从 S3 到 DataZone,亚马逊云科技用16年讲完一个数据的故事


点击上方【凌云驭势 重塑未来】
一起共赴年度科技盛宴!
2022亚马逊云科技 re:Invent 全球大会在 Las Vegas 刚落下帷幕,和去年疫情刚结束后举行的 re:Invent 2021相比,这次的现场参展人数规模空前,官方统计超过5万。这也是 Adam Selipsky 作为亚马逊云科技掌门人的第二次线下 re:Invent 亮相,在 Adam 的 Keynote 中,他以浩渺星辰作为开场铺垫了3分多钟,只为了引出 Keynote 的第一个主题 —— Data。


亚马逊云科技的数据产品线起点也是亚马逊云科技的起点。Keynote 上,Adam 说亚马逊云科技拥有业界最全面的数据产品矩阵,那就借着这次 re:Invent 发布会,我们来一起回顾一下亚马逊云科技数据产品线的演进历程。
亚马逊云科技数据产品的演进
S3 - Simple Storage Service
注:亚马逊云科技把 S3 归在了存储(Storage),而不是数据(Data),但 S3 和数据关联紧密,所以是放在一起讨论。
S3 发布于2006年3月,是亚马逊云科技最古老的服务,标志着亚马逊云科技的诞生。S3 也是最核心的服务,假设要给亚马逊云科技服务做减法的话,最后一个留下的肯定也会是 S3。所以说,亚马逊云科技迈入云市场的第一步是正确的。S3 确如其名,提供的服务是很简单的,就是把文件托管到云上。
当然,提供简单服务的背后并不简单,Amazon.com 副总裁兼首席技术官 Werner Vogels 博士是服务化的铁杆粉丝,在他每次的 Keynote 里都会用 S3 作为案例。今年他又再次提到 S3 的微服务数量超过了235个(作为对比,通常一个互联网服务的微服务数是5个左右)。

不过在 2019年,S3 的微服务数量是262个。看来 S3 内部还是做了一系列的瘦身工作。
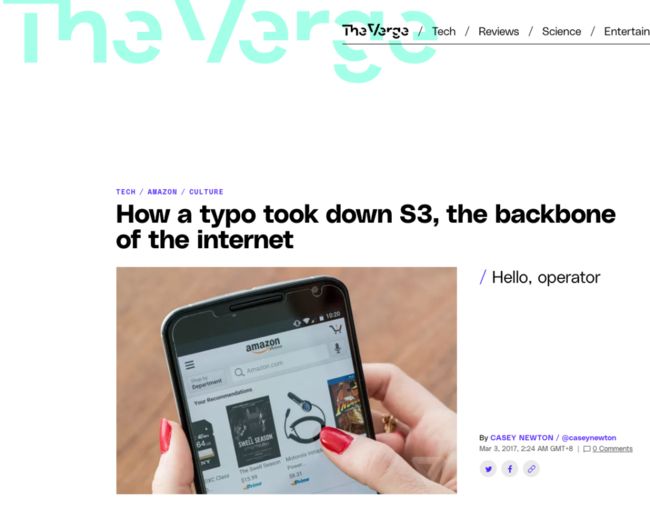
S3 的重要性也可以从另一个角度来印证。2017年 S3 在美东区的事故,造成了大面积的互联网服务瘫痪,也让许多人第一次意识到,S3 其实已经成为了互联网的基础设施(backbone)。
而也正是因为 S3 提供了简单,或者说基础原子的能力,在其之上才有了千变万化的可能。我想当初 S3 的设计者们,也一定没想到 S3 会成为数据湖(Data Lake)的基础,毕竟当年还没有数据湖这个概念呢。

