YOLO神经网络
YOLO神经网络
本文准备详细介绍一下用于目标检测的YOLO神经网络,主要是个人研读《You Only Look Once: Unified, Real-Time Object Detection》与《YOLO9000: Better, Faster, Stronger》这两篇论文的所得,以及结合网上一些对YOLO网络的解读。
首先我想说明下我个人认为YOLO网络的核心突破点。
在基于神经网络的机器视觉领域,两个问题一直居于核心,大部分流传甚广的优秀网络架构基本都是围绕这两个问题展开的,一个是目标识别,一个是目标检测。其中目标识别处于一个更基础的位置,所以很多基础的网络都是为了实现目标识别问题展开的,比如VGG、AlexNet、ResNet等。
但是,目标识别只能识别出图片中的目标的种类,但是不能分辨出其位置与外框,也就是俗称的“定位问题”。目标检测的任务就是找出图片中存在的物体位置(包括其中心与外框),以及该物体是什么,即目标定位与目标识别的结合。
其实看到这儿大家应该就想到了一个问题,那就是目标检测看似是一个问题,实际上是两个问题,这两个问题本质上不分先后,但是就我个人的知识,目前应该还没有先识别对象类别再进行定位的算法,我认为这主要是因为,目标检测问题往往一张图片上存在多个物体,同时识别多个物体种类非常复杂繁琐,而且成功率不高。
在YOLO之前,经典的目标检测算法,如RCNN、Fast-RCNN、Faster-RCNN等,其思路都是,先根据目标聚类提取ROI(Region of Interest),即可能带有物体的区域,尽可能保证每个区域有且仅有一个物体,然后对每个区域中的物体种类进行识别。这两步分别由两个神经网络来实现,一个是ROI提取,一个是目标识别。
接下来就说到YOLO的核心突破了。上面也提到,目标检测其实是两个问题,一般网络也是这样处理的,但这也就意味着,目标检测网络一般都很复杂,层数很多,运算速度很慢,处理频率很低,难以达到实时处理的效果。
所以,Joseph等人在构架YOLO网络时提出,不分步进行了,直接将对象位置与对象种类一起学习,用一个更轻便的网络来实现。从本质的本质上来讲,YOLO的核心就是这个,“You Look Only Once”,即通过一次学习直接定位对象并贴上标签。
当然,之后YOLO网络也经过了不断地改进,但是核心就是一次性学习,这里面当然也存在一些需要解决的算法问题,而且,初代的YOLO虽然在速度上已经大幅提升,但是离真正的在移动设备上实时应用还有一段距离,即使YOLO9000(YOLOv2)也不太行。不过,YOLOv4已经比较成熟了,大家可以自己到GitHub上看看源码。
下面,我将以个人理解的方式,介绍下YOLO网络中提出的一些具有创新性的算法思路:
YOLO
核心思路
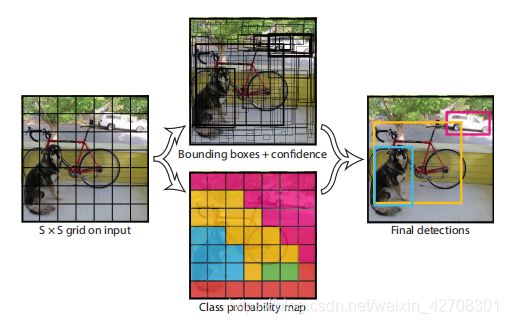
首先,Joseph等人对输入图片做了一个分块的操作,将 224 × 224 224\times224 224×224的标准输入图片分成了 7 × 7 7\times7 7×7的区域,如果物体中心落入了某个网格单元,则由该网格单元负责检测该物体。每个单元格可以给出多个可能的边界框,但是存在既定上限,YOLOv1中给定的上限是2,即每个单元格最多给出两个预测边界框。
检测某物体时需要检测的参数包括边界框(x,y,w,h)、置信度(confidence)、对象概率(20类)。其中,(x,y)是边界框的中心坐标,采用单元格边长进行归一化到0-1之间,w,h则是边界框边长,采用图片边长归一化到0-1之间。
