ppg_decode_spec_5ms_sch代码和训练
0. 项目描述
ppg_decode_spec_5ms_sch是从ppg到spec的NN版本映射,期望他能修复FindA中找到的中ppgs不连贯问题,产出连贯的specs
主要基于实验室的服务器和开源代码+LJSpeech等
1. 数据和特征情况
1.1 英文数据集:LJSpeech-1.1
1.1.1 提取的代码项目
Git:https://github.com/ruclion/linears_decoder_5ms_sch_mel_linear/tree/master/LJSpeech
1.1.2 服务器
脚本路径:/datapool/home/hujk17/linears_decoder_5ms_sch_mel_linear/LJSpeech
![]()
1.1.3 处理得到的数据
路径:/datapool/home/hujk17/chenxueyuan/LJSpeech-1.1

其中meta_good.txt是提取特征成功的文件名字list,有些ppg的nparray文件,因为服务器变动损坏了,不过问题不大(反正之后要重新做10ms版本)
meta_small.txt是meta_good.txt的一小部分,便于测试;meta.txt是完整的13100句list;注意这两个有文本,meta_good没文本
1.2 中文数据集:DataBaker双语私有语料中文部分(DataBaker_Bilingual_CN)
基本上和LJSpeech差不多,是对称的;大多数区别是读list清单的代码区别
也老老实实列出来吧,以后找路径啥的好找
1.2.1 提取的代码项目
Git:https://github.com/ruclion/linears_decoder_5ms_sch_mel_linear/tree/master/DataBaker_Bilingual_CN
1.1.2 服务器
脚本路径:/datapool/home/hujk17/linears_decoder_5ms_sch_mel_linear/DataBaker_Bilingual_CN
![]()
1.1.3 处理得到的数据
路径:/datapool/home/hujk17/chenxueyuan/DataBaker_Bilingual_CN
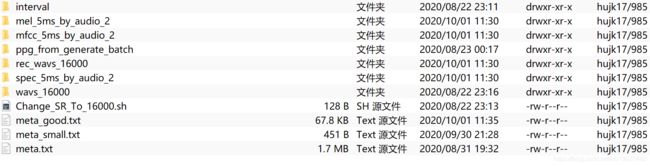
其中meta_good.txt是提取特征成功的文件名字list,有些ppg的nparray文件,因为服务器变动损坏了,不过问题不大(反正之后要重新做10ms版本)
meta_small.txt是meta_good.txt的一小部分,便于测试;meta.txt是完整的10000句list;注意这两个是双行,meta_good只是最简单的一行一个文件名字
interval是类似于开源标贝数据集东西,可能对于衡量PPG有用,先留着吧
2. PPG Decode Spec 模型
2.1. 总的项目架构
使用DCBHG,而不是DLSTM,原因是sch已经跑通了,效果也不错,代码也用的人家的,复现可预期性更高~
Git:https://github.com/ruclion/linears_decoder_5ms_sch_mel_linear
服务器路径:/datapool/home/hujk17/linears_decoder_5ms_sch_mel_linear
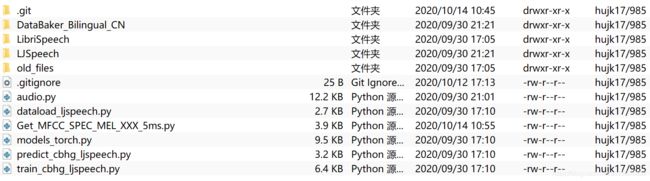
为了方便,单独复制出来三个独立项目,分别是:LJSpeech的,Baker的,Multi-speaker的
2.2. ppg_decode_spec_5ms_sch_LJSpeech项目
Git:https://github.com/ruclion/ppg_decode_spec_5ms_sch_LJSpeech
服务器路径:/datapool/home/hujk17/ppg_decode_spec_5ms_sch_LJSpeech
2.2.1. dataload_ljspeech
- 修改路径,用绝对路径
- 先用meta_small.txt测试
- 设定最长长度,目前先2000,后来再调;以后也不能这么padding,临时先用着吧,padding的代码没细看,总之__getitem__得到了固定的长度,有些奇怪。先用着吧,之后看看lh版本的
- 最长长度的设置反倒方便了调节batch size适应内存
2.2.2. train_cbhg_ljspeech
- 构建batch目前很烂,需要排序+shuffle版本的
- 计算loss目前很烂,for循环,太慢了
- 恢复训练代码没写
- 只有train,没有validation,需要补上
- 超参数是长河的,不过需要详细确认下,比如lr是不是太小了
-
改动了这个,具体弄不太清楚,不过都统一起来吧,'center': True;只要不报错,就没事
-
Variable(ppgs).float()不知道目的是什么。也不会查询pytorch Tensor的变量类型
2.2.3. models_torch
- 修正下超参数的写法,改为字典,和audio中写法统一起来
- 画了一张模型图,其中标红的是不理解的
- 先用着这个版本吗,毕竟和港中文的不同,但是先不变动了,跑出声音再说
2.2.4. 运行环境
应该是用的是标准的pytorch环境,凑活着用fastspeech_p36吧
看tensorboard的时候用tensorflow_p36。。。
2.2.5. 训练过程




不知道为什么GPU占用率是0,先不管了,从1200的序列长度one step只有2s来看,是用了GPU的
2.2.6. 预测过程
- 改动:'center': True
- 构造了一个:inference_ppgs_path_list.txt,包含ppg的路径们
- 每次batch size = 1去合成,并且不padding到1200;先这么处理吧
- 然后去跑,发现可以,效果还挺好


2.3. ppg_decode_spec_5ms_sch_LJSpeech项目添加validation部分
这部分是由于代码太简化了,没有分成train和validation集
需要用validation部分来决定early stop
2.3.1. 增添validation函数完成所有
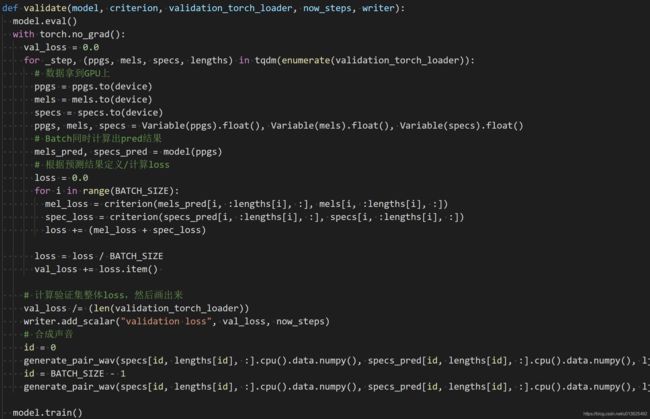
注意每隔600steps才测一次,因为测试一次1000句的就需要3分钟
2.3.2. 切分meta list

2.4. ppg_decode_spec_5ms_sch_LJSpeech项目添加restore部分
见图片

2.5. 中文都被killed
为什么?
2.6. ppg_decode_spec_5ms_sch_DataBakerCN项目
Git网址:
服务器路径:
改改路径就好
2.5.1. dataload_DataBakerCN
替换即可
2.5.2. generate_trian_validation_list
替换即可
2.5.3. train_cbhg_DataBakerCN
替换即可

