openFoam代码读懂笔记
1. sed口令
sed -i "/method/s/manual/simple/g" decomposeParDict是不是指:将文件decomposeParDict内method那一行的manual换成simple
sed -i 就是直接对文本文件进行操作的
sed -i 's/原字符串/新字符串/' /home/1.txt
sed -i 's/原字符串/新字符串/g' /home/1.txt
这两条命令的区别就是,看示例吧
这是1.txt的内容
#cat 1.txt
d
ddd
#ff再看执行这两条命令的区别吧
只换了每一行的第一个d
sed -i 's/d/7523/' /home/1.txt
执行结果
7523
7523dd
#ff全换了
sed -i 's/d/7523/g' /home/1.txt
执行结果
7523
752375237523
#ff更多sed
https://blog.csdn.net/qq_33468857/article/details/84324609
需要学习更多正则化表达
https://www.runoob.com/regexp/regexp-rule.html
https://www.freesion.com/article/3158625799/
2. mpirun口令 ls -1口令 wc -l口令 grep口令 xargs口令 awk口令
mpirun -np $(ls -1 | grep processor | wc -l) ./$EXE -parallel意思是不是:参数-parallel并行计算./$EXE程序(可执行程序,如icoFoam),进程数(核心数量)为(ls -1 | grep processor | wc -l)
ls -1将文件全列出来,然后grep processor查找含有processor的文件按行列出来,然后wc -l数行数
mpirun --hostfile -np -parallel > log & >log& 输出日志文件log
ls -1 -d processor* | grep -v ini | xargs rm意思是不是:将当前文件夹下前缀为processor的文件按一个文件一行地列出来,然后找出不含ini的文件,然后全部删掉
-d指当前文件夹,processor*指processor为前缀的文件名,xargs rm删掉
mpirun
基本格式
mpirun [mpirun-options…] [options…]其中 [mpirun-options…], 主要选项如下:
-np 要加载的进程个数。
-p4pg 按照pgfile文件中的要求加载用户进程。pgfile文件描述用户在那些结点上加载什么样的用户进程。
ls
ls 则一行空格全列出来
ls -1 list one file per line,也就是只列出文件名
ls -l是Linux和unix命令,意思指以长格式的形式查看当前目录下所有可见文件的详细属性。
举例:
ls -1
apache-maven-2.2.1-bin.tar.gz
apache-tomcat-6.0.30
apache-tomcat-6.0.30.zip
jdk-6u5-linux-x64.bin
jetty-6.1.14-fgw-aps.zip
jetty-distribution-7.3.0.v20110203.zip
moni2.tar.gz
ouput.log
status.sh
ls -l
total 149780
-rw-r--r-- 1 root root 2840961 Aug 7 2009 apache-maven-2.2.1-bin.tar.gz
drwxr-xr-- 2 root root 4096 Jul 5 10:45 apache-tomcat-6.0.30
-rw-r--r-- 1 root root 6908320 Jun 30 17:51 apache-tomcat-6.0.30.zip
-rwxr-xr-- 1 root root 63724381 Jun 30 17:51 jdk-6u5-linux-x64.bin
-rw-r--r-- 1 root root 24942637 Jul 11 16:59 jetty-6.1.14-fgw-aps.zip
-rw-r--r-- 1 root root 5910895 Apr 3 2011 jetty-distribution-7.3.0.v20110203.zip
-rw-r--r-- 1 root root 48835553 Jun 30 17:51 moni2.tar.gz
-rw-r--r-- 1 root root 211 Nov 14 16:35 ouput.log
-rw-r--r-- 1 root root 164 Oct 18 15:19 status.shwc
Linux wc命令用于计算字数。
利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法:
wc [-clw][--help][--version][文件...]参数:
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 显示行数。
- -w或--words 只显示字数。
- --help 在线帮助。
- --version 显示版本信息.
