Java八股文重点记录
JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的⽂件),它不⾯向任何特定的处理器,只⾯向虚拟机。Java 语⾔通过字节码的⽅式,在⼀定程度上解决了传统解释型语⾔执⾏效率低的问题,同时⼜保留了解释型语⾔可移植的特点。所以 Java 程序运⾏时⽐较⾼效,⽽且,由于字节码并不针对⼀种特定的机器,因此,Java 程序⽆须重新编译便可在多种不同操作系统的计算机上运⾏。
JDK 是 Java Development Kit,它是功能⻬全的 Java SDK。它拥有 JRE 所拥有的⼀切,还有编译器(javac)和⼯具(如 javadoc 和 jdb)。它能够创建和编译程序。
Java允许重载任何方法
多态就是指程序中定义的引⽤变量所指向的具体类型和通过该引⽤变量发出的⽅法调⽤在编程时并不确定,⽽是在程序运⾏期间才确定
成员变量如果没有被赋初值:则会⾃动以类型的默认值⽽赋值(⼀种情况例外:被 final 修饰的成员变量也必须显式地赋值),⽽局部变量则不会⾃动赋值。

String 中的 equals ⽅法是被重写过的,因为 object 的 equals ⽅法是⽐较的对象的内存地
址,⽽ String 的 equals ⽅法⽐较的是对象的值。
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相
同的对象,如果有就把它赋给当前引⽤。如果没有就在常量池中重新创建⼀个 String 对象。
hashCode()该⽅法通常⽤来将对象的 内存地址 转换为整数之后返回
当你把对象加⼊ HashSet 时, HashSet 会先计算对象的 hashcode 值来判断对象加⼊的位置,
同时也会与其他已经加⼊的对象的 hashcode 值作⽐较,如果没有相符的 hashcode, HashSet
会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调⽤ equals() ⽅
法来检查 hashcode 相等的对象是否真的相同




Runnable 接⼝不会返回结果或抛出检查异常,但是 Callable 接⼝可以
Atomic 是指⼀个操作是不可中断的。即使是在多个线程⼀起执⾏的时候,⼀个操作⼀旦开始,就不会被其他线程⼲扰。

















IOC方式

![]()















lock 接口在多线程和并发编程中最大的优势是它们为读和写分别提供了锁,它能满足你写
像 ConcurrentHashMap 这样的高性能数据结构和有条件的阻塞。
sleep与wait的区别
sleep是放弃CPU,在经过指定的时间后再获取CPU继续执行,wait是放弃同步锁,等待notify去唤醒




![]()








ArrayList扩容是1.5倍




王道记录
并行是并发的特例,并行一定并发
并行是真正的同一时刻发生。
线程是独立调度的基本单位,进程是拥有资源的基本单位。同一个进程的线程共享资源。内核意识不到线程的存在
死锁是指多个进程因竞争资源而造成的互相等待
预防死锁:破坏死锁的四个必要条件
避免死锁:在资源动态分配过程中设置某些条件防止系统进入不安全状态(银行家算法)
CSMA适用于半双工
端口标识的是主机中的应用进程
两次握手的问题:
防止已失效的报文传到服务端产生问题。假设客户A向服务端B建立TCP请求,A的第一个报文超时于是重传一次,B收到之后建立连接通信,数据传输结束后断开连接,而此时超时的第一个报文又到达B则B又会认为A发来了连接请求从而产生错误。
DNS不区分大小写,除了-外不能使用其他标点。
URL中也不区分大小写。
万维网以C/S架构工作
链表的存储密度不如顺序表
克鲁斯卡尔是加边与点无关,普利姆是加点适合稠密图
基数排序的适用场景是关键字选择范围较小
复杂度
时间:快希堆nlogn、
空间:快nlogn,归并n,基数rd
稳定性:快希选堆
b树孩子节点个数的最大值称为阶
叶节点处于同一层
select name as Employee
from Employee e
where salary > (select salary from Employee
where id = e.managerId)
每次对 String 类型进行改变的时候都会生成一个新的 String 对象,然后将指针指向新的 String。

join 可以把两张相同的表拼接到一起,更准确的说是按某种条件拼接到同一行。








order by放查询最后,并不一定要连接两个表
查询连续空座位
select distinct c1.seat_id
from Cinema c1, Cinema c2
where abs(c1.seat_id-c2.seat_id) = 1 and c1.free = 1 and c2.free
order by c1.seat_id
@Autowired注解由Spring提供,只按照byType注入;@resource注解由J2EE提供,默认按照byName自动注入
- static修饰的类只能为内部类,普通类无法用static关键字修饰。
- static修饰静态方法的访问方式为 (类名.方法名)
- static修饰的变量为静态变量,静态变量在内存中只有一份存储空间,静态变量不属于某个实例对象,被一个类中的所有对象所共享,属于类,所以也叫类变量,可以直接通过类名来引用。
一般引起Cookie丢失的原因
1、Cookie的Domain设置不正确
2、Cookie超时
3、Cookie中含有一些非法字符,致使浏览器丢弃Cookie
4、程序源码可能有多处重复设置或取消Cookie
select *,
if(x+y>z and x+z>y and y+z>x, 'Yes', 'No') triangle
from Triangle







