的局限性 |
| MEMM | 条件概率,判别式模型 | 有向图 | 1.极大似然估计 2.梯度下降3.牛顿迭代 |
viterbi | label bias |
| CRF | 条件概率,判别式模型 | 无向图 | 1.极大似然估计 2.梯度下降 |
viterbi | 考虑的信息多,模型复杂。 全局归一化的归一化因子可能性过多(指数级别),计算困难 |
4.1 相同点
- 隐层状态序列都服从马尔科夫性;
- 都有3个典型问题;
4.2 不同点
- HMM服从观测独立性假设,CRF不服从观测独立性假设;
- HMM每一时刻是对隐状态序列、观测序列的联合概率进行建模的生成式模型,CRF每一时刻是给定所有观测序列X和上一时刻隐状态下的条件概率分布判别模型;
- HMM求解过程可能是局部最优,CRF可以全局最优;
- CRF概率归一化较合理,HMM则会导致label bias 问题
- HMM是概率有向图,CRF是概率无向图
二、“随机场”–>“马尔科夫随机场”–>“条件随机场”–>“线性链条件随机场”
1、随机场
随机过程: 我们将随机变量的集合称为随机过程.
随机场:由一个空间变量索引的随机过程, 我们将其称为随机场.
“随机场”的名字取的很玄乎,其实理解起来不难。
随机场:是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。
还是举词性标注的例子:假如我们有一个十个词形成的句子需要做词性标注。这十个词每个词的词性可以在我们已知的词性集合(名词,动词…)中去选择。当我们为每个词选择完词性后,这就形成了一个随机场。
上面的例子中, 做词性标注时:
- 可以将{名词、动词、形容词、副词}这些词性定义为随机变量,
- 然后从中选择相应的词性, 而这组随机变量在某种程度上遵循某种概率分布, 将这些词性按照对应的概率赋值给相应的词, 就完成了句子的词性标注.
2、马尔科夫随机场
了解了随机场,我们再来看看马尔科夫随机场。
马尔科夫随机场是随机场的特例,
马尔科夫随机场:它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。
继续举十个词的句子词性标注的例子:
- 如果我们假设所有词的词性只和它相邻的词的词性有关时,这个随机场就特化成一个马尔科夫随机场。
- 比如第三个词的词性除了与自己本身的位置有关外,只与第二个词和第四个词的词性有关。
3、条件随机场
理解了马尔科夫随机场,再理解CRF就容易了。
CRF是马尔科夫随机场的特例,
条件随机场(CRF):假设马尔科夫随机场中只有 X X X 和 Y Y Y 两种变量, X X X 一般是给定的,而 Y Y Y 一般是在给定X的条件下我们的输出。这样马尔科夫随机场就特化成了条件随机场。
在我们十个词的句子词性标注的例子中, X X X 是词, Y Y Y 是词性。因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个CRF。
对于CRF,我们给出准确的数学语言描述:
设 X X X 与 Y Y Y 是随机变量, P ( Y ∣ X ) P(Y|X) P(Y∣X) 是给定 X X X 时 Y Y Y 的条件概率分布,若随机变量 Y Y Y 构成的是一个马尔科夫随机场,则称条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 是条件随机场。
4、线性链条件随机场
注意在CRF的定义中,我们并没有要求 X X X 和 Y Y Y 有相同的结构。而实现中,我们一般都假设 X X X 和 Y Y Y 有相同的结构,即:
X = ( X 1 , X 2 , . . . X n ) , Y = ( Y 1 , Y 2 , . . . Y n ) X =(X_1,X_2,...X_n),\;\;Y=(Y_1,Y_2,...Y_n) X=(X1,X2,...Xn),Y=(Y1,Y2,...Yn)
我们一般考虑如下图所示的结构: X X X 和 Y Y Y 有相同的结构的CRF就构成了线性链条件随机场(Linear chain Conditional Random Fields,以下简称 linear-CRF)。
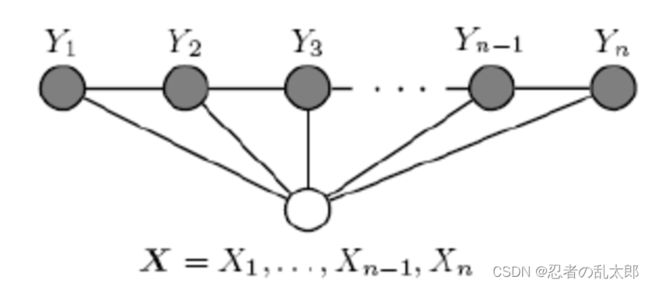
在我们的十个词的句子的词性标记中,词有十个,词性也是十个,因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个linear-CRF。