ls|wc -l与ls -l|wc -l的区别就是ls-l|wc -l多了显示total的一行。
ls|wc -l的结果是文件个数,ls -l|wc -l的结果是文件个数+1,也就是它计算的是行数
grep processor 查看逻辑CPU
grep -v 命令排除输出
cat test.log | grep "login"|grep -v "deviceType"上面的命令的意思是:找出test.log中包含login信息的,且没有deviceType这个字段的。
xargs口令
xargs(英文全拼: eXtended ARGuments)是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。xargs是给命令传递参数的一个过滤器,可以将前一个命令产生的输出作为后一个命令的参数
用 rm 删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long. 用 xargs 去避免这个问题。xargs将产生的长串文件列表拆散成多个子串,然后对每个子串调用rm。
linux中,&和&&,|和||
在linux中,&和&&,|和||介绍如下:
& 表示任务在后台执行,如要在后台运行redis-server,则有 redis-server &
&& 表示前一条命令执行成功时,才执行后一条命令 ,如 echo '1‘ && echo '2'
| 表示管道,上一条命令的输出,作为下一条命令参数,如 echo 'yes' | wc -l
|| 表示上一条命令执行失败后,才执行下一条命令,如 cat nofile || echo "fail"
\ 表示下一行继续
$1在shell中称为“位置参数”,表示传入的第1个参数(第1个入参)
其他变量说明:
Linux——$1、$#、$@、$0、$1、$2_u012114090的博客-CSDN博客
并行计算mpi总结
并行计算:MPI总结_JacksonKim的博客-CSDN博客_mpi
awk口令
Linux awk 命令 | 菜鸟教程 (runoob.com)
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号例子:log.txt
2 this is a test 3 Are you like awk This's a test 10 There are orange,apple,mongo
# 每行按空格或TAB分割,输出文本中的1、4项
$ awk '{print $1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
# 格式化输出
$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo3. decomposePar工具
decomposePar -force -cellDistIt decomposes a case to be run in parallel. The syntax of the command is the following
decomposePar [-cellDist] [-fields] [-filterPatches] [-copyUniform] It requires a dictionary named decomposeParDict is present in the system subdirectory of the case. 分解求解域,decomposePar程序相关的字典文件:decomposeParDict
OpenFOAM采用的并行计算方法是区域分解法
decomposeParDict文件中四种分解方法(simple, hierarchical, scotch, manual)都需要指定一些参数Coeffs,method来指定用哪种方法。
decomposePar会在算例文件的目录下为每一个核产生一个子文件夹,processorN(N为0, 1, ...)
DecomposePar - OpenFOAMWiki
4. reconstructPar工具
将分割后的场和网格重新合并,简单地以命令行来运行它即可
reconstructPar [-constant] [-latestTime] [-time time] 也可以单独对分割后的求解域的一部分进行后处理,即将各处理器文件夹看作一个独立的算例
paraFoam -case processor1ReconstructPar - OpenFOAMWiki
5. 编译
g++编译:

g++ rewrite.cpp -o rewrite意思是不是:用g++将rewrite.cpp编译成文件名为rewrite的文件
-o:指定生成可执行文件的名称。使用方法为:g++ -o afile file.cpp file.h ... (可执行文件不可与待编译或链接文件同名,否则会生成相应可执行文件且覆盖原编译或链接文件),如果不使用-o选项,则会生成默认可执行文件a.out。
-c:只编译不链接,只生成目标文件。
-g:添加gdb调试选项。
C/C++完整编译过程详解
【转载】C/C++完整编译过程详解 - ericling - 博客园
gcc/g++常用编译选项:
gcc/g++常用编译选项_clozxy的专栏-CSDN博客
6. rm口令
1、rm -r :rm -r 只能用于删除文件,不能用于删除文件夹。
2、rm -R:rm -R既能用于删除文件,也能用于删除文件夹。
7. nohup与&后台运行
nohup mpirun -np `echo processor* | wc -w` -machinefile mf \
./$EXE -parallel > log 2>&1 &意思是不是: 不挂断地(nohup)后台(nohup...&)并行(-parallel)运算./$EXE(如icoFoam),核数为`echo processor* | wc -w`,机子文件为mf,信息输出到log文件,并且将将标准错误信息转变成标准输出。
echo "hello world"|wc -w 将会输出2,表示有两个英文单词,w即为word的缩写,表示统计英文单字的意思
其中 0、1、2分别代表如下含义:
0 – stdin (standard input)
1 – stdout (standard output)
2 – stderr (standard error)
nohup ./startWebLogic.sh >out.log 2>&1 &(nohup+最后面的&) 是让命令在后台执行
>out.log 是将信息输出到out.log日志中
2>&1 是将标准错误信息转变成标准输出,这样就可以将错误信息输出到out.log 日志里面来。
machinefile表示机子文件
nohup用途:不挂断地运行命令。
语法:
nohup Command [ Arg … ] [ & ]&用途:在后台运行
一般两个一起用
nohup command &查看运行的后台进程
jobsps -ef终止后台运行
kill -9 进程号结束程序
Ctrl + C
-
一般是用 CTRL + C 来结束当前命令
-
有时候CTRL + C 不好使,那就打开另一个终端,通过 ps 命令找到进程的 pid ,然后使用 kill 命令干掉他
在 Linux 中如何结束进程 | 《Linux就该这么学》
退出系统
exitnohup和&后台运行,进程查看及终止 - 慕尘 - 博客园
显示系统中各个进程的资源占用状况
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
top结束top:ctrl+c
Linux top命令详解 - 牛奔 - 博客园
查看文件内容:vi
vi mf查看mf文件内容
8. shell文件结构
开头:
#!/bin/bash#!/bin/sh表示本脚本由/bin/路径的sh程序来解释
#通常用作注释,但是#!放在一起就标志着这是一个shell script,其后的路径指出了用来解释这个script的程序。
如果一个script只是一些普通linux指令的堆砌。那么#!可以略去不写。但通常我们遇到的都不是这种情况。
如果这个script中包含一些自定义的程序组件,比如说函数,变量等,#!便需要标注。
9. boundaryField边界条件 zeroGradient fixedValue
zeroGradient是无滑移边界条件,对压力指零梯度
fixedValue则是固定值
最明显的区别是:zerogradient边界上的值可以随着计算不断变化,fixedvalue则一直不变。一般开放的空气等等情况常用zerogradient,固定数值的速度边界或者压强边界用fixedvalue。
10. 执行权限修改chmod
Linux chmod(英文全拼:change mode)命令是控制用户对文件的权限的命令
Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)。
Linux下文件的权限类型一般包括读,写,执行。对应字母为 r、w、x。
语法:
chmod [-cfvR] [--help] [--version] mode file...chmod也可以用数字来表示权限如 :
chmod 777 file这三个数字777,或者abc,其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。
常用形式:
chmod 777 [filename]
chmod 755 [filename]
chmod a+x [filename]
chmod u+r [filename]
r:read------4
w:write------2
x:execute------1
d: ----------- 0
X:我也不知道怎么用
(rwx作为一组出现,如果有某个权限,其标志为1,否则为0,例如r-x为101 、rwx为111,101转化成十进制为5,111为7)
a:all--所有用户
u:user----文件拥有着
g:group----与user同属一个group的其他user
o:other-----其他group的user
整个文件夹和子文件均修改
chmod -Rf 777 test
or
chmod -R 777 testtest文件夹以及其所有子文件的权限都被设置为了777
查看当下文件夹所有文件的权限
ll更多:
Linux chmod 命令 | 菜鸟教程
11. fluentMeshToFoam和fluent3DMeshToFoam checkMesh
导入fluent网格到openFoam
fluentMeshToFoam is the old code. It can handle 2D Fluent meshes but struggles with some 3D meshes (for example, meshes with hanging nodes)
fluent3DMeshToFoam is newer. Can handle only 3D meshes, but it does this much better than the old one. If you have a 3D mesh, this has to be preferred.
Comparing the source code for fluentMeshToFoam and fluent3DMeshToFoam in OpenFOAM 1.4.1 and 1.5, the following main differences can be found:
- fluentMeshToFoam supports 2D and 3D Fluent meshes, while fluent3DMeshToFoam only supports 3D.
- fluent3DMeshToFoam deals with hanging nodes.
- fluentMeshToFoam has the options to write sets and zones, while fluent3DMeshToFoam has the option to ignore a cell groups and face groups.
- fluentMeshToFoam can only handle the following 3D cell types: tet, hex, pyramid, prism
- fluent3DMeshToFoam can handle internal walls/patches, or at least it looks like it does. fluentMeshToFoam requires a workaround: Howto importing fluent mesh with internal walls
Fluent3DMeshToFoam - OpenFOAMWiki
checkMesh - Checks validity of a mesh.
CheckMesh - OpenFOAMWiki
12. linux系统环境配置
export命令显示当前系统定义的所有环境变量 echo $PATH命令输出当前的PATH环境变量的值
使用export命令直接修改PATH的值,配置MySQL进入环境变量的方法:
export PATH=/home/uusama/mysql/bin:$PATH
# 或者把PATH放在前面
export PATH=$PATH:/home/uusama/mysql/bin终端或者修改文件(如 .bashrc)
生效方法:使用相同的用户打开新的终端时生效,或者手动source ~/.bashrc生效
Linux环境变量配置 | 《Linux就该这么学》
13. boundary type里面的patch和wall的区别
patch
是基本的 patch 类型,不包括关于网格几何或拓扑的信息 (wall 边界有),例如:inlet 或 outlet.
wall
壁面,特别需要处理的一种边界或 patch 。如湍流模型中的 wall function,计算湍流时,需要用到壁面函数时,壁面必须指定为 wall,这时,wall 所属的网格的中心到 wall 的距离可以存储下来做计算。
这两种 patch 的区别不在于力,而是对于模型的一种处理方式。
patch
The basic patch type for a patch condition that contains no geometric or topological information about the mesh (with the exception of wall), e.g. an inlet or an outlet.
wall
There are instances where a patch that coincides with a wall needs to be identifiable as such, particularly where specialist modelling is applied at wall boundaries. A good example is wall turbulence modelling where a wall must be specified with a wall
patch type, so that the distance from the wall of the cell centres next to the wall are stored as part of the patch.
