百度paddle的强化学习教程笔记-DQN
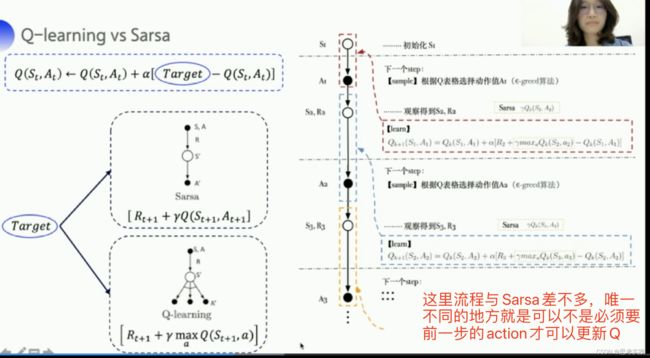
On-policy与Off-policy
强化学习中on-policy 与off-policy有什么区别?
强化学习中on-policy 与off-policy有什么区别? - 知乎
强化学习中on-policy 与off-policy有什么区别_百度知道
on-policy在学习的过程中实际只存在一种策略,它用一种策略去做action的选取也用一种策略去做优化。所以Sarsa知道它下一步的动作有可能会跑到悬崖边去,所以它就会在优化它自己的策略的时候就会尽可能的离悬崖远一点。那这样子就会保证哪怕它有随机动作也能保证它在安全区内,而off-policy在学习的过程中保留了两种不同的策略,第一种策略是我们希望学到的最佳的目标策略,另外一个策略是探索环境的行为策略(也叫做行为策略Behavior policy),它可以大胆的探索到所有可能的轨迹,喂给目标策略去学习,而且喂给目标策略的数据并不需要at+1,

行为策略像一个天不怕地不怕前线的战士,可以在环境里面探索所有的动作和轨迹经验,把这些经验教给目标策略去学习,目标策略就像后方指挥的军师,他可以根据经验来学习最优的策略,
Sarsa里面穿的action一定是作用到真实环境的action,而Q-learning里面的action可以是探索所有的情况筛选出来最优的action。
 你看这里也是这样的更新W表格不需要Q’,
你看这里也是这样的更新W表格不需要Q’,

这里sample与predict函数的实现与Sarsa一样的,动用到了贪心算法(我还不会呢找时间去学习)
 这里运行展示的代码与Sarsa差不多的。
这里运行展示的代码与Sarsa差不多的。




Lesson 3 神经网络方法求解RL——DQN
飞桨AI Studio - 人工智能学习与实训社区
人还是要活在当下,再放眼未来,否则可能顾此失彼。
Lesson3-1-函数逼近与神经网络 Lesson3-1-函数逼近与神经网络
Lesson3-1-函数逼近与神经网络
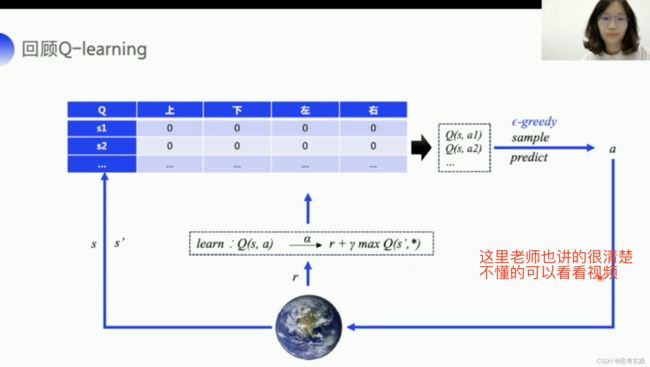
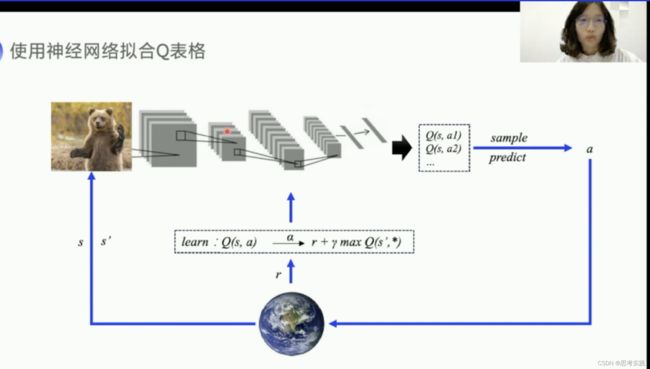
如果机器人手脚弯曲的角度作为状态那就是一个不可数的连续量,这种情况Q表格储存问题还有更新查Q表格效率问题的很严重,这里有一个值函数的近似,值函数就是我们的Q函数,我们可以用一个带参数的Q函数,来近似这个Q表格,比如说我们用多项式函数比如说我们用神经网络,近似可以有不同的类别。

重点来了:DQN