现代数据架构
由 S3 开始,亚马逊云科技的数据产品线逐渐壮大,发育成了「五纵三横」的现代数据架构(Modern Data Architecture):「五纵」代表的是垂直产品,就是图上的5个圈——Databases、Analytics、Business Intelligence (BI)、Data Lakes、Machine Learning。
「三横」代表的是横向产品,即图中间的 Catalog 和 Governance 以及连接线隐含的 Integration。
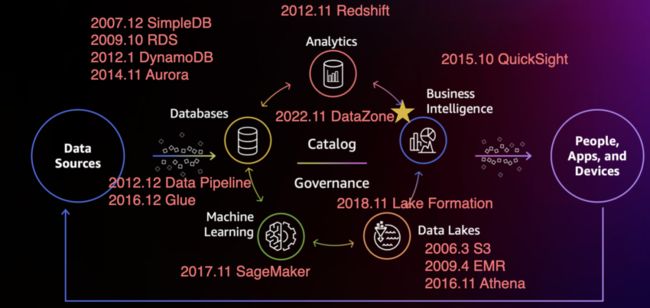
五纵
1.Databases:支撑在线业务的应用数据库,这其中最核心的是关系型(RDBMS)和非关系型(NoSQL),各自都经历了一次产品演进:
关系型:2009.10 RDS -> 2014.11 Aurora
非关系型:2007.12 SimpleDB -> 2012.1 DynamoDB
2.Analytics:分析型数据库/数据仓库,Redshift 一直是唯一的产品,而今年也正好是 Redshift 推出的第10年。其实 Redshift 最早是一款被收购来的产品,它的前身是 ParAccel 基于 PostgreSQL 的魔改。
3.Business Intelligence (BI):2015 年推出的 QuickSight,这块相对不是亚马逊云科技的强项。
4.Data Lakes:这两年数据领域最火的概念,亚马逊云科技在这块也早早地布了局:
存储:2006.3 发布的 S3,前面提过了,有点无心插柳成了数据湖领域的根基。
计算:2009.4 发布的 EMR (Elastic MapReduce),当然它也不再是只能跑 Hadoop 的 MapReduce 了,Spark、Flink、 TensorFlow、 Ray 各种执行引擎都能可以应用。
查询:2016.11 发布的 Athena,提供了通过 SQL 查询 S3 及其他数据源的接口。
5.Machine Learning:最早入列的是 re:Invent 2016上推出的三剑客:图像识别 Rekognition、文字识别 Polly、语音识别 LEX。

1年之后,亚马逊云科技推出了在 AI / ML 战线的基石产品 SageMaker。

三横
Integration:让用户把数据从系统 A 转移到系统 B,以及就在单一系统里做数据变换。这也是一条经过了迭代的产品线,从 2012.12 Data Pipeline 升级到2016.12 Glue。
Governance:2018.11 Lake Formation,是面向数据湖的产品。因为数据湖相比数据仓库,数据量大得多,又缺少结构化信息,不加以管理的话,就像是一堆乱积木丢在那里,既没有意义,哪里被人顺走一块也不知道。不过它的边界和 DataZone 之间会有些模糊,后续会谈到。
Catalog:2022.11 DataZone。这次 re:Invent 推出的产品,在后面新产品解读中会展开。
Data Gravity - 数据引力 / 重力

这也是 Keynote 上听到的一个概念,尤其是对应到中文翻译也很贴切。Gravity 在中文翻译里既有引力,也有重力的意思:
引力:资源是跟着数据跑的,数据在哪里,其他东西就在哪里。所以几大公有云厂商对于进来的数据流量都是不收费的(截图来自亚马逊云科技官网)。
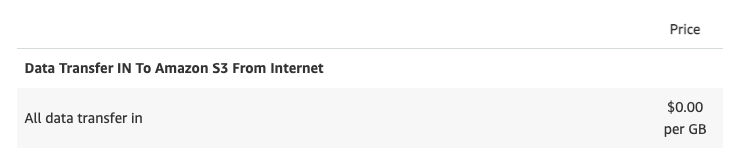
而出去的数据,则收得异常之高,Cloudflare 去年就此还专门写过一篇针对亚马逊云科技的文章(截图来自 https://blog.cloudflare.com/aws-egregious-egress/)。

重力:数据越积越多,数据种类和数据库类型也越来越丰富。驾驭数据的能力是自然下坠的趋势。
亚马逊云科技早期产品决策有关键的三点:
亚马逊云科技最先进入云市场,在2006年先后推出 S3、EC2。
押注在基于 VM 的 EC2方案,而不是直接跳到 PaaS。事实证明,用户上云的姿势还是 lift-and-shift,而不是直接一步到位(leapfrog)到云原生架构。
基于对数据引力的认知,尽早推出了各种独立的数据产品,这使亚马逊云科技很快成为公有云市场领跑者。在亚马逊云科技的体系里,数据和计算是两个独立的服务,先把数据弄上来,而又因为数据引力的作用,计算自然而然跟着数据也上来。

