论文阅读笔记---《TransferNet: An Effective and Transparent Framework for Multi-hop Question Answering over》
Abstract
多跳问答 (QA) 是一项具有挑战性的任务,因为它需要在获得答案的每一步都对实体关系进行精确推理。这些关系可以用知识图谱中的标签(例如,配偶)或文本语料库中的文本(例如,他们已经结婚 26 年)来表示。现有模型通常通过预测顺序关系路径或聚合隐藏图特征来推断答案。前者难以优化,后者缺乏可解释性。在本文中,我们提出了 TransferNet,这是一种有效且透明的多跳 QA 模型,它在统一的框架中支持标签和文本关系。 TransferNet 在多个步骤中跨越实体。在每一步,它都会处理问题的不同部分,计算关系的激活分数,然后以可微分的方式将先前的实体分数沿着激活的关系传递。我们对三个数据集进行了广泛的实验,并证明 TransferNet 在很大程度上超越了最先进的模型。特别是在 MetaQA 上,它在 2-hop 和 3-hop 问题中实现了 100% 的准确率。通过定性分析,我们表明 TransferNet 具有透明且可解释的中间结果。
1 Introduction
问答(QA)在人工智能中起着核心作用。它需要机器理解自由形式的问题并通过分析来自大型语料库(Rajpurkar 等人,2016;Joshi 等人,2017;Chen 等人,2017)或结构化知识库(Bordes 等人)的信息来推断答案al., 2015; Yih et al., 2015;jiang et al., 2019)。最先进的模型已被证明与人类在只需要单跳的简单问题上的表现相比较(Petrochuk 和 Zettlemoyer,2018 年;Zhang 等人,2020 年),例如,谁是微软公司的 CEO。然而,需要在多个步骤中对实体关系进行推理的多跳 QA 远未得到解决(Yang 等人,2018;Dua 等人,2019;Zhang 等人,2017;Talmor 和 Berant,2018) .
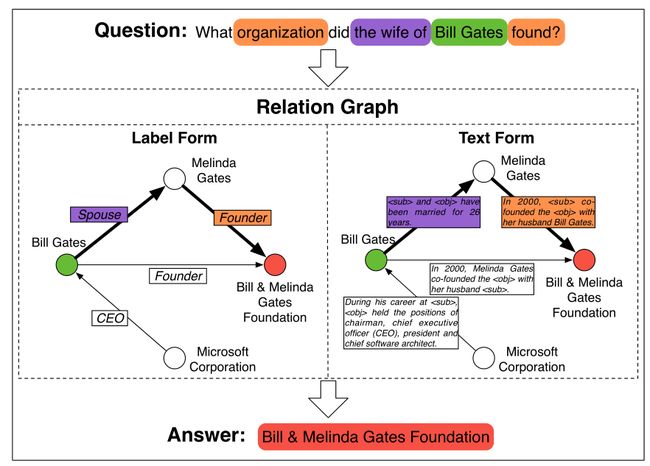
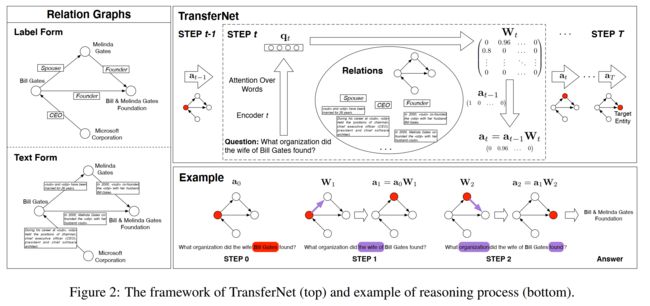
图 1:在关系图上回答多跳问题。关系是标签形式的约束谓词(即知识图),而文本形式的自由文本。推理过程已在图中标出,其中关系和疑问词之间的对应关系已以相同颜色突出显示。
在本文中,我们专注于基于关系图的多跳 QA,关系图由实体及其关系组成。如图1所示,关系可以用两种形式表示:
- 标签形式,也称为知识图谱(例如,Freebase (Bollacker et al., 2008)、Wikidata (Vrandeˇci´c and Krötzsch, 2014)),其关系是手动定义的约束谓词(例如,配偶、CEO)。
- 文本形式,其关系是从文本语料库中检索的自由文本。我们可以通过提取两个实体的同时出现的句子来轻松地构建图。由于标签形式昂贵且通常不完整,因此文本形式更经济实用。
在本文中,我们的目标是在一个统一的框架中解决这两种不同形式的多跳问题。
现有的多跳 QA 方法有两个主要方面。首先是在弱监督设置中预测顺序关系路径(Zhang et al., 2017; Qiu et al., 2020),即仅根据最终答案学习中间路径。由于巨大的搜索空间导致收敛问题,这严重阻碍了它们的性能。此外,它们主要用于标签形式。因此,尚不清楚如何使它们适应文本形式,其搜索空间更大。第二条是使用图神经网络收集证据(Sun et al., 2018, 2019)。他们可以处理这两种关系形式并实现最先进的性能。尽管它们在性能上优于基于路径的模型,但它们的可解释性很弱,因为它们的中间推理过程是黑盒神经网络层。
