Python数据分析三剑客之Pandas
写在前面的话: 开始之前请确保已经配置好python环境,并安装好第三方库pandas和numpy。
1. pandas库介绍
什么是pandas?pandas是提供高性能易用数据类型和数据分析工具的第三方库。简单讲,pandas主要作用有两个:提供了简易高效的数据类型、提供了数据分析的工具。pandas基于numpy,常和numpy、matplotlib一起使用。 关于数据类型,python中自带的数据类型远远不能满足于数据分析。可以说在数据分析中numpy中的数据类型是基础数据类型,关注的是数据的结构表达,体现在数据间的关系(维度);pandas中的数据类型是基于numpy的扩展数据类型,关注的是数据的应用表达,体现在数据与索引之间的关系上。我们再学习pandas时最重要的是理解如何去操作索引,从某种程度上来说,操作索引就是操作数据。
2. pandas库的series类型
pandas主要有两种数据类型,一维度的Series数据类型,二维及高维的DataFrame类型。我们先来看一下第一种,series类型。
2.1 什么是series类型?
series类型由一组数据及与之相关的数据索引组成。我们来看几行代码:
import pandas as pd
a = pd.Series([7,8,9,10])
print(a)
复制代码输出如下:
0 7
1 8
2 9
3 10
dtype: int64
复制代码观察输出代码,我们可以发现Series对象一共由3部分组成:左侧自动索引部分,右侧数据部分,底部数据类型(numpy中的数据类型)部分。
除了自动添加索引外,我们还可以对其索引进行自定义:
import pandas as pd
a =pd.Series([7,8,9,10],index=["a","b","c","d"]) # index指定索引
print(a)
复制代码输出如下:
a 7
b 8
c 9
d 10
dtype: int64
复制代码可见,索引部分变为了我们自定义的abcd。
2.2 如何创建series类型?
创建Series类型的方法有很多种,主要以 以下几种为主:
- 从标量创建
- 从字典创建
- 从ndarray类型创建
- 从列表创建
下面进行具体讲解:
(1)从标量值创建
即指定一个标量生成一个series类型,如下:
import pandas as pd
a = pd.Series(5,index=["a","b","c","d","e","f"])
print(a)
复制代码输出如下:
a 5
b 5
c 5
d 5
e 5
f 5
dtype: int64
复制代码需要注意的是,此时的index参数不能省略(因为需要index来指定生成元素的个数和索引)。 (2)从字典类型创建 传入一个参数字典,字典的键为series类型的索引,字典的值为series类型的值:
import pandas as pd
my_dir={
"a":1,
"b":2,
"c":3
}
b = pd.Series(my_dir)
print(b)
复制代码输出如下:
a 1
b 2
c 3
dtype: int64
复制代码此外,利用字典构造series类型时,我们同样可以使用index来指定其索引或改变其结构,这个索引会覆盖字典中的“键索引”。
(3)从ndarray类型创建 ndarray类型是numpy中的数据类型,我们可以直接传入ndarray类型进行创建:
import pandas as pd
import numpy as np
c = np.arange(4)
d = pd.Series(c)
print(d)
复制代码输出如下:
0 0
1 1
2 2
3 3
dtype: int32
复制代码同样,也可以使用index参数自定义索引。
(4)也可以从python列表创建,见2.1中的小例。
2.3 series类型的基本使用
Series对象包括index和values两部分,所以主要是这两部分操作。我们先看一下下面的案例:
- a.index:获取索引
- a.values: 获取数据
- a['a']: 获取索引为a的元素
- a[0]:获取索引为0的元素,注意!自动索引和自定义索引并存但不能混合使用
因为series是基于ndarray类型的,所以对Series的操作类似于ndarray类型的操作:
- numpy中运算和操作可用于series类型
- 可以通过自动索引或自定义索引对其进行切片
import pandas as pd
a = pd.Series([1,2,3,4,5,6],index=["a","b","c","d","e","f"])
print("a的值:",a.values)
print("a的索引:",a.index)
print("a[0]:",a[0])
print("a['a']:",a["a"])
print("a切片:\n",a[::-1])
复制代码输出如下:
a的值: [1 2 3 4 5 6]
a的索引: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
a[0]: 1
a['a']: 1
a切片:
f 6
e 5
d 4
c 3
b 2
a 1
dtype: int64
复制代码此外,series类型具备对齐操作。如下:
import pandas as pd
a = pd.Series([1,2,3],index=["c","d","e"])
b = pd.Series([4,5,6,7,8],index=["a","b","e","f","g"])
c = a+b
print(c)
复制代码输出如下:
a NaN
b NaN
c NaN
d NaN
e 9.0
f NaN
g NaN
dtype: float64
复制代码我们让两个series类型相加。观察输出结果可以发现,只有当a、b两者中有相同索引(包括位置)时,他们才会相加,而其余值则不会相加。这就对是series的对齐操作。这也同时验证了pandas是基于索引的运算。
Series类型还有一个name属性,即series对象和索引都可以被赋予一个名称。我们可以使用.name来获取或定义其名称。
import pandas as pd
a = pd.Series([1,2,3],index=["c","d","e"])
print(a.name) # 初始是没有名称的
a.name = "mySeries"
print(a.name)
print(a.index.name)
a.index.name = "索引列"
print(a.index.name)
print("*"*20)
print(a)
复制代码输出如下:
None
mySeries
None
索引列
********************
索引列
c 1
d 2
e 3
Name: mySeries, dtype: int64
复制代码3. pandas库的DataFrame类型
介绍完Series类型,再然我们来看一下二维及多维的DataFrame类型。
3.1 什么是DataFrame类型?