patch 和 wall 的区别 - OpenFOAM - CFD Academy (CFDwired)
4.2 Boundaries
14. dimensions in openFoam

dimensions [1 -3 -1 0 0 0 0]; 即kg/m3/s,应该是个质量源项,或者质量传递(Ksl文件在算例里)
15. linux窗口解压 zip和tar
zip:
unzip metallic-container.zip -d my_zipunzip -o -d /home/sunny myfile.zip把myfile.zip文件解压到 /home/sunny/
-o:不提示的情况下覆盖文件;
-d:-d /home/sunny 指明将文件解压缩到/home/sunny目录下;
查看压缩文件中的内容而不解压压缩文件
unzip -l zipped_file.ziptar:
tar zxvf text.tar.gz -C /tmp复制解压遇到的报错:
cp: cannot create regular file `/home/yyxie/openFoam_code/Test_20210817/TEMP-MPI3/pic/res.0138.tif': Input/output error
cp: cannot open `/home/yyxie/TEMP-MPI3/pic/res.0273.tif' for reading: Input/output error
原因不详,可能是计算节点没有调试好,或者计算节点环境不对。可以问问计算节点管理员。
16. C++代码
C++中的~
“~”这个符号所代表的函数为析构函数,
在C++的面向对象编程中,都会有一个以上的构造函数形如CSerial();
和一个析构函数形如~CSerial();
按位取反操作
按位取反运算是单目运算,用来求一个位串信息按位的反,即哪些为0的位,结果是1,而哪些为1的位,结果是0。例如, ~7的结果为0xfff8。
sprintf
sprintf指的是字符串格式化命令,函数声明为 int sprintf(char *string, char *format [,argument,...]);,主要功能是把格式化的数据写入某个字符串中,即发送格式化输出到 string 所指向的字符串。sprintf 是个变参函数。使用sprintf 对于写入buffer的字符数是没有限制的,这就存在了buffer溢出的可能性。解决这个问题,可以考虑使用 snprintf函数,该函数可对写入字符数做出限制。
fopen
open的函数原型为: FILE *fopen(const char *filename, const char *mode);其功能是使用给定的模式 mode 打开 filename 所指向的文件。文件顺利打开后,指向该流的文件指针就会被返回。如果文件打开失败则返回 NULL,并把错误代码存在 error 中。该函数位于C 标准库
| r |
以只读方式打开文件,该文件必须存在。 |
指针
对于指针boxptr
*boxptr 为值
boxptr 为地址
对于普通变量box
box 为值
&box 为地址C++ 指针 | 菜鸟教程
指针可以++操作,ptr++指加多4个字节
#pragma once
#pragma once是一个比较常用的C/C++杂注,只要在头文件的最开始加入这条杂注,就能够保证头文件只被编译一次。
#pragma once是编译器相关的,有的编译器支持,有的编译器不支持,具体情况请查看编译器API文档,不过现在大部分编译器都有这个杂注了。
#ifndef,#define,#endif是C/C++语言中的宏定义,通过宏定义避免文件多次编译。所以在所有支持C++语言的编译器上都是有效的,如果写的程序要跨平台,最好使用这种方式。
方式一:
#ifndef _SOMEFILE_H_
#define _SOMEFILE_H_
.......... // 一些声明语句
#endif
方式二:
#pragma once
... ... // 一些声明语句makefile中的条件判断ifeq, ifneq, ifdef, ifndef
ifeq
ifeq (;, ;)
ifeq ';' ';'
ifeq ";" ";"
ifeq ";" ';'
ifeq ';' ";" 比较参数“arg1”和“arg2”的值是否相同。
ifneq
ifneq (;, ;)
ifneq ';' ';'
ifneq ";" ";"
ifneq ";" ';'
ifneq ';' ";" 其比较参数“arg1”和“arg2”的值是否相同,如果不同,则为真。和“ifeq”类似。
ifdef
ifdef ; 如果变量
还是来看两个例子:
示例一:
bar =
foo = $(bar)
ifdef foo
frobozz = yes
else
frobozz = no
endif
示例二:
foo =
ifdef foo
frobozz = yes
else
frobozz = no
endif 第一个例子中,“$(frobozz)”值是“yes”,第二个则是“no”。
ifndef
ifndef ;
这个我就不多说了,和“ifdef”是相反的意思。
记得endif
makefile中的条件判断ifeq、ifneq、ifdef_nyist327的专栏-CSDN博客
17. 边界条件
第一类边界条件(Dirichlet boundary):
给出未知函数在边界上的数值;
第二类边界条件(Neumann boundary):
给出未知函数在边界外法线的方向导数;
第三类边界条件:
给出未知函数在边界上的函数值和外法线的方向导数的线性组合。
传热例子:
第一类边界条件(也叫狄利克雷边界条件),给定边界上的温度值;
第二类边界条件(也叫诺依曼边界条件),给定边界上温度的梯度值,或者说给定边界上的热流密度;
第三类边界条件,给定边界上温度的梯度值与边界温度的关系。18. setFields openFOAM自带
位于system/setFieldsDict