我们再来看看 linear-CRF的数学定义:
设 X = ( X 1 , X 2 , . . . X n ) , Y = ( Y 1 , Y 2 , . . . Y n ) X =(X_1,X_2,...X_n),\;\;Y=(Y_1,Y_2,...Y_n) X=(X1,X2,...Xn),Y=(Y1,Y2,...Yn) 均为线性链表示的随机变量序列,在给定随机变量序列 X X X 的情况下,随机变量 Y Y Y 的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 构成条件随机场,即满足马尔科夫性:
P ( Y i ∣ X , Y 1 , Y 2 , . . . Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) P(Y_i|X,Y_1,Y_2,...Y_n) = P(Y_i|X,Y_{i-1},Y_{i+1}) P(Yi∣X,Y1,Y2,...Yn)=P(Yi∣X,Yi−1,Yi+1)
则称 P ( Y ∣ X ) P(Y|X) P(Y∣X) 为线性链条件随机场。
三、HMM(隐马尔可夫模型)–>MEMM(最大熵马尔可夫模型)->CRF(条件随机场)
在隐马尔可夫模型中,假设隐状态(即序列标注问题中的标注) x i x_i xi 的状态满足马尔可夫过程。但是实际上,在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还和观察序列的长度、上下文等信息相关。
例如词性标注问题中,一个词被标注为动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的其他词,于是引出了最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)。
最大熵马尔可夫模型在建模时,去除了隐马尔可夫模型中观测状态相互独立的假设,考虑了整个观测序列,因此获得了更强的表达能力。
- 隐马尔可夫模型是一种对隐状态序列和观测状态序列的联合概率P(x,y)进行建模的生成式模型;
- 最大熵马尔可夫模型是直接对标注的后验概率P(y|x)进行建模的判别式模型;
最大熵马尔可夫模型存在标注偏置问题:由于局部归一化的影响,隐状态会倾向于转移到那些后续状态可能更少的状态上,以提高整体的后验概率。这就是标注偏置问题。
条件随机场在最大熵马尔可夫模型的基础上,进行了全局归一化,枚举了整个隐状态序列 x 1 … x n x_1…x_n x1…xn的全部可能,从而解决了局部归一化带来的标注偏置问题。【给定了观察值(observations)集合的马尔科夫随机场(MRF)】
四、马尔科夫模型(HMM) v.s. 条件随机场(CRF)
马尔科夫模型(HMM):当前位置的取值只和与它相邻的位置的值有关, 和它不相邻的位置的值无关。应用到我们上面的词性标注例子中, 可以理解为当前词的词性是根据前一个词和后一个词的词性来决定的, 等效于从词性前后文的概率来给出当前词的词性判断结果.
条件随机场(CRF):现实中可以做如下假设,假设一个动词或者副词后面不会连接同样的动词或者副词, 这样的概率很高. 那么, 可以假定这种给定隐藏状态(也就是词性序列)的情况下, 来计算观测状态的计算过程。 本质上CRF模型考虑到了观测状态这个先验条件, 这也是条件随机场中的条件一词的含义。而隐马尔可夫模型(HMM)不考虑先验条件。
五、CRF三个典型问题
在隐马尔科夫模型HMM中,我们讲到了HMM的三个基本问题,而linear-CRF也有三个类似的的基本问题。
不过和HMM不同,在linear-CRF中,我们对于给出的观测序列 X X X 是一直作为一个整体看待的,也就是不会拆开看 ( x 1 , x 2 , . . . ) (x_1,x_2,...) (x1,x2,...),因此linear-CRF的问题模型要比HMM简单一些。
- linear-CRF第一个问题是概率评估,即给定 linear-CRF的条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x) , 在给定输入序列 x x x 和输出序列 y y y 时,计算条件概率 P ( y i ∣ x ) P(y_i|x) P(yi∣x) 和 P ( y i − 1 , y i ∣ x ) P(y_{i-1},y_i|x) P(yi−1,yi∣x) 以及对应的期望.