除了尊重数据引力的客观事实,亚马逊云科技另外做的就是对抗数据重力(Data AntiGravity),这次请来 Intuit 站台讲的也是这个主题,我们接下来就开始介绍围绕这个主题的几个新发布。
2022亚马逊云科技
re:Invent 全球大会
数据产品新发布功能的解读
DataZone

DataZone 是这次亚马逊云科技 re:Invent 数据线上最重磅的发布,也出现在了 Adam 的 Keynote 之中。DataZone 的介绍语是「A data management service to catalog, discover, share and govern data」,它的推出补上了整个数据线上唯一缺失的一个大模块——数据资产的管理。它的产品介绍里也提到了 Govern,前面讲 Lake Formation 是专门针对数据湖场景的 Governance 方案,所以在这块上,DataZone 和 Lake Formation 会存在一些边界上的重合,后续应该需要进行一下整合。不过我相信,DataZone 会是未来亚马逊云科技数据线上的基石产品——DataOps 的承载者,承担着打通各个数据系统任督二脉的角色。而基于 DataZone 之上,会再开发出数据安全、业务洞察等更加上层的应用。
不过亚马逊云科技发布 DataZone 的时间还是有些晚。在2018年的时间点才选择发布了只针对数据湖的 Lake Formation,而没有直接一步到 DataZone ,我能想到这么几个原因:
要做一个整合所有数据系统的数据平台,需要协调太多的资源,那时亚马逊云科技的组织架构没有准备好。
那时数据湖大火,Databricks、Snowflake 给了很大的压力,所以快速先出一个针对数据湖的产品。
Lake Formation 接下来的演进可以有两条路径:
类似 SageMaker,发展成 Lake Studio,成为数据湖的开发平台,Governance、Catalog 这些底层能力还是交给 DataZone。
和 Redshift 工作台进行整合,开发出湖仓一体的 Lakehouse 开发平台。
Aurora Zero ETL integration with
Redshift

不需要用户手工配置 ETL 任务,就能把 Aurora 的数据进行 ETL 同步到 Redshift 里面。
Auto-copy from Amazon S3 to
Redshift

和上面那个类似,不过数据源换成了 S3,也暂时没有 ETL 功能。不过这也是解决了一个刚需高频场景,也为未来进一步的 ETL 方案铺路。
以上两个功能整体揭开了亚马逊云科技往 Zero ETL 方向发展的序幕。数据的归属可以分成四大类:
在线事务数据库的数据
数仓里的数据
数据湖里的数据
在 Salesforce、HubSpot 这些第三方系统里的数据
那为了达成 Zero ETL,整合数据的思路有两种,一种是整合数据库系统,比如像 HTAP 数据库,底下有一套 TP 和 AP 引擎,至于数据是否是一套和两套,用户则并不需要关心,这其中的代表是 PingCAP 的 TiDB 以及 Google 的 AlloyDB。另一种思路还是让数据在各自的系统(the best of the breed),但是尽可能优化数据之间的流转,亚马逊云科技目前是后一种思路的代表。前一种思路具备架构先进性,而后一种则更为务实。
说完数仓这块,我们再介绍两个在线数据库方面的新发布。
RDS 蓝绿发布


