Neo4j【有与无】【N4】构建图形数据库应用程序
目录
1.数据建模
1.1.根据应用程序的需求描述模型
1.2.事物的节点,结构的关系(Nodes for Things, Relationships for Structure)
1.3.精细关系与一般关系(Fine-Grained versus Generic Relationships)
1.4.将事实建模为节点(Model Facts as Nodes)
1.4.1.Employment
1.4.2.Performance
1.4.3.Emailing
1.4.4.Reviewing
1.5.将复杂值类型表示为节点
1.6.时间(Time)
1.6.1.时间轴树(Timeline trees)
1.6.2.Linked lists
1.6.3.版本控制(Versioning)
1.7.迭代和增量开发
2.应用架构
2.1.嵌入式与服务器(Embedded versus Server)
2.1.1.嵌入式Neo4j
2.1.2.服务器模式
2.1.3.服务器扩展
2.2.聚类
2.2.1.复制
2.2.2.使用队列进行缓冲区写
2.2.3.全球集群
2.3.负载均衡
2.3.1.将读取流量与写入流量分开
2.3.2.缓存分片
2.4.阅读自己的文章
3.测试(Testing)
3.1.测试驱动的数据模型开发
3.1.1.示例:测试驱动的社交网络数据模型
3.1.2.测试服务器扩展
3.2.性能测试
3.2.1.查询性能测试
3.2.2.应用程序性能测试
3.2.3.使用代表性数据进行测试
4.容量规划(Capacity Planning)
4.1.优化标准
4.2.性能
4.2.1.计算图形数据库性能的成本
4.2.2.性能优化选项
4.3.冗余
4.4.负载
5.导入和批量加载数据
5.1.初始导入
5.2.批量导入
6.摘要
在本章中,我们讨论使用图形数据库的一些实际问题。 在前面的章节中,我们研究了图形数据; 在本章中,我们将在开发图形数据库应用程序的背景下应用这些知识。 我们将研究可能出现的一些数据建模问题,以及可供我们使用的一些应用程序体系结构选择。
根据我们的经验,图数据库应用程序非常适合使用当今广泛使用的渐进式,增量式和迭代式软件开发实践进行开发。 这些实践的主要特征是在整个软件开发生命周期中普遍进行测试。 在这里,我们将展示如何以测试驱动的方式开发数据模型和应用程序。
在本章的最后,我们将探讨在计划生产时需要考虑的一些问题。
1.数据建模
在第3章中,我们详细介绍了建模和使用图数据的方法。在这里,我们总结了一些更重要的建模准则,并讨论了实现图数据模型如何与迭代和增量软件开发技术相适应的方法。
1.1.根据应用程序的需求描述模型
我们需要对数据提出的问题有助于识别实体和关系。 敏捷的用户故事提供了一种简洁的方法,用于表达从外到内,以用户为中心的应用程序需求视图,以及在满足此需求过程中出现的问题。 这是一个有关书评网络应用程序的用户故事的示例:
作为喜欢一本书的读者,我想知道其他喜欢同一本书的读者喜欢哪本书,因此我可以找到其他书籍。
AS A reader who likes a book, I WANT to know which books other readers who like the same book have liked, SO THAT I can find other books to read.
这个故事表达了用户需求,激发了我们数据模型的形状和内容。从数据建模的角度来看,“ AS A”子句建立了一个包含两个实体(读者和书本)以及连接它们的LIKES关系的上下文。然后,I WANT子句提出了一个问题:喜欢我当前正在阅读的书的读者也喜欢哪些书?这个问题揭示了更多的LIKES关系,以及更多的实体:其他读者和其他书籍。
如图4-1所示,我们在分析用户的描述时,实体和关系迅速转变为简单的数据模型。
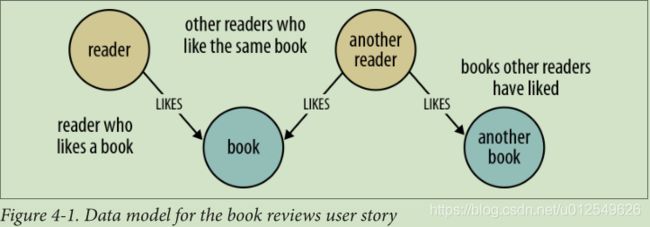
由于此数据模型直接对用户描述所提出的问题进行编码的,因此可以以类似反映我们要针对数据提出的问题的结构的方式进行查询,比如
Alice likes Dune, find books that others who like Dune have enjoyed
MATCH (:Reader {name:'Alice'})-[:LIKES]->(:Book {title:'Dune'})
<-[:LIKES]-(:Reader)-[:LIKES]->(books:Book)
RETURN books.title1.2.事物的节点,结构的关系(Nodes for Things, Relationships for Structure)
尽管并非在所有情况下都适用,但这些通用准则将帮助我们选择何时使用节点以及何时使用关系:
- 使用节点表示实体,即我们所关注的领域中可以标记和分组的事物。
- 使用关系既可以表示实体之间的连接,也可以为每个实体建立语义上下文,从而构造域。
- 使用关系方向进一步阐明关系语义。 许多关系是不对称的,这就是为什么属性图中的关系始终是有向的。 对于双向关系,我们应该使查询忽略方向,而不是使用两个关系。
- 使用节点属性表示实体属性,以及任何必要的实体元数据,例如时间戳,版本号等。
- 使用关系属性来表达关系的强度,权重或质量,以及任何必要的关系元数据,例如时间戳,版本号等。
努力发现和捕获域实体是值得的。正如我们在第3章中所看到的,使用清晰命名的关系来建模应该以节点表示的事物相对容易。如果我们想使用一种关系来为实体建模(例如,电子邮件或评论),则必须确保该实体不能与两个以上的其他实体相关。记住,一个关系必须有一个开始节点和一个结束节点,仅此而已。如果以后发现我们需要将已建模为关系的对象与其他两个以上的实体连接,则必须将关系内的实体重构为一个单独的节点。这是对数据模型的重大更改,很可能需要我们对产生或使用数据的任何查询和应用程序代码进行更改。
1.3.精细关系与一般关系(Fine-Grained versus Generic Relationships)
在设计关系时,我们应该注意在使用细粒度关系名称和具有属性的通用关系之间的权衡。 使用DELIVERY_ADDRESS和HOME_ADDRESS与 ADDRESS {type:'delivery'}和 ADDRESS {type:'home'} 之间的区别。
关系是图中的皇家之路。 通过关系名称进行区分是从遍历中消除大量图形的最好方法。 首次访问这些属性时,使用一个或多个属性值来决定是否遵循某个关系会导致额外的I/O,因为这些属性与关系位于不同的存储文件中(但是此后将对其进行缓存) 。
每当我们有一组封闭的关系名称时,我们就使用细粒度的关系。 权重(按照最短加权路径算法的要求)很少包含封闭集,通常最好用关系的属性表示。
但是,有时我们有一组封闭的关系,但是在某些遍历中,我们希望遵循该组中的特定类型的关系,而在另一些遍历中,我们希望遵循所有这些关系,而与类型无关。地址就是一个很好的例子。遵循封闭集原则,我们可能选择创建HOME_ADDRESS,WORK_ADDRESS和DELIVERY_ADDRESS关系。这使我们可以遵循特定类型的地址关系(例如DELIVERY_ADDRESS),而忽略其余所有关系。但是,如果我们要查找用户的所有地址,该怎么办?这里有两个选择。首先,我们可以对查询中所有不同关系类型的知识进行编码:例如,MATCH (user)-[:HOME_ADDRESS|WORK_ADDRESS|DELIVERY_ADDRESS]->(address)。但是,当存在许多不同类型的关系时,这很快变得难以处理。另外,除了细粒度的关系外,我们还可以向模型添加更通用的地址关系。然后,使用两种关系将表示地址的每个节点连接到用户:精细关系(例如DELIVERY_ADDRESS)和更通用的ADDRESS {type:'delivery'}关系。
正如我们在“根据应用程序的需求描述模型”中讨论的那样,关键是要让我们要问数据的问题指导我们引入模型中的各种关系。
1.4.将事实建模为节点(Model Facts as Nodes)
当两个或多个域实体互动一段时间后,就会出现一个事实。 我们将事实表示为一个单独的节点,该节点与该事实中涉及的每个实体都有连接。 根据行为的产品(即根据行为产生的事物)对行为进行建模,会产生类似的结构:表示两个或多个实体之间交互结果的中间节点。 我们可以在此中间节点上使用时间戳属性来表示开始时间和结束时间。
