目标检测 - YOLOv1
YOLOv1目标检测
一、 算法介绍
YOLO是一个可以一次性预测多个bbox位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑动窗口或提取proposal的方式训练网络,而是直接选用整幅图片来训练模型。这样做的好处在于可以更好的区分目标和背景区域。
二、 原理实现
2.1 网络设计
YOLOv1的网络结构主要是借鉴了GoogLeNet网络,该网络包括了24个卷积层,2个全链接层。其中,利用1×1 reduction layers紧跟3×3 convolutional layers取代GoogLeNet的inception modules,具体的网络结构实现如图所示:

2.2 训练
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用了GoogLeNet中前20个卷积层,然后添加一个平均池化层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。网络的最后一层采用了线性激活函数,其它层都是Leaky ReLU激活函数,并在训练中采用了Dropout和数据增强来防止过拟合。整个网络的流程如下所示:

2.3 预测
训练好网络后,随机输入一张图片送入网络中进行预测,网络最后输出一个7x7x30的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和置信度(confidence)。之后通过NMS来对可能的目标框进行过滤筛选,最终得到预测的目标框。其预测过程如下:

2.4 NMS
当我们对测试图片完成推理后,此时网络预测出了特别多的bbox以及各种class probability,现在我们要从中过滤出我们最终的预测bbox。
NMS(non maximum suppression)非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值。在最近几年常见的物体检测算法(包括R-CNN、SppNet、Fast-RCNN、Faster-RCNN等)中,最终都会从一张图片中找出很多个可能是物体的矩形框,具体实现步骤如下:
(1) 按照分类概率由高到低进行排序,选取概率最高的框作为候选框;
(2) 计算剩余框与候选框的IOU,高于阈值的框概率置为0;
(3) 在剩余不为0的框里寻找第二大概率的框,并计算剩余框与候选框的IOU,高于阈值的框概率置为0;
(4) 依次类推;
(5) 最后剩下的所有概率非0的框就是最终的检测框。

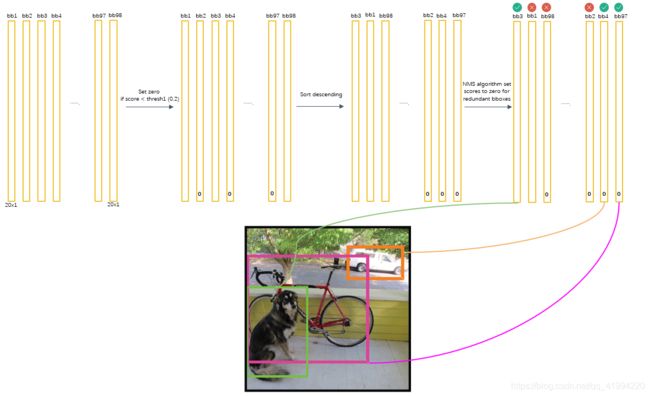
就如上图所示,我们想要定位一只狗,但算法最终找出了一堆疑似狗的目标的方框,因此我们需要判别哪些矩形框是没用的。
开始我们将所有98个框按照预测概率从高到低排序(为方便计算,排序前可以剔除极小概率的框,也就是把它们的概率置为0),然后通过非极大抑制NMS方法,继续剔除多余的框:

那么,NMS方法在这里如何运行呢?首先因为经过了排序,所以第一个框是概率最大的框(下图橘色)。然后继续扫描下一个框跟第一个框,看是否IOU大于0.5,如果IOU大于0.5,那么第二个框是多余的,将它剔除:

继续扫描到第三个框,它与最大概率框的IOU小于0.5,需要保留:

继续扫描到第四个框,同理需要保留:

继续扫描后面的框,直到所有框都与第一个框比较完毕。
此时保留了不少框,接下来,根据次一级概率的框(因为一开始排序过,它在顺序上也一定是保留框中最靠近上一轮的基础框的),将它后面的其它框于之比较。最后,在经历了所有的扫描之后,对狗类别只留下了两个框:

这时候,或许会有疑问:明显留下来的蓝色框,并非狗的类,为什么要留下?因为对计算机来说,图片可能出现两只狗,保留概率不为0的框是安全的。不过的确后续设置了一定的阈值(比如0.5)来删除掉概率太低的框,这里的蓝色框在最后并没有保留,因为它在20种类别里要么因为IOU不够而被删除,要么因为最后阈值不够而被剔除。
上面描述了对狗的类进行的框的选择,接下来,我们还要对余下的19种类别分别进行上面的操作,最后进行纵向跨类的比较。判定流程和法则如下:

从而得到最后的结果:
三、 损失函数
YOLOv1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括两个候选框的位置和有无包含物体的置信度以及网格中包含20个物体类别的概率。那么损失函数则包括三个部分:位置误差,置信度误差,分类误差。算法中全部采用了sum-squared error loss来做这件事,如下图:

在上图中,我们也能清晰的看出来,整个算法的损失是由预测框的坐标误差、有无包含物体的置信度误差以及网格预测类别的误差三部分组成,三部分的损失都使用了均方误差的方式来实现:
(1)位置损失
从上图可以看出,坐标损失分为两部分,即坐标中心误差和位置宽高的误差,其中l_ij^obj表示第i个网格中的第j个预测框是否负责这个物体的预测,只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IOU是不是在那个网格的所有box中最大。
我们可以看到,对于中心点的损失直接用了均方误差,但是对于宽高为什么用了平方根呢? 对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移损失是一样。为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的w和h取平方根代替原本的w和h,如下图:

Small bbox的横轴值较小,发生偏移时,反应到纵轴上的损失比Big bbox要大。所以,算法对位置损失中的宽高损失加上了平方根。
(2)置信度损失
这里分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。confidence是针对bounding box的,由于每个网格有两个bounding box,所以每个网格会有两个confidence与之相对应。
从损失函数上看,当网格i中的第j个预测框包含物体的时候,用上面的置信度损失,而不包含物体的时候,用下面的损失函数。
(3)类别损失
类别损失这里也用了均方误差,其中l_i^obj表示有无目标的中心点落到网格i中,如果网格中包含有物体目标的中心的话,那么就负责预测该目标的概率。
我们知道,将位置误差、置信度误差以及分类误差视为同等重要显然是不合理的,而且如果一个网格中没有目标,那么网格中box的置信度将被置为0,相比于那些有较少目标的网格,这种做法是太过强硬的,容易导致网络不稳定甚至发散。因此,算法使用了权重系数来进行平衡,对于不同的损失用不同的权重:因为网格预测框坐标较为重要,因此给这部分损失赋予了更大的损失权重,在Pascal VOC中取值为5;对没有目标box的置信度损失赋予较小的损失,在Pascal VOC训练中取0.5;对有目标box的置信度损失以及类别损失取值为1。
四、 实验分析
4.1 评价指标
YOLO的评价指标一般为mAP和ROC曲线:
(1)mAP
mean average precision,意思是平均精度均值。AP就是PR曲线下面的面积,是指不同召回率下的精度的平均值。然而,在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR曲线,进而计算出一个AP值。那么多个类别的AP值的平均就是mAP。
(2)ROC曲线
Receiver Operating Characteristic Curve,该曲线的横坐标为假阳性率(False Positive Rate, FPR),N是真实负样本的个数,FP是N个负样本中被分类器预测为正样本的个数。纵坐标为真阳性率(True Positive Rate, TPR) TPR=TP/P 其中,P是真实正样本个数,TP是P个正样本被分类器预测为正样本个数。当绘制完成曲线后,就会对模型有一个定性的分析。
4.2 论证分析
作者在论文中做了大量的对比实验,具体如下:
(1)在PASCAL VOC2007 和PASCAL VOC2012数据集上,YOLO同DPM、R-CNN、Fast R-CNN以及Faster R-CNN进行了对比实验,结果如下:

(2)YOLO与Fast R-CNN的检测误差分布对比如下:

(3)YOLO与当时主流的目标检测算法的精度-召回曲线对比:

(4)YOLO与R-CNN在PASCAL VOC2007数据集下的AP值与F1分数对比:

(5)实际检测效果:

五、 总结
YOLO模型构造简单,可以直接在完整图像上进行训练。与基于分类器的方法不同,YOLO针对与检测性能直接对应的损失函数进行训练。
总的来说,YOLO将目标检测任务向前推进了一大步,使目标检测能够在实际生活中使用变成了可能。