针对数据库变更场景的一个实用功能,现场在介绍到这个功能时,底下爆发出了热烈的欢呼。今年不少数据库都开始投入到开发工作流上,像 PlanetScale、Neon,而 RDS 也终于在推出13年后,开始在这块有所动作。针对 Schema Changes 的场景虽然和我们的 Bytebase 有重合,但行业里有更多公司提供这类场景的解决方案,是一个好事情,能让更多人意识到直接连上数据库做 schema 变更是不 OK 的。当然 RDS 做这套方案还有一个好处,就是它可以多卖一倍的 RDS 实例,而 RDS 本身的 margin 已经很高了。
Trusted Language Extensions for
PostgreSQL
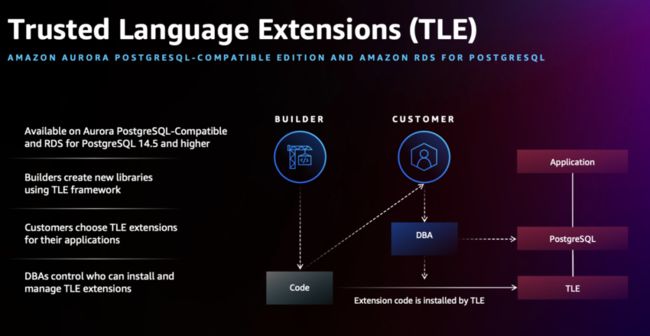
据笔者了解,亚马逊云科技是所有公有云里,PostgreSQL 内核开发经验储备最丰富的厂商。这次他们就给社区带来了一套开发 Extension 的新框架 TLE。出于安全和稳定性考虑,本来云上的 PostgreSQL 实例只能装亚马逊云科技指定的 Extension,如果业务团队有自己的业务需求,要写新的 Extension 就没有办法了。这就是 TLE 希望解决的问题,TLE 提供了一些 hook 点,在保证安全和稳定性的前提下,可以让开发团队在这套框架里自己开发插件,然后再由 DBA 帮忙安装到实例上去。TLE 本身也是开源的 https://github.com/aws/pg_tle,项目还处于早期,目前只开放了用于密码检查的一个 hook。

这也算是亚马逊云科技回馈给开源社区的一点工作,而近10年来,整个亚马逊云科技数据产品线和开源商业公司们之间发生了不少故事, 我们就接着讲一下他们之前的关系演进。
亚马逊云科技
和开源商业公司的博弈
目前比较成功的开源商业公司,大多数都集中在数据产品线。这些公司合在一起的体量也有资格和亚马逊云科技进行博弈,而亚马逊云科技和这些开源商业公司的关系演进可以用 Tuckman 团队发展模型来概括:
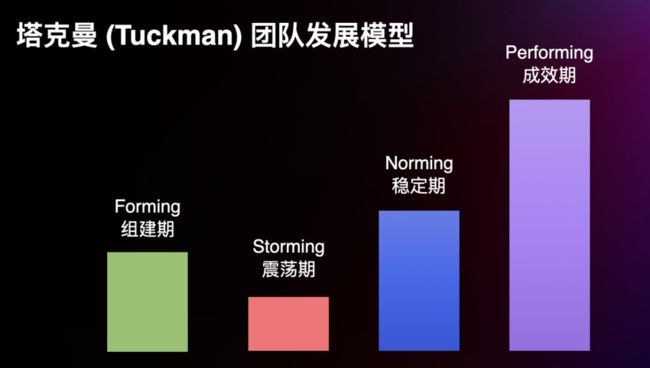
模式探索的组建期

第一次亚马逊云科技和开源商业公司的交手是围绕在 Hadoop 生态上,当时整个业界也还在探索开源商业模式,比如到底是提供公有云服务还是做私有化部署。亚马逊云科技因为本身就只有公有云,所以推出了 EMR (Elastic MapReduce),而 EMR 则给 Amazon EC2 带来了第一根增长曲线。MapReduce 简单粗暴的计算模型,随便跑一个任务就掀起几十上百个 EC2 实例,后来 Hive 提供了 SQL 查询能力,又进一步扩大了受众面。
Hadoop 本身是一个平价版的 MapReduce 实现,而恰恰是这个不那么高效的实现,却给 Amazon EC2 带来了最好的场景。
无论是有意还是无意,总之在开源商业化方兴未艾之时,亚马逊云科技利用别人研发的开源软件在商业上取得了巨大的成功。
四面楚歌的震荡期
Hadoop之后,又涌现了一批优秀的开源数据产品,以及基于这些产品成立的商业公司。而因为一开始大家都采用了开放的(permissive)开源证书,比如 Apache、MIT,这些协议规定比较宽松,大的云厂商都可以直接使用,再集成上自身平台上的其他服务,很快就能推出一个非常有竞争力的发行版。这使得那些开源商业公司坐不住了,因为毕竟绝大多数开源产品的研发工作是由他们完成的,而其他公司却能直接使用,并且还能加上自身平台优势和这些开源商业公司直接竞争。这其中最激烈的要数 Elastic 改协议事件「Amazon: NOT OK -why we have to change Elasticlicensing」,因为部分协议对使用要求过于开放,商业利益限制不够明确,在那段时间,开源项目也纷纷修改证书,以不断修正公有云厂商的和自己的这种直接竞争。

