Python 层次分析法 AHP
import logging
import time
import numpy as np
import pandas as pd
logging.basicConfig(format='%(message)s', level=logging.INFO)
LOGGER = logging.getLogger(__name__)成对比较矩阵
该函数用于将下三角矩阵转化为成对比较矩阵
def pair_comp_array(tril):
''' tril: 下三角矩阵 (以列为单元)
return: 成对比较矩阵'''
dim = len(tril)
# 将下三角矩阵用 0 填充成方阵
for row in range(dim):
size = row + 1
assert len(tril[row]) == size, f'第 {size} 行数据不满足下三角矩阵要求'
tril[row].extend([0 for _ in range(dim - size)])
array = np.array(tril)
# 以成对比较矩阵的标准设置矩阵值
for col in range(dim):
for row in range(col):
array[row][col] = 1 / array[col][row]
return arrayRI 计算
当矩阵阶数大于 15 时,用于一致性检验的 RI 是不能通过查表得到的,需计算 1000 个随机成对比较矩阵的 CI 均值作为 RI
def cal_RI(dim, epochs=1000, decimals=4):
if dim <= 15:
return {3: 0.52, 4: 0.89, 5: 1.12, 6: 1.26, 7: 1.36, 8: 1.41, 9: 1.46,
10: 1.49, 11: 1.52, 12: 1.54, 13: 1.56, 14: 1.58, 15: 1.59}[dim]
else:
mark = time.time()
LOGGER.info(f'Calulating RI: dim = {dim}, epochs={epochs}, decimals={decimals}')
lambda_sum = 0
for i in range(epochs):
array = np.eye(dim)
# 随机构造成对比较矩阵
for col in range(dim):
for row in range(col):
array[col][row] = np.random.choice([1, 2, 3, 4, 5, 6, 7, 8, 9,
1 / 2, 1 / 3, 1 / 4, 1 / 5,
1 / 6, 1 / 7, 1 / 8, 1 / 9])
array[row][col] = 1 / array[col][row]
# 求取最大特征值
solution, weights = np.linalg.eig(array)
lambda_sum += np.real(solution.max())
# 最大特征值的均值
lambda_ = lambda_sum / 1000
RI = round((lambda_ - dim) / (dim - 1), decimals)
LOGGER.info(f'RI = {RI}, time = {round(time.time() - mark, 2)}s')
return RI特征向量
求解成对比较矩阵的特征向量有 算术平均法、几何平均法、特征值法,求解过程中会输出比较结果,并返回 3 个结果的均值、一致性指标 CI:
![]()
其中,n 为成对比较矩阵的阶数,λ 为成对比较矩阵的最大特征根
def solve_weight(array):
''' 求解特征方程
return: w, CI'''
array = array.copy()
dim = array.shape[0]
weight_list = []
# 算术平均法
weight = (array / array.sum(axis=0)).mean(axis=1, keepdims=True)
weight_list.append(weight)
# 几何平均法
weight = np.prod(array, axis=1, keepdims=True) ** (1 / dim)
weight /= weight.sum()
weight_list.append(weight)
# 特征值法
solution, weights = np.linalg.eig(array)
index = solution.argmax()
lambda_ = np.real(solution[index])
weight = np.real(weights[:, index])
weight /= weight.sum()
weight_list.append(weight[:, None])
# 输出对比结果
weight = np.concatenate(weight_list, axis=1)
LOGGER.info(pd.DataFrame(weight, columns=['算术平均', '几何平均', '特征值']))
LOGGER.info('')
weight = weight.mean(axis=1)
# 计算 CI
CI = (lambda_ - dim) / (dim - 1)
return weight, CI一致性检验
一致性比率 CR < 0.1 时,则成对比较矩阵具有满意一致性:

def consistency_check(CI, dim, single=True, decimals=5):
''' 一致性检验
single: 是否为单排序一致性检验
decimals: 数值精度
CI = (λ - n) / (n - 1)
CR = CI / RI
Success: CR < 0.1'''
if dim >= 3:
RI = cal_RI(dim)
CR = round(CI / RI, decimals)
message = f'CI = {round(CI, decimals)}, RI = {RI}, CR = {CR}'
success = CR < 0.1
else:
message = 'dim <= 2'
success = True
# 依照不同模式输出字符串
head = 'Single sort consistency check' if single else 'Total sorting consistency check'
LOGGER.info(f'{head}\nMessage: {message}\n')
assert success, f'{head}: CR >= 0.1'准则层特征向量
准则层只有一个成对比较矩阵,其特征向量即准则层的特征向量,需进行单排序一致性检验
def solve_criterion_feature(array):
''' 求解准则层特征向量'''
feature, CI = solve_weight(array)
dim = feature.size
# dim: 准则层指标数
consistency_check(CI, dim, single=True)
return feature决策层权值矩阵
决策层的成对比较矩阵数量与准则层指标数相等,每个成对比较矩阵的特征向量按列拼接即得到决策层的权值矩阵
记 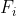 为准则层特征向量,总排序一致性检验使用的 CI 为:
为准则层特征向量,总排序一致性检验使用的 CI 为:
![]()
def solve_decision_weight(decision_array, criterion_feature):
''' 求解决策层权值矩阵
decisions_array: 决策层成对比较矩阵序列
criterion_feature: 准则层权向量'''
weight_list = []
CI_list = []
# 分别求解决策层的各个权值向量
for array in decision_array:
weight, CI = solve_weight(array)
weight_list.append(weight)
CI_list.append(CI)
# 拼接得到决策层权值矩阵
decision_weight = np.stack(weight_list, axis=1)
CI = (np.array(CI_list) * criterion_feature).sum()
dim = decision_weight.shape[0]
# dim: 决策层方案数
consistency_check(CI, dim, single=False)
return decision_weight求解示例
A = pair_comp_array([[1],
[2, 1],
[1 / 4, 1 / 7, 1],
[1 / 3, 1 / 5, 2, 1],
[1 / 3, 1 / 5, 3, 1, 1]])
B_1 = pair_comp_array([[1],
[1 / 2, 1],
[1 / 5, 1 / 2, 1]])
B_2 = pair_comp_array([[1],
[3, 1],
[8, 3, 1]])
B_3 = pair_comp_array([[1],
[1, 1],
[1 / 3, 1 / 3, 1]])
B_4 = pair_comp_array([[1],
[1 / 3, 1],
[1 / 4, 1, 1]])
B_5 = pair_comp_array([[1],
[1, 1],
[4, 4, 1]])
# 准则层特征向量: [5,]
A_feature = solve_criterion_feature(A)
# 决策层权值矩阵: [3, 5]
B_weight = solve_decision_weight([B_1, B_2, B_3, B_4, B_5], A_feature)
# 组合权向量: [3, 5] × [5,] -> [3,]
print(B_weight @ A_feature)