OpenFOAM中非均匀初始场的设定_苏军伟_新浪博客
19. gcc编译参数-fPIC -std icpc是intel编译器
1. c++实际上是只编译源文件的
2. c++源文件中在包含头文件的地方,将被包含头文件中的代码全部拷贝进去进行编译;
3. 包含头文件是有顺序的,因为包含头文件的顺序意味着该头文件在源文件进行展开的顺序。
CC := $(MPIDIR)/bin/mpiicpc -fPIC -std=c++11linux bash shell之变量替换::=句法、=句法、:-句法、-句法、=?句法、?句法、:+句法、+句法
= 是最基本的赋值
:= 是覆盖之前的值
?= 是如果没有被赋值过就赋予等号后面的值
+= 是添加等号后面的值:=句法
例子:这些代码开始的冒号是一个正确执行非活动任务的shell命令。
: ${VAR:=”some default”}:=句法表示VAR变量将会和“some defalut”字符串进行比较。
在这个表达式中,如果变量VAR还没有被设置,那么“:=”之后表达式的值将被赋给它,这个值可能是一个数字,一个字符串,或者是另外一个变量。
系统中的脚步可能需要将多个变量设置成默认值。程序员可以在一行中给多个变量设置默认值,而不是编码一组变量替换,这样也使得代码更加紧凑、易读。下面的例子包含了程序员需要执行的各种替换操作。第一个默认值是一个显示的串,第二个是一个显示的整数,第三个是一个已定义的变量。
: ${VAR:=”some default”} ${VAR2:=42} ${VAR3:=$LOGNAME}username=””
echo “${username:=$LOGNAME}”在使用“:=”进行比较时,username变量已经被定义了,但是它的值为空。因此,这里对echo命令使用了变量LOGNAME的值,即设置变量username的值为LOGNAME的值。
有了这个特殊的句法,只有当变量username已被定义,而且有一个实际的非空值时,变量username才会被设置为变量LOGNAME的值。
和前例的主要不同是使用活动命令(echo)而不是被动的冒号来设置变量的默认值,当活动命令被调用时,默认赋值仍然会执行,并输出显示结果。
Makefile 中:= ?= += =的区别 - wanqi - 博客园
linux bash shell之变量替换::=句法、=句法、:-句法、-句法、=?句法、?句法、:+句法、+句法 - fhefh - 博客园
-fPIC
-fPIC 作用于编译阶段,告诉编译器产生与位置无关代码(Position-Independent Code),则产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载器加载到内存的任意位置,都可以正确的执行。这正是共享库所要求的,共享库被加载时,在内存的位置不是固定的。
gcc -shared -fPIC -o 1.so 1.c这里有一个-fPIC参数
PIC就是position independent code
PIC使.so文件的代码段变为真正意义上的共享
如果不加-fPIC,则加载.so文件的代码段时,代码段引用的数据对象需要重定位, 重定位会修改代码段的内容,这就造成每个使用这个.so文件代码段的进程在内核里都会生成这个.so文件代码段的copy.每个copy都不一样,取决于 这个.so文件代码段和数据段内存映射的位置.
也就是
不加fPIC编译出来的so,是要再加载时根据加载到的位置再次重定位的.(因为它里面的代码并不是位置无关代码)
如果被多个应用程序共同使用,那么它们必须每个程序维护一份.so的代码副本了.(因为.so被每个程序加载的位置都不同,显然这些重定位后的代码也不同,当然不能共享)
我们总是用fPIC来生成so,也从来不用fPIC来生成.a;fPIC与动态链接可以说基本没有关系,libc.so一样可以不用fPIC编译,只是这样的so必须要在加载到用户程序的地址空间时重定向所有表目.
-std
用GCC编译代码时候后面带有-std=c++1z 的选项,这是指定c/c++的标准.具体的标准如下,详细信息可以看引用里面的详细说明

Standards (Using the GNU Compiler Collection (GCC))
A revised ISO C++ standard was published in 2011 as ISO/IEC 14882:2011, and is referred to as C++11; before its publication it was commonly referred to as C++0x. C++11 contains several changes to the C++ language, all of which have been implemented in GCC. For details see C++ Standards Support in GCC- GNU Project. To select this standard in GCC, use the option -std=c++11.
gcc编译器 CFLAGS 标志参数说明
CFLAGS := -m64 -Dlinux64 -DWM_DP -O3 -DNoRepository -ftemplate-depth-100 \
-Wall -Wno-unused-functionCFLAGS 表示用于C编译器的选项
CXXFLAGS 表示用于C++编译器的选项
这两个变量实际上涵盖了编译和汇编的两个步骤
64位版:加上 -m64 参数,生成64位的代码。
-O 选项告诉 GCC 对源代码进行基本优化。这些优化在大多数情况下都会使程序执行的更快。 -O2 选项告诉 GCC 产生尽可能小和尽可能快的代码。 如-O2,-O3,-On(n 常为0--3); -O 主要进行跳转和延迟退栈两种优化; -O2 除了完成-O1的优化之外,还进行一些额外的调整工作,如指令调整等。 -O3 则包括循环展开和其他一些与处理特性相关的优化工作。 选项将使编译的速度比使用 -O 时慢, 但通常产生的代码执行速度会更快。