置信度则定义为 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth,若该单元格存在物体, P r ( O b j e c t ) = 1 Pr(Object)=1 Pr(Object)=1,否则为0; I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth则表示预测框与真实框之间的并集比例(0-1之间)。
最后是对象概率,YOLOv1支持20类物体的检测,即对于每个物体,输出其分别属于20类物体的概率。
结合上述,最终YOLO网络输出的预测值是一个 7 × 7 ( 单 元 格 数 ) × [ 2 × 5 ( 边 界 框 参 数 ) + 20 ( 对 象 概 率 ) ] 7\times7(单元格数)\times[2\times5(边界框参数)+20(对象概率)] 7×7(单元格数)×[2×5(边界框参数)+20(对象概率)]的张量。
至此,我们已经搞清了YOLO网络的根本思路与核心参数。剩下的就是一些网络结构与训练参数设定的问题了。
网络设计
 YOLO网络的架构原型来自GoogleNet,具有24个卷积层与两个全连接层,完整的网络如上图所示。
YOLO网络的架构原型来自GoogleNet,具有24个卷积层与两个全连接层,完整的网络如上图所示。
训练(损失函数设计)
训练阶段也有一个核心问题,那就是损失函数的设计。由于YOLO的输出参数较多,损失函数的设计也会比较复杂。下面来简析以下YOLO网络的损失函数设计思路。
一开始,Joseph等人是打算用输出的和平方误差来作为损失函数,但是和平方误差并不符合最大化平均精度的目标。定位误差和分类误差的权重不应该相等,而且,在每个图像中,许多网格单元格不包含对象,导致这些单元格的置信度接近0,通常会压倒包含对象的单元格的梯度,导致模型不稳定,训练结果发散。
为了纠正这一点,Joseph等人增加边框坐标预测的损失权重,减少不包含对象的框的置信度预测的损失权重。权重调整通过 λ c o o r d \lambda_{coord} λcoord和 λ n o o b j \lambda_{noobj} λnoobj来实现,设 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5, λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5。
和平方误差在大盒和小盒中同样加权误差,大盒子里的小偏差比小盒子里的小偏差影响小。为了部分解决这个问题,采用预测边框宽度w和高度h的平方根的误差来计算损失。
最终,损失函数设计如下:
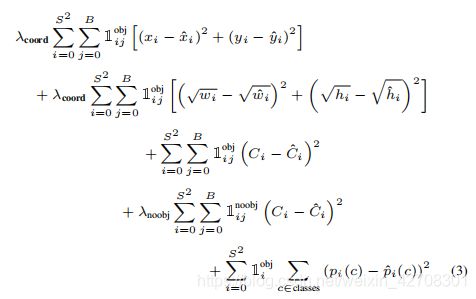
简单解读一下: 1 i o b j 1^{obj}_{i} 1iobj表示对象是否落在单元格 i i i中(0或1), 1 i j o b j 1^{obj}_{ij} 1ijobj则表示单元格 i i i中的第 j j j个预测边界框是准确的预测边界框(0或1)。
第一行是边界框中心坐标的误差;
第二行是边界框长宽的误差,由于边界框大小本身便会影响到误差的大小,为了降低边界框大小的影响,而采用了开方差来比较;
第三行是包含物体的单元格以及准确预测的边界框的置信度误差;
第四行是不包含物体的单元格中以及准确预测的边界框的置信度误差;
第五行是包含物体的单元格中,预测对象概率的各分项的误差平方之和。
至此,YOLO的几个核心问题其实已经讲完了,YOLO本身并不复杂, 其重点在于创新性,但是YOLOv1无论是精度还是泛用性都还不尽如人意,所以下面再讲讲YOLO9000,可以更好地理解如何去改进YOLO网络。
YOLO9000
YOLO9000,顾名思义,其相对YOLO网络的核心优势在于将识别对象的种类从20类扩展到了9000类,另外进一步提高了网络的运行速度(简化网络)与检测精度。还有就是解决了原网络只能处理 224 × 224 224\times 224 224×224的输入的问题,YOLOv2能够处理任意尺寸的图片。