在本文中,我们提出了一种新的多跳 QA 模型,称为 TransferNet,它具有以下优点:1)通用性。它可以在一个统一的框架中处理标签形式、文本形式以及它们的组合。 2) 有效性。 TransferNet 显着优于以前的模型,在 MetaQA 数据集中实现了 2-hop 和 3-hop 问题的 100% 准确率。 3) 透明度。 TransferNet 完全基于注意力,因此其中间步骤可以很容易地被人类可视化和理解。
具体来说,TransferNet 通过沿多个步骤的关系分数传输实体分数来推断答案。它从问题的主题实体开始,并维护一个实体得分向量,其元素表示一个实体被激活的概率。在每一步,它都会处理一些疑问词(例如,妻子)并计算图中关系的分数。与疑问词相关的关系将获得高分(例如,配偶)。我们将这些关系分数公式化为一个相邻矩阵,其中每个条目表示实体对的转移概率。通过将实体得分向量与关系得分矩阵相乘,我们可以以可微分的方式沿着关系“跳跃”。重复多个步骤后,我们终于可以到达目标实体。
我们分别对这两种形式进行了实验。对于标签形式,我们使用 MetaQA (Zhang et al., 2017)、WebQSP (Yih et al., 2016) 和 CompWebQ (Talmor and Berant, 2018)。 TransferNet 在 MetaQA 的 2-hop 和 3-hop 问题中实现了 100% 的准确率。在 WebQSP 和 CompWebQ 上,我们也实现了对最先进模型的显着改进。对于文本形式,遵循 (Sun et al., 2019),我们从 WikiMovies 语料库 (Miller et al., 2016) 构建 MetaQA 的关系图。我们证明了 TransferNet 大大超过了以前的模型,特别是对于 2-hop 和 3-hop 问题。当我们将标签形式和文本形式混合在一起时,TransferNet 仍然保持着它的优势。此外,通过可视化中间结果,我们展示了其强大的可解释性。
2 Related Work
在本文中,我们专注于基于知识图或从文本语料库构建的图结构上的多跳问答。在之前的工作中,GraftNet (Sun et al., 2018) 和 PullNet (Sun et al., 2019) 与我们的设置相似,但它们主要针对混合形式,包括标签关系和文本关系。他们首先检索特定问题的子图,然后使用图卷积网络(Kipf 和 Welling,2016)隐式推断答案实体。这些基于 GCN 的方法通常在可解释性上很弱,因为它们不能产生中间推理路径,我们认为这对于多跳问答任务是必要的。此外,还有很多作品专门针对一种图表形式:
对于标签形式,也称为“KBQA”或“KGQA”,现有方法分为两类:信息检索(Miller et al., 2016; Xu et al., 2019; Zhao et al., 2019b; Saxena等人,2020)和语义解析(Berant 等人,2013;Yih 等人,2015;Liang 等人,2017;Guo 等人,2018;Saha 等人,2019)。前者通过学习问题和图的表示从 KG 中检索答案,而后者通过将问题解析为逻辑形式来查询答案。在这些方法中,VRN (Zhang et al., 2017) 和 SRN (Qiu et al., 2020) 具有良好的可解释性,因为它们通过强化学习学习了明确的推理路径。然而,由于巨大的搜索空间,它们存在收敛性问题。 IRN (Zhou et al., 2018) 和 ReifKB (Cohen et al., 2020) 学习了中间关系的软分布,并且可以仅使用最终答案进行优化。但是,不清楚如何将它们扩展到文本形式.