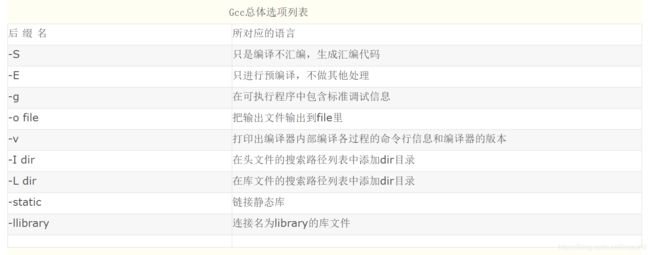


还有好多。。
CFLAGS详解_m0_37170593的博客-CSDN博客_cflags
Makefile:GCC CFLAGS变量和LDFLAGS变量_flag的小鱼塘的博客-CSDN博客
-l参数和-L参数 -include和-I参数
-l参数(这个是el)就是用来指定程序要链接的库(库文件在/lib、/usr/lib和/usr/local/lib下),-l参数紧接着就是库名,那么库名跟真正的库文件名有什么关系呢?就拿数学库来说,他的库名是m,他的库文件名是libm.so,很容易看出,把库文件名的头lib和尾.so去掉就是库名了。好了现在我们知道怎么得到库名了,比如我们自已要用到一个第三方提供的库名字叫libtest.so,那么我们只要把libtest.so拷贝到/usr/lib里,编译时加上-ltest参数,我们就能用上libtest.so库了(当然要用libtest.so库里的函数,我们还需要与libtest.so配套的头文件)。
放在/lib和/usr/lib和/usr/local/lib里的库直接用-l参数就能链接了,但如果库文件没放在这三个目录里,而是放在其他目录里,这时我们只用-l参数的话,链接还是会出错,出错信息大概是:“/usr/bin/ld: cannot find -lxxx”,也就是链接程序ld在那3个目录里找不到libxxx.so,这时另外一个参数-L就派上用场了(-L指定路径,-l指定具体库,配合使用),比如常用的X11的库,它放在/usr/X11R6/lib目录下,我们编译时就要用-L/usr/X11R6/lib -lX11参数,-L参数跟着的是库文件所在的目录名。再比如我们把libtest.so放在/aaa/bbb/ccc目录下,那链接参数就是-L/aaa/bbb/ccc -ltest。
-include用来包含头文件,但一般情况下包含头文件都在源码里用#include xxxxxx实现,-include参数很少用。
-I参数(这个是i)是用来指定头文件目录,/usr/include目录一般是不用指定的,gcc知道去那里找,但是如果头文件不在/usr/include里我们就要用-I参数指定了,比如头文件放在/myinclude目录里,那编译命令行就要加上-I/myinclude参数了,如果不加你会得到一个"xxxx.h: No such file or directory"的错误。-I参数可以用相对路径,比如头文件在当前目录,可以用-I.来指定。
gcc -l -L -I -include 参数_weixin_30284355的博客-CSDN博客
gcc的-l参数和-L参数和-include(转载) - 长缨在手_521 - 博客园
wildcard notdir patsubst
一般我们可以使用“$(wildcard *.c)”来获取工作目录下的所有的.c文件列表。
1、wildcard : 扩展通配符
2、notdir : 去除路径
3、patsubst :替换通配符
例子
建立一个测试目录,在测试目录下建立一个名为sub的子目录
$ mkdir test
$ cd test
$ mkdir sub
在test下,建立a.c和b.c2个文件,在sub目录下,建立sa.c和sb.c2 个文件
建立一个简单的Makefile
src=$(wildcard *.c ./sub/*.c)
dir=$(notdir $(src))
obj=$(patsubst %.c,%.o,$(dir) )
all:
@echo $(src)
@echo $(dir)
@echo $(obj)
@echo "end"
执行结果分析:
第一行输出:
a.c b.c ./sub/sa.c ./sub/sb.c
wildcard把 指定目录 ./ 和 ./sub/ 下的所有后缀是c的文件全部展开。
第二行输出:
a.c b.c sa.c sb.c
notdir把展开的文件去除掉路径信息
第三行输出:
a.o b.o sa.o sb.o
在$(patsubst %.c,%.o,$(dir) )中,patsubst把$(dir)中的变量符合后缀是.c的全部替换成.o,
然后输出。
或者可以使用
obj=$(dir:%.c=%.o)
效果也是一样的。
这里用到makefile里的替换引用规则,即用您指定的变量替换另一个变量。
它的标准格式是
$(var:a=b) 或 ${var:a=b}
它的含义是把变量var中的每一个值结尾用b替换掉a
Xlinker
-Xlinker选项
传递选项作为链接器的选项.您可以使用它来提供GCC不知道如何识别的特定于系统的链接器选项.
如果要传递一个带有单独参数的选项,则必须使用-Xlinker两次,一次用于选项,一次用于参数.例如,要传递-assert定义,必须编写-Xlinker -assert -Xlinker定义.编写-Xlinker"-assert definitions"不起作用,因为它将整个字符串作为单个参数传递,这不是链接器所期望的.
Makefile书写规则
规则包含两个部分,一个是依赖关系,一个是生成目标的方法。
在Makefile中,规则的顺序是很重要的,因为,Makefile中只应该有一个最终目标,其它的目标都是被这个目标所连带出来的,所以一定要让make知道你的最终目标是什么。一般来说,定义在Makefile中的目标可能会有很多,但是第一条规则中的目标将被确立为最终的目标。如果第一条规则中的目标有很多个,那么,第一个目标会成为最终的目标。make所完成的也就是这个目标。
foo.o: foo.c defs.h # foo模块
cc -c -g foo.c看到这个例子,各位应该不是很陌生了,前面也已说过,foo.o是我们的目标,foo.c和defs.h是目标所依赖的源文件,而只有一个命令“cc -c -g foo.c”(以Tab键开头)。这个规则告诉我们两件事:
规则的语法
targets : prerequisites
command
...