以下示例说明了如何使用中间节点对事实和动作进行建模。
1.4.1.Employment
图4-2显示了如何在图表中表示Ian被Neo Technology聘用为工程师的事实。
在Cypher中,这可以表示为:
CREATE (:Person {name:'Ian'})-[:EMPLOYMENT]->
(employment:Job {start_date:'2011-01-05'})
-[:EMPLOYER]->(:Company {name:'Neo'}),
(employment)-[:ROLE]->(:Role {name:'engineer'})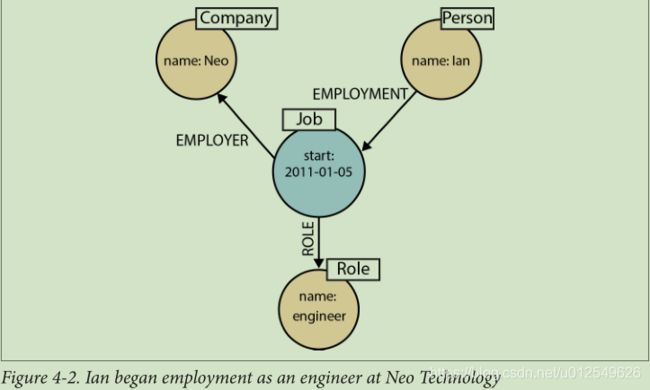
1.4.2.Performance
图4-3显示了威廉·哈特内尔(William Hartnell)在故事《Sensorites》中扮演医生(Doctor)的事实如何在图表中表示
In Cypher:
CREATE (:Actor {name:'William Hartnell'})-[:PERFORMED_IN]->
(performance:Performance {year:1964})-[:PLAYED]->
(:Role {name:'The Doctor'}),
(performance)-[:FOR]->(:Story {title:'The Sensorites'})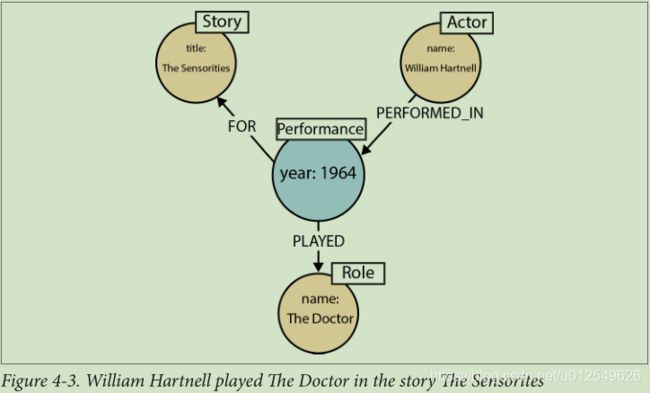
1.4.3.Emailing
图4-4显示了Ian向Jim发送电子邮件并在Alistair中复制的行为。

在Cypher中,这可以表示为:
CREATE (:Person {name:'Ian'})-[:SENT]->(e:Email {content:'...'})
-[:TO]->(:Person {name:'Jim'}),
(e)-[:CC]->(:Person {name:'Alistair'})1.4.4.Reviewing
图4-5显示了如何在图表中表示Alistair观看电影的行为。
在Cypher中,这可以表示为:
CREATE (:Person {name:'Alistair'})-[:WROTE]->
(review:Review {text:'...'})-[:OF]->(:Film {title:'...'}),
(review)-[:PUBLISHED_IN]->(:Publication {title:'...'})
1.5.将复杂值类型表示为节点
值类型是没有身份的事物,其对等仅基于其值。 示例包括资金,地址和SKU。 复杂值类型是具有多个字段或属性的值类型。 例如,地址是复数值类型。 这样的多属性值类型可以有用地表示为单独的节点:
MATCH (:Order {orderid:13567})-[:DELIVERY_ADDRESS]->(address:Address)
RETURN address.first_line, address.zipcode1.6.时间(Time)
时间可以在图中以几种不同的方式建模。 这里我们描述两种技术:时间轴树(timeline trees)和链表(linked lists)。 在某些解决方案中,将这两种技术结合起来很有用。
1.6.1.时间轴树(Timeline trees)
如果我们需要查找在特定时期内发生的所有事件,则可以构建一个时间轴树,如图4-6所示。
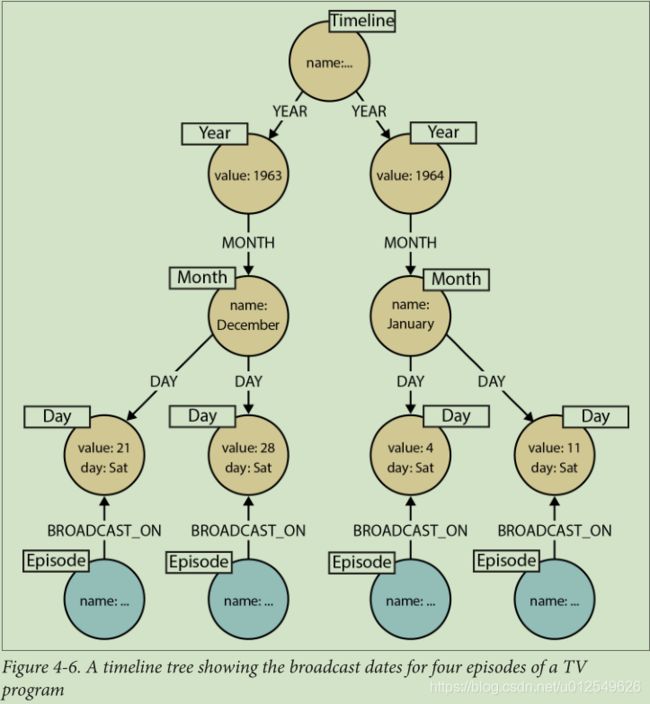
每年都有自己的月份节点集; 每个月都有自己的日节点集。我们只需要在需要时将节点插入时间轴树中即可。假设根时间轴节点已被索引或可以通过遍历图来发现,则以下Cypher语句可确保 特定事件的所有必要节点和关系(年,月,日,以及代表事件本身的节点)已经存在于图形中,或者(如果不存在)被添加至图形(MERGE将添加任何缺失的元素 ):
MATCH (timeline:Timeline {name:{timelineName}})
MERGE (episode:Episode {name:{newEpisode}})
MERGE (timeline)-[:YEAR]->(year:Year {value:{year}})
MERGE (year)-[:MONTH]->(month:Month {name:{monthName}})
MERGE (month)-[:DAY]->(day:Day {value:{day}, name:{dayName}})
MERGE (day)<-[:BROADCAST_ON]-(episode)可以使用以下Cypher代码查询日历中开始日期(包括开始日期)和结束日期(包括结束日期)之间的所有事件:
MATCH (timeline:Timeline {name:{timelineName}})
MATCH (timeline)-[:YEAR]->(year:Year)-[:MONTH]->(month:Month)-[:DAY]->
(day:Day)<-[:BROADCAST_ON]-(n)
WHERE ((year.value > {startYear} AND year.value < {endYear})
OR ({startYear} = {endYear} AND {startMonth} = {endMonth}
AND year.value = {startYear} AND month.value = {startMonth}
AND day.value >= {startDay} AND day.value < {endDay})
OR ({startYear} = {endYear} AND {startMonth} < {endMonth}
AND year.value = {startYear}
AND ((month.value = {startMonth} AND day.value >= {startDay})
OR (month.value > {startMonth} AND month.value < {endMonth})
OR (month.value = {endMonth} AND day.value < {endDay})))
OR ({startYear} < {endYear}
AND year.value = {startYear}
AND ((month.value > {startMonth})
OR (month.value = {startMonth} AND day.value >= {startDay})))
OR ({startYear} < {endYear}
AND year.value = {endYear}
AND ((month.value < {endMonth})
OR (month.value = {endMonth} AND day.value < {endDay}))))
RETURN n这里的WHERE子句虽然有些冗长,但只是根据提供给查询的开始和结束日期过滤每个匹配项。
1.6.2.Linked lists
许多事件与之前和之后的事件具有时间关系。我们可以使用NEXT和/或PREVIOUS关系(取决于我们的偏好)来创建捕获此自然顺序的链接列表,如图4-7所示。 链接列表允许快速遍历按时间顺序排列的事件。

1.6.3.版本控制(Versioning)
版本图可以使我们在特定时间点恢复图的状态。 大多数图形数据库不支持将版本控制作为一流的概念。 但是,可以在图模型内部创建版本控制方案。 使用此方案,每当修改节点和关系时,便会加上时间戳并进行归档。这种版本控制方案的缺点是,它们会泄漏到针对该图编写的任何查询中,即使最简单的查询也增加了一层复杂性。
1.7.迭代和增量开发
我们按功能开发数据模型功能,按用户描述开发用户描述。这将确保我们确定应用程序将用于查询图形的关系。根据应用程序功能的迭代和增量交付而开发的数据模型看起来与使用数据模型优先方法绘制的模型完全不同,但是它将是正确的模型,始终受应用程序需求以及与这些需求相关的问题所驱动。