- linear-CRF第二个问题是解码,即给定 linear-CRF的条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x),和输入序列 x x x, 计算使条件概率最大的输出序列 y y y。类似于HMM,使用维特比算法可以很方便的解决这个问题。
- linear-CRF第三个问题是参数学习,即给定训练数据集 X X X 和 Y Y Y,学习linear-CRF的模型参数 w k w_k wk 和条件概率 P w ( y ∣ x ) P_w(y|x) Pw(y∣x),这个问题的求解比HMM的学习算法简单的多,普通的梯度下降法,拟牛顿法都可以解决。
1、概率计算问题【评估观察序列概率: 前向-后向算法(动态规划)】
2、解码问题 / 预测问题【维特比(Viterbi)算法-动态规划】
3、模型参数学习问题:梯度下降法算法
六、“词性标注”案例
1、转移概率矩阵
首先假设我们需要标注的实体类型有以下几类:
{"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4}
其中dis表示疾病(disease), sym表示症状(symptom), B表示命名实体开头, I表示命名实体中间到结尾, O表示其他类型.
因此我们很容易知道每个字的可能标注类型有以上五种可能性, 那么在一个句子中, 由上一个字到下一个字的概率乘积就有5 × 5种可能性, 具体见下图所示【其中的概率数值是通过模型在所给语料的基础上训练得到每个词的tag,然后统计出的结果】:
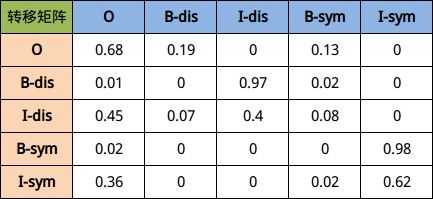
最终训练出来结果大致会如上图所示, 其中下标索引为(i, j)的方格代表如果当前字符是第i行表示的标签, 那么下一个字符表示第j列表示的标签所对应的概率值. 以第二行为例, 假设当前第i个字的标签为B-dis, 那么第i+1个字最大可能出现的概率应该是I-dis.
转移概率矩阵是行数、列数都为tag-size的方阵。
2、发射概率矩阵
发射概率, 是指已知当前标签的情况下, 对应所出现各个不同字符的概率. 通俗理解就是当前标签比较可能出现的文字有哪些, 及其对应出现的概率.
下面是几段医疗文本数据的标注结果:
![]()

![]()
![]()
可以得到以上句子的转移矩阵概率如下(比如:其中 28 表示标记为 “O” 的汉字转移到所有标签汉字的总转移次数):

对应的发射矩阵可以理解为如下图所示结果(其中:29表示标记为O的所有汉字、符号的总数量):
![]()

参考资料:
参考资料:
概率图模型:HMM,MEMM,CRF
谈谈序列标注三大模型HMM、MEMM、CRF
自然语言处理基础:HMM与CRF模型比较
概率图模型:HMM,MEMM,CRF
条件随机场CRF(一)从随机场到线性链条件随机场
条件随机场CRF(二) 前向后向算法评估标记序列概率
条件随机场CRF(三) 模型学习与维特比算法解码
如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?
概率图模型:HMM和CRF
HMM VS CRF and 生成模型VS判别模型
NLP硬核入门-条件随机场CRF
CRF条件随机场~
HMM和CRF区别
CRF 和 HMM 的区别与联系
HMM,MEMM,CRF总结和比较