基于文本语料库的问答也称为“阅读理解”。对于可以直接从文本中检索答案的简单问题,预训练模型(Devlin 等人,2018 年;Lan 等人,2019 年)的表现优于人类(Zhang 等人,2020 年)。对于更具挑战性的多跳问题,现有的工作(Ding et al., 2019; Fang et al., 2019; Tu et al., 2020; Zhao et al., 2019a)通常将文本转换为基于规则或基于学习的实体图,然后使用图神经网络 (Kipf and Welling, 2016) 进行隐式推理。与 PullNet 类似,它们的可解释性很弱。此外,它们中的大多数仅通过连接相关实体来构建图,而缺少重要的边缘文本信息。
3 Methodology
3.1 Preliminary
我们在关系图上进行多跳推理,将实体作为节点,将实体之间的关系作为边。关系可以是不同的形式,特别是受约束的标签或自由文本。前者也称为结构化知识图(例如,Wikidata (Vrandeˇci´c and Krötzsch, 2014)),它预先定义了一组谓词来表示实体关系。后者可以很容易地根据实体对的共现从大规模文档语料库中提取出来。图1显示了这两种形式的示例。在本文中我们将它们分别称为标签形式和文本形式,并使用混合形式来表示由标签和文本组成的关系图。
我们将关系图表示为 G,其实体表示为 E,其边表示为 R。设 n 表示实体的数量,则 R 是一个 n × n 矩阵,其元素 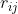 表示头部实体 ei 和尾部之间的关系实体 ej。 可以是一组标签(用于标签形式)或文本(用于文本形式)或两者(用于混合形式)。多跳问题 q 通常从主题实体
表示头部实体 ei 和尾部之间的关系实体 ej。 可以是一组标签(用于标签形式)或文本(用于文本形式)或两者(用于混合形式)。多跳问题 q 通常从主题实体 ![]() 开始,需要遍历关系才能到达答案实体 Y = {ey1, · · · , ey|Y |}。
开始,需要遍历关系才能到达答案实体 Y = {ey1, · · · , ey|Y |}。
3.2 TransferNet
为了推断多跳问题的答案,TransferNet 从主题实体开始并跳转 T 步。在每一步,它都会关注问题的不同部分以确定最合适的关系。 TransferNet 为每个实体维护一个分数来表示它们的激活概率,主题实体初始化为 1,其他实体初始化为 0。在每一步,TransferNet 为每个关系计算一个分数,以表示它们在当前查询方面的激活概率,然后在这些激活的关系之间传输实体分数。图 2 显示了框架。
形式上,我们将步骤 t 的实体分数表示为 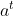 ∈
∈ ![]() 处的行向量,其中 [0, 1] 表示 0 到 1 之间的实数。
处的行向量,其中 [0, 1] 表示 0 到 1 之间的实数。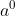 是初始分数,即只有主题实体
是初始分数,即只有主题实体![]() 得到 1。在步骤 t,我们关注问题的一部分以获得查询向量