 Eureka保证的是AP(网络有问题时触发自我保护机制,不会移除过期服务,同时能接受新服务,保证可用性,而不会同步到其他节点,无法保证一致性)
Eureka保证的是AP(网络有问题时触发自我保护机制,不会移除过期服务,同时能接受新服务,保证可用性,而不会同步到其他节点,无法保证一致性)
我们可以将调用的服务方法定义成抽象方法保存在本地添加一点点注解就可以了,不需要自己构建Http请求了,直接调用接口就行了


 db仅作为存储不做运算
db仅作为存储不做运算
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False.
TCP慢开始,指数增长拥塞窗口,到达门限后线性增长,网络拥塞后再变成1进行循环。

 没有主键没关系,有隐藏字段roll_id
没有主键没关系,有隐藏字段roll_id









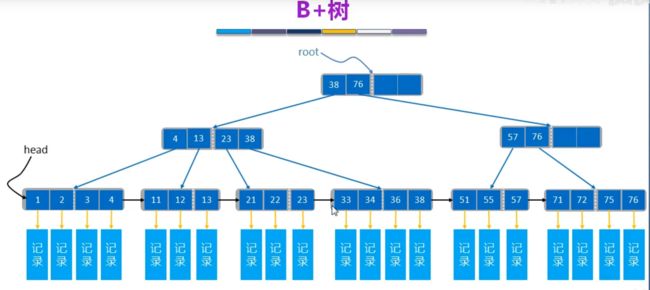
 左小右大,每个树孩子节点最多阶数的一半保持平衡性
左小右大,每个树孩子节点最多阶数的一半保持平衡性

大根堆是指父节点的值大于等于子节点。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。(因为客户端可能还没发完,所以只是回复收到并没有回复Fin断开)
(3) 服务器关闭客户端的连接,发送一个FIN给客户端。
(4) 客户端发回ACK报文确认,并将确认序号设置为收到序号加1。
数据链路层 网络层 传输层 应用层
快恢复是指从信的拥塞窗口(拥塞值+原来值)/2 直接开始线性增长。
慢开始是从2的指数开始增。
update salary
set sex = if(sex=‘m’,‘f’,‘m’)
CAS是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。




本地方法栈与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
本地方法一般是用其它语言(C、C++ 或汇编语言等)编写的,并且被编译为基于本机硬件和操作系统的程序,对待这些方法需要特别处理。

垃圾收集器版本
串行与并行,细分又有是否对老年代的专一回收。
CMS 收集器
CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。






 docker
docker




IOC初始化流程
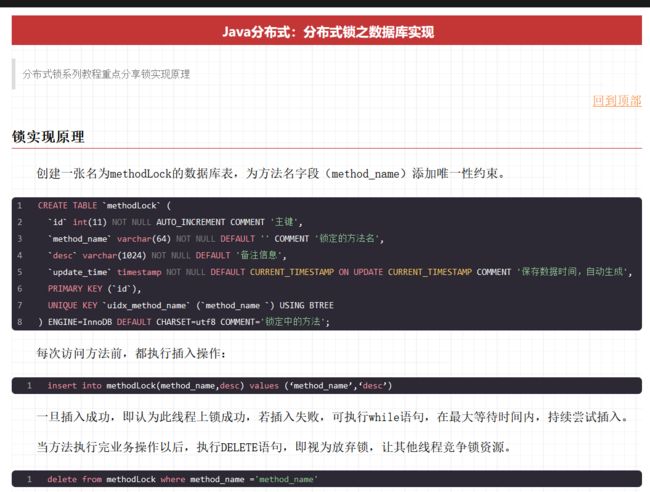
第一个过程是Resource定位过程。这个Resource定位指的是BeanDefinition的资源定位,它由ResourceLoader通过统一的Resource 接口来完成,这个Resource对各种形式的BeanDefinition的使用都提供了统一接口。
第二个过程是BeanDefinition的载入。这个载入过程是把用户定义好的Bean表示成IoC容器内部的数据结构,而这个容器内部的数据结构就是BeanDefinition。
第三个过程是向IoC 容器注册这些BeanDefinition 的过程。这个过程是通过调用BeanDefinitionRegistry接口的实现来完成的。这个注册过程把载入过程中解析得到的BeanDefinition 向IoC容器进行注册。通过分析,我们可以看到,在IoC容器内部将BeanDefinition注入到一个HashMap 中去, IoC容器就是通过这个HashMap来持有这些BeanDefinition数据的。

IOC 是基于 java 的反射机制以及工厂模式实现的。





覆盖索引:就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
节点之间采用Gossip协议进行通信,Gossip协议就是指节点彼此之间不断通信交换信息


MySQL数据存储结构
数据保存在连续的内存中,如果没有行号,还会隐式加上行号
先更新缓存然后更新数据库
这种情况出现缓存更新成功,但是数据库失败这就很严重了
先更新数据库再更新缓存
可能会出现缓存出错,这种情况等缓存失效就可以正常读取了
这两种的根本问题在于无法保证缓存与数据库操作的原子性
先删除缓存再更新数据库
删除成功更新数据库失败则永远读到的都是老数据
先更新数据库,再删除缓存
更新数据库成功,删除失败。在缓存失效前读到的是老数据,影响最小。并且可以增加定时任务去比对缓存与db作为补偿,redis存的是字段,一般认为瓶颈是在db。
删除失败操作
在删除失败后把信息打入一个队列并监听,监听队列挂了考虑采用守护进程挂起,守护进程挂了怎么办就是无底洞
分布式锁




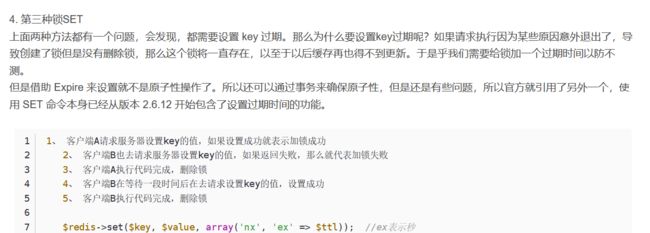
 方法做了唯一性约束,这样如果有多个请求同时提交到数据库的话,数据库可以保证只有一个操作可以成功,那么那么我们就可以认为操作成功的那个请求获得了锁。
方法做了唯一性约束,这样如果有多个请求同时提交到数据库的话,数据库可以保证只有一个操作可以成功,那么那么我们就可以认为操作成功的那个请求获得了锁。
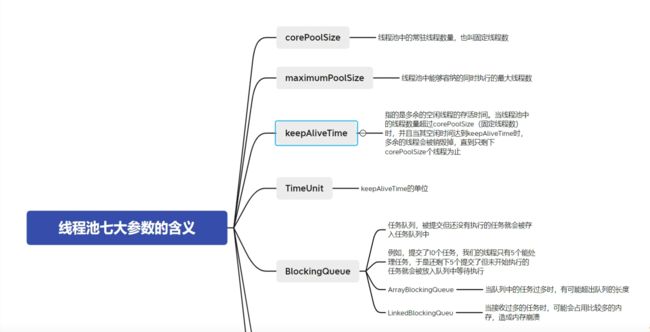
 核心线程,也就是正在处理中的任务
核心线程,也就是正在处理中的任务
线程池的核心线程数量等于CPU核心数+1。如果当前运行线程小于核心线程数可以直接运行。
group by不加括号
查询的select 最后不要加逗号

动态代理
介绍动态代理之前必须要了解静态代理。假如现在有这样一个需求,在不改变原有代码的基础上在所有类的方法前后打印日志。我们可以为所有类都编写代理类,并且让他们实现对应的接口,然后在创建代理对象时传入目标对象,然后在调用前后打印日志。代理对象 = 目标对象+增强方法。有了代理类就不需要原对象了。动态代理的思想就是不写代理类,直接通过反射技术来创建代理实例。
//Java实现是通过实现 InvocationHandler 接口创建自己的调用处理器。
队列满了,线程池数量达到最大值再有新的任务会拒绝执行抛出异常。

支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。




SELECT 子结果嵌套
SELECT ROUND(
100 * (SELECT COUNT(*) FROM Delivery WHERE order_date = customer_pref_delivery_date )/
(SELECT COUNT(*) FROM Delivery)
,2
) AS immediate_percentage



线程通信



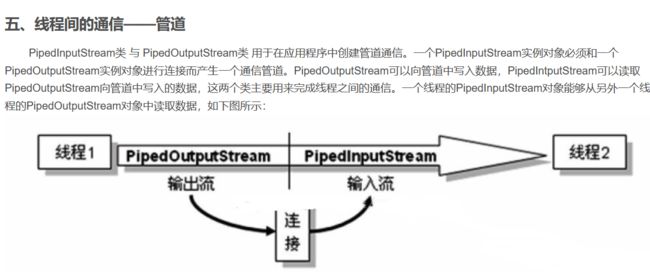
Java锁的原理是通过底层CPU去监视是有被占用。
非聚簇索引叶子节点是数据地址,聚簇索引是值。每张表只能有一个聚簇索引,也就是我们常说的主键索引;
HTTPS 在内容传输的加密上使用的是对称加密,非对称加密只作用在证书验证阶段。
spring循环依赖
循环依赖会导致注入发生死循环
循环依赖有三种情况:A依赖A,自我依赖;A依赖B,B依赖A;A依赖B,B依赖C,C依赖A
解决方式是设置多级缓存来解决
当我们使用getBean获取bean实例的时候,spring会先从一级缓存去找,一级找不到会去二级找,二级也找不到则这个bean没有被初始化,会去初始化放入二级缓存,还有一个三级缓存放置代理bean。
除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(OOM)异常的可能,
mysql如何保证ACID
数据库保证原子性
原子性由undolog日志来保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
数据库保证隔离性
隔离性是由MVCC来保证
数据库保证持久性
持久性由redolog来保证,mysq|修改数据的时候会在redolog中记录一份日志数据,就算数据没有保存成功,只要日志保存成功了,数据仍然不会丢失
数据库如果保证一致性
一致性由其他三大特性保证,程序代码要保证业务上的一致性
redis删除失败补偿机制
补偿措施即可,例如利用消息队列
查询结果过多优化
分页查询(limit关键字)
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
Druid:数据库连接池实现技术
线程池:



线程池的核心思想是重复利用线程执行任务而不是执行完就释放
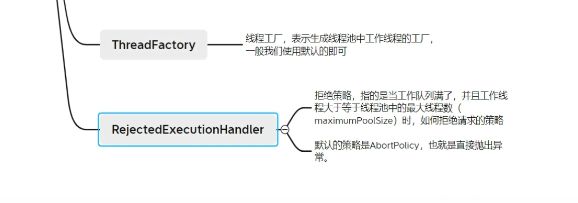
拒绝策略
默认策略:抛出异常
直接将刚提交的任务丢弃,而且不会给与任何提示通知
这种策略和上面相似。不过它丢弃的是队列中的头节点,也就是存活时间最久的
这种策略算是最完善的相对于其他三个,当线程池无能力处理当前任务时,会将这个任务的执行权交予提交任务的线程来执行,也就是谁提交谁负责,这样的话提交的任务就不会被丢弃而造成业务损失,同时这种谁提交谁负责的策略必须让提交线程来负责执行,如果任务比较耗时,那么这段时间内提交任务的线程也会处于忙碌状态而无法继续提交任务,这样也就减缓了任务的提交速度,这相当于一个负反馈。也有利于线程池中的线程来消化任务
超卖问题

spring事务失效
1、spring的事务注解@Transactional只能放在public修饰的方法上才起作用,如果放在其他非public(private,protected)方法上,虽然不报错,但是事务不起作用
2、如使用mysql且引擎是MyISAM,则事务会不起作用,原因是MyISAM不支持事务,可以改成InnoDB引擎
3、在业务代码中如果抛出RuntimeException异常,事务回滚;但是抛出Exception,事务不回滚;
解决方法@Transactional改为@Transactional(rollbackFor = Exception.class)
4、如果在加有事务的方法内,使用了try…catch…语句块对异常进行了捕获,而catch语句块没有throw new RuntimeExecption异常,事务也不会回滚
5、在类A里面有方法a 和方法b, 然后方法b上面用 @Transactional加了方法级别的事务,在方法a里面 调用了方法b, 方法b里面的事务不会生效。原因是在同一个类之中,方法互相调用,切面无效 ,而不仅仅是事务。这里事务之所以无效,是因为spring的事务是通过aop实现的。
group_concat可以将group后的字段拼接起来
mysql默认隔离级别可重复读
mysql索引B+树
2、可重入锁:
又称递归锁,指同一线程在外层方法获取锁的时候,在进入内层方法会自动获取锁,可一定程度上避免死锁
ReentrantLock锁是可重入锁,名称是 Reentrant Lock
Synchronized锁也是可重入锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7和JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承ReentrantLock)。当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在哪一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
redis快的原因:IO多路复用
Java synchronize只能修饰内部类
分段锁假如是空的链表头,那么用cas,假如是往后面添加,就用sychronize
AQS是AbstractQueuedSynchronizer的简称。AQS提供了一种实现阻塞锁和一系列依赖FIFO等待队列的同步器的框架
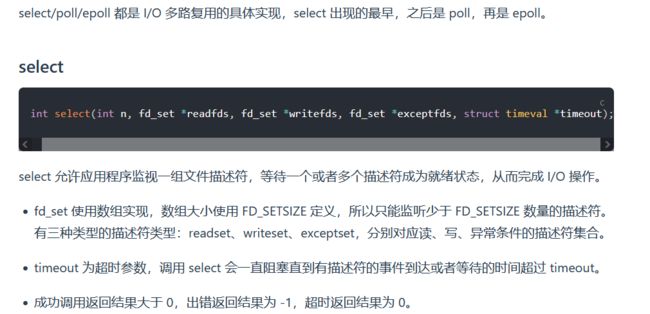
IO复用
一个线程可以处理多个IO请求。
可重入就是说某个线程已经获得某个锁,可以再次获取锁而不会出现死锁
MySQL 幻读假如是快照读的化,用MVCC即可。但是假如是当前读的化,就需要用间隙锁
cglib和jdk动态代理区别:
1、Jdk动态代理:利用拦截器(必须实现InvocationHandler)加上反射机制生成一个代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理
2、 Cglib动态代理:利用ASM框架,对代理对象类生成的class文件加载进来,通过修改其字节码生成子类来处理
302状态码应用的典型场景是服务器页面路径的重新规划
什么是跨域?
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域
想从子查询中查结果可以先写子查询代码,并且包含需要查询的字段
select person_name
from (
select person_name,sum(weight) over(order by turn) total
from Queue
) a
where total <= 1000
order by total desc limit 1
Serial(串行GC)-复制
ParNew(并行GC)-复制
Parallel Scavenge(并行回收GC)-复制
Serial Old(MSC)(串行GC)-标记-整理
CMS(并发GC)-标记-清除
Parallel Old(并行GC)--标记-整理
G1(JDK1.7update14才可以正式商用)
AQS


concurrenthashmap专题



I/O多路复用 (单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流 。)
可重入锁可以理解为:同一个线程下,外层方法上锁之后,内层调用的方法也能正常获取锁。
Thread.yield() 方法,使当前线程由执行状态,变成为就绪状态,让出cpu时间,在下一个线程执行时候,此线程有可能被执行,也有可能没有被执行。
其内部包含一个计数器,当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在 执行 monitorexit 指令后,将锁计数器设为0
ReentrantLock 是如何实现可重入性的?
ReentrantLock 内部自定义了同步器 Sync,在加锁的时候通过 CAS 算法,将线程对象放到一个双向链表中,每次获取锁的时候,检查当前维护的那个线程 ID 和当前请求的线程 ID 是否 一致,如果一致,同步状态加1,表示锁被当前线程获取了多次。
ReentrantLock和synchronized区别
ReentrantLock的粒度要更细,类似于lock
使用synchronized关键字实现同步,线程执行完同步代码块会自动释放锁,而ReentrantLock需要手动释放锁。
synchronized是非公平锁,ReentrantLock可以设置为公平锁。
ReentrantLock上等待获取锁的线程是可中断的,线程可以放弃等待锁。而synchonized会无限期等待下去。
ReentrantLock 可以设置超时获取锁。在指定的截止时间之前获取锁,如果截止时间到了还没有获取到锁,则返回。
ReentrantLock 的 tryLock() 方法可以尝试非阻塞的获取锁,调用该方法后立刻返回,如果能够获取则返回true,否则返回false。
共享式与独占式锁
共享式与独占式的最主要区别在于:同一时刻独占式只能有一个线程获取同步状态,而共享式在同一时刻可以有多个线程获取同步状态。例如读操作可以有多个线程同时进行,而写操作同一时刻只能有一个线程进行写操作,其他操作都会被阻塞。
Semaphore(信号量):是一种计数器,用来保护一个或者多个共享资源的访问。如果线程要访问一个资源就必须先获得信号量。如果信号量内部计数器大于0,信号量减1,然后允许共享这个资源;否则,如果信号量的计数器等于0,信号量将会把线程置入休眠直至计数器大于0.当信号量使用完时,必须释放。


 快照读就是读取的是快照数据,不加锁的简单 Select 都属于快照读。
快照读就是读取的是快照数据,不加锁的简单 Select 都属于快照读。
5、In 和 Exists 的区别?
in 适合内表比外表数据小的情况,exists 适合内表比外表数据大的情况。如果查询的内外表大小相当,则二者效率差别不大。
一条sql可以使用多条索引,叫索引合并
会死锁的sql,update+where
UPDATE t1 SET
Field1 = ‘someValue’
FROM Table1
WHERE Condition = ‘TheCondition’
UPDATE t1 SET
Condition = ‘someValue’
FROM Table1
WHERE Field1 = ‘someValue’
限流算法
计数器算法
这是最容易理解和实现的算法,假设一个接口1s中最多请求100次。最开始设置一个计数器count=0,来一个请求count+1,1s之内count<=100的请求可以正常访问,count>100的请求则被拒绝,1s之后count被重置为0,重新开始计数
当然这种方式有个弊端,1s内只有最开始的100个请求能正常访问,后面的请求都不能正常访问,即突刺现象。此时我们就可以用滑动窗口算法来解决这个问题,例如把1s分成5个时间段,每个时间段能正常请求20次。
漏桶算法参考家里使用的漏斗你就能明白了,往漏斗里面倒水,不论倒多少水,下面出水的速率是恒定的。当漏斗满了,多余的水就被直接丢弃了。
类比流量,每秒处理的速率是恒定的,如果有大量的流量过来就先放到漏斗里面。当漏斗也满了,请求则被丢弃。
令牌桶算法
令牌桶算法可以说是对漏桶算法的改进。漏桶算法能限制请求的速率。而令牌桶算法在限制请求速率的同时还允许一定程度的突发调用
UNION 会去重,可以简单的把多个查询的结果合并展示
SELECT employee_id,department_id
FROM employee
WHERE PRIMARY_FLAG = 'Y'
UNION
SELECT employee_id,department_id
FROM employee
GROUP BY 1
HAVING COUNT(*) = 1
ORDER BY employee_id;
IFNULL(A,B) 非null返回A,null返回B
Redis中sorted set的实现是这样的:
当数据较少时,sorted set是由一个skiplist来实现的。
当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据
秒杀防重提交会用到分布式锁。
分布式锁与数据库锁:
为什么要使用分布式锁
为了保证一个方法在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLcok或synchronized)进行互斥控制。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。数据库锁是针对于单个微服务应用来说的,分布式锁是针对于多个集群微服务之间竞争而言的。
单节点多线程处理方式是JDK自带的synchronize。但是JDK的锁只能针对单个节点,针对集群的多节点就需要分布式锁,分布式锁可以实现同一时刻只有一个节点访问。
注册中心:
eurekeka,consul,zk
nacos与eureka
nacos同时支持AP与CP,eureka只支持AP。nacos提供了控制页面图形操作,eureka只支持API。nacos可以通过http,sql,tcp方式检查。eureka只支持http心跳。
1、配置中心里的是系统启动需要的参数和依赖的各类外部信息,比如spring boot里的配置项,一般情况都是。这种信息我们一般用key-value来存取,也可以做成是一个有层次结构的key-value。配置中心一般用来控制系统的启动,运行时的部分参数的调整,比如线程数之类的。这些数据的特点是,一般情况下变化不大,但是需要考虑不同环境(有时也叫组)的隔离性,就是说同时需要考虑存在很多套不同的配置,不同环境的系统通过这样的一个配置中心来去拉取自己的参数。这一块基本上常见的apollo、zk、etcd、nacos都支持的很好。
3、注册中心,是动态数据,这些数据在开发情况是不存在的,通过一些实例的启动停止,而产生和变动。比如一个新节点加入到了系统,或者有一个新的client订阅了所有的服务变动,可以通过某个服务查找所有在线的实例。这一块除了前面说的zk、etc、nacos、etcd之外,还可以用redis、consul、eruka之类的技术实现。
Redis单线程事务安全:redis虽然是单线程的,能够保证命令的顺序执行,但由于效率很高,多个客户端命令之间不做好请求同步同样会造成顺序错乱。
协程:为了解决。一是系统线程会占用非常多的内存空间,二是过多的线程切换会占用大量的系统时间。协程运行在线程之上,当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上。协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。
sql 的 if else语句,可以同时查多张表,并不是使用,只是为了使用这些表的数值,这些表必须起别名
select case
when c1 > c2 then 'New York University'
when c2 > c1 then 'California University'
else 'No Winner' end Winner
from
(select sum(score>=90) c1 from newyork) t1,
(select sum(score>=90) c2 from California) t2
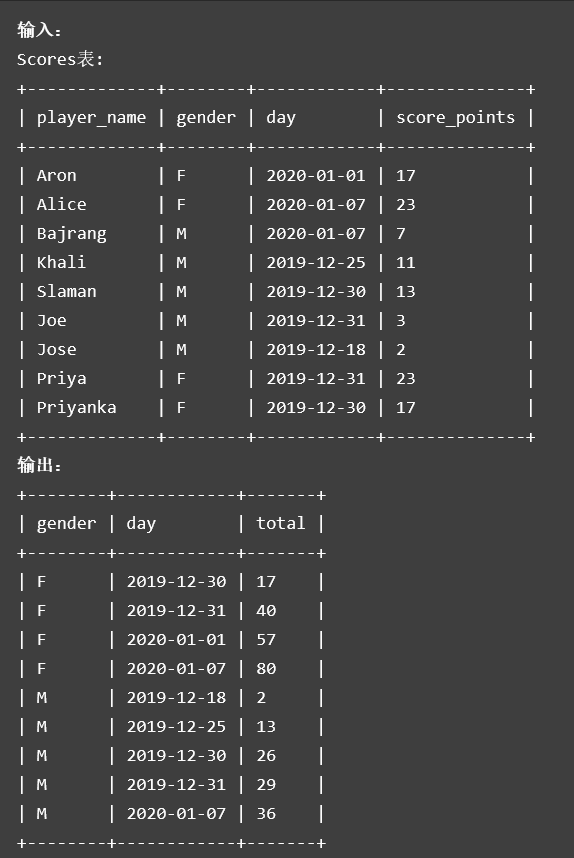
窗口函数,按照需求划分组
select gender, day,
sum(score_points) over(partition by gender order by day) total
from scores
order by gender,day
(a,b,c) in select min可以实现条件最小化查找
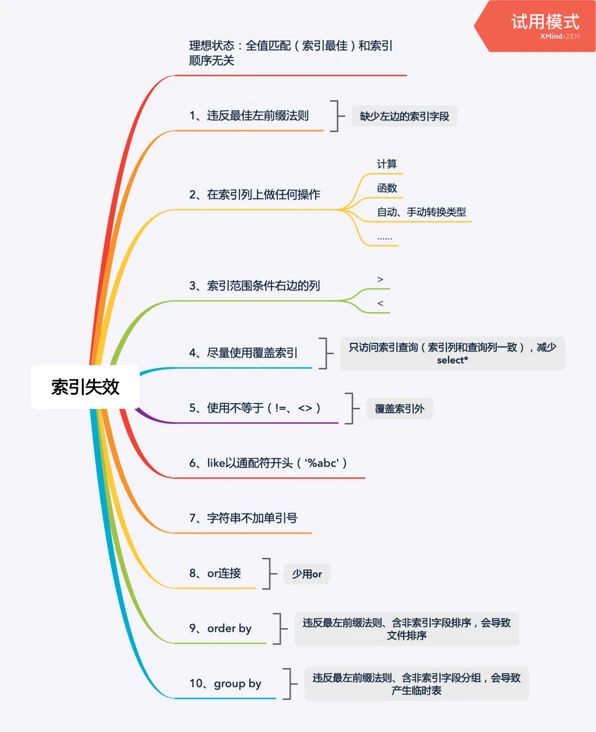
最左匹配。mysql有查询优化器
比如索引(a,b,c) 查询b=,a=可以用上
查询 a=,c=可以用到索引a,查询b=,c=就不行,越往左越重要

b+树第一个字段绝对有序,第二个字段局部有序(比如第一个字段都是1,第二个字段递增),所以查找的时候只有前一个字段是=后一个用范围才可以使用二分(=时是局部有序的)
进程通信

where,group by,having
where years_of_exp >= 2
group by candidate_id
having sum(score) > 15
CASE WHEN
select e.*,
case
when operator = '<' and v1.value < v2.value then 'true'
when operator = '=' and v1.value = v2.value then 'true'
when operator = '>' and v1.value > v2.value then 'true'
else 'false'
end value
from Expressions e
left join Variables v1
on e.left_operand = v1.name
left join Variables v2
on e.right_operand = v2.name
set里放list可以不用变字符串会自动判断去重
配置中心
配置中心可以认为是一个服务器,开发人员可以通过界面去操作配置。
服务获取获取配置有两种方式push和pull从服务端去获取。push是客户端主动去拉,好处是如果网络出现问题了多试几次可以保证收到,pull的好处是实时性强,但是网络出问题了不一定能到服务端。实际可以采取定期拉取与配置更新推送的方式。并且客户端可以在本地缓存配置,即使服务端挂了也可以读取到。
rdb执行的是全量快照,由于只是某个时刻的数据快照,所以并不全
aof是记录命令但随着时间增长会越来越多,是实时记录命令的
熔断判断依据:记录请求成功,失败,超时和线程拒绝。服务错误百分比超过了阈值,熔断器开关自动打开,一段时间内停止对该服务的所有请求。请求失败,被拒绝,超时或熔断时执行降级逻辑。
配置中心是管理配置的,比如不同的yml
定时任务原理
底层是优先队列,数据结构是小顶堆,按照到期时间差建堆,每次加入调整logn的复杂度,数据量太大了效果不好
第二种实现:

按照时间排到时间轴上,每次走到对应的时间执行时间点上的任务,如果刻度差距过大,比如刻度是秒,但是执行任务是天饶过一圈都执行不到可以加计数器,没走一圈减1,等计数器为0再执行。还有一种方式是多级时间轮,比如1min30判定是min轮走到1,s轮走到30
spring注解事务@Transactional和分布式锁不能一起使用
需求:生成岗位roleCode,这个code是唯一的,所以需要查master库,查完之后要写好几个岗位相关的库,所以加了@Transactional的注解,查重加了分布式锁,但在高并发的情况下还是会重,加了锁还是重很诡异。
这是因为@Transactional是通过方法是否抛出异常来判断事务是否回滚还是提交,此时方法已经结束。但是我们必须在方法结束之前释放锁,因此在释放锁之后,此时还没提交,由于锁已经释放,其他进程可以获得锁,并从数据库查询地点标记数,但是此时前一个进程没有提交数据。该进程查到的数据不是最新的数据,本质就是finaly里释放锁了但是没有回滚读到脏数据了。(回滚是已经生效了再回到之前的版本)
解决方法是给要查重的roleCode和valid增加唯一约束,由db来保证唯一性。还有一种方式是给调用服务的上一层加锁,但这样并发就降低了很多。
thrift是一个中间语言,把一个RPC的远程调用变成了本地调用,是一个轻量级的RPC框架,最大的好处是可以跨语言,自动生成代码。Thrift是采取bp协议,tcp/ip传输协议的一种RPC框架。因为Thrift使用的是TCP/IP协议。对于网络数据传输,TCP/IP协议的性能要高于HTTP协议,不仅因为HTTP协议是应用层协议,HTTP协议传输内容除了应用数据本身之外,还有响应状态码、Header信息等。
bp协议与文本协议的区别:
空间占用大小:bp只是01,占空间小
运算规则:bp运算规则简单
可靠性:bp可靠性高
可读性:bp可读性差
技术场景实现复杂度:通过json很容易获取到数据的场景,用bp会很麻烦
扩展性:bp协议扩展性差(对已经确定的数据解析顺序不可改变)
反向代理与正向代理
正向代理的场景比如VPN,代理的是客户端。反向代理则代理的是服务端,用户只需要知道服务端的url,具体访问哪个由nginx决定(负载均衡)
数据量大,就分表;并发高,就分库
查重要去查主库
消息队列使用
岗位下面有多个用户,更改了岗位的信息要同步改用户的信息。用户过多修改时间过长会超时,放入消息队列实现异步。
redis单实例中实现分布式锁的正确方式(原子性非常重要):
1.设置锁时,使用set命令,因为其包含了setnx,expire的功能,起到了原子操作的效果,给key设置随机值,并且只有在key不存在时才设置成功返回True,并且设置key的过期时间(最好用毫秒),要设计自己的key
SET key_name my_random_value NX PX 30000 # NX 表示if not exist 就设置并返回True,否则不设置并返回False PX 表示过期时间用毫秒级, 30000 表示这些毫秒时间后此key过期
定时任务就是写一个方法去定期的调用,还可以用来测试,比如调用测试内部方法
可以写定时任务调用,也可以写thrift接口调用
Transactional是事物要么成功要么失败,比如一个操作里有多个sql必须都成功才commit不然会滚抛异常,和分布式锁用在一起会有很多问题,考虑添加唯一索引解决。
没有throw并不是不会抛异常,throw是自定义的异常
输入一条sql后的流程
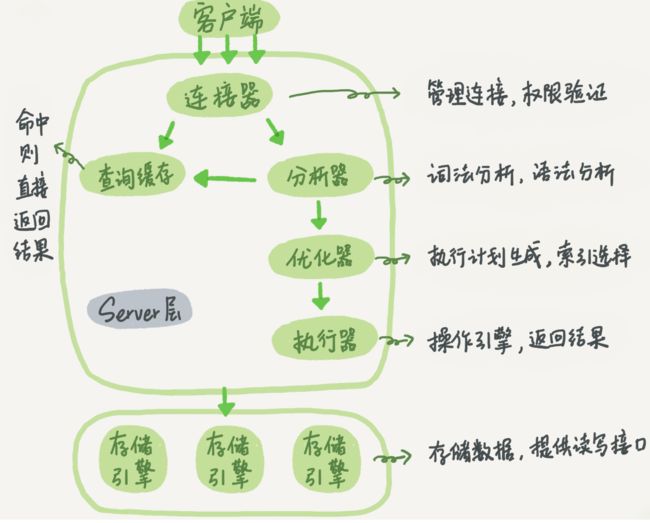
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
binlog指二进制日志,只存在于innodb中,它记录了数据库上的所有改变,并以二进制的形式保存在磁盘中,它可以用来查看数据库的变更历史、数据库增量备份和恢复、MySQL的复制
管道是用于进程交换数据的单向进程间通信通道。管道有一个读取端和一个写入端,可以从读取端读取写入端写入的数据,读取和写入通道通常是同步、阻塞的。
synchronized底层实现原理
当线程执行到monitorenter时,代表即将进入到同步语句块中,线程首先需要去获得Object的对象锁,而对象锁处于每个java对象的对象头中,对象头中会有一个锁的计数器,当线程查询对象头中计数器,发现内容为0时,则代表该对象没有被任何线程所占有,此时该线程可以占有此对象,计数器于是加1。
线程占有该对象后,也就是拿到该对象的锁,可以执行同步语句块里面的方法。此时,如果有其他线程进来,查询对象头发现计数器不为0,于是进入该对象的锁等待队列中,一直阻塞到计数器为0时,方可继续执行。
第一个线程执行到enterexit后,释放了Object的对象锁,此时第二个线程可以继续执行。
[1]为什么有一个monitorenter指令,却有两个monitorexit指令?
因为编译器必须保证,无论同步代码块中的代码以何种方式结束(正常 return 或者异常退出),代码中每次调用 monitorenter 必须执行对应的 monitorexit 指令。为了保证这一点,编译器会自动生成一个异常处理器,这个异常处理器的目的就是为了同步代码块抛出异常时能执行 monitorexit。这也是字节码中,只有一个 monitorenter 却有两个 monitorexit 的原因。
java8新特性有:1、Lambda表达式;2、方法引用;3、默认方法;4、新编译工具;5、Stream API;6、Date Time API;7、Option;8、Nashorn javascript引擎。
乐观锁:指的是在操作数据的时候非常乐观,乐观地认为别人不会同时修改数据,因此乐观锁默认是不会上锁的,只有在执行更新的时候才会去判断在此期间别人是否修改了数据,如果别人修改了数据则放弃操作,否则执行操作。
注解本质是一个继承了Annotation的特殊接口
如果目标对象实现了接口,默认情况下是采用JDK动态实现AOP(反射)
如果目标对象没有实现接口,必须采用CGLIB库.
Java 开发中,在使用注解时,一不小心把注解写到了 private方法上,编译既不报错也不会有任何提示,默认忽略,实际功能却不会生效。原因在于,spring AOP无法实现或者继承private方法