YOLO9000相较YOLO,究竟在哪些方面做出了改进是我们最关心的问题。一些非核心的改进,比如批处理规范化(Batch Normalization)、高分辨率的分类器(High Resolution Classifier)等。一些算法的核心改动如下:
Better(更准确)
带有锚盒的卷积(Convolutional With Anchor Boxes)
上文提到过,YOLO与Faster RCNN等网络不同,直接预测边界框的参数,而YOLOv2则返回去借鉴了Faster RCNN中用到的anchor思想。
原先的YOLO网络,每个单元格只预测两个边界框,因此一共只有 7 × 7 × 2 = 98 7\times 7\times 2=98 7×7×2=98个边界框,而YOLOv2引入Anchor boxes后,预测的box数量超过了1000。
box的增加是两方面的,一方面,YOLOv2的输入由 224 × 224 224\times 224 224×224增大到了 416 × 416 416\times 416 416×416,且最终的输出变成了 13 × 13 13\times 13 13×13的feature map。每个grid cell包含9个anchor box,一共就有1521个box。
顺便一提,Faster RCNN在输入为1000*600时,约有6000个box,增加box数量能有效提高定位准确率。
维集群(Dimension Clusters)
一般来说,box的尺寸是依靠经验设定,然后在训练过程中调整,而作者提出采用k-means的方法对Bounding Box做聚类,一开始就找出合适尺寸的anchor box,以此提高预测准确率。
然后作者发现,标准的k-means方法采用的是欧氏距离,在box尺寸较大时,差异也会比较大,但是我们希望差异与box尺寸本身无关,所以通过IOU定义了如下距离函数:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box,centroid)=1-IOU(box,centroid) d(box,centroid)=1−IOU(box,centroid)
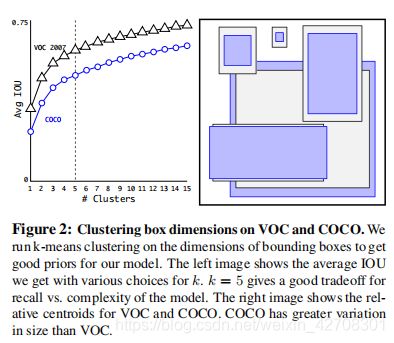
如图是VOC和COCO(两个测试集)的聚类框尺寸。最终他们通过实验选定了 k = 5 k=5 k=5作为召回率和模型复杂性的一个平衡点。
直接位置预测(Direct location prediction)
作者在引入anchor box时也遭遇了模型不稳定的问题,早期的迭代过程这个不稳定主要来自于预测box的(x,y)。
在诸如Faster RCNN一类基于Region proposal的object detection算法中,是通过预测offset来计算(x,y)值的,即:
x = ( t x ∗ w a ) − x a x=(t_x*w_a)-x_a x=(tx∗wa)−xa y = ( t y ∗ h a ) − y a y=(t_y*h_a)-y_a y=(ty∗ha)−ya
其中, x a x_a xa与 y a y_a ya是anchor的坐标, w a w_a wa与 h a h_a ha是anchor的size,通过预测偏移量 t x t_x tx与 t y t_y ty来确定box的位置。
但是作者认为该方法并不适用于YOLO网络,因为任何anchor box都可能在图像中的任何点结束,在随机初始化的情况下,模型需要很长时间稳定预测出合理的偏移量。所以最终还是沿用了YOLOv1中直接预测(x,y)的方法。