DataFrame类型是由共用相同索引的一组列数据组成的数据类型。即DataFrame类型是一个类似于表格型的数据类型,每列值类型可以不同,同一行的多列数据都共用同一个索引。我们先看一个小例子:
import pandas as pd
import numpy as np
a = np.arange(10).reshape(2,5)
b = pd.DataFrame(a)
print(b)
复制代码通过numpy生成一个二维的ndarray数组,并将其作为参数传给DataFrame,从而生成DataFrame类型的数据。输出如下:

从输出结果中,可以发现,输出结果一共由三部分组成:左侧(纵向)行索引index(红色区,为轴axis=0) 、顶部(横向)列索引column(黄色区,为轴axis=1) 以及数据部分(蓝色区)。 DataFrame常用于表达二维数据,但也可以表达多维数据。
3.2 如何创建DataFrame类型?
dataFrame可以由以下4种方法创建:
- 二维ndarray对象
- 字典
- Series类型
- 其它DataFrame类型
接下来,我们进行详细介绍:
(1)由二维ndarray对象创建
import pandas as pd
import numpy as np
a = np.arange(16).reshape(4,4)
print('ndarray类型:\n',a)
b = pd.DataFrame(a)
print('转换后的DataFrame类型:\n',b)
复制代码通过numpy生成一个4*4的ndarray类型,然后作为参数转换成DataFrame类型,输出如下:
ndarray类型:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
转换后的DataFrame类型:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
复制代码(2)由多个一维Series组成的字典生成 我们首先创建一个字典,并将其作为采参数传给DataFrame:
import pandas as pd
import numpy as np
a = {
"小明":pd.Series([100,99,98,100,95,99],index=["语文","数学","英语","物理","化学","生物"]),
"小红":pd.Series([100,99,98,100,95,99],index=["语文","数学","英语","物理","化学","生物"]),
"小蓝":pd.Series([100,99,98,100,95,99],index=["语文","数学","英语","物理","化学","生物"]),
"小黄":pd.Series([100,99,98,100,95,99],index=["语文","数学","英语","物理","化学","生物"]),
"小绿":pd.Series([100,99,98,100,95,99],index=["语文","数学","英语","物理","化学","生物"])}
b = pd.DataFrame(a)
print(b)
复制代码输出如下:
小明 小红 小蓝 小黄 小绿
语文 100 100 100 100 100
数学 99 99 99 99 99
英语 98 98 98 98 98
物理 100 100 100 100 100
化学 95 95 95 95 95
生物 99 99 99 99 99
复制代码可以看到,键名变成了列标签,键值索引变成了行标签。
3.3 DataFrame与Series的关系
可以发现当我们从DataFrame中取出一行或一列时,所得结果是Series类型。也就是说DataFrame是Series类型的容器。
4. pandas库的数据操作
在上文中,我们提到pandas的两种数据类型是series类型和DataFrame类型。接下来,我们主要针对这两种数据类型的操作进行讲解。
4.1 Dataframe的基本属性
-
df.shape:行数和列数
-
df.dtype:列数据类型
-
df.ndim:数据维度
-
df.index:行索引
-
df.columns:列索引
-
df.values:值
import pandas as pd import numpy as np df = pd.DataFrame(np.arange(16).reshape(4,4),index=list("abcd"),columns=list("ABCD")) print(df) print("行数和列数:",df.shape) print("列数据类型:\n",df.dtypes) print("数据维度:",df.ndim) print("行索引:",df.index,"数据类型:",type(df.index)) print("列索引:",df.columns,"数据类型:",type(df.columns)) print("对象值:\n",df.values,"数据类型:",type(df.values)) 复制代码
输出如下:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
行数和列数: (4, 4)
列数据类型:
A int32
B int32
C int32
D int32
dtype: object
数据维度: 2
行索引: Index(['a', 'b', 'c', 'd'], dtype='object') 数据类型:
列索引: Index(['A', 'B', 'C', 'D'], dtype='object') 数据类型:
对象值:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] 数据类型:
复制代码 4.2 dataFrame整体情况查询
-
df.head(n): 显示前n行,默认前五行
-