 DQN的本质啊还是咱们的Q-learning
DQN的本质啊还是咱们的Q-learning
Lesson3-2-DQN算法解析
引入了神经网络就引入了非线性函数,因为我们可能会用到relu或者一些其他的激活函数,引入非线性函数来近似Q表格,其实在理论上没有办法证明训练到最后会收敛。DQN提出了两大创新点来使得Q网络的训练更有效率也更稳定。
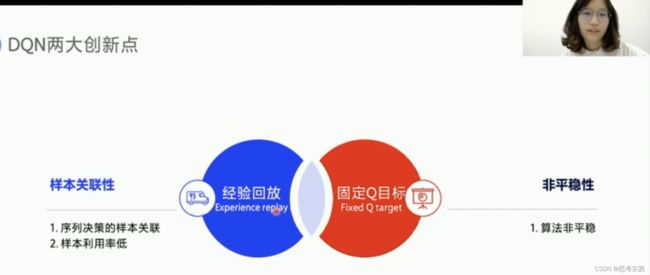
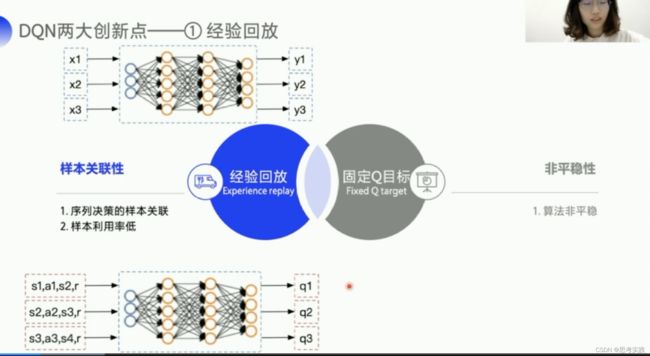
普通神经网络的输入如上图的X1,X2,X3之间上没有什么关系的,而下面这个Q网络它输入的是状态值,强化学习是一个训练决策的问题,它前后的状态其实是相互影响的,相互关联的,所以需要去打乱,切断输入样本之间的联系,才会比较好用这个神经网络,DQN就利用Q-Learning的off-policy的一个特点,他存储了一批的经验数据,然后打乱顺序从中选取一个小的batch的数据来更新网络,这种方式既可以打乱状态之间的相关性,又可以使神经网络更有效率(体现在模型泛化等等方面),这里问一下大家还记得off-policy吗,off-policy也就是训练过程中保留两种不同的策略。
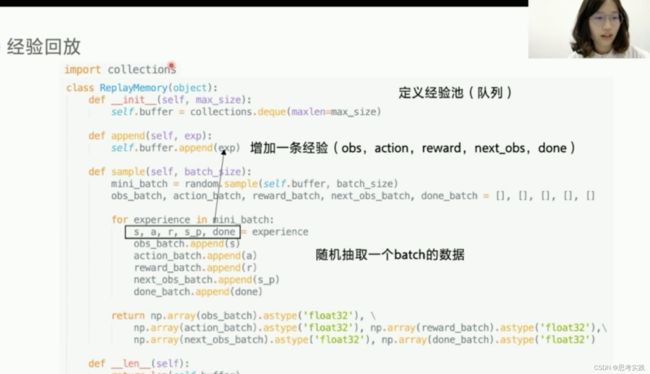
 增加这个缓冲区来存储经验还有一个好处,用本利用率会提高,经验可以重复利用,而不是像Q-learning一样,拿出一条数据去更新了Q表格就扔,我门可以用python的一个类 Class ReplayMemory来实现经验池,只需要实现append()方法与sample()方法就可以了,
增加这个缓冲区来存储经验还有一个好处,用本利用率会提高,经验可以重复利用,而不是像Q-learning一样,拿出一条数据去更新了Q表格就扔,我门可以用python的一个类 Class ReplayMemory来实现经验池,只需要实现append()方法与sample()方法就可以了,
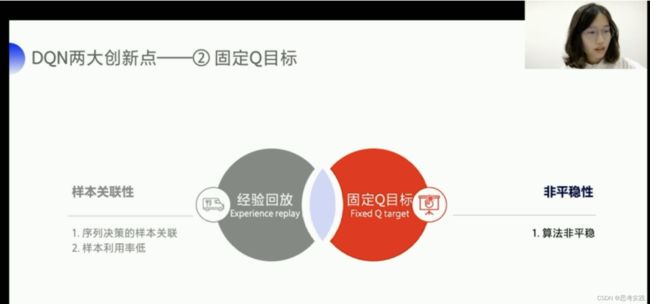 固定Q目标解决了算法更新不平稳的问题,我们先来看一下什么叫做算法更新不平稳。我们可以与监督学习做对比。
固定Q目标解决了算法更新不平稳的问题,我们先来看一下什么叫做算法更新不平稳。我们可以与监督学习做对比。

为什么要固定Q-target是因为这个Q一直跳来跳去(目前你还没有深刻的理解到)
DQN算法总结一下就三点:
1.在Q-learning的基础上引入了神经网络
2.然后增加了两大创新的算法