得到 1。在步骤 t,我们关注问题的一部分以获得查询向量![]() ∈
∈ 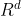 ,其中 d 是隐藏维度。
,其中 d 是隐藏维度。
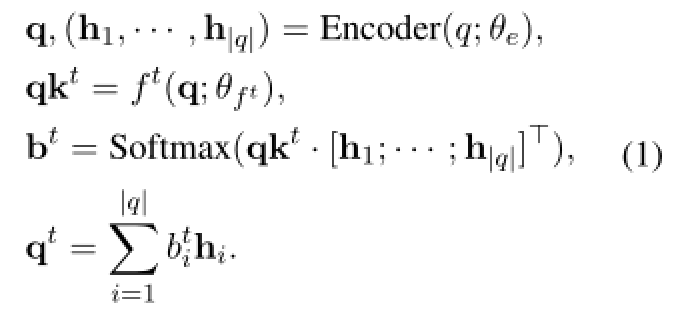
q 表示问题嵌入。 ![]() 是步骤 t 的投影函数,它将 q 映射到特定的查询键
是步骤 t 的投影函数,它将 q 映射到特定的查询键 ![]() 。
。 ![]() 是基于每个单词的隐藏向量 hi 计算分数的注意力键。 qt 是 hi 的加权和。
是基于每个单词的隐藏向量 hi 计算分数的注意力键。 qt 是 hi 的加权和。
根据 qt TransferNet 计算关系分数 Wt ∈ ![]()
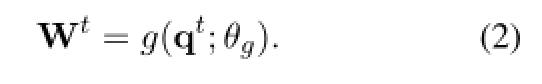
![]() 表示可学习的参数。对于标签形式和文本形式,我们将有不同的 g 实现,这将在 Sec.3.5 中介绍。
表示可学习的参数。对于标签形式和文本形式,我们将有不同的 g 实现,这将在 Sec.3.5 中介绍。
然后我们可以将“跨边跳跃”模拟为以下公式:
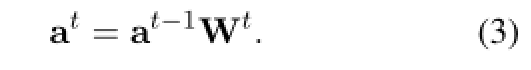
具体来说,我们有
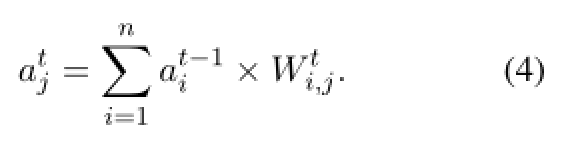
这意味着实体 的先前分数和边缘
的先前分数和边缘 的当前分数的产生将被收集到
的当前分数的产生将被收集到![]() 的当前分数中。
的当前分数中。
重复T次后,我们得到每一步的实体分数a1,a2,···,aT。然后我们计算它们的加权和作为最终输出:
 其中c ∈ [0, 1]T表示问题跳的概率分布,ct是跳数t的概率值。我们可以通过自动确定其跳数来回答从 1 跳到 T 跳的所有问题。 a∗ 中得分最高的实体作为答案输出。
其中c ∈ [0, 1]T表示问题跳的概率分布,ct是跳数t的概率值。我们可以通过自动确定其跳数来回答从 1 跳到 T 跳的所有问题。 a∗ 中得分最高的实体作为答案输出。
TransferNet 是一个高度透明的模型。如图 2 的示例所示,我们可以通过在每个步骤中可视化激活的单词、关系和实体来轻松跟踪模型行为(更多示例请参见第 5.4 节)
3.3 Training
给定黄金答案集 Y = {ey1, · · · , ey|Y |},我们通过以下方式构造目标得分向量 y ∈ {0, 1}n
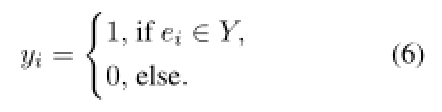
然后我们将 a* 和 y 之间的 L2 欧几里得距离作为我们的训练目标:
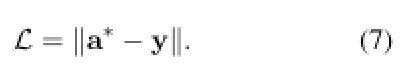
请注意,TransferNet 是完全可微的,因此我们可以通过这个简单的目标学习所有中间分数(即问题注意力、关系分数和每一步的实体分数)。
3.4 Additional Modules
我们提出了两个模块来促进 TransferNet 的学习。
分数截断。根据等式 4,atj 在转移步骤后可能超过 1。太大的分数会对梯度计算产生不好的影响。特别是当跳数增加时,可能会导致梯度爆炸。此外,如果最终得分具有无限值,我们的损失函数公式 7 将失败。所以我们需要在每一步转移后对实体分数进行修正,以确保取值范围在 [0, 1] 内。同时,我们需要保持运算的可微性。我们提出了这样一个截断函数:

在每个传输步骤之后,我们通过将此函数应用于其每个元素来截断 at。
语言掩码。 TranferNet 不考虑问题的语言偏见,其中可能包含一些对其答案的提示。例如,在文本形式的关系图中,我们可能有(哈利波特, 出版于
为了解决这个问题,我们提出了一个语言掩码来合并问题提示。我们使用问题嵌入预测每个实体的掩码分数:
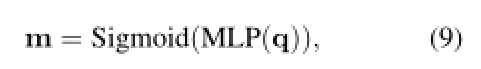
其中 m ∈ ![]() ,mi 表示实体 ei 的掩码分数,MLP(多层感知器的缩写)将 d 维特征投影到 n 维。我们将掩码乘以最终的实体分数,
,mi 表示实体 ei 的掩码分数,MLP(多层感知器的缩写)将 d 维特征投影到 n 维。我们将掩码乘以最终的实体分数,
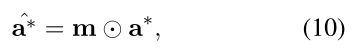
 表示逐元素乘法。目标函数方程 7 中的 a* 应替换为
表示逐元素乘法。目标函数方程 7 中的 a* 应替换为 ![]() 。注意我们只需要文本形式的语言掩码,因为标签形式的谓词没有歧义。
。注意我们只需要文本形式的语言掩码,因为标签形式的谓词没有歧义。
3.5 Relation Score Computation(3.5 关系分数计算)
考虑方程 2,Wt = g(qt; θg),我们为不同的关系形式设计不同的 g 实现。
3.5.1 Label Form
在标签形式中,关系用一个固定的谓词集 P 表示。我们首先根据 qt 计算这些谓词的概率,然后收集 ri,j 的相应概率为 ![]() 。
。
形式上,谓词分布由下式计算
![]()
如果谓词不互斥,即同时激活多个谓词,则可以将 Softmax 函数替换为 Sigmoid。令 b 表示一对实体之间的最大关系数,那么我们可以将关系表示为 = {![]() ,····,
,····, ![]() },其中
},其中 ![]() ∈ {1, 2,····,|P|}。谓词概率是根据关系标签收集的:
∈ {1, 2,····,|P|}。谓词概率是根据关系标签收集的:
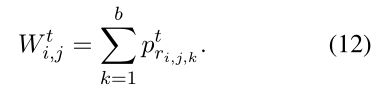
我们通过汇总来收集概率。max 是另一个可行的选择,但我们发现  更有效且更稳定。
更有效且更稳定。
3.5.2 Text Form
在文本形式中,关系用自然语言描述来表示。该图是通过提取一对实体的共现句子并用特殊占位符替换实体来构建的。例如,Bill Gates 和 Melinda Gates 已结婚 26 年这句话从 Bill Gates 到 Melinda Gates 贡献了一条边,其关系文本 is and have been mapped for 26,如图 2 所示。我们可以得到反向关系通过交换主客体的占位符,但为了简单起见,我们没有在图中显示它们。
在文本形式中,关系用自然语言描述来表示。该图是通过提取一对实体的共现句子并用特殊占位符替换实体来构建的。例如,Bill Gates 和 Melinda Gates 已结婚 26 年这句话从 Bill Gates 到 Melinda Gates 贡献了一条边,其关系文本 is and have been mapped for 26,如图 2 所示。我们可以得到反向关系通过交换主客体的占位符,但为了简单起见,我们没有在图中显示它们。
令 = {![]() ,···,
,···,![]() },
},![]() 表示第k 个关系句。我们使用关系编码器来获得关系嵌入,然后通过以下方式计算关系分数
表示第k 个关系句。我们使用关系编码器来获得关系嵌入,然后通过以下方式计算关系分数

表示逐元素乘积,MLP 将特征从 d 维映射到 1 维。
由于关系图中有大量(通常是数百万)关系文本,因此不可能计算所有这些文本的嵌入和分数。所以在实践中,我们在每一步选择关系的一个子集。具体来说,在步骤 t,我们选择先前在-1i 处的分数大于预定义阈值 τ 的实体,并且只考虑从这些实体开始的关系。此外,如果满足此条件的关系太多,我们将只保留其中的 top ω,并根据它们的主题实体得分进行排序。通过这样做,我们只需要在每一步中最多考虑 ω 关系。
我们使用相同的方法来处理混合形式,将标签谓词简单地视为一个单词的句子。
4 Experiments
4.1 Datasets
MetaQA(Zhang et al.,2017)是一个基于知识图的大规模多跳问答数据集,它将WikiMovies(Miller et al.,2016)从单跳扩展到多跳。它包含超过40万个问题,这些问题使用数十个模板生成,最多有3个跳跃。它的知识图来自电影领域,包括43k个实体、9个谓词和135k个三元组。
除了标签形式之外,我们还通过提取 WikiMovies (Miller et al., 2016) 的文本语料库构建了 MetaQA 的文本形式,该语料库引入了带有自由文本的电影信息。以下 (Sun et al., 2019),我们使用表面形式的精确匹配进行实体识别和链接。给定电影的一篇文章,我们将电影作为主题,将其他相关实体(例如,提到的演员、年份等)作为对象。句子用占位符处理,即用(如果出现)替换电影,用
4.2 Baselines(个人感觉不太重要)
4.3 Implementations
我们在关系图中添加了反向关系,导致谓词和三元组的大小加倍。对于文本表单,我们将占位符 和
对于 MetaQA 的实验,我们设置步数 T = 3。我们使用双向 GRU (Chung et al., 2014) 作为问题编码器,并设置隐藏维度为 1024。投影函数 ft 是一个堆栈线性层和 Tanh 层。所涉及的 MLP 被实现为简单的线性层。对于文本形式,我们使用另一个双向 GRU 作为关系编码器。阈值 τ 设置为 0.7,ω 设置为 400。由于 MetaQA 中提供了问题跳数,因此我们使用黄金跳数作为辅助目标帮助学习跳跃分布 c.我们计算了交叉熵损失,并在乘以 0.01 后将其添加到公式 7 中。该模型使用 RAdam (Liu et al., 2020) 进行了优化,20 个 epoch 的学习率为 0.001,在 NVIDIA 1080Ti 的单个 GPU 上,标签表单需要几个小时,而文本表单需要大约一天时间。
对于 WebQSP 和 CompWebQ 的实验,我们设置步数 T = 2。我们使用预训练的 BERT (Devlin et al., 2018) 作为问题编码器,并在我们的任务中微调其参数。没有跳跃注释,所以我们没有使用辅助损失。其他设置与 MetaQA 相同。
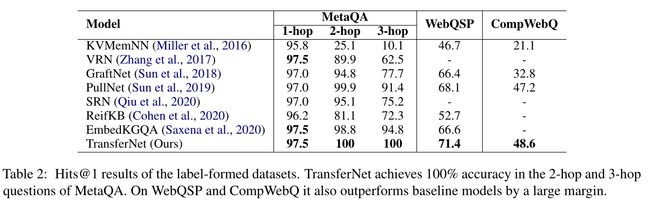
表 2:标签形成数据集的 Hits@1 结果。 TransferNet 在 MetaQA 的 2-hop 和 3-hop 问题中实现了 100% 的准确率。在 WebQSP 和 CompWebQ 上,它也大大优于基线模型。
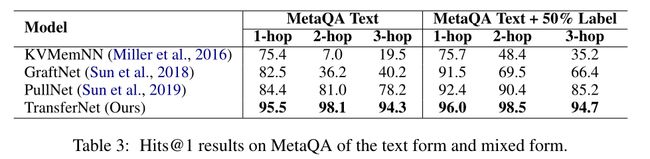
表 3:文本形式和混合形式的 MetaQA 上的 Hits@1 结果。
5 Results
5.1 Results on Label-Formed Graph
表 2 比较了标签形成数据集上的不同模型。 TransferNet 在 MetaQA 的 2-hop 和 3-hop 问题上表现完美,即达到 100% 的准确率。对于 MetaQA 的 1 跳问题,TransferNet 达到了 97.5%,与之前的模型如 VRN 和 EmbedKGQA 相当。我们分析了 1-hop 的错误情况,发现错误是由实体的歧义引起的。例如,谁在《最后的莫西干人》中扮演角色的问题是问电影《最后的莫西干人》的演员。在知识图中,有两部电影同名,一部于 1936 年上映,另一部于 1920 年上映。我们的模型输出两部电影的演员,而 MetaQA 数据集仅将 1920 年的演员视为黄金答案,导致不可避免的不匹配。以前的工作的表现也应该受到这个数据集错误的影响。在 2-hop 和 3-hop 的问题中,歧义大多通过关系限制来消除。因此,TransferNet 可以达到 100% 的准确率。可以说,我们的 TransferNet 几乎解决了标签形成的 MetaQA 数据集。
WebQSP 比 MetaQA 更具挑战性,因为它有更多的谓词和三元组,但训练示例却少得多。 TransferNet 达到了 71.4% 的准确率,大大超过了之前最先进的模型(68.1%),这意味着它非常适合大规模的知识库。
在 CompWebQ 数据集上,我们将结果与 Sun 等人进行了比较。 (2019)在开发集上。 TransferNet 达到了 48.6% 的准确率,仍然优于 PullNet (47.2%)。
5.2 Results on Text-Formed Graph
在表 2 中,我们将 TransferNet 与能够处理文本形式关系的最先进模型进行了比较。我们可以看到 TransferNet 明显优于以前的模型。特别是对于 2-hop 和 3-hop 的问题,我们分别将准确率从 81.0% 提高到 98.1% 和从 78.2% 提高到 94.3%。 PullNet 和 GraftNet 都通过隐式聚合图特征来推断答案,因此无法提供中间关系路径。与它们相比,TransferNet 不仅性能优越,而且具有更好的可解释性(见 Sec.5.4)。
除了纯文本形式,我们还比较了以下混合形式(Sun et al., 2018, 2019)。也就是说,随机选择 50% 的标签形式的三元组并将它们添加到文本形式的关系图中。在这种情况下,我们简单地将谓词视为仅包含一个单词的句子,并使用关系编码器(参见第 3.5.2 节)来处理它们。这 50% 的标签比纯文本形式稍微提高了 TransferNet 的性能(大约 0.4%),因为文本语料库中缺少一些关系。与 PullNet 相比,TransferNet 仍以较大的差距领先(85.2% vs.94.7%)。
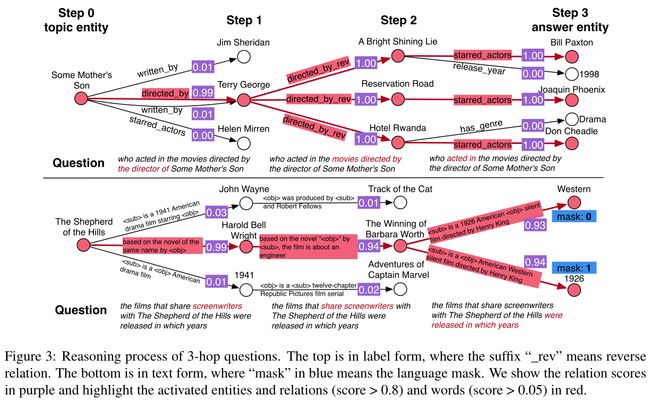
图 3:3 跳问题的推理过程。顶部为标签形式,其中后缀“_rev”表示反向关系。底部是文本形式,其中蓝色的“掩码”表示语言掩码。我们以紫色显示关系分数,并以红色突出显示激活的实体和关系(分数 > 0.8)和单词(分数 > 0.05)。
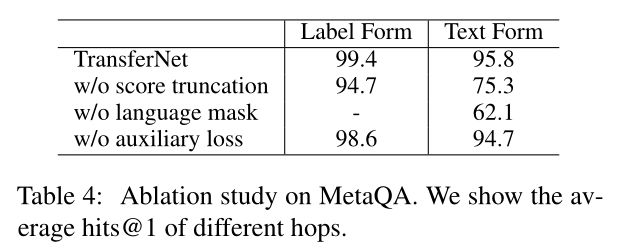
表 4:MetaQA 的消融研究。我们展示了不同跃点的平均 hits@1。
5.3 Ablation Study
表4显示了消融研究的结果。我们可以看到分数截断和语言掩码都很重要,尤其是对于文本形式。如第二节所述。 3.4、标签表单中不需要语言掩码。辅助损失(参见第 4.3 节)略微提高了性能,因为它有助于学习 hop attention。
5.4 Interpretability
我们在图 3 中可视化了两个 3 跳问题的 TransferNet 的中间结果。分数大于 0.8 的实体和关系以红色突出显示。最重要的问题是针对标签形成的关系图。三跳的激活谓词分别为directed_by、directed_by_rev和starred_actors,其中后缀_rev表示反向关系。下面的问题针对的是文本形式。在第1步,TransferNet试图找到主题电影的编剧,并激活文字描述为“根据同名小说改编”的关系。在第 2 步,找到了 Harold Bell Wright 编写的电影。在第 3 步,我们的目标是找到电影的发行年份。但由于西部(这是电影的类型)和 1926 的文字描述非常相似,这两个实体都被激活了。在这里,建议的语言掩码成功地过滤掉了错误的答案。
5.5 Model Efficiency
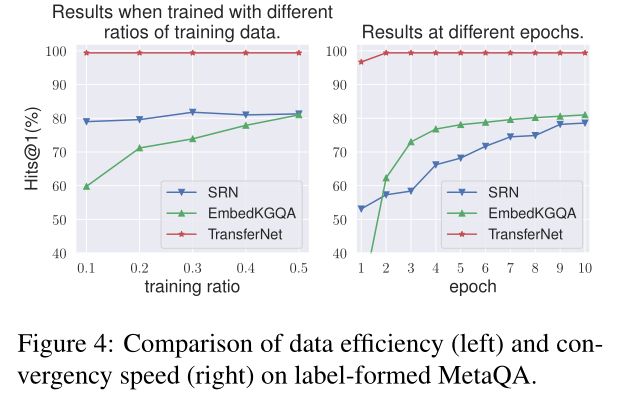
图4:标签形成的MetaQA上数据效率(左)和收敛速度(右)的比较。
图4显示了平均值hits@1在MetaQA的标签形式上,使用部分训练示例(左)和不同时期(右)训练模型。我们可以看到,TransferNet的数据效率非常高,收敛速度非常快。仅使用10%的训练数据,它仍能达到与整个训练集相同的性能。它只需要两个阶段就可以达到最佳结果。
6 Conclusions
我们提出了TransferNet,这是一种有效且透明的知识图或文本关系图多跳QA框架。它在标签形成的MetaQA的2-hop和3-hop问题上达到了100%的准确率,几乎解决了数据集。在更具挑战性的WebQSP、CompWebQ和text-formed-MetaQA上,它也显著优于其他最先进的模型。定性分析表明,TransferNet具有良好的可解释性。
原文链接:https://arxiv.org/abs/2104.07302