df.tail(n):显示末尾n行,默认后五行
-
df.info():基本信息:行列数,列索引,列非空值个数,列类型行类型,内存占用等
-
df.describe(): 统计信息:行数,列数,均值,标准差,最大值,最小值,四分位数等
-
df.sort_values(by="列标签",ascending=True):升序排序
import pandas as pd import numpy as np df = pd.DataFrame(np.arange(16).reshape(4,4),index=list("abcd"),columns=list("ABCD")) print(df) print("前3行:\n",df.head(3)) print("-"*50) print("后3行:\n",df.tail(3)) print("-"*50) print("基本信息:") print(df.info()) print("-"*50) print("统计信息:",df.describe()) print("降序排序:") print(df.sort_values(by="B", ascending=False)) 复制代码
输出如下:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
前3行:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
--------------------------------------------------
后3行:
A B C D
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
--------------------------------------------------
基本信息:
# 数据类型
Index: 4 entries, a to d # 行数 4行
Data columns (total 4 columns): # 列数 4列
# Column Non-Null Count Dtype
--- ------ -------------- ----- # 列标签 列非空值个数 列数据类型
0 A 4 non-null int32
1 B 4 non-null int32
2 C 4 non-null int32
3 D 4 non-null int32
dtypes: int32(4)
memory usage: 96.0+ bytes # 内存占用大小
None
--------------------------------------------------
统计信息: # 以下结果也为DataFrame类型
A B C D
count 4.000000 4.000000 4.000000 4.000000 #包含的行数
mean 6.000000 7.000000 8.000000 9.000000 # 均值
std 5.163978 5.163978 5.163978 5.163978 # 标准差
min 0.000000 1.000000 2.000000 3.000000 # 最小值
25% 3.000000 4.000000 5.000000 6.000000 # 前25%中位数
50% 6.000000 7.000000 8.000000 9.000000 # 中位数
75% 9.000000 10.000000 11.000000 12.000000 # 前75%中位数
max 12.000000 13.000000 14.000000 15.000000 # 最大值
降序排序:
A B C D
d 12 13 14 15
c 8 9 10 11
b 4 5 6 7
a 0 1 2 3
复制代码 4.3 取值操作
取值操作是pandas中的一个基本操作,我们先生成一个100行3列的数据,用于下面操作:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(16).reshape(4,4),index=list("abcd"),columns=list("ABCD"))
print(df)
复制代码输出如下:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
复制代码pandas中有较多的取值方法,但是最常用最好用的方法是以下两种,这里也将详细介绍这两种方法:
-
df.loc[]: 通过标签索引获取行数据
-
df.iloc[]: 通过位置获取行数据
(1)先来看一下 df.loc[]:
print("取a行A列的数据:",df.loc["a","A"],"数据类型:",type(df.loc["a","A"])) print("取A B列的数据:\n",df.loc[:,["A","B"]],"数据类型:",type(df.loc[:,["A","B"]])) 复制代码
输出如下:
取a行A列的数据: 0 数据类型:
取A B列的数据:
A B
a 0 1
b 4 5
c 8 9
d 12 13 数据类型:
复制代码 loc[]可以通过自定义的索引进行查找也可以通过位置索引进行查找。值得注意的是,这里我们用到了 [ : ],这里是前闭后闭的,即会选择冒号后面的数据。
(2)接着 来看一下df.iloc[]:
print("取前两行前两列:\n",df.iloc[:2,:2])
复制代码输出:
取前两行前两列:
A B
a 0 1
b 4 5
复制代码(3)布尔索引
我们通过通常范围筛选数值,或通过判断进行筛选数值
print("选取df中数值大于7小于13的行:\n",(df.loc[(df["B"]>7)&(df["B"]<13)]))
复制代码输出:
选取df中数值大于7小于13的行:
A B C D
c 8 9 10 11
复制代码这里选取多个条件时,需要用()括起来。
4.4 改变数据类型