图形数据库为我们的数据模型的平稳升级提供了条件。 迁移和非规范化很少成为问题。 新事实和新构成成为新的节点和关系,而对性能至关重要的访问模式进行优化通常涉及在两个节点之间引入直接关系,否则它们将仅通过中介进行连接。与我们在关系世界中采用的优化策略不同,优化策略通常涉及去规范化并因此损害高保真模型,这不是一个或非问题:详细的,高度规范化的结构或高性能的折衷。 使用该图,我们保留了原始的高保真图结构,同时又为它添加了满足新需求的新元素。
我们将很快看到,不同的关系如何彼此并存,满足不同的需求,而又不会因偏爱任何特定需求而扭曲模型。 地址有助于说明这一点。 想象一下,例如,我们正在开发零售应用程序。 在开发履行案例时,我们增加了将包裹发送到客户的收货地址的功能,可以使用以下查询找到该地址:
MATCH (user:User {id:{userId}})
MATCH (user)-[:DELIVERY_ADDRESS]->(address:Address)
RETURN address稍后,当添加一些计费功能时,我们引入了BILLING_ADDRESS关系。 稍后,我们增加了客户管理所有地址的功能。这最后一个功能要求我们查找所有地址-送货,开票还是其他地址。 为方便起见,我们引入了一般的地址关系:
MATCH (user:User {id:{userId}})
MATCH (user)-[:ADDRESS]->(address:Address)
RETURN address到此时,我们的数据模型看起来类似于图4-8所示的模型。 DELIVERY_ADDRESS代表应用程序的实现需求对数据进行专业化处理; BILLING_ADDRESS代表应用程序的计费需求专门处理数据; 而ADDRESS则代表应用程序的客户管理需求对数据进行专业化处理。

仅仅因为我们可以添加新的关系以满足新的应用程序目标,并不意味着我们总是必须这样做。 我们将一如既往地寻找重构模型的机会。 会有很多次,例如,现有关系足以满足新查询的需要,或者重命名现有关系将使它可以用于两种不同的需求。 当这些机会出现时,我们应该抓住它们。 如果我们以测试驱动的方式开发解决方案(本章稍后将详细介绍),我们将提供一套完善的回归测试套件。这些测试使我们有信心对模型进行实质性更改。
2.应用架构
在规划基于图形数据库的解决方案时,需要做出几个体系结构决策。 这些决定会因我们选择的数据库产品而略有不同。 在本节中,我们将介绍一些使用Neo4j时可用的体系结构选择以及相应的应用程序体系结构。
2.1.嵌入式与服务器(Embedded versus Server)
今天,大多数数据库都作为服务器运行,可以通过客户端库进行访问。 Neo4j有点不同寻常,因为它可以在嵌入式和服务器模式下运行,实际上,距今已有近十年的历史,它的起源是嵌入式图形数据库。
嵌入式数据库与内存数据库不同。Neo4j的嵌入式实例仍使所有数据持久存储在磁盘上。 稍后,在“测试(Testing)”中,我们将讨论Impermanent GraphDatabase,它是Neo4j的内存版本,旨在用于测试。

2.1.1.嵌入式Neo4j
在嵌入式模式下,Neo4j与我们的应用程序运行相同的过程。 嵌入式Neo4j可以是硬件设备,台式机应用程序以及整合到我们自己的应用程序服务器中的理想选择。 嵌入式模式的一些优点包括:
- 低延迟(Low latency)
- 由于我们的应用程序直接与数据库对话,因此没有网络开销。
- API的选择
- 我们可以访问用于创建和查询数据的所有API:核心API,遍历框架和Cypher查询语言。
- 显式事务
- 使用Core API,我们可以控制事务的生命周期,在单个事务的上下文中针对数据库执行任意复杂的命令序列。 Java API还公开了事务生命周期,使我们能够插入自定义事务事件处理程序,该事件处理程序对每个事务执行附加的逻辑。
但是,在嵌入式模式下运行时,我们应牢记以下几点:
- 仅JVM(Java虚拟机)
- Neo4j是基于JVM的数据库。 因此,只能从基于JVM的语言访问其许多API。
- GC行为
- 当以嵌入式模式运行时,Neo4j会受到主机应用程序的垃圾回收(GC)行为的影响。 较长的GC暂停可能会影响查询时间。此外,当将嵌入式实例作为HA(高可用性)群集的一部分运行时,较长的GC暂停可能会导致群集协议触发主服务器重选。
- 数据库生命周期
- 该应用程序负责控制数据库的生命周期,包括安全地启动和关闭它。
与服务器版本一样,嵌入式Neo4j可以集群化以实现高可用性和水平读取扩展。 实际上,我们可以运行嵌入式和服务器实例的混合集群(集群是在数据库级别而不是服务器级别执行的)。 这在企业集成方案中很常见,在该方案中,针对嵌入式实例执行来自其他系统的定期更新,然后将其复制到服务器实例中。
2.1.2.服务器模式
在服务器模式下运行Neo4j是当今部署数据库的最常用方法。 每个服务器的核心是Neo4j的嵌入式实例。 服务器模式的一些好处包括:
- REST API
- 服务器公开了丰富的REST API,该API允许客户端通过HTTP发送JSON格式的请求。 响应包括JSON格式的文档,这些文档带有丰富的超媒体链接,这些链接可以宣传数据集的其他功能。 REST API可由最终用户扩展,并支持Cypher查询的执行。
- 平台独立性
- 由于访问是通过HTTP发送的JSON格式的文档进行的,因此几乎可以在任何平台上运行的客户端都可以访问Neo4j服务器。 所需要的只是一个HTTP客户端库。
- 扩展独立性
- 通过在服务器模式下运行Neo4j,我们可以独立于应用程序服务器集群扩展数据库集群。
- 与应用程序GC行为的隔离
- 在服务器模式下,Neo4j受到保护,免受应用程序其余部分触发的任何不良GC行为的影响。 当然,Neo4j仍会产生一些垃圾,但是在开发过程中已仔细监视和调整了它对垃圾收集器的影响,以减轻任何重大的副作用。 但是,由于服务器扩展使我们能够在服务器内部运行任意Java代码(请参阅“服务器扩展”),因此使用服务器扩展可能会影响服务器的GC行为。
在服务器模式下使用Neo4j时,请记住以下几点:
- 网络开销
- 每个HTTP请求的通讯开销虽然很小,但仍然有些消耗。 在第一个客户端请求之后,TCP连接将保持打开状态,直到被客户端关闭。
- 事务状态
- Neo4j服务器具有一个事务的Cypher端点。 这允许客户端在单个事务的上下文中执行一系列Cypher语句。 对于每个请求,客户端都会延长其对事务的时间。 如果客户端由于任何原因未能完成或回滚事务,则该事务状态将保留在服务器上直到超时(默认情况下,服务器将在60秒后回收孤立的事务)。 对于需要单个事务上下文的更复杂的多步骤操作,我们应考虑使用服务器扩展(请参阅“服务器扩展”)。
如前所述,通常通过其REST API访问Neo4j服务器。REST API包括通过HTTP的JSON格式的文档。 使用REST API,我们可以提交Cypher查询,配置命名索引以及执行几种内置图形算法。 我们还可以提交JSON格式的遍历描述,并执行批处理操作。 对于大多数用例而言,REST API就足够了。 但是,如果需要执行当前无法使用REST API完成的操作,则应考虑开发服务器扩展。
2.1.3.服务器扩展
服务器扩展使我们能够在服务器内部运行Java代码。 使用服务器扩展,我们可以扩展REST API或完全替换它。
扩展采用JAX-RS注释类的形式。 JAX-RS是用于构建RESTful资源的Java API。 使用JAX-RS批注,我们装饰每个扩展类以向服务器指示其处理的HTTP请求。附加注释控制请求和响应的格式,HTTP报头,和的URI模板的格式。
这是一个简单的服务器扩展的实现,允许客户端请求社交网络中两个成员之间的距离:
@Path("/distance")
public class SocialNetworkExtension
{
private final GraphDatabaseService db;
public SocialNetworkExtension(@Context GraphDatabaseService db)
{
this.db = db;
}
@GET
@Produces("text/plain")
@Path("/{name1}/{name2}")
