solr与.net系列课程(三)solr连接数据库
solr与.net系列课程(三)solr连接数据库
上一章直接讲述的配置文件把大部分人看的很迷惑,大家都想听的是solr到底是怎么用的,好,这一节我们就开始链接数据库,首先讲一下连接之前都要配置哪些文件
1.先下载连接sqlserver的驱动(sqljdbc4.jar)sqljdbc4.jar,),将其复制到C:\Program Files\Apache Software Foundation\Tomcat 7.0\webapps\solr\WEB-INF\lib (C:\Program Files\Apache Software Foundation\Tomcat 7.0为tomcat安装路径)
2.在C:\Program Files\Apache Software Foundation\Tomcat 7.0\solr\collection1\conf下新建data-config.xml文件(名字任意,路径也可以任意)
3.在C:\Program Files\Apache Software Foundation\Tomcat 7.0\solr\collection1\conf \solrconfig.xml,文件里配置data-confing.xml路径
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">C:\Program Files\Apache Software Foundation\Tomcat 7.0\solr\collection1\conf\data-config.xml</str> </lst> </requestHandler>
4.将solr4.72文件夹下的dist, contrib文件夹复制到C:\Program Files\Apache Software Foundation\Tomcat 7.0\
5.在C:\Program Files\Apache Software Foundation\Tomcat 7.0\solr\collection1\conf \solrconfig.xml,文件里配置dist, contrib这两个文件夹的路径(solrconfig.xml已存在这些路径,如果以你放置的路径不一样,修改一下就可以了)
<lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/contrib/extraction/lib" regex=".*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/dist/" regex="solr-cell-\d.*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/contrib/clustering/lib/" regex=".*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/dist/" regex="solr-clustering-\d.*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/contrib/langid/lib/" regex=".*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/dist/" regex="solr-langid-\d.*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/contrib/velocity/lib" regex=".*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/dist/" regex="solr-velocity-\d.*\.jar" