python学习笔记
花了三四天快速学了下python,潦草记录一下。
注释
#单行注释
'''
多行注释
'''
变量
1.大小写字母、数字、下划线和汉字等字符及组合。
2.注意事项:大小写敏感Python≠python,首字符不能是数字,不能有保留字相同。
保留字33个:

数据类型
数字类型:
- 整数(包含正负):18、-18
- 小数(包含正负):1.8、-1.8
字符串类型:
- 包含引号的值称为字符串。
- Python提供给字符串一个正向索引和逆向索引:
正向索引从0开始,逆向索引从-1开始:
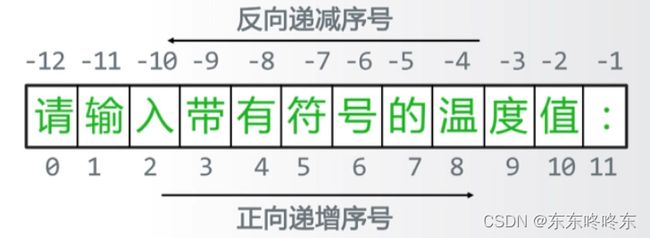
- 索引的使用与切片
索引的使用:
1.
"请输入第一个字符"[0] #"请"
2.
temp = "请输入第一个字符"
temp[0] #"请"
索引的切片:切片操作包头不包尾,如果头不写则默认从头开始,如果尾不写则默认一直到结束
temp = "请输入字符串"
temp[0:-1] #"请输入字符"
- 获取字符串的长度是len()函数
列表类型:
- 用[]包围,然后中间用,隔开
list = ['C','c']
- 使用in可以判断某元素是否存在列表中
if 'c' in list
分支语句if elif else
if A :
***
elif B :
***
else:
***
输入输出input()、print()
input()使用方法
<变量> = input(<提示语句>)
注意:用户输入的东西都是以字符串存储的,想要转换为数字得使用eval()函数。
print()使用方法
print(<提示语句>)
print函数中的参数:
end:end默认为换行,如果不想换行则要设置end=“”
print("Python",end="")
eval()评估函数
eval()的作用是去掉输入的引号后执行剩下的语句
eval("1")
>>1
eval("1+2")
>>3
eval("'1+2'")
>>'1+2'
eval("print(Hello world)")
>>Hello world
for循环与range函数
使用range函数可以表示数字范围,然后通过这个数字范围可以用来遍历for循环
range()函数的使用:
- range(N) #产生从0至N-1的整数序列
- range(M,N) #产生从M至N-1的整数序列
temp = "0123456789"
for i in range(0,len(temp)):
print(temp[i])
*for循环还可以遍历列表。
*for循环还可以遍历文件,当in后面是文件标识符时,i被赋值的是文件的每一行。
库引用
python库的概念:
标准库:随解释器一起安装
第三方库:需要额外安装的库
turtle库属于标准库之一。
使用import关键字来引用其他库以拓展函数的功能。
- 常用方法直接import,然后使用<库名>.<函数名>()来调用。
import turtle
turtle.setup(300,300)
- 使用from+import函数导入库的某个函数,可以直接使用该函数,形如<函数>(),缺点是函数名会与用户函数名冲突。
from turtle import setup
setup(300,300)
- 使用import+as给函数起别名
import turtle as t
t.setup(300,300)
turtle海龟库的学习
- 窗体
api是turtle.setup(width, height, startx, starty)
其中width表示窗体的宽,height表示高,startx、starty表示窗口左上角离频幕左上角的x轴、y轴距离。
后两个参数不是必须的,如果没写则默认在频幕正中间。
- 坐标
绝对坐标:
海龟最开始的位置是在窗体正中间,定为(0,0)。
使用turtle.goto(x,y)可以去到窗体的任一位置。
相对坐标(海龟坐标):
以海龟来定方向。
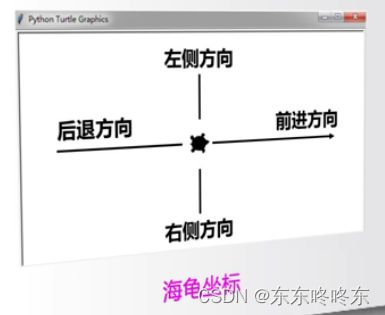
API:
turtle.fd()前进
turtle.bk()后退
turtle.circle(r,angle)以左侧的某一个点为圆心,进行曲线运动。
- 角度坐标体系
API:
turtle.seth(angle)改变方向。
turtle.left(angle)向左改变方向。
turtle.right(angle)向右改变方向。
- 画笔控制函数
API:
turtle.penup() #画笔抬起 别名turtle.pu()
turtle.pendown()#画笔降下 别名turtle.pd()
turtle.pensize(宽度) #画笔宽度 别名turtle.width(宽度)
turtle.pencolor(color) #画笔颜色 使用方式如下:
颜色字符串:turtle.pencolor(“purple”)
RGB三通道小数值:turtle.pencolor(0.63,0.13,0.94)
RGB元组值:turtle.pencolor((0.63,0.13,0.94))
数字数据运算
+、-、*:加减积
/:python中的除可以直接得到小数,与其他语言不一样。
//:整数除,等于其他语言的整数类型相除。
%:取模运算
**:与pow(x,y)的效果一致。 x ∗ ∗ y = = x y x**y==x^y x∗∗y==xy
10/3 #3.3333
10//3 #3
10%3 #1
二元运算符:+=、-=、*=、/=、//=、%=、**=
x = 10
x**=3 #x==1000
字符串运算
- 字符串的表示 ‘…’、“…”、‘’‘…’‘’
单引号、双引号、三引号都可以表示字符串,虽然冗余,但是便于嵌套使用。
- 字符串切片拓展 [M:N:K]
M、N都是表索引,而K是表数量。
K的作用表示步长,只有该步长的索引可以被取出。
形象解释:“从开始索引先取一个,然后每走K步取走到的那个值,知道结束索引的前一个。”
*当K等于-1时表示逆序取出。
str1 = "〇一二三四五六七"
str2 = str1[::2] #"〇二四六"
str3 = str1[::-1] #"七六五四三二一〇"
- 转义符 \
转义符“\”表示取消下一个字符的特殊含义。可用于字符串嵌套。
特殊字符:
“\n”:换行,但注意,print中本身结束时就有换行了。
“\t”:相当于一个tab键位。
“\r”:回到本行行首。
- 操作符 +、*、in
+操作符用于连接两个字符串。
*操作符用于必须得有一个操作数为数字,另一个操作数为字符串,表示赋值n次此字符串。
in: x i n s x\ in\ s x in s用于判断x是否属于s的子串,若是则返回True,不是则返回False。
- 处理字符串的函数
len():判断字符串的长度。
str():与eval()函数对应且相反,将输入的参数变为字符串。如str(123)==>“123”
hex():将参数转化为16进制。
oct():将参数转化为8进制。
- 字符串作为对象提供的方法
str.lower():将字符串全部转为小写。
str.upper():将字符串全部转为大写。
str.split(sep):字符串分割字符串,以字符串中的"sep"字符为界分割,返回一个列表。注意,sep字符不会载入到列表中。
str.count(sub):计算sub子串在str字符串中出现的次数。
str.replace(old,new):将字符串中的old子串替换成new子串,注意修改与返回的都是副本。
str.center(width[,fillchar]):将字符串根据宽度居中,fillchar字符可选,如果不写则默认填充空字符,返回的是副本,不会修改原字符串。
str.strip(chars):去掉字符串中左右出现的chars中出现的字符。
str1 = "= python= ="
strs = str1.strip(" =")
print(strs) #python
print(str1) #= python= =
str.join(iter):
注意,不要反了。在iter字符串中,除了最后一个元素,每一个元素后面都加上str字符。
str1 = ","
strs = str1.join("python")
print(strs)
print(str1)
- 槽 {} 与字符串格式化 .format() :槽应与format()方法一起使用,也只有开槽才能使用format方法。
默认情况:槽中不使用参数
默认format()中的参数依次填在槽中。
str = "{}一二三四{}六七".format("〇","五") #〇一二三四五六七
str = "{}一二三四{}六七{}".format("〇","五") #槽开多了,format参数没跟上,会报错。
str = "{}一二三四五六七".format("〇","五") #〇一二三四五六七,槽开少了,不会报错。
槽中使用参数{<参数序号>:<格式控制标记>}
-
槽中若有参数序号则在format函数的参数中寻找对应序号的参数填充。若没有参数序号则默认依次填充。
-
若出现":“,则”:"后面的表示控制,控制如下:
注意:使用后三种要保证format的参数是数字类型。