前面提到YOLO9000的最终输出是一个 13 × 13 13\times 13 13×13的feature map,每个单元格预测5个bounding box(5个是由上面box先验预测决定的,5个bounding box已经能够比较准确的预测box尺寸了)。然后,每个bounding box包含5个坐标 ( t x , t y , t w , t h , t o ) (t_x,t_y,t_w,t_h,t_o) (tx,ty,tw,th,to)( t o t_o to类似于YOLO中的confidence)。
c x , c y c_x,c_y cx,cy表示一个cell到左上角的距离, p w , p h p_w,p_h pw,ph表示bounding box的宽高,最终的预测值就对应于:
b x = σ ( t x ) + c x b_x=\sigma(t_x)+c_x bx=σ(tx)+cx b y = σ ( t y ) + c y b_y=\sigma(t_y)+c_y by=σ(ty)+cy b w = p w e t w b_w=p_we^{t_w} bw=pwetw b h = p h e t h b_h=p_he^{t_h} bh=pheth P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) Pr(object)*IOU(b,object)=\sigma(t_o) Pr(object)∗IOU(b,object)=σ(to)
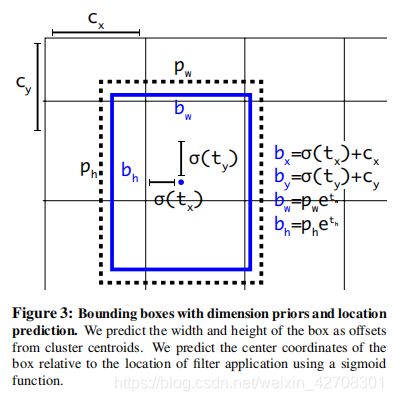
光这么讲很难直观的理解,可以结合这张图看一看,黑色的虚线框是bounding box,蓝色的框是预测框。之所以搞得这么复杂主要是为了归一化方便后续计算。
细粒度特性(Fine-Grained Features)
YOLO9000输出一个13*13的feature map,对于大物体的预测已经足够了,但是对于细粒度特征识别度不够,Faster RCNN和SSD都在不同的粒度特征图上进行运行。而YOLO9000采用了一种新的方法,作者添加了一个passthrough层,从前面的层 26 × 26 26\times 26 26×26的feature map中提取特征,加到 13 × 13 13\times 13 13×13的feature map中,有点ResNet的意思,主要就是保留细粒度特征。
多尺度训练(Multi-Scale Training)
这一步主要是为了提高YOLO9000对图片尺寸的鲁棒性,简单说就是能够处理不同size的图片。
作者他们采用的方法是这样的,每隔几次迭代就改变网络。网络每10批随机选择新的图像尺寸,由于YOLO9000将图像size压缩了32倍,这个输入的size就选择了32的倍数,从 { 320 , 352 , ⋯ , 608 } \left \{320,352,\cdots,608 \right \} {320,352,⋯,608}中选取,最终使得该网络能够适应不同分辨率的图像。
而且,这种机制意味着网络可以在较小的规模下高速运行,在低分辨率下( 288 × 288 288\times 288 288×288),YOLOv2可以超过90帧,mAP与Faster RCNN几乎一样。
Faster(更快)
上面主要是在如何使网络更准确稳定的改进,而速度也是目标检测网络的一大追求。
DarkNet-19
作者做的第一项改进是使用DarkNet-19替代了YOLOv1中使用的GoogleNet,该网络只需要5.58 billion operation,而GoogleNet需要8.25,VGG甚至需要30.69。下图是DarkNet-19最终的结构,包含19个卷积层和5个max pooling层,最后用average pooling层代替全连接层进行预测。