这里所谓的改变数据类型的结构就是对数据类型进行索引重排或增删 。主要操作如下:
(1) .reindex(index/columns):重排数据,通过改变数据的索引来对数据进行重新排序。 我们依旧拿上述的成绩单作为例子来进行讲解:
import pandas as pd
import numpy as np
a = {
"小明":pd.Series([100,99,91,90,85,69],index=["语文","数学","英语","物理","化学","生物"]),
"小红":pd.Series([100,93,92,100,65,93],index=["语文","数学","英语","物理","化学","生物"]),
"小蓝":pd.Series([100,94,93,70,55,92],index=["语文","数学","英语","物理","化学","生物"]),
"小黄":pd.Series([100,95,88,80,85,89],index=["语文","数学","英语","物理","化学","生物"]),
"小绿":pd.Series([100,92,78,89,75,79],index=["语文","数学","英语","物理","化学","生物"])}
b = pd.DataFrame(a)
print(b)
c = b.reindex(columns=["小红","小明","小蓝","小黄","小绿"])
print("对换小明和小红:\n",c)
d = b.reindex(index=["数学","语文","英语","物理","化学","生物"])
print(d)
复制代码输入如下:
小明 小红 小蓝 小黄 小绿
语文 100 100 100 100 100
数学 99 93 94 95 92
英语 91 92 93 88 78
物理 90 100 70 80 89
化学 85 65 55 85 75
生物 69 93 92 89 79
对换小明和小红:
小红 小明 小蓝 小黄 小绿
语文 100 100 100 100 100
数学 93 99 94 95 92
英语 92 91 93 88 78
物理 100 90 70 80 89
化学 65 85 55 85 75
生物 93 69 92 89 79
对换数学和语文:
小明 小红 小蓝 小黄 小绿
数学 99 93 94 95 92
语文 100 100 100 100 100
英语 91 92 93 88 78
物理 90 100 70 80 89
化学 85 65 55 85 75
生物 69 93 92 89 79
复制代码可见,通过columns调换了列数据,通过index调换了行数据。 下面补充一下.index()方法的其余参数:
- index,columns:新的行列自定义索引
- fill_value:重新索引中,用于填充缺失位置(NaN)的值
- limit: 最大填充量
- method:填充方法 ffill向前填充,bfill向后填充
- copy:默认True,生成新的对象
(2)另外,对于缺失值还有另一种处理方法:
-
pd.isnull(df): 是否为空值,空值标为True
-
pd.isnotnull(df):是否为非空值,非空值标为True
-
df.dropna(axis=0/1,how="all/any",inplace=True/False): 删除nan所在的行/列
-
df.fiullan(n):将空值填充为n
import pandas as pd import numpy as np df = pd.DataFrame(np.arange(16).reshape(4,4),columns=list("ABCD")) df.loc[3,"C"] = None df.loc[2,"C"] = None print(df) print(df.isnull()) print(df.notnull()) print(df.dropna(axis=0,inplace=False)) print(df.fillna(df.mean())) 复制代码
输出为:
A B C D
0 0 1 2.0 3
1 4 5 6.0 7
2 8 9 NaN 11
3 12 13 NaN 15
A B C D
0 False False False False
1 False False False False
2 False False True False
3 False False True False
A B C D
0 True True True True
1 True True True True
2 True True False True
3 True True False True
A B C D
0 0 1 2.0 3
1 4 5 6.0 7
A B C D
0 0 1 2.0 3
1 4 5 6.0 7
2 8 9 4.0 11
3 12 13 4.0 15
复制代码4.5 索引操作
对于索引,也有下常用的方法:
- .append()连接另一个index对象,产生新的index对象
- .diff(idx):计算差集,产生新的index对象
- intersection(idx):计算交集
- union(idx):吉计算并集
- delete(loc): 删除loc位置处的元素
- insert(loc,c):在loc位置增加一个元素c
4.6 删除指定索引对象
.drop()可以删除series和DataFrame指定的行或列索引。
import pandas as pd
a = pd.Series([4,5,6,7],index=["a","b","c","d"])
print(a)
b = a.drop(["b","d"])
print(b)
复制代码输出如下:
a 4
b 5
c 6
d 7
dtype: int64
a 4
c 6
dtype: int64