public String getDistance ( @PathParam("name1") String name1, @PathParam("name2") String name2 )
{
String query = "MATCH (first:User {name:{name1}}),\n" +
"(second:User {name:{name2}})\n" +
"MATCH p=shortestPath(first-[*..4]-second)\n" +
"RETURN length(p) AS depth";
Map params = new HashMap();
params.put( "name1", name1 );
params.put( "name2", name2 );
Result result = db.execute( query, params );
return String.valueOf( result.columnAs( "depth" ).next() );
}
} 这里特别有趣的是各种注释:
- @Path("/distance") 指定此扩展将响应针对以 /distance 开头的相对URI的请求。
- getDistance() 上的 @Path("/{name1}/{name2}") 注释进一步限定了与此扩展关联的URI模板。 此处的片段与/distance串联以生成/distance to produce /distance/{name1}/{name2},其中{name1}和{name2}是正斜杠之间出现的任何字符的占位符。 稍后,在“测试服务器扩展”中,我们将在/socnet相对URI下注册该扩展。 那时,路径的这几个不同部分确保了HTTP请求定向到以/socnet/distance/{name1}/{name2}开头的相对URI(例如,http://localhost/socnet/distance/Ben/Mike )将分派到此扩展程序的实例。
- @GET指定仅当请求是HTTP GET时才应调用 getDistance()。 @Produces表示响应实体主体将被格式化为text/plain。
- 参数前面的两个 @PathParam批注在getDistance()处,用于将{name1}和{name2}路径占位符的内容映射到方法的name1和name2参数。 给定URI http://localhost/socnet/distance/Ben/Mike,将调用 getDistance(),其中Ben代表name1,Mike代表name2。
- 构造函数中的@Context批注使此扩展传递给对服务器内部嵌入式图形数据库的引用。 服务器基础结构负责创建扩展并将其注入图数据库实例,但是GraphDatabaseService参数的存在使得此扩展非常可测试。 稍后我们将在“测试服务器扩展”中看到,我们可以对测试扩展进行单元测试,而不必在服务器内部运行它们。
服务器扩展是我们应用程序体系结构中的强大元素。 他们的主要利益包括:
- 复杂事务
- 扩展使我们能够在单个事务的上下文中执行任意复杂的操作序列。
- API的选择
- 每个扩展都注入了对服务器核心嵌入式图形数据库的引用。 这使我们可以访问所有API,包括核心API,遍历框架,图形算法包和Cypher,以开发我们扩展程序的行为。
- 封装
- 因为每个扩展都隐藏在RESTful接口的后面,所以我们可以随着时间的推移改进和修改其实现。
- 响应格式
- 我们控制响应(包括表示格式和HTTP标头)。这使我们能够创建响应消息,其内容使用我们域中的术语,而不是标准REST API的基于图的术语(例如,用户,产品和订单, 而不是节点,关系和属性)。 此外,在控制附加到响应的HTTP标头时,我们可以利用HTTP协议处理诸如缓存和发送请求之类的事情。
在考虑使用服务器扩展时,我们应牢记以下几点:
- 仅JVM
- 与针对嵌入式Neo4j进行开发一样,我们必须使用基于JVM的语言。
- GC行为
- 我们可以在服务器扩展内部执行任意复杂(危险)的事情。我们需要监视垃圾收集行为,以确保不会带来任何不利的副作用。
2.2.聚类
正如我们在“可用性”中更详细讨论的那样,Neo4j群集使用主从复制来实现高可用性和水平读取扩展。 在本节中,我们讨论使用群集Neo4j时要考虑的一些策略。
2.2.1.复制
尽管所有写入群集的操作都是通过主服务器进行协调的,但Neo4j确实允许通过从属服务器进行写入,但是即使如此,要写入的从属服务器也将与主服务器进行同步,然后再返回客户端。由于附加的网络流量和协调协议,通过从站进行写操作可能比直接写入主控设备慢一个数量级。通过从站进行写操作的唯一原因是为了提高每次写操作的持久性保证(在两个实例(而不是一个实例)上使写变得持久),并确保在使用缓存分片时可以读取自己的写操作(请参见“缓存分片”)。和本章后面的“读自己的文章”)。由于Neo4j的更新版本使我们能够指定将对主服务器的写入复制到一个或多个从属服务器,从而增加了对对主机的写入的持久性保证,因此通过从属服务器进行写入的情况现在不那么吸引人了。今天,建议将所有写操作定向到主服务器,然后使用ha.tx_push_factor和ha.tx_push_strategy配置设置复制到从服务器。
2.2.2.使用队列进行缓冲区写
在高写负载情况下,我们可以使用队列来缓冲写操作并调节负载。通过这种策略,对集群的写操作被缓冲在队列中。 然后,工作程序轮询队列并针对数据库执行批量写入。 这不仅可以调节写流量,还可以减少争用,并使我们能够在维护期间暂停写操作而不会拒绝客户端请求。在高写负载情况下,我们可以使用队列来缓冲写操作并调节负载。 使用此策略,对群集的写操作被缓存在队列中。 然后,工作程序轮询队列并针对数据库执行批量写入。 这不仅可以调节写入流量,还可以减少争用并使我们能够暂停写入操作,而无需在维护期间拒绝客户的请求。
2.2.3.全球集群
对于迎合全球受众的应用程序,可以在多个数据中心和Amazon Web Services(AWS)等云平台上安装多区域集群。 多区域群集使我们能够为群集中地理位置最接近客户端的部分提供读取服务。 但是,在这些情况下,由区域的物理隔离引入的等待时间有时会破坏协调协议。 因此,通常希望将主选区限制在单个区域。 为此,我们为不希望参与主选举的实例创建了仅从属数据库。 为此,我们在实例的配置中包含ha.slave_coordinator_update_mode = none配置参数。
2.3.负载均衡
当使用集群图数据库时,我们应该考虑跨集群负载均衡流量,以帮助最大化吞吐量并减少延迟。 Neo4j不包括本地负载均衡器,而是依靠网络基础架构的负载均衡功能。
2.3.1.将读取流量与写入流量分开
鉴于建议将大部分写流量定向到主服务器,我们应该考虑清楚地将读请求与写请求分开。 我们应该配置负载平衡器,以将写入流量定向到主服务器,同时平衡整个集群中的读取流量。
在基于Web的应用程序中,HTTP方法通常足以区分具有严重副作用(即写入)的请求和对服务器没有重大副作用的请求:POST,PUT和DELETE可以修改服务器端资源 ,而GET是没有副作用的。
使用服务器扩展时,请务必使用@GET和@POST注释区分读写操作。 如果我们的应用程序仅依赖于服务器扩展,则将两者分开就足够了。 但是,如果我们使用REST API将Cypher查询提交到数据库,情况就不是那么简单了。 REST API使用POST作为读取和写入Cypher请求的常规“process this”语义。 为了在这种情况下分离读写请求,我们引入了一对负载均衡器:一个始终将请求定向到主服务器的写负载均衡器,以及一个在整个集群之间均衡请求的读负载均衡器。 在我们的应用程序逻辑中,我们知道该操作是读取还是写入,然后我们将不得不决定对任何特定请求应使用两个地址中的哪个地址,如图4-9所示。
在服务器模式下运行时,Neo4j会公开一个URI,指示该实例当前是否是主实例,如果不是,则表明哪个实例是主实例。负载均衡器可以定期轮询该URI,以确定将流量路由到何处。
2.3.2.缓存分片
当需要满足它们的图形部分驻留在主内存中时,查询运行最快。 当图包含数十亿个节点,关系和属性时,并非所有图都可以放入主内存中。 其他数据技术通常通过对数据进行分区来解决此问题,但是对于图形而言,分区或分片异常困难(请参见“图形可伸缩性的圣杯”)。 那么,我们如何在一个很大的图上提供高性能查询呢?