examples:
{:20}:若只有一个字符,则表宽度,毕竟没有宽度,填充和对齐也就没有意义了。本例表示宽度为20,默认左对齐,填充空格。
{:=^20}:宽度为20,原字符居中对齐,用=填充。
“{:*^20,.2f}python”.format(123456) #*****123,456.00*****python
time库
- 获取time
time.time():获取时间戳,是一个浮点数,从1970.1.1开始到现在的秒数。
time.ctime():获取一个程序员易读的时间。
time.gmtime():获取一个计算机容易操作的时间变量。
- 时间格式化
time.strftime(tpl, ts)
关于ts
ts是通过time.gmtime()获取到的时间变量。
关于tpl
tpl是格式化模板字符串,用来指示输出的格式。由时间控制符加其他字符组成,时间控制符包含如下:
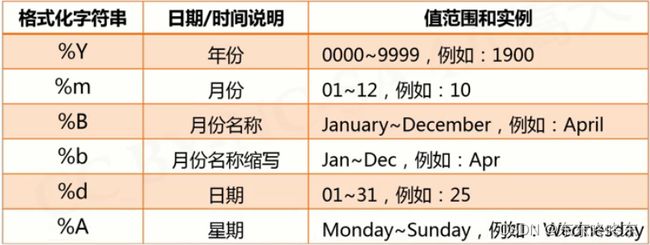

import time
t = time.gmtime()
str = time.strftime("%Y.%m.%d\n%H:%M:%S,\n今天是%A",t)
print(str)
#2023.01.01
#09:02:40,
#今天是Sunday
*注意,这里%H获取到的小时是UTC时区,在中国要多加8个小时。如果要获取中国时间,其实strftime可以直接不要第二个参数,直接使用模板字符串。
time.strptime(str, tpl):
tpl定义如上
关于str
str是字符串形式的时间值。使用strptime可以将此字符串时间值当做参数输入,会转化为一个内部时间变量,然后又根据时间模板字符串输出。
- 程序计时
使用 time.perf_ counter() 可以获得精确时间计数值,单位时间为秒,要想获得程序执行的时间,应该连续使用time.perf_counter()函数然后相减得到。
begin = time.perf_counter()
end = time.perf_counter()
print(end-begin)
使用 time.sleep(s) 可以使程序休眠s秒。
或、与、非
python中使用的并不是II、&&、!
而是使用and、or、not。
当然不等于还是使用"!=",逻辑非才使用not。
程序异常处理
- 使用try+except组合来捕获异常。
#执行try中的语句,当遇到异常时跳转执行except中的语句2
try:
#<语句1>
except:
#<语句2>
- 更进一步,可以细分错误类型:
try:
#<语句1>
except NameError :
#<语句2>
异常名字NameError是python中已经定义的,无需自己定义。
- 异常处理的高级使用:
try+except+else+finally配合使用
try:
#<语句1>
except:
#<语句2>
else:
#<语句3>
finally:
#<语句4>
#执行语句1,如果异常则执行语句2,没有异常则执行语句3,不管怎样都会执行语句4。等于说是在语句2和语句3中选择一个。
ifelse紧凑形式
ifelse紧凑形式只能作为表达式使用
a = eval(input())
b = 1 if a > 0 else -1
#输入10 输出1
continue、break
python中依旧使用continue、break作为循环保留字。
continue表示跳出本次循环。
break表示结束整个循环。
循环与else
在for循环和while循环中,如果没有遇到break,则正常退出。
配合上else,可以作为正常退出的奖励。
for i in range(3):
#<语句1>
else:
#<语句2>
random库的使用
- 引入
import random
- 基本随机数函数
random.random()
random()函数会基于当前计算机时间来产生一个随机数。
random.seed():产生“确定”的随机数
使用seed()函数可以函数设置一个种子,后续的random()就会基于这个种子来产生随机数。相同的种子后续依次调用random()得到的随机数是一样的。
*因此当想要复现程序时才使用种子函数,否则若只是想要产生一个随机数直接使用random()即可。
- 拓展随机数函数



函数
- 关键字为def
- 是否有参数是可选的,但是没有参数时括号仍要保留。
- 是否有return也是可选的。
关于默认参数
可以预设参数等于某个值,当函数调用时,若用户有输入时该参数赋值为该值,否则赋值为默认值。
def fact(n,m=1):
s = 1
for i in range(1,n+1):
s *= i
return s//m
关于不确定参数数量
用户可以输入不确定个参数的数量,在形参中设置*items后由items作为列表全部接收。
def fact(n, *items):
s = 1
for i in range(1, n+1):
s *= i
for item in items:
s *= item
return s
关于参数传递
- 可以按照默认位置传递。
- 可以指定参数传递。

关于返回值
若返回多个值可以使用逗号隔开。调用的函数会得到一个元组。
列表与指针
在python中,列表是用指针实现的,也就是在一个函数中修改一个列表的值,被修改的列表的值也会影响到函数的外部。
特点:
但若函数中又创建了一个同名列表(同名指针),那么该列表的修改不会影响到外面。
#指针修改
ls = ["A","B"]
def fun(con):
ls.append(con)
return
fun("C")
print(ls) #['A', 'B', 'C']
#在函数中重新创建了一个,因此不会修改
ls = ["A","B"]
def fun(con):
ls = ["A","B"]
ls.append(con)
print(ls) #['A', 'B', 'C']
return
fun("C")
print(ls) #['A', 'B']
lambda函数
lambda函数其实就是函数的紧凑形式,将函数写成一行的形式:<函数名> = lambda <参数>:<表达式>
注意,lambda函数的表达式不仅是执行也是返回。
fun = lambda x,y : x+y
print(fun(10,20)) #30
PyInstaller库
PyInstaller库能够将python文件转换成可执行文件。
PyInstaller是在.py文件所在的命令行中使用的:PyInstaller -F <文件名>
其他命令行参数:
-h:查看帮助
-i:设置可执行文件图标
PyInstaller -i curve.ico -F afunction.py
集合
集合类型的定义与数学中的集合概念一致。
-
集合中元素是唯一的,不存在相同的元素,如果故意存储相同的元素也会被过滤到剩一个。
-
集合之间的元素是无序的。
-
集合之间的元素天然要求不可修改。
集合的表示与建立
集合用{}表示,元素之间用逗号隔开。
集合建立使用{}或者set()建立。注意,建立空集合必须使用set()。
jh = set("python")
print(jh) #{'y', 't', 'p', 'n', 'h', 'o'}
集合的运算
6个运算:并、减、交、补、包含、子集
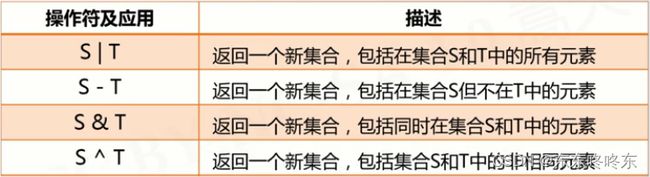

集合的增强操作
增强操作直接更新S。

集合的方法
- 增
set.add():增加数字或字符串类型都可以直接写。每次只能添加一个。
set.update():增加字符串类型可以直接写,增加数字类型要用列表包裹。可以添加多个。
nums = {1,2,3,4,5,6,7}
#nums.add(8)
#nums.add('8')
#nums.update([8])
#nums.update('8')
- 删
set.remove(x):移除集合中的x,若集合中没有x,则报错。
set.discard(x):移除集合中的x,若集合中没有x,也不会报错。
set.clear():清除集合中的所有元素。
- 副本
set.copy():返回集合的一个副本,等于浅拷贝。
- 长度
len(set):返回集合的长度。
- 查找
x in set:判断元素x是否在集合中。
x not in set:判断元素x是否不在集合中。
- 取出
set.pop():随机取出一个元素。
集合类型应用场景

