【AdaSeq行业应用系列】篇章级关键词抽取比赛,baseline模型开箱即用,
作者:落叶
链接:https://zhuanlan.zhihu.com/p/593807831
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:映辉
本文介绍下最近开源的框架AdaSeq中集成了关键词提取的模型和代码。
我们从alimeeting的654场会议内容作为文档,对每篇会议文档找了三名标注人员进行关键词抽取标注,然后将每个在文中的关键词标注为进行NER的格式,在bert-crf的框架上当做NER任务进行训练。训练好的模型已经开源在modelscope上,安装modelscope,采取ner pipeline,调用我们训练好的baseline model,就可以使用了。

ModelScope 魔搭社区
快速使用
modelscope上已经提供了采用alimeeting的数据、structbert为backbone训练好了的模型,并进行了封装。简单使用方法如下:
先安装modelscope
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html接下来就可以调用接口在自己的数据上测试
from modelscope.pipelines
import pipeline
from modelscope.utils.constant import Tasks
ner_pipeline = pipeline(Tasks.named_entity_recognition, 'damo/nlp_structbert_keyphrase-extraction_base-icassp2023-mug-track4-baseline')
result = ner_pipeline('我的名字叫做张小明,我们根本不喜欢今天的晚会,今天的晚会很不好。') print(result)
# {'output': [{'type': 'KEY', 'start': 20, 'end': 22, 'span': '晚会'}, {'type': 'KEY', 'start': 26, 'end': 28, 'span': '晚会'}]}可见在随便的一句话中,zero-shot的识别效果也还不错。一些模型、指标等细节可以访问modelscope链接
https://modelscope.cn/models/damo/nlp_structbert_keyphrase-extraction_base-icassp2023-mug-track4-baseline/summary
===============================分界线==============================
使用AdaSeq自主训练
想尝试用AdaSeq,在自己的数据集上train一个关键词抽取模型的小伙伴,可以往下看。
数据下载
以Alimeeting的数据集为例。(训练集数据可以在关键词抽取train集上下载)数据格式:
将csv的每条数据转化为json,所有数据构成一个json列表。

数据格式
其中我们关心的key是sentences和candidate。sentences是单条数据中会议的每句话,candidate是关键词标注(key_word)和关键词所抽取的句子来源(key_sentence)。
代码下载
git clone代码。
git clone https://github.com/modelscope/adaseq.git pip install -r requirements.txt -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html数据处理
我们的模型处理数据的格式是conll格式,某个关键词的头采用B-KEY的tag,关键词的其他部分采用I-KEY的tag,其余不涉及关键词的token打上O,具体demo如下:

conll数据格式
由于一篇文档长达1.7w个token,直接送入模型中对显存要求较高,而且除了deberta等,大多数的PLM不支持这么长的token序列,所以我们要做切割。我们保证同一句话的每个token是在同一个batch中的,所以可以将一些句子按照指定长度附近拼接为一个小文档。比如我们设置max_size是192,就可以将其中的六七句话拼接到一起,作为小文档,在后面接上\n\n 。
数据处理可以直接使用内部代码
cd examples/ICASSP2023_MUG_track4
python preprocess.py序列标注模型框架

AdaSeq提供基础的序列标注模型是BERT CRF,通过将关键词转成标签序列,模型学习输入文本到标签序列的mapping,这里BERT可以有效建模中文文本字与字之间上下文的关系,CRF有效建模标签之间的关系。当然,AdaSeq里也提供了更多丰富的组件,可以进一步优化和尝试,
模型训练配置
在AdaSeq框架下,可以直接通过配置yaml文件,来进行训练模式的调整,设计训练模型的backbone(struct-bert等)、模型架构(bert-crf等)、数据集目录、任务类型(sequence-labeling等),在该任务下的配置文件如下:
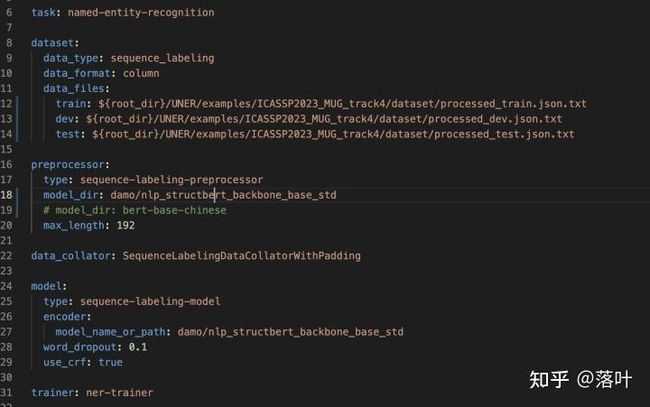
bert_crf_sbert.yaml文件内容
之后直接在项目根目录下,运行scripts/train.py,指定配置文件为bert_crf_sbert.yaml即可开始训练
python scripts/train.py -c examples/ICASSP2023_MUG_track4/configs/bert_crf_sbert.yaml训练模型的过程中会打印dev集上NER的评估结果,以及将预测结果写入对应的输出文件pred.txt。
评估指标
关键词的评估指标和NER并不完全相同,其最终需要提取的是关键词的集合和真正关键词的重合之间的关系,而并不取决于每个位置的BIOtag识别的正误。主要有exact matched 和partial matched两种metrics进行评估。
exact matched:是指评估一个关键词是否正确是取决于一个词是否出现在标注关键词中,一个词算作正确当且仅当与标注关键词集合中的某个完全一致的情况,如“文艺晚会”和“文艺晚会”
partial matched:一个词算作正确,只需要其与标注关键词集合中的某个词有超过2大小的公共子串即可,如“文艺晚会”和“晚会”
此外,为了减缓模型overgenerate关键词的情况,我们还根据提取出的关键词在文档中的词频来进行排序,选取出top@10,top@20,作为答案进行评估。
在adaseq的关键词抽取模块ICASSP2023_MUG_track4中,也集成了对于全量关键词、top@10、top@20的关键词采用exact matched和partial matched的评估函数,运行脚本即可:
cd examples/ICASSP2023_MUG_track4
python evaluate_kw.py dataset/dev.json ${root_dir}/experiments/kpe_sbert/outputs/${datetime}/pred.txt dataset/split_list_dev.json evaluation.log输出的评估指标会写入evaluation.log中。
==========================分界线=============================
欢迎小伙伴们到ModelScope 魔搭社区上了解其他的模型和数据哦,可以基于AdaSeq完成一键进行训练和推理哦~
可以加入钉钉 4170025534交流哈~