一种解决方案是使用一种称为缓存分片的技术(图4-10),该技术包括将每个请求路由到HA群集中的数据库实例,在该实例中,满足该请求所需的图形部分可能已经存在于主内存中(记住 :集群中的每个实例都将包含数据的完整副本)。 如果应用程序的大多数查询是图本地查询,这意味着它们从图中的一个或多个特定点开始并遍历周围的子图,则该机制可以将从同一组起始点开始的查询始终路由到同一数据库实例将增加每个查询命中热缓存的可能性。

用于实现一致路由的策略将因域而异。 有时候进行粘性sessions就足够了; 其他时候,我们将根据数据集的特征进行路由。 最简单的策略是让实例首先为特定用户提供请求,然后为该用户提供后续请求。其他特定于域的方法也将起作用。 例如,在地理数据系统中,我们可以将有关特定位置的请求路由到已为该位置预热的特定数据库实例。 两种策略都增加了所需的节点和关系已经被缓存在主存储器中的可能性,可以在其中对其进行快速访问和处理。

2.4.阅读自己的文章
有时,我们可能需要阅读我们自己的文章,通常在应用程序应用最终用户更改时,并且需要下一个请求将更改的影响反映回用户。 尽管对主服务器的写入是立即一致的,但是整个集群最终还是一致的。 我们如何确保在下一个负载平衡的读取请求中反映出指向主服务器的写入? 一种解决方案是使用与高速缓存分片中相同的一致路由技术,将写入定向到将用于服务后续读取的从属。 假设可以基于每个请求中的某些域条件一致地路由写入和读取。
这是通过从属设备进行写入的少数情况之一。 但请记住:通过从属设备写入可能比直接写入主设备要慢一个数量级。 我们应谨慎使用此技术。 如果大量写入要求我们读取自己的写入,则此技术将显着影响吞吐量和延迟。
3.测试(Testing)
测试是应用程序开发过程的基本部分,不仅是一种验证查询或应用程序功能行为正确的方法,而且还是一种设计和记录我们的应用程序及其数据模型的方式。 在本节中,我们强调测试是日常活动。 通过以测试驱动的方式开发我们的图形数据库解决方案,我们为系统提供了快速发展,并不断响应新的业务需求。
3.1.测试驱动的数据模型开发
在讨论数据建模时,我们强调了我们的图形模型应反映我们要针对它进行的查询的种类。 通过以测试驱动的方式开发数据模型,我们记录了对域的理解,并验证了查询的行为正确。
通过测试驱动的数据建模,我们基于从我们的领域中绘制的小型,代表性示例图编写单元测试。 这些示例图仅包含足够的数据来传达域的特定功能。 在许多情况下,它们可能仅包含10个左右的节点以及连接它们的关系。 我们使用这些示例描述该域的正常情况以及异常情况。 当我们在真实数据中发现异常和极端情况时,我们会编写一个测试来重现我们发现的内容。
我们为每个测试创建的示例图包括该测试的设置或上下文。在此上下文中,我们执行查询,并断言查询的行为符合预期。 因为我们控制测试数据的内容,所以作为测试的作者,我们知道预期的结果。
测试可以像文档一样工作。 通过阅读测试,开发人员可以了解应用程序要解决的问题和需求,以及作者解决这些问题的方式。 考虑到这一点,最好使用每种测试仅测试我们网域的一个方面。 阅读许多小型测试要容易得多,每个小型测试都以清晰,简单,简洁的方式传达我们数据的离散特征,而不是对单个大型大型测试进行反向工程。 在许多情况下,我们会发现一个特定的查询正在由多个测试来执行,其中一些测试展示了遍历我们领域的成功之路,而另一些测试则在某些特殊结构或一组值的背景下进行了测试。
3.1.1.示例:测试驱动的社交网络数据模型
在此示例中,我们将演示为社交网络开发非常简单的Cypher查询。 给定网络中几个成员的名称,我们的查询将确定它们之间的距离。
首先,我们创建一个代表我们领域的小图。 使用Cypher,我们创建了一个包含10个节点和8个关系的网络:
public GraphDatabaseService createDatabase()
{
// Create nodes
String createGraph = "CREATE\n" +
"(ben:User {name:'Ben'}),\n" +
"(arnold:User {name:'Arnold'}),\n" +
"(charlie:User {name:'Charlie'}),\n" +
"(gordon:User {name:'Gordon'}),\n" +
"(lucy:User {name:'Lucy'}),\n" +
"(emily:User {name:'Emily'}),\n" +
"(sarah:User {name:'Sarah'}),\n" +
"(kate:User {name:'Kate'}),\n" +
"(mike:User {name:'Mike'}),\n" +
"(paula:User {name:'Paula'}),\n" +
"(ben)-[:FRIEND]->(charlie),\n" +
"(charlie)-[:FRIEND]->(lucy),\n" +
"(lucy)-[:FRIEND]->(sarah),\n" +
"(sarah)-[:FRIEND]->(mike),\n" +
"(arnold)-[:FRIEND]->(gordon),\n" +
"(gordon)-[:FRIEND]->(emily),\n" +
"(emily)-[:FRIEND]->(kate),\n" +
"(kate)-[:FRIEND]->(paula)";
String createIndex = "CREATE INDEX ON :User(name)";
GraphDatabaseService db =
new TestGraphDatabaseFactory().newImpermanentDatabase();
db.execute( createGraph );
db.execute( createIndex );
return db;
}createDatabase()有两件有趣的事情。 首先是使用ImpermanentGraphDatabase,它是Neo4j的轻量级内存版本,专门为单元测试而设计。 通过使用ImpermanentGraphDatabase,我们避免了每次测试后都必须清除磁盘上的存储文件。 该类可以在Neo4j内核测试jar中找到,可以通过以下依赖关系引用获得该类:
org.neo4j
neo4j-kernel
${project.version}
test-jar
test
ImpermanentGraphDatabase仅用于单元测试,它是Neo4j的仅内存版本,不适用于生产用途。

createDatabase() 中的第二件有趣的事情是Cypher命令,该索引使用给定属性上具有给定标签的节点编制索引。 在这种情况下,我们要基于节点的name属性值为带有:User标签的节点建立索引。
创建示例图后,我们现在可以编写第一个测试。 这是测试我们的社交网络数据模型及其查询的测试装置:
public class SocialNetworkTest
{
private static GraphDatabaseService db;
private static SocialNetworkQueries queries;
@BeforeClass
public static void init()
{
db = createDatabase();
queries = new SocialNetworkQueries( db );
}
@AfterClass
public static void shutdown()
{
db.shutdown();
}
@Test
public void shouldReturnShortestPathBetweenTwoFriends() throws Exception
{
// when
Result result = queries.distance( "Ben", "Mike" );
// then
assertTrue( result.hasNext() );
assertEquals( 4, result.next().get( "distance" ) );
}
// more tests
}该测试装置包括一个@BeforeClass注释的初始化方法,该方法在任何测试开始之前执行。 在这里,我们调用createDatabase()来创建示例图的实例,并创建一个SocialNetworkQueries实例,以容纳正在开发的查询。
我们的第一个测试应该shouldReturnShortestPathBetweenTwoFriends()来测试正在开发的查询可以找到网络的任何两个成员之间的路径,在本例中为Ben和Mike。 给定样本图的内容,我们知道Ben和Mike是相互连接的,但是距离是4。但是,该测试因此断言查询返回的是包含值为4的非空结果。 测试,我们现在开始开发第一个查询。 这是SocialNetworkQueries的实现。
public class SocialNetworkQueries
{
private final GraphDatabaseService db;
public SocialNetworkQueries( GraphDatabaseService db )
{
this.db = db;
}
public Result distance( String firstUser, String secondUser )
{
String query = "MATCH (first:User {name:{firstUser}}),\n" +
"(second:User {name:{secondUser}})\n" +
"MATCH p=shortestPath((first)-[*..4]-(second))\n" +
"RETURN length(p) AS distance";
Map params = new HashMap();
params.put( "firstUser", firstUser );
params.put( "secondUser", secondUser );
return db.execute( query, params );
}
// More queries