复制代码对于DataFrame对象,.drop()默认操作0轴上的对象,当我们要操作1轴上的对象时,需要添加参数指定是1轴:axis=1。
5. pandas库的数据类型运算
5.1 算数运算
pandas的数据类型在进行算数运算时,根据行列索引,补齐后运算,即只有当索引相同时才进行运算,不同索引之间不进行运算而是补齐NaN。默认结果为浮点型。不同维度的数据类型之间的运算采用广播运算,即对应索引之间进行运算。 我们先来看一下相同维度的运算:
import pandas as pd
import numpy as np
a = np.arange(10).reshape(2,5)
b = np.arange(15).reshape(3,5)
a = pd.DataFrame(a)
b = pd.DataFrame(b)
print(a)
print(b)
print(a*b)
复制代码输出如下:
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
0 1 2 3 4
0 0.0 1.0 4.0 9.0 16.0
1 25.0 36.0 49.0 64.0 81.0
2 NaN NaN NaN NaN NaN
复制代码不同维度的运算如下:
import pandas as pd
import numpy as np
a = pd.Series([1,2,3,4,5])
b = np.arange(10).reshape(2,5)
b = pd.DataFrame(b)
print(a)
print(b)
print("________")
c = b-a
print(c)
复制代码我们生成一个一维series对象a,一个二DataFrame对象b,然后用b-a,得到的结果如下:
0 1
1 2
2 3
3 4
4 5
dtype: int64
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
________
0 1 2 3 4
0 -1 -1 -1 -1 -1
1 4 4 4 4 4
复制代码观察结果可以发现,b中的1轴都减去了a,即b中的每一行都对应减去了a中的元素。所以,对于不同维度的数据类型运算来说,默认的是高纬度的对series进行1轴运算。
5.2 比较运算
比较运算只能比较相同索引的元素,需要注意的是这里不进行补齐。二维和一维,一维和零维之间为广播运算,结果产生由布尔值组成的对象。
相同纬度:
import pandas as pd
import numpy as np
a = np.arange(16).reshape(4,4)
a = pd.DataFrame(a)
b = np.arange(4,20).reshape(4,4)
b = pd.DataFrame(b)
print(a,"\n")
print(b,"\n")
print(a == b)
复制代码输出如下:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
0 1 2 3
0 4 5 6 7
1 8 9 10 11
2 12 13 14 15
3 16 17 18 19
0 1 2 3
0 False False False False
1 False False False False
2 False False False False
3 False False False False
复制代码相同维度进行比较时,要求两个数据的尺寸必须相同,否则会报错。那么不同维度的相比较会是怎样的结果呢?让我们来看一下:
import pandas as pd
import numpy as np
a = pd.Series([1,2,3,4])
b = np.arange(1,17).reshape(4,4)
b = pd.DataFrame(b)
print(a,"\n")
print(b,"\n")
print(a==b)
复制代码输出结果为:
0 1
1 2
2 3
3 4
dtype: int64
0 1 2 3
0 1 2 3 4
1 5 6 7 8
2 9 10 11 12
3 13 14 15 16
0 1 2 3
0 True True True True
1 False False False False
2 False False False False
3 False False False False
复制代码可以发现,不同维度相比较,进行广播运算,默认是1轴。 此外,除了直接利用运算符进行运算外,我们还可以利用函数进行运算。
- .add(d,**argws):加法
- .sub(d,**argws):减法
- .mul(d,**argws):乘法
- .div(d,**argws):除法
通过这些函数我们不仅可以进行基本运算,而且带有可选参数的它,为我们提供了更加强大的功能,如下:
import pandas as pd
import numpy as np
a = np.arange(16).reshape(4,4)
a = pd.DataFrame(a)
b = np.arange(20).reshape(5,4)
b = pd.DataFrame(b)
print(a)
print(b)
c = b.add(a,fill_value=100)
print(c)
复制代码输出如下:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
0 1 2 3
0 0.0 2.0 4.0 6.0
1 8.0 10.0 12.0 14.0
2 16.0 18.0 20.0 22.0
3 24.0 26.0 28.0 30.0
4 116.0 117.0 118.0 119.0
复制代码可以发现,ab是相同维度,但是尺寸不同,按照上文中直接使用加法运算程序会报错。但是在这里,我们传入了一个参数,在进行先进行补齐操作,然后进行运算。
6. pandas操作CSV