除了直接看这个网络,我认为作者在论文中给出的一张从YOLO到YOLOv2的改进表格也很值得学习。
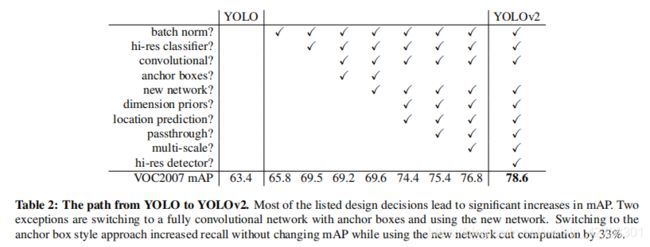
如图,作者分析了从YOLOv1到YOLOv2中做了哪些改进,以及这些改进对mAP的贡献。除了引入anchor box和新网络没有显著提高mAP外,不过anchor box和新网络的引入本身是为了提高召回率以及提速。
分类训练与检测训练
这里就是训练的一个小trick了,先在ImageNet上进行预训练,训练网络的目标识别能力,先实现准确的分类。
然后,开始移植网络,然后基于检测的数据再进行fine-tuning。首先把最后一个卷积层去掉,然后添加3个33的卷积层,每个卷积层有1024个filter,而且每个后面都连接一个11的卷积层,1*1卷积的filter个数根据检测的类数决定。
比如对于VOC数据,每个grid cell预测5个box,每个box有5个坐标值和20个类别值,所以每个grid cell有125个filter。
这里要注意,YOLOv1中,每个grid cell有30个filter,类别概率是由grid cell来预测的,也就是,每个单元格虽然有2个box,但是只预测一个物体的概率;而YOLOv2里面,每个box对应一个物体的类别概率,因此每个box对于25个预测值(5个坐标值+20个类别值)。
另外,作者还将最后一个33512的卷积层与倒数第二个卷积层相连,来利用细粒度特征。
Stronger(泛用性更强)
作者提出需要解决一个问题,那就是用于object classification的数据集很多,但是用于object detection的数据集相对就很少。作者提出除了构造数据集外,还可以采用WordTree和Joint classification and detection来解决。
这两个概念我也是第一次遇到,只能凭所学猜个一知半解。
首先,作者他们在训练过程中,混合使用了来自检测数据集和分类数据集的数据(分类数据集只有物体标签,但是没有物体位置)。当网络检测到输入为检测数据集数据时,可以以完整的loss函数进行反向传播,而输入为分类数据集数据时,只从体系结构的分类特定部分进行loss的反向传播。
这里面作者遇到了一个标签合并的问题,不同数据集对物体的划分程度可能不一样,如检测数据集一般只会分出“猫”“狗”,而分类数据集可能会细分出猫狗的品种。最终,作者采用了一个多标签模型来组合假定不互斥的数据集。
分级分类
即大标签套小标签,很好理解,如“猎狗”是“狗”的一类,这样一层层挖下去,形成一个WordTree或者WordNet,然后,预测出每个节点的概率,简单说就是,假如WordTree上存在这么一条分支:纽福克斯猎犬-猎犬-狗-哺乳动物-动物-物理对象,那么检测目标属于纽福克斯猎犬的概率就是:
P r ( 纽 福 克 斯 猎 犬 ) = P r ( 纽 福 克 斯 猎 犬 ∣ 猎 犬 ) ∗ P r ( 猎 犬 ∣ 狗 ) ∗ ⋯ ∗ P r ( 动 物 ∣ 物 理 对 象 ) Pr(纽福克斯猎犬)=Pr(纽福克斯猎犬|猎犬)*Pr(猎犬|狗)*\cdots*Pr(动物|物理对象) Pr(纽福克斯猎犬)=Pr(纽福克斯猎犬∣猎犬)∗Pr(猎犬∣狗)∗⋯∗Pr(动物∣物理对象)
作者在1000类的ImageNet上尝试构建这么一个WordTree,最终构建出了一个1369个节点的概率向量,用来表征检测目标属于某类物体的概率。
这种方法有一个核心优势,那就是当网络不确定目标是哪一种猎犬时,至少能够确定目标确实是一条狗,如果直接采用原来的标签分类,极易在不同的猎犬之间产生判断分歧,甚至导致误判,这样做虽然不能提高彻底的准确率,但是能保证大方向尽量不错。