} 在SocialNetworkQueries的构造函数中,我们将提供的数据库实例存储在成员变量中,这使它可以在查询实例的整个生命周期中反复使用。 查询本身我们在distance()方法中实现。 在这里,我们创建一个Cypher语句,初始化包含查询参数的映射,然后执行该语句。
如果shouldReturnShortestPathBetweenTwoFriends()通过(确实通过),那么我们继续测试其他方案。 例如,如果网络的两个成员被四个以上的连接分开,会发生什么情况? 我们写下该场景以及我们期望查询在另一个测试中执行的操作:
@Test
public void shouldReturnNoResultsWhenNoPathAtDistance4OrLess()
throws Exception
{
// when
Result result = queries.distance( "Ben", "Arnold" );
// then
assertFalse( result.hasNext() );
}在这种情况下,第二项测试通过了,而无需修改基础的Cypher查询。 但是,在许多情况下,新的测试将迫使我们修改查询的实现。 发生这种情况时,我们将修改查询以使新的测试通过,然后在固定装置中运行所有测试。 固定装置中任何地方的测试失败均表明我们已经破坏了某些现有功能。 我们将继续修改查询,直到所有测试再次变为绿色。
3.1.2.测试服务器扩展
服务器扩展可以通过测试驱动的方式开发,就像嵌入式Neo4j一样容易。 使用前面所述的简单服务器扩展,我们将对其进行测试:
@Test
public void extensionShouldReturnDistance() throws Exception
{
// given
SocialNetworkExtension extension = new SocialNetworkExtension( db );
// when
String distance = extension.getDistance( "Ben", "Mike" );
// then
assertEquals( "4", distance );
}由于扩展程序的构造函数接受GraphDatabaseService实例,因此我们可以注入一个测试实例(一个ImpermanentGraphDatabase实例),然后像其他任何对象一样调用其方法。
但是,如果我们想测试服务器内部运行的扩展,则需要做更多的设置:
public class SocialNetworkExtensionTest
{
private ServerControls server;
@BeforeClass
public static void init() throws IOException
{
// Create nodes
String createGraph = "CREATE\n" +
"(ben:User {name:'Ben'}),\n" +
"(arnold:User {name:'Arnold'}),\n" +
"(charlie:User {name:'Charlie'}),\n" +
"(gordon:User {name:'Gordon'}),\n" +
"(lucy:User {name:'Lucy'}),\n" +
"(emily:User {name:'Emily'}),\n" +
"(sarah:User {name:'Sarah'}),\n" +
"(kate:User {name:'Kate'}),\n" +
"(mike:User {name:'Mike'}),\n" +
"(paula:User {name:'Paula'}),\n" +
"(ben)-[:FRIEND]->(charlie),\n" +
"(charlie)-[:FRIEND]->(lucy),\n" +
"(lucy)-[:FRIEND]->(sarah),\n" +
"(sarah)-[:FRIEND]->(mike),\n" +
"(arnold)-[:FRIEND]->(gordon),\n" +
"(gordon)-[:FRIEND]->(emily),\n" +
"(emily)-[:FRIEND]->(kate),\n" +
"(kate)-[:FRIEND]->(paula)";
server = TestServerBuilders
.newInProcessBuilder()
.withExtension(
"/socnet",
ColleagueFinderExtension.class )
.withFixture( createGraph )
.newServer();
}
@AfterClass
public static void teardown()
{
server.close();
}
@Test
public void serverShouldReturnDistance() throws Exception
{
HTTP.Response response = HTTP.GET( server.httpURI()
.resolve( "/socnet/distance/Ben/Mike" ).toString() );
assertEquals( 200, response.status() );
assertEquals( "text/plain", response.header( "Content-Type" ));
assertEquals( "4", response.rawContent( ) );
}
}在这里,我们使用ServerControls实例来托管扩展。 我们使用TestServerBuilders提供的构建器创建服务器,并在测试装置的init()方法中填充其数据库。 这个构建器使我们能够注册扩展,并将其与相对URI空间相关联(在本例中,是/socnet下面的所有内容)。init()完成后,我们就可以启动并运行数据库服务器实例。
在测试本身serverShouldReturnDistance()中,我们使用Neo4j测试库中的HTTP客户端访问此服务器。 客户端在/socnet/distance/Ben/Mike处发出对该资源的HTTP GET请求。 (在服务器端,此请求被分派到SocialNetworkExtension的实例。)当客户端收到响应时,测试将断言HTTP状态代码,内容类型和响应主体的内容正确。
3.2.性能测试
到目前为止,我们已经描述了测试驱动的方法,可以传达上下文和领域的理解,并测试其正确性。 但是,它不会测试性能。 当面对一个大得多的图时,对一个只有20个节点的小样本图快速运行的方法可能效果不佳。 因此,为了配合我们的单元测试,我们应该考虑编写一套查询性能测试。 最重要的是,我们还应该在应用程序的开发生命周期的早期投资一些彻底的应用程序性能测试。
3.2.1.查询性能测试
查询性能测试与成熟的应用程序性能测试不同。 在此阶段,我们感兴趣的是,在针对某个与我们预期在生产中遇到的图形大致一样大的图形运行特定查询时,该查询的性能是否良好。理想情况下,这些测试是开发并排侧单元测试。 没有什么比花很多时间完善查询更糟糕的了,只是发现它不适合生产规模的数据。
创建查询性能测试时,请记住以下准则:
- 创建一套性能测试,以行使通过我们的单元测试开发的查询。 记录性能数据,以便我们可以看到调整查询,修改堆大小或从图形数据库的一个版本升级到另一个版本的相对影响。
- 经常运行这些测试,以便我们迅速意识到性能的任何下降。 我们可能会考虑将这些测试合并到一个连续交付的构建管道中,如果测试结果超过一定值,则构建失败。
- 在单个线程上运行这些测试。 在此阶段,无需模拟多个客户端:如果单个客户端的性能不佳,那么多个客户端就不太可能提高性能。 严格来讲,即使它们不是单元测试,我们也可以使用与开发单元测试相同的单元测试框架来驱动它们。
- 运行每个查询多次,每次随机选择启动节点,这样我们就可以看到从冷缓存开始的效果,然后随着多个查询的执行逐渐变暖。
3.2.2.应用程序性能测试
应用程序性能测试与查询性能测试不同,它在代表生产使用情况下测试整个应用程序的性能。
与查询性能测试一样,我们建议将这种性能测试作为日常开发的一部分与应用程序功能的开发并行进行,而不是作为单独的项目阶段。 为了在项目生命周期的早期阶段促进应用程序性能测试,通常有必要开发一个“行走骨架(walking skeleton)”,即整个系统的端到端切片,性能测试客户端可以访问和使用它。 通过开发行走骨架,我们不仅提供性能测试,而且还为解决方案的图形数据库部分建立了架构环境。 这使我们能够验证我们的应用程序体系结构,并确定允许对单个组件进行离散测试的层和抽象。
性能测试有两个目的:它们演示了系统在生产中使用时的性能,并且排除了使人们更容易诊断性能问题,错误行为和错误的操作能力。 在实际部署和运行系统时,我们在创建和维护性能测试环境中所学的知识将被证明是无价的。
在制定性能测试标准时,我们建议指定百分位数而不是平均值。 永远不要假设响应时间呈正态分布:现实世界并非如此。 对于某些应用程序,我们可能要确保所有请求在特定时间段内返回。 在极少数情况下,最重要的是,第一个请求要与预热缓存一样快。 但是在大多数情况下,我们将要确保大多数请求在特定时间段内返回; 也就是说,在200毫秒内满足了98%的请求。 保持后续测试运行的记录很重要,这样我们就可以比较一段时间内的性能数据,从而快速确定性能下降和异常行为。
与单元测试和查询性能测试一样,应用程序性能测试在自动交付管道中使用时被证明是最有价值的,在自动交付管道中,将应用程序的后续构建自动部署到测试环境中,执行测试并自动分析结果。 日志文件和测试结果应存储起来,以便以后检索,分析和比较。 回归和失败会使构建失败,从而促使开发人员及时解决问题。 在应用程序开发生命周期的整个过程中而不是最后进行性能测试的一大优势是,失败和回归通常可以与最近的开发联系在一起。 这使我们能够快速,简洁地诊断,查明和纠正问题。