6.1 pandas读取CSV文件
我们先创建一个15行4列的a.csv文件,用于下列案例之用:
import pandas as pd
import numpy as np
# 创建一个csv文件
a = np.arange(60).reshape(15,4)
a = pd.DataFrame(a,columns=("a","b","c","d"))
print(a,"\n")
a.to_csv("./a.csv",index=False)
复制代码文件内容如下:
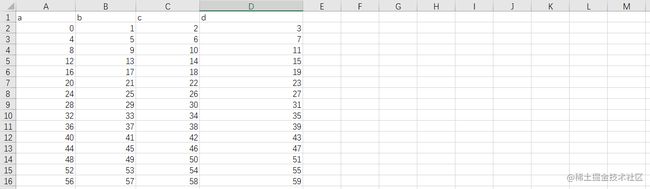
pd.read_csv()的常用参数如下:
- filepath_or_buffer:-- str 文件路径,可以是本地路径,也可以是url路径
- sep:指定分隔符,默认","
- header: --int 指定列名:header=0为默认值,表示数据第一行为列名;header=None表示数据没有列名(为0,1,2,3,4……),原列名变为第0行数据。
如案例1:
"""案例1:filepath_or_buffer、sep、header的使用 """
def demo01():
print("=== header=0时(默认)表示数据第一行为列名===")
path = "data.csv"
df = pd.read_csv(path, sep=",", header=0)
print(df.head(), "\n") # 默认输出前5行
print("===header=none时 列名变为第0行数据===")
# header = None时
df = pd.read_csv(path, sep=",", header=None)
print(df.head(), "\n")
复制代码输出如下:
=== header=0时(默认)===
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
===header=none时 ===
0 1 2 3
0 a b c d
1 0 1 2 3
2 4 5 6 7
3 8 9 10 11
4 12 13 14 15
复制代码- names: --list 指定列名,当文件含有列名时会覆盖
如案例2:
"""通过names参数重新指定列名"""
def demo02():
df = pd.read_csv(path, names=["A", "B", "C", "D"])
print("重新指定列名:")
print(df.head(), "\n")
复制代码输出如下:
重新指定列名:
A B C D
0 a b c d
1 0 1 2 3
2 4 5 6 7
3 8 9 10 11
4 12 13 14 15
复制代码- encoding:指定编码格式,默认为utf-8。常用户解决乱码问题和平台编码不同的问题。
- index_col:--str/list 指定索引,将表中的某一列数据指定为索引。可以是单列也可以是多列。
如案例3:
"""通过index_col参数指定索引"""
def demo03():
print("指定b列为索引:")
df = pd.read_csv(path, index_col="b")
print(df.head(), "\n")
df.to_csv("text.csv")
print("指定ab两列为索引:")
df = pd.read_csv(path, index_col=["a", "b"])
print(df.head())
复制代码输出如下:
指定b列为索引:
a c d
b
1 0 2 3
5 4 6 7
9 8 10 11
13 12 14 15
17 16 18 19
指定ab两列为索引:
c d
a b
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
16 17 18 19
复制代码- usecols: --str/list 指定读取的列,默认读取全部列
- nrows:--int 仅读取前多少行(不包括此行)
- skiprows:--int 跳过指定行数,开始读取(包括此行),注意必要时要指定列名,否则根据header=0当前行会为列名
如案例4:
"""usecols、nrows、skiprows的使用"""
def demo04():
print("只读取bc列:")
df = pd.read_csv(path, usecols=("b", "c"))
print(df.head(), "\n")
print("读取前6行:")
df = pd.read_csv(path, nrows=6)
print(df, "\n")
print("从第6行开始读取:")
df = pd.read_csv(path, skiprows=6, names=list("abcd"))
print(df.head(), "\n")
复制代码输出如下:
只读取bc列:
b c
0 1 2
1 5 6
2 9 10
3 13 14
4 17 18
读取前6行:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
5 20 21 22 23
从第6行开始读取:
a b c d
0 20 21 22 23
1 24 25 26 27
2 28 29 30 31
3 32 33 34 35
4 36 37 38 39
复制代码6.2 pandas保存CSV文件
通过pandas保存csv实质上是调用DataFrame对象的to_csv方法。接下来我们就主要介绍一下to_csv方法的常用参数。
path_or_buf: 保存路径sep:分隔符,默认为,na_rep:替换空格。将空格替换为指定的值float_format: 格式化数值如保留两位小数%.2fheader: 是否保留列名,默认保留。值为0则不保留。index:是否保留索引(布尔值),默认保留。