亚马逊云科技和开源商业公司存在一定的竞争是行业发展的必然。大家发现开源产品,尤其是数据域的开源产品,靠产品 +Cloud 而不是走 Redhat 的服务模式也能产生巨大的商业价值,自然就一拥而上。开源社区已有的规则无法适应新的开源商业模式,双方也只能互相试探,尽可能占据道德制高点,给自己多争取点地盘。毕竟像 PostgreSQL 这样纯社区运营的开源项目,大家不就处得很好么。
Marketplace 支撑的稳定期
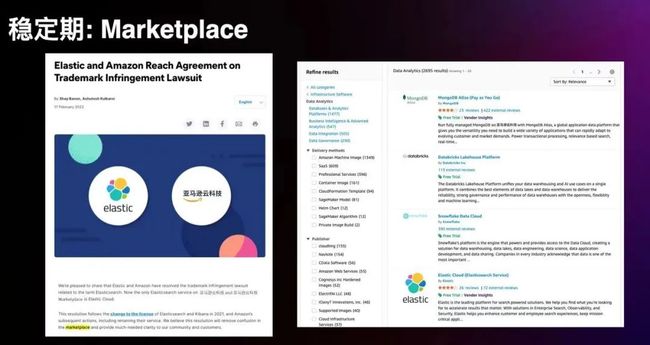
所幸近两年双方的对立开始缓和。开源商业公司本身也是云厂商的用户,他们自己的服务要跑在云厂商提供的 VM、k8s 这些服务上面,他们也要和云厂商的服务做集成,以提供更具竞争力的产品,他们也需要亚马逊云科技这样的分发采购渠道,提高他们的商业效率。而对于云厂商来说,首先市场也并不是只有一家服务商,同时云市场的增长空间依然巨大,所以也没有必要现在选择零和博弈。而在有合作基础的情况下,Marketplace 给双方提供了一个合作的平台,从亚马逊云科技的 Marketplace 可以看到,第三方服务还排在它自家服务的前面。
求同存异的成效期?
今年 re:Invent 举办时,MongoDB 发了一篇热情洋溢的文章,回顾了和亚马逊云科技过去十年的合作。虽然这篇文章和作者 Matt Asay 本人经历有关,他之前先在 Mongo,后去了亚马逊云科技,这次又回到 Mongo,但在官博上写一篇这样的文章还是挺意外的。只能说像 Mongo 这样的开源商业公司和亚马逊云科技这样的云平台的关系是微妙的,但看起来大家逐渐找到了求同存异的方法(像雇佣 Matt 这样两边都有人情的人也绝对是好招)。
有人觉得掺杂商业元素的开源就不纯粹了。但你情愿自己依赖的开源软件是个人爱好者躲在小黑屋里,用爱发电,利用业余时间维护的产品?还是有明确的商业模式,有全职团队维护的产品?
以商业为目的的开源是否也是另一种的纯粹呢?

未来展望
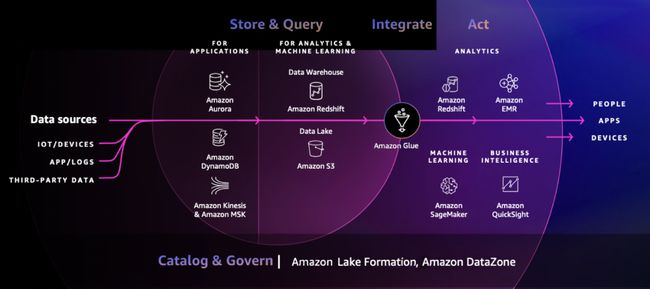
随着这次 DataZone 的推出,亚马逊云科技数据产品矩阵补上了最后一块缺失的拼图,而接下来我还有两大期待:
面向终局的 Zero ETL
re:Invent 上亚马逊云科技已经表达了会往 Zero ETL 的方向走,不过这次推出的 Zero ETL 相关功能,底层还是要在不同数据存储系统间做转移。另一边我们也可以看到,亚马逊云科技的 RDBMS 和 NoSQL 都已经迭代了一次(RDS -> Aurora,SimpleDB ->DynamoDB),而同为三剑客之一的 OLTP 数仓 Redshift 大体还是10年前的样子(这个还不算上它的前身,从 2006 年开始的 ParAccel)。数据湖的数据是放在 S3 上的,而 AlloyDB 已经把基于类 S3 存储的 OLAP/OLTP 混合引擎给实现了。所以我在猜想亚马逊云科技的下一个大招是否会推出一个基于 S3,集合 TP、AP 和 Lake 的全新数据库,名字嘛,可以就叫 ALT=A(nalytical)+L(ake)+T(ransactional)。