为了生成负载,我们需要一个负载生成代理。 对于Web应用程序,有几种可用的开源压力和负载测试工具,包括Grinder,JMeter和Gatling。 在测试负载平衡的Web应用程序时,我们应确保测试客户端分布在不同的IP地址上,以便在整个群集之间平衡请求。
3.2.3.使用代表性数据进行测试
对于查询性能测试和应用程序性能测试,我们将需要一个数据集,该数据集代表我们将在生产中遇到的数据。 因此,有必要创建或获取此类数据集。 在某些情况下,我们可以从第三方获取数据集,或改编我们拥有的现有数据集; 无论哪种方式,除非数据已经是图形形式,否则我们都必须编写一些自定义的导出-导入代码。
但是,在许多情况下,我们都是从头开始。 如果是这种情况,我们必须花一些时间来创建数据集构建器。 与软件开发生命周期的其余部分一样,最好以迭代和增量方式完成此操作。 只要我们在单元测试中记录和测试了我们在域数据模型中引入的新元素,就会将相应的元素添加到性能数据集构建器中。 这样,我们对领域的当前理解将使我们的性能测试接近实际使用情况。
在创建代表性数据集时,我们尝试重现我们已经确定的任何域不变式:每个节点的最小,最大和平均关联数,不同关联类型的散布,属性值范围等等。 当然,并非总是可以事先了解这些情况,并且经常我们会发现自己需要进行粗略的估算,直到有可用的生产数据来验证我们的假设为止。
尽管理想情况下,我们总是使用生产规模的数据集进行测试,但通常不可能或不希望在测试环境中重现大量数据。 在这种情况下,我们至少应确保建立一个有代表性的数据集,其大小超出了将整个图形保存在主内存中的能力。 这样,我们将能够观察到逐出缓存的效果,并查询当前未保存在主内存中的图表部分。
代表性数据集也有助于容量规划。 无论是创建完整的数据集,还是按比例缩小样本以达到预期的生产图,我们的代表性数据集都将为我们提供一些有用的数据,以估算磁盘上生产数据的大小。 这些数字可帮助我们计划要分配给页面缓存和Java虚拟机(JVM)堆的内存量(有关更多详细信息,请参见“容量规划”)。
在以下示例中,我们使用名为Neode的数据集构建器来构建示例社交网络:
private void createSampleDataset( GraphDatabaseService db )
{
DatasetManager dsm = new DatasetManager( db, SysOutLog.INSTANCE );
// User node specification
NodeSpecification userSpec =
dsm.nodeSpecification( "User",
indexableProperty( db, "User", "name" ) );
// FRIEND relationship specification
RelationshipSpecification friend =
dsm.relationshipSpecification( "FRIEND" );
Dataset dataset =
dsm.newDataset( "Social network example" );
// Create user nodes
NodeCollection users =
userSpec.create( 1_000_000 ).update( dataset );
// Relate users to each other
users.createRelationshipsTo(
getExisting( users )
.numberOfTargetNodes( minMax( 50, 100 ) )
.relationship( friend )
.relationshipConstraints( RelationshipUniqueness.BOTH_DIRECTIONS ) )
.updateNoReturn( dataset );
dataset.end();
}Neode使用节点和关系规范来描述图中的节点和关系及其属性和允许的属性值,然后Neode提供了一个流畅的界面来创建和关联节点。
4.容量规划(Capacity Planning)
在应用程序开发生命周期的某个时刻,我们将要开始计划进行生产部署。 在许多情况下,组织的项目管理门控流程意味着,如果不了解应用程序的生产需求,就无法进行项目。 容量规划对于预算目的和确保有足够的交货时间来采购硬件和保留生产资源都是必不可少的。
在本节中,我们描述了一些可用于硬件大小调整和容量规划的技术。 我们估算生产需求的能力取决于许多因素。 关于代表性图形大小,查询性能以及预期用户及其行为的数量,我们拥有的数据越多,我们估计硬件需求的能力就越强。 通过在应用程序开发生命周期的早期应用“测试”中描述的技术,我们可以获得很多此类信息。 此外,我们应该了解在业务需求范围内可用于我们的成本/性能折衷。
4.1.优化标准
在计划生产环境时,我们将面临许多优化选择。 我们的支持将取决于我们的业务需求:
- 成本(Cost)
- 我们可以通过安装完成任务所需的最少硬件来优化成本。
- 性能(Performance)
- 我们可以通过购买最快的解决方案(受预算限制)来优化性能。
- 冗余(Redundancy)
- 我们可以通过确保数据库集群足够大以承受一定数量的机器故障来优化冗余和可用性(例如,要使两台机器发生故障,我们需要一个包含五个实例的集群)。
- 负载(Load)
- 使用复制的图形数据库解决方案,我们可以通过水平缩放(用于读取负载)和垂直缩放(用于写入负载)来优化负载。
4.2.性能
冗余和负载可以根据确保可用性(例如,五台机器在面对两台机器出现故障时提供连续可用性的必要机器)和可伸缩性(按照每台并发请求数计算一台机器)方面的成本来计算。 计算中的“负载”)。 但是性能如何呢? 我们如何衡量绩效?
4.2.1.计算图形数据库性能的成本
为了了解优化性能的成本含义,我们需要了解数据库堆栈的性能特征。 如我们稍后在“本机图存储”中更详细描述的那样,图数据库使用磁盘进行持久存储,并使用主内存来缓存图的某些部分。
硬盘很便宜,但是对于随机寻道来说并不是很快(现代磁盘大约6毫秒)。 一直到硬盘的查询要比仅接触图形内存部分的查询慢几个数量级。 可以通过使用固态驱动器(SSD)代替硬盘(将性能提高大约20倍)或使用企业级闪存硬件(可以进一步减少延迟)来改善磁盘访问。
对于图形中数据大小大大超过可用RAM(以及缓存)数量的那些部署,SSD是一个不错的选择,因为它们没有与硬盘相关的机械代价。

4.2.2.性能优化选项
然后,我们可以在三个方面优化性能:
- 增加JVM堆大小。
- 增加映射到页面缓存的存储的百分比。
- 投资更快的磁盘:SSD或企业闪存硬件。
如图4-11所示,在成本与性能之间进行权衡的最佳点在于我们可以将存储文件整体映射到页面缓存中,同时允许一个健康但大小适中的堆。 尽管在许多情况下,较小的堆实际上可以提高性能(通过减轻昂贵的GC行为),但4至8 GB的堆并不少见。
计算要分配给堆和页面缓存的内存量取决于我们对图形的预计大小。 在应用程序开发生命周期的早期建立一个有代表性的数据集,将为我们提供进行计算所需的一些数据。 如果我们无法将整个图适合主内存,则应考虑缓存分片(请参阅“缓存分片”)。
有关常规性能和调优技巧的更多信息,请访问此站点。


在优化图形数据库解决方案以提高性能时,我们应牢记以下准则:
- 我们应该尽可能地利用页面缓存; 如果可能的话,我们应该将我们的商店文件整体映射到此缓存中。
- 我们应该在监视垃圾回收的同时调整JVM堆,以确保行为顺畅。
- 当磁盘访问不可避免时,我们应该考虑使用快速磁盘(SSD或企业闪存硬件)来提高基准性能。
4.3.冗余
规划冗余要求我们确定在保持应用程序正常运行的同时,群集中有多少个实例可以承受损失。 对于非关键业务应用程序,该数字可能低至一个(甚至为零)。 一旦第一个实例失败,另一个失败将使该应用程序不可用。关键业务应用程序可能会需要至少两个冗余; 也就是说,即使在两台计算机发生故障之后,应用程序仍会继续处理请求。
对于其群集管理协议需要大多数成员才能正常工作的图形数据库,可以通过三个或四个实例实现一个冗余,而通过五个实例实现两个冗余。 在这方面,四个不比三个更好,因为如果四实例集群中的两个实例不可用,其余协调者将不再能够取得多数。
4.4.负载
优化负载可能是容量规划中最棘手的部分。 根据经验:
并发请求数 =(1000 / 平均请求时间(毫秒)) * 每台计算机的内核数 * 计算机数
实际上,确定其中一些数字或预期的数字有时可能非常困难:
- 平均请求时间(Average request time)
- 这涵盖了从服务器收到请求到发送响应的时间段。 假设测试是在代表性硬件上针对代表性数据集运行的,那么性能测试可以帮助确定平均请求时间(否则,我们将不得不相应地进行套期保值)。 在许多情况下,“代表性数据集”本身是基于粗略估计的; 每当此估算值发生变化时,我们都应该修改我们的数据。
- 并发请求数(Number of concurrent requests)
-
在这里,我们应该区分平均负载和峰值负载。 确定新应用程序必须支持的并发请求数是一件困难的事情。 如果我们要替换或升级现有的应用程序,则可以访问一些最新的生产统计信息,以用于优化估算。 一些组织能够从现有应用程序数据推断出新应用程序的可能要求。 除此之外,我们的利益相关者需要估计系统上的预计负载,但是我们必须提防虚高的期望。
-
5.导入和批量加载数据
许多(如果不是大多数的话)任何类型的数据库部署都不会以空的存储开始。 作为部署新数据库的一部分,我们还可能需要从旧平台迁移数据,需要来自某些第三方系统的主数据,或者仅仅是将测试数据(例如本章示例中的数据)导入到其他数据库中。 空的存储。 随着时间的流逝,我们可能不得不从实时商店的上游系统执行其他批量加载操作。
Neo4j提供了用于实现这些目标的工具,无论是针对初始批量加载还是正在进行的批量导入场景,都使我们能够将来自其他各种来源的数据流式传输到图形中。
5.1.初始导入
对于初始导入,Neo4j有一个名为neo4j-import的初始加载工具,该工具可实现每秒约1,000,000条记录的持续提取速度。 它实现了这些令人印象深刻的性能指标,因为它没有使用数据库的常规事务处理功能来构建存储文件。 取而代之的是,它以类似于fashion的方式构建存储文件,添加各个图层,直到存储完成为止,并且只有在存储完成后,存储才变得一致。