序列类型
序列类型包括三种:字符串类型,元组类型,列表类型。
序列类型通用
之前关于字符串的属性、方法都是序列类型通用的,如:
正向索引,反向索引,in,not in,+号连接,*号复制n倍,[i]通过索引获取元素,[i:j:k]切片操作
len(s)获取长度,min(s)返回最小元素,max(s)返回最大元素,s.index(x)返回元素x第一次出现的位置。
元组
元组类型使用()或者tuple()创建。
注意当同时赋予多个值时即表示使用元组类型。
tup = 1,2,3
print(tup) #(1, 2, 3)
列表


列表排序:
list.sort()改变原列表,无返回值。
sorted(list)不改变原列表,返回一个排序后的列表。
字典
字典的表示:{“键”:“值”, “键”:“值”, “键”:“值”, “键”:“值”,}
字典的功能:

jieba库
jieba库是第一个第三方库,能够将一个字符串进行分词。显然适用于搜索引擎。


文件
文件类型:文本文件,二进制文件
文件在计算机中都是以0、1来存储的,
但若有统一编码的,称为文本文件,如使用UTF-8编码的。
如果有没统一编码的,则称为二进制文件。
读文件
读文件使用open()函数,open()函数的使用见下图。

文件名路径注意事项:
由于windows中的路径由’\‘隔开,而python中此字符又表示为转义符,因此在写路径时要么使用’/‘即"除号"来代替,要么使用两个转义符来’\\'来代替。
文件打开:

文件关闭:
文件关闭只有一句:文件句柄.close()
文件读取:
-
.read():读入文件全部为字符串,如果传入参数则读取前n个字符。 -
.readline():读入文件的全部的行为列表,如果传入参数则只读取前n行。 -
.readlines():读入文件的全部行作为列表。 -
直接for in遍历文件句柄,则会逐行遍历文件。
文件写入:
.write(s):向文件写入一个字符或者一个字符串。至于写在哪里是由打开模式决定的。 .writelines(lines):将一个元素全为字符串的列表写入文件。 .seek(offset):改变当前文件操作指针的位置,0-回到文件开头,1-当前位置,2-文件结尾。
map函数
map函数的使用如下:map(A,B),表示将B中的每一个元素都作为参数运行A函数。
一维数据
一维数据读入:从文件中获取字符串然后分割成列表。使用str.split()函数。
一维数据写出:使用’ '.join(str)将列表会写成字符串然后写入文件。
二维数据与csv
CSV是用逗号分割存储值的一种方式,每行都是一个一维数据,没有空行。例子如下:
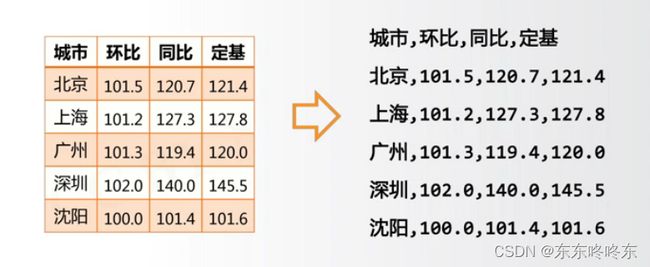
从.CSV文件中读入数据
fo = open(fname) #默认打开方式为读
ls = []
for line in fo:
line.replace('\n','') #把读入的每行的最后一个换行符给替换掉。
ls.append(line.split(',')) #line.split(',')将每行读入的字符串按','切成一个数组,然后该数组再被append()被添加进ls中。
将数据写入.CSV文件中
ls = [[],[],[]]
f = open(fname,'w')
for item in ls:
f.write(','.join(item) + '\n') #获取每行元素然后用逗号拼接成一行字符串最后加上回车符写入文件。注意这里列表使用join方法要求列表中的每一个元素都是字符串。
f.close()
pip安装第三方库
命令如下:
安装:pip install <第三方库>
更新:pip install -U <第三方库>
卸载:pip uninstall <第三方库>
下载但不安装:pip download <第三方库>
显示信息:pip show <第三方库>
列出当前已经安装的第三方库:pip list
os库
os库也是标准库之一。os库三大功能:路径操作、进程管理、环境参数。
路径操作
通过使用os库中的path子库的各种方法来进行路径操作。
进程管理
os库中的system()方法。
环境参数
具体参考库使用手册。