具体的DQN算法流程我们来看一下一张框架图,首先我们从Q-learning出发,Q-learning大概就是这样一张框架图,Q-learning是根据Q表格来输出动作的,Q-learning主要实现两个函数嘛,sample()函数带epuselong-greedy的采样来保证所用的动作被探索到,然后根据拿到的环境数据,用learn()方法去更新Q表格。
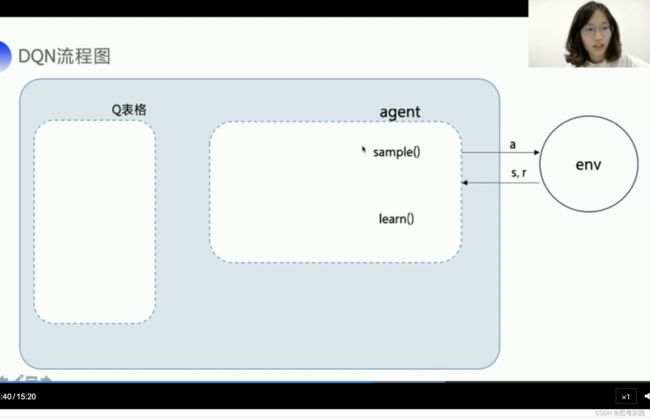
DQN就是在Q-learning的基础上,它使用模型来代表Q表格,模型输入状态s,输出不同的动作q,但是使用神经网络代替Q表格会带来两个问题,那DQN分别用经验回放与固定目标值,来解决刚才说的问题,经验回放,就是把与环境交互的数据存放在这个经验池里面,用append函数取进去,然后用sample函数从经验池里面sample一个batch的数据送到learn函数里面去训练,我们再来看看Fixed-Q target,Fixed-Q target需要另外一个与Q网络一样的targetQ网络,它的参数可以是固定一段时期,定期的从Q网络复制到Fixed-Q target, Q网络作用是用来产生Q预测值,就是可以直接决定对环境输出的action,而target Q的作用是产生一个相对稳定的Q目标值,那我们算的Q预测值与Q目标的差值就是我们Q网络要去优化的一个目标,计算出来的loss把他放到paddle的优化器里面,直接minimize, 我们就可以去更新左上角Q网络的参数。 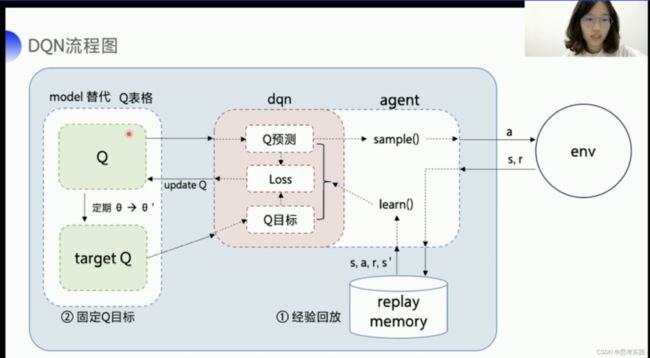
红色的这个区块其实是DQN最核心的部分,我们完全可以把这部分单独抽离出来实现dqn算法的精髓,这个也是PARL强化学习框架提出的一个框架的思想然后就是把算法框架拆分成一个嵌套的model,algorithm跟agent三个部分,model的话就是用来定义有神经网络部分的网络结构,它可以是Q网络也可以是策略网络,策略网络下节课会讲,如果说想要修改网络结构,在model里面修改就好,比如说你要定义几层全连接层,几层cnn等等之内的,然后用parl的model结构也可以非常地做模型之间的参数的复制与参数的同步,algorithm定义了一个具体的算法来更新Q网络,也就是通过定义loss函数来去更新model,DQN的loss_function呢其实就是Q预测和Q目标的一个均方差,我们可以在algorithm里面去定义两个成员一个是self.model,一个是self.target_model,分别指向我们Q网络与target-Q网络对应的model,Q-learning主要实现两个函数一个是predict()函数,一个是learn()函数,learn()函数就是来更新Q值的,再加一个sync_target()函数,去把model的参数同步到target_model里面去//这里就是之前讲的固定Q目标,实现所谓的网络同步,agent负责与环境做交互,在交互的过程中,它把生成的数据,提供给algorithm,去更新网络model,数据的预处理呢也一般都定义在这里,包括说构建一些静态图、计算图呢也定义在build_program()里面。
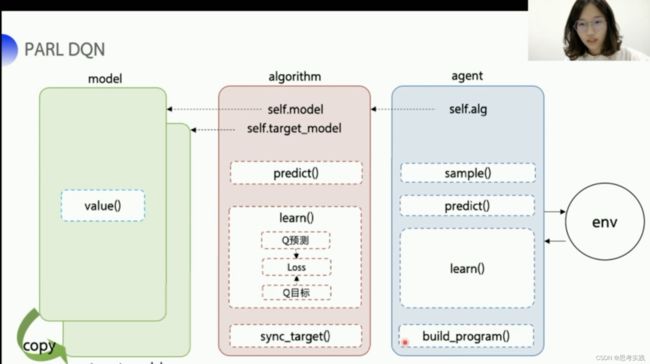 用PARL框架可以让整个DQN流程(DQN相对来说比较抽象)会比较清晰,PARL的architecture这么去设计目的其实是为了完成一个复杂任务,为了构建一个可以完成复杂任务的智能体agent,我们用嵌套的方式去组成这样一个大的agent,model定义咱们智能体的网络结构,algorithm去更新网络结构也就是定义我们的loss function,然后agent负责算法与环境之间的交互,交互的过程中生成的数据提供给algorithm来更新model,这样子的架构最最核心就是中间这个部分,PARL就把中间这个核心的部分根据数据和模型结构来去构建loss function的这一趴,PARL它就咱给实现好了已经,这样的架构可以让PARL很方便的应用在各类的深度强化学的问题当中,像比如说DQN,用这种架构,DQN整个的代码风格会看起来比较简洁,一共就五个文件
用PARL框架可以让整个DQN流程(DQN相对来说比较抽象)会比较清晰,PARL的architecture这么去设计目的其实是为了完成一个复杂任务,为了构建一个可以完成复杂任务的智能体agent,我们用嵌套的方式去组成这样一个大的agent,model定义咱们智能体的网络结构,algorithm去更新网络结构也就是定义我们的loss function,然后agent负责算法与环境之间的交互,交互的过程中生成的数据提供给algorithm来更新model,这样子的架构最最核心就是中间这个部分,PARL就把中间这个核心的部分根据数据和模型结构来去构建loss function的这一趴,PARL它就咱给实现好了已经,这样的架构可以让PARL很方便的应用在各类的深度强化学的问题当中,像比如说DQN,用这种架构,DQN整个的代码风格会看起来比较简洁,一共就五个文件 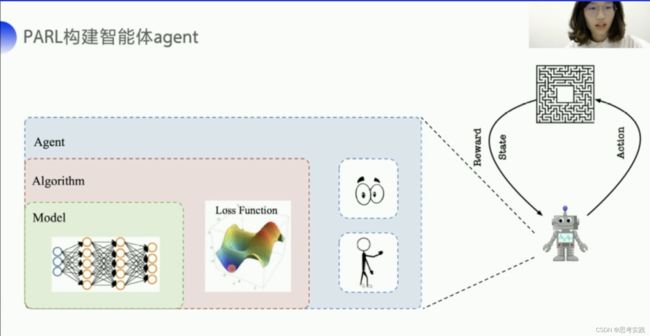
![]() 接下里我们一个一个讲怎么去实现。代码讲解部分来咯,篇幅太大,重新写一篇博客来记录代码部分。
接下里我们一个一个讲怎么去实现。代码讲解部分来咯,篇幅太大,重新写一篇博客来记录代码部分。