自定义分割数据集中的png格式图片的模式转换(P -> L)以及其他问题解决
0. 问题背景
使用labelme对自己的工业数据集进行了标注,得到原图和标注的json文件,如下图所示:

因为自己前期用的是图片+mask的数据集格式进行训练,所以也想接着用这种格式,那么接下来就要进行图像转换,我用的labelme2coco进行格式转换得到了png格式的mask图,如下:

然后就出现了各种各样的问题,接下来彻底梳理一下这种格式的问题,防止再次造轮子。
1. 格式检查
labelme2coco转换出来的原图仍然是png格式,且模式检查发现是RGB格式,如下:
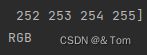
然而 :转换出来的mask图却是这种格式:
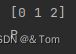
可以看到,虽然mask图显示出了彩色,但是其像素点的像素值只有0.1.2,也就是每一个像素点的像素值就是该点的类别标签。另外需要注意的是,mask的模式为P模式,也就是调色板模式。祖这点需要特别注意!!! 这样的格式与VOC数据集的图像格式是相同的,可以用VOC的读取方法进行读取。
2. cv2读取
目前用cv2.imread()函数是无法正确读取P模式的png图像的,因此如果想用cv2读取的话,要将P模式转换成L模式,这里的第一个坑也就出现了。
![]()
如果在直接读取图像之后添加convert('L')转换的话,可以看到原来的像素值(标签值)就会改变,这样就与原来的像素值就是标签值冲突了,于是我们需要进一步调整,而不是直接convert().
转换成L模式后,cv2就可以直接读取了, 读取后是一个只有尺寸而没有通道数的格式,因为L模式本身就是单通道。
原图像的话,因为是RGB模式,可以直接用cv2读取。
3. 重新调整
通过以上分析,我们可以看出如果用cv2读取P模式的图像时会发生错误,那么我们用另一种方法修改图像格式。
需要注意的是,转L模式要保证标签值不变。既然直接转会发生变化,那么就复制一个再转换。大体思路就是,创建一个L的蒙版,然后把mask的像素值全部复制进去即可。
label_ori = Image.open(label_path + "/" + masklist)
p = label_ori.getpalette()
label_ori = label_ori.resize((256, 256), Image.NEAREST)
temp = max(label_ori.size)
mask = Image.new('L', (temp, temp), 0) # 创建蒙板
mask.putpalette(p) # 获取调色板
mask.paste(label_ori, (0, 0)) # 创建一个L模式的副本
label_ori = np.array(mask)
mask = Image.fromarray(label_ori, 'L') # L模式
mask.save(save_label_path + "/" + str(i) + ".png") # 保存这样就可以得到一张L模式的png图像,但是这样的话,mask图像就变成了全黑的图像,没有了颜色映射,就像这样:

接下来,我们再检查一下图像的格式

可以看出来,像素值仍然保存了最初的标签值,但模式变成了L模式,这样可以就直接用cv2读取了。
4. 使用PIL读取
P模式的png图片,可以使用PIL直接读取,有点类似于VOC格式的读取方式,这里就不进一步说明了。大家有更好的方式可以评论在下方,共同学习。
其他问题解决:
1. 错误:
RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
1. 解决:
这个错误的原因有很多,会有标签错误等等,可以百度一下,在这里我说明一下自己的错误供大家参考查阅。
我这里的错去是因为直接用cv2处理了P模式的图像,以至于后来的Tensor无法正确获取,从而在进行 下列操作:
output.data.cpu().detach().numpy()时会出现以上报错 。在调试时也会发现,对该数据进行监控,就会提示无法正确获取Tensor,因此就会报错。
2. 错误
SELF.WAS_KILLED.IS_SET()并报错RUNTIMEERROR: DATALOADER WORKER IS KILLED BY SIGNAL
这个出现原因我也不太明确,不过把num_works设置为0确实解决了这个问题:
https://www.freesion.com/article/7292534749/ https://www.freesion.com/article/7292534749/
https://www.freesion.com/article/7292534749/
3. cv2读取png图像
https://www.csdn.net/tags/MtTaEgzsMTE2NjMtYmxvZwO0O0OO0O0O.htmlhttps://www.csdn.net/tags/MtTaEgzsMTE2NjMtYmxvZwO0O0OO0O0O.html但是这样不能读取P模式的png图片,其他模式是可以的
其他读取方法可以参照这个https://blog.csdn.net/weixin_43794311/article/details/105208731https://blog.csdn.net/weixin_43794311/article/details/105208731
4. labelme2coco
https://github.com/fcakyon/labelme2cocohttps://github.com/fcakyon/labelme2coco
5. Image 与 numpy相互转换
https://blog.csdn.net/m0_46653437/article/details/112253562?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-112253562-blog-122157558.t5_layer_eslanding_A_4&spm=1001.2101.3001.4242.1&utm_relevant_index=3https://blog.csdn.net/m0_46653437/article/details/112253562?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-112253562-blog-122157558.t5_layer_eslanding_A_4&spm=1001.2101.3001.4242.1&utm_relevant_index=3
6. transform数据增强
神经网络数据增强transforms的相关操作(持续更新)_燃烧吧哥们的博客-CSDN博客_transforms 数据增强transforms的相关操作(Pytorch)一、图像的相关变化1、格式转换(1)transforms.ToTensor()(2)transforms.ToPILImage()1、图像大小(1)一、图像的相关变化1、格式转换(1)transforms.ToTensor()可将PIL格式、数组格式转换为tensor格式img_path = "E:\expression_recognition\\2.jpg"img = Image.open(img_path) # #数组类型PIL类型都可a1https://blog.csdn.net/hjkdh/article/details/123439969https://blog.csdn.net/qq_41375318/article/details/102984221?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-102984221-blog-124452966.topnsimilarv1&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-102984221-blog-124452966.topnsimilarv1&utm_relevant_index=1https://blog.csdn.net/qq_41375318/article/details/102984221?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-102984221-blog-124452966.topnsimilarv1&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-102984221-blog-124452966.topnsimilarv1&utm_relevant_index=1
7. import torch 出现段错误,核心已转存
这个错误原因也有很多,在github上说是重新把anconda的环境变量重新更新一遍就可以了,但是对我来说,并没有发挥作用。一次偶然机会,我重新装了一下系统的显卡驱动,就好了。希望对大家有所启发。安装方法:
https://blog.csdn.net/a319506345/article/details/125004586https://blog.csdn.net/a319506345/article/details/125004586
8. RuntimeError: "softmax" not implemented for Long
这个错误的原因是在进行交叉熵损失函数时,输入的input因该时torch.float64,而输入的Target则应该是long型,这个时候只需要转换一下就可以了。
y.to(args.device).squeeze().long()https://blog.csdn.net/suyunzzz/article/details/105478701https://blog.csdn.net/suyunzzz/article/details/105478701
9. 改变Tensor尺寸
https://blog.csdn.net/qq_43581151/article/details/97271131?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_linkhttps://blog.csdn.net/qq_43581151/article/details/97271131?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link
10. AttributeError:module 'distutils' has no attribute 'version'
https://zhuanlan.zhihu.com/p/489042988https://zhuanlan.zhihu.com/p/489042988
11. pytorch的whl下载网址
https://download.pytorch.org/whl/torch_stable.htmlhttps://download.pytorch.org/whl/torch_stable.html以上就是近期遇到的难题,有大有小,欢迎大家交流共同学习!!!