或是这样:
targets : prerequisites ; command
command
...targets是文件名,以空格分开,可以使用通配符。一般来说,我们的目标基本上是一个文件,但也有可能是多个文件。
command是命令行,如果其不与“target:prerequisites”在一行,那么,必须以[Tab键]开头,如果和prerequisites在一行,那么可以用分号做为分隔。(见上)
prerequisites也就是目标所依赖的文件(或依赖目标)。如果其中的某个文件要比目标文件要新,那么,目标就被认为是“过时的”,被认为是需要重生成的。这个在前面已经讲过了。
如果命令太长,你可以使用反斜框(‘\’)作为换行符。make对一行上有多少个字符没有限制。规则告诉make两件事,文件的依赖关系和如何成成目标文件。
一般来说,make会以UNIX的标准Shell,也就是/bin/sh来执行命令。
一篇文章教你读懂Makefile - 程序员修练之路 - 博客园
gcc -g -o -c
-g 可执行程序包含调试信息:加个-g 是为了gdb 用,不然gdb用不到。
-o 指定输出文件名(o:output)-o output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out。
-c 只编译不链接:产生.o文件,就是obj文件,不产生执行文件(c : compile)。
gcc filename.c -o filename
上面的意思是如果你不打 -o filename(直接gcc filename.c );那么默认就是输出a.out.这个-o就是用来控制输出文件的。用./a.out 执行文件。
gcc -o hello hello.c
gcc 编译器就会为我们生成一个hello的可执行文件。执行./hello就可以看到程序的输出结果了。命令行中 gcc表示我们是用gcc来编译我们的源程序,-o 选项表示我们要求编译器给我们输出的可执行文件名为hello 而hello.c是我们的源程序文件。
gcc编译器有许多选项,一般来说我们只要知道其中的几个就够了。 -o选项我们已经知道了,表示我们要求输出的可执行文件名。 -c选项表示我们只要求编译器输出目标代码,而不必要输出可执行文件。 -g选项表示我们要求编译器在编译的时候提供我们以后对程序进行调试的信息。
Makefile里面的$@,$^,$<
Makefile有三个非常有用的变量。分别是$@,$^,$<代表的意义分别是:
$@--目标文件,$^--所有的依赖文件,$<--第一个依赖文件。
如果我们使用上面三个变量,那么我们可以简化我们的Makefile文件
%.o: solid-phase/%.cpp
$(CC) $(CINC) $(CFLAGS) -o $@ -g -c $^$符号:取路径、文件名、后缀
Linux中的$符号的三种常见用法_统木木的博客-CSDN博客
1. 显示脚本参数($0、$?、$*、$@、$#、$$、$!)(本质上属于变量替换)
$# 是传给脚本的参数个数
$0 是脚本本身的名字
$1是传递给该shell脚本的第一个参数
$2是传递给该shell脚本的第二个参数
$@ 是传给脚本的所有参数的列表
2. 获取变量与环境变量的值
如:path=2,则echo $path 或者echo${path}显示的就是path的值。
3. shell中$(( ))、$( )、``与${ }的区别
$( )与``(反引号):返回括号中命令的结果
${ }变量替换,一般情况下,$var与${var}是没有区别的,但是用${ }会比较精确的界定变量名称的范围
先赋值一个变量为一个路径,如下:
file=/dir1/dir2/dir3/my.file.txt
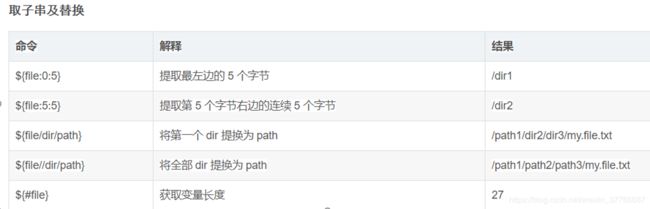
num=${folder:9:3}提取folder第9个字节右边的连续3个字节。
Makefile里面的clean
clean:
rm -v $(EXE) $(OBJECT) MPPICFoam.o20. C++一些句子
struct timespec 定义
typedef long time_t;
#ifndef _TIMESPEC
#define _TIMESPEC
struct timespec {
time_t tv_sec; // seconds
long tv_nsec; // and nanoseconds
};
#endif
struct timespec有两个成员,一个是秒,一个是纳秒, 所以最高精确度是纳秒。
一般由函数int clock_gettime(clockid_t, struct timespec *)获取特定时钟的时间,常用如下4种时钟:
CLOCK_REALTIME 统当前时间,从1970年1.1日算起
CLOCK_MONOTONIC 系统的启动时间,不能被设置
CLOCK_PROCESS_CPUTIME_ID 本进程运行时间
CLOCK_THREAD_CPUTIME_ID 本线程运行时间int main(int argc,char* argv[ ])
argc是命令行总的参数个数
argv[]是argc个参数,其中第0个参数是程序的全名,以后的参数命令行后面跟的用户输入的参数,
————————
char *argv[]是一个字符数组,其大小是int argc,
主要用于命令行参数argv[]参数,数组里每个元素代表一个参数;
————————
例如:
int main(int argc, char* argv[])
{
int i;
for (i=0;i>i; //输出数组argv[i]
return 0;
} 比如你输入:
test a.c b.c t.c输出如下:
test
a.c
b.c
t.c则
argc = 4
argv[0] = “test”
argv[1] = “a.c”
argv[2] = “b.c”
argv[3] = “t.c”*argv[] 与 **argv区别
1.char *argv[]声明的是一个字符型指针数组,数组元素是字符型指针变量,指针变量存储的是字符串的地址,即指针数组存储了字符串的地址,argv[i]即为指针数组中第i个字符串的地址;char **argv声明的是一个指向字符型指针数组的指针(字符型指针数组指针),argv存储的是指针数组的地址,argv[i]也是指针数组中第i个字符串的地址。因此*argv[]与 **argv两者都可以访问字符串。
2.char *argv[]中argv为字符型指针数组的首地址,是个常量,不能argv++(同理char a[]也不能a++),而**argv中argv是个变量,可以argv++,但是实际使用时两者都可以argv++,这是因为*argv[]是main函数的参数,数组作为函数参数时会自动退化为指针,因此main函数参数中的char *argv[]退化为char **argv(当char a[]和char *a[]用作函数参数时也会分别自动退化成char *a和char **a)。
21 OpenFOAM中fvc和fvm的区别

OpenFOAM®的另一个特点是它使用运算符重载,允许以自然的方式表示算法。例如,通用标量的输运方程的离散化为:

用OpenFOAM®编写为:
fvm::ddt(phi)
+ fvm::div(mDot, phi)
- fvm::laplacian(Dphi, phi)
==
fvm::Sp(P, phi)
- fvc::(C)例如,fvm::div运算符将对流通量作为在控制单元面上定义的系数场,将phi作为在单元质心上定义的变量场,并返回表示对流算符离散化的包含左边矩阵和右边源的一个方程组。这些左边矩阵和右边向量是为每个运算符生成的,然后根据需要添加或删掉,以生成最终的方程组,这些方程组表示在计算域的每个元素上定义的离散化的代数方程组。
名称空间fvm::和fvc::分别允许隐式和显式评估各种运算符。
名为“有限体积演算(finite volume calculus)”的显式运算符fvc根据实际场值返回一个等效场。例如,运算符fvc::div(ϕ)返回等效的geometricField,其中每个单元格包含变量(ϕ)的散度值。
相反,fvm隐式运算符根据系数矩阵定义隐式有限体积离散化。例如fvm::laplacian(ϕ)返回一个fvMatrix,其中所有系数都基于拉普拉斯算子的有限体积离散化。
fvm::和fvc::运算符的作用是构造方程组的左边和右边,该方程组表示网格中每个元素上方程(1)的离散形式。离散化过程产生了一个方程组,可以用图1所示的矩阵形式表示。

22 IOobject
OpenFOAM中使用字典和IOobject类实现输入输出操作_xxyhjy的专栏-CSDN博客
OpenFOAM中很多输入输出的操作都是使用IOobject类来实现的,其头文件说明了它的功能:
IOobject定义了对象的一些由objectRegistry隐式管理时所需要的属性,同时还提供了基础性的输入/输出流。一个IOobject
对象在构造的时候需要六个参数:对象名称,类名称,实例路径,一个objectRegistry的引用,以及描述读写方式的参数。
IOobject类有两种构造函数
- 从对象名称,实例路径,objectRegistry引用和读写设置来构造。
- 从对象名称,实例路径,位置,objectRegistry引用和读写设置来构造。
IOobject和字典
IOdictionary transportProperties
(
IOobject
(
"transportProperties",
runTime.constant(),
mesh,
IOobject::MUST_READ,
IOobject::NO_WRITE
)
);本例中使用了第一种构造函数,其中:
- "transportProperties" 是含有字典的文件名称。
- runTime.constant()实例路径,给出字典的位置,在本例中存在于算例的constant路径下。
- objectRegistry为mesh(前面提过polyMesh和fvMesh都是是objectRegistry的派生类)。
IOobject和场
volScalarField T
(
IOobject
(
"T",
runTime.timeName(),
mesh,
IOobject::MUST_READ,
IOobject::AUTO_WRITE
),
mesh
);其中:
- "T" 为文件名。
- runTime.timeName()实例路径,这里是告诉OpenFOAM将每个文件存在以运行时间为名称的路径下面。
- mesh是所需的objectRegistry。
- 读/写设置选项设置为MUST_READ和AUTO_WRITE以便OpenFOAM可以读取场数据并自动保存。如果不需要读场数据,则需要将MUST_READ
- 改为NO_READ。
23 linux里的反引号和单引号的区别
linux 里的`反引号_cll_jj的博客-CSDN博客_linux中的反引号
反引号的作用就是将反引号内的Linux命令先执行,然后将执行结果赋予变量。
需要记住单引号和反引号之间的区别。单引号把Linux命令视为字符集合。反引号会强迫执行Linux命令。对比:
$ lscc='ls *.c'
$ echo $lscc
ls *.c
$ lscc=`ls *.c`
$ echo $lscc
main.c prog.c 如何打出反引号