更成熟的 Marketplace 和生态合作
除了开幕 Keynote 外,亚马逊云科技首席执行官 Adam Selipsky 唯一还参与的就是 Partner 的 Keynote,从这点也可以看出亚马逊云科技对于生态合作伙伴的重视。而 Partner 中的 Marketplace 板块则是让亚马逊云科技从提供单纯的技术赋能,延伸到商业赋能的核心阵地。Marketplace 使得亚马逊云科技和开源商业公司之间,可以在技术产品层面保持竞争,但在商业层面实现共赢。当然这着实考验平台的格局、操盘者的智慧以及合作方之间化学反应的运气。
接下来的故事

从一个简单的文件存储服务 S3 到这次 re:Invent 推出的一站式数据资产管理平台 DataZone,亚马逊云科技花了16多年的时间讲完了一个数据的故事。当年 S3 的创立者想必也没有预见到,本来只是用于存放文件的云服务,催生了云数仓,数据湖这些新的品类,还很有可能成为下一代数据库的基石。
而在技术之上,如今的亚马逊云科技更肩负着平台的责任。这次 Adam keynote 上选择的 Guest Speakers,一个是探索绿色能源的 Engie,一个是探索太空的西门子,还有一个是探索分子靶向治疗癌症的 Lyell。相较于 re:Invent 2019 请 Vanguard 来讲金融系统的上云,亚马逊云科技这次想传达给观众的,是它的平台正在承载拓展文明边界的事业。

而一个能够平衡眼前商业利益和长期理想主义的平台才能引导整个行业走向远方,让我们一起跟随亚马逊云科技,进入它下一个数据的故事。

撰写本文的素材主要来自:
亚马逊云科技 re:Invent 2022 - Keynote with Adam Selipsky -
https://www.youtube.com/watch?v=Xus8C2s5K9A
亚马逊云科技 re:Invent 2022 - Keynote with Swami Sivasubramanian -
https://www.youtube.com/watch?v=TL2HtX-FmiQ
亚马逊云科技 re:Invent 2022 - Keynote with Dr. Werner Vogels -
https://www.youtube.com/watch?v=RfvL_423a-I
亚马逊云科技 re:Invent 2022 - Keynote with Ruba Borno -
https://www.youtube.com/watch?v=jT92JD6KIH8
亚马逊云科技 re:Invent 2022 - Unlock the value of your data with Amazon analytics -
https://www.youtube.com/watch?v=A6DG_Afe07I
亚马逊云科技 re:Invent 2022 - Your data: How you need it, where you need it, when you need it -
https://www.youtube.com/watch?v=AJlsAin7_rQ
A History of Amazon Web Services -
https://www.awsgeek.com/AWS-History
同时笔者也参考了如下 re:Invent 相关的公众号文章:
2019亚马逊云科技 re:Invent 之旅:
https://mp.weixin.qq.com/s/MnqTHEZ_adqAB0hAwf-_MQ
亚马逊云科技 re:Invent 2022讲了什么:
https://mp.weixin.qq.com/s/WL2HlmlHhQDE2ZrSEL7SuA
亚马逊云科技 re:Invent 2022的一些发布:
https://mp.weixin.qq.com/s/WlZLirzZ0mFDQ1lyypxcsA
飞总带大家解读 亚马逊云科技 re:Invent 2022大数据相关的发布:
https://mp.weixin.qq.com/s/7YWHIzY-IRYXJgfhzJYSCw
Amazon CodeCatalyst 走马观花:
https://mp.weixin.qq.com/s/1aIQmC0-s9s8ks8u6zUQTg
最后也感谢 Fei Xue,Monica Xie 对本文细致的审阅。
2022亚马逊云科技 re:Invent 全球大会
中国行现已开启!
点击下方图片即刻注册

听说,点完下面4个按钮
就不会碰到bug了!