neo4j-import工具的输入是一组提供节点和关系数据的CSV文件。 例如,请考虑以下三个CSV文件,它们代表一个小型电影数据集。
第一个文件是 movies.csv:
:ID,title,year:int,:LABEL
1,"The Matrix",1999,Movie
2,"The Matrix Reloaded",2003,Movie;Sequel
3,"The Matrix Revolutions",2003,Movie;Sequel第一个文件代表电影本身。 文件的第一行包含描述电影的元数据。 在这种情况下,我们可以看到每部电影都有一个ID,一个title和一个year(是整数)。 ID字段用作密钥。 导入的其他部分可以使用其ID引用电影。 电影也有一个或多个标签:电影和续集
第二个文件actors.csv包含电影演员。 如我们所见,actor具有一个ID和name属性,以及一个Actor标签:
:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor第三个文件role.csv指定演员在电影中扮演的角色。 此文件用于在图中创建关系:
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",1,ACTS_IN
keanu,"Neo",2,ACTS_IN
keanu,"Neo",3,ACTS_IN
laurence,"Morpheus",1,ACTS_IN
laurence,"Morpheus",2,ACTS_IN
laurence,"Morpheus",3,ACTS_IN
carrieanne,"Trinity",1,ACTS_IN
carrieanne,"Trinity",2,ACTS_IN
carrieanne,"Trinity",3,ACTS_IN该文件中的每一行都包含一个START_ID和END_ID,一个角色值和一个关系TYPE。 START_ID值包含来自actor CSV文件的actor ID值。 END_ID值包含电影CSV文件中的电影ID值。 每个关系都表示为START_ID和END_ID,具有角色属性,以及从关系TYPE派生的名称。
使用这些文件,我们可以从命令行运行导入工具:
neo4j-import --into target_directory \
--nodes movies.csv --nodes actors.csv --relationships roles.csvneo4j-import构建数据库存储文件,并将它们放在target_directory中
5.2.批量导入
另一个常见的要求是将大量数据从外部系统推送到实时图形中。 在Neo4j中,通常使用Cypher的LOAD CSV命令执行此操作。LOADCSV以与neo4j-import工具相同的CSV数据作为输入。 它旨在支持大约一百万个项目的中间负载,因此非常适合处理来自上游系统的定期批次更新。
举例来说,让我们用一些有关设置位置的数据丰富我们现有的电影图。 location.csv包含标题和位置字段,其中location是电影中拍摄位置的分号分隔列表:
title,locations
"The Matrix",Sydney
"The Matrix Reloaded",Sydney;Oakland
"The Matrix Revolutions",Sydney;Oakland;Alameda有了这些数据,我们可以使用Cypher LOAD CSV命令将其加载到实时Neo4j数据库中,如下所示:
LOAD CSV WITH HEADERS FROM 'file:///data/locations.csv' AS line
WITH split(line.locations,";") as locations, line.title as title
UNWIND locations AS location
MERGE (x:Location {name:location})
MERGE (m:Movie {title:title})
MERGE (m)-[:FILMED_IN]->(x)该Cypher脚本的第一行告诉数据库我们要从文件URI加载一些CSV数据(LOAD CSV也与HTTP URI一起使用)。 WITH HEADERS告诉数据库,我们的CSV文件的第一行包含命名的标题。 AS行将输入文件分配给变量行。 然后,将针对源文件中每行CSV数据执行脚本的其余部分。
脚本的第二行以WITH开头,使用Cypher的split函数将一行的location值拆分为字符串集合。 然后,将结果集合和该行的标题值传递到脚本的其余部分。
UNWIND是有趣的工作开始的地方。 UNWIND扩展了一个系列。 在这里,我们将其用于将locations集合扩展为单独的位置行(请记住,此时我们正在处理单个电影的位置),每个行都将由随后的MERGE语句处理。
第一条MERGE语句确保该位置由数据库中的节点表示。 第二条MERGE语句确保影片也作为节点出现。 第三个MERGE语句确保位置和电影节点之间存在FILMED_IN关系。
MERGE就像MATCH和CREATE的混合。 如果图形中已经存在MERGE语句中描述的模式,则该语句的标识符将绑定到该现有数据,就像我们指定了MATCH一样。 如果图形中当前不存在该模式,则MERGE会创建它,就像我们使用CREATE一样。
为了使MERGE匹配现有数据,图形中的所有元素必须已经存在于图形中。 如果无法匹配模式的所有部分,则MERGE将创建整个模式的新实例。 这就是为什么我们在LOAD CSV脚本中使用了三个MERGE语句的原因。鉴于特定的电影和特定的位置,图表中很可能已经存在一个或另一个。 它们也可能同时存在,但是没有联系它们的关系。 如果要使用单个大型MERGE语句而不是三个小型语句。
MERGE (:Movie {title:title})-[:FILMED_IN]->(:Location {name:location}))仅当电影和位置节点及其之间的关系已经存在时,匹配才会成功。 如果该模式的任何一部分不存在,那么将创建所有部分,从而导致数据重复。
我们的策略是将较大的模式分解为较小的块。 我们首先确保该位置存在。 接下来,我们确保电影存在。 最后,我们确保两个节点已连接。 使用MERGE时,这种增量方法非常正常。

此时,我们可以将大量CSV数据插入实时图形。 但是,我们尚未考虑进口的机械影响。 在现有的大型数据集上运行类似的大型查询时,插入操作可能会花费很长时间。 为了提高导入效率,我们需要考虑两个关键特性:
- 索引已经存在的图
- 通过数据库的事务流
对于我们这些来自关系背景的人来说,索引的需求在这里很明显。 没有索引,我们必须搜索数据库中的所有电影节点(在最坏的情况下,是所有节点),以确定电影是否存在。 这是成本O(n)运算。 使用电影索引,该成本下降到O(log n),这是一个很大的改进,尤其是对于较大的数据集。 位置也是如此。
如上一章所述,声明索引很简单。 要索引电影,我们只需发出命令 CREATE INDEX ON :Movie(title) 。 我们可以通过浏览器或使用Shell来执行此操作。 如果索引仅在导入期间有用(即它在操作查询中不起作用),则在导入后使用 DROP INDEX ON :Movie(title) 将其删除。
在某些情况下,将临时ID作为属性添加到节点很有用,这样在导入期间可以轻松地引用它们,尤其是在创建关系网络时。 这些ID没有域意义。 它们仅在多步导入过程中存在,因此该过程可以找到要连接的特定节点。
使用临时ID完全有效。 请记住,导入完成后,请使用REMOVE将其删除。

鉴于对实时Neo4j实例的更新是事务性的,因此使用LOAD CSV进行批量导入也是事务性的。 在最简单的情况下,LOAD CSV建立一个事务并将其馈送到数据库。 对于较大的批次插入,这在机械上可能效率很低,因为数据库必须管理大量的事务状态(有时为千兆字节)。
对于大型数据导入,我们可以通过将单个大型事务提交分解为一系列较小的提交来提高性能,这些较小的提交随后针对数据库进行串行执行。 为此,我们使用PERIODIC COMMIT功能.PERIODIC COMMIT将导入分为一组较小的事务,这些事务在处理了一定数量的行(默认为1000)后提交。 利用我们的电影位置数据,我们可以选择将每笔交易的默认CSV行数减少到100,例如,通过在Cypher脚本前添加USING PERIODIC COMMIT 100来进行。 完整的脚本是:
USING PERIODIC COMMIT 100
LOAD CSV WITH HEADERS FROM 'file:///data/locations.csv' AS line
WITH split(line.locations,";") as locations, line.title as title
UNWIND locations AS location
MERGE (x:Location {name:location})
MERGE (m:Movie {title:title})
MERGE (m)-[:FILMED_IN]->(x)这些用于加载批量数据的工具使我们既可以在设计系统时尝试使用示例数据集,又可以与其他系统和数据源集成(作为生产部署的一部分)。 CSV是一种无处不在的数据交换格式-几乎每种数据和集成技术都对生成CSV输出有一定的支持。 这使得一次性或定期将数据导入Neo4j非常容易。
6.摘要
在本章中,我们讨论了开发图形数据库应用程序的最重要方面。 我们已经了解了如何创建满足应用程序需求和最终用户目标的图形模型,以及如何使用单元测试和性能测试使我们的模型和相关查询具有表现力和鲁棒性。 我们研究了两种不同应用程序架构的优缺点,并列举了在计划生产时需要考虑的因素。
最后,我们研究了用于将批量数据快速加载到Neo4j中的选项,用于初始导入和正在进行的批量插入实时数据库。
在下一章中,我们将探讨当今如何使用图形数据库来解决社交网络,建议,主数据管理,数据中心管理,访问控制和物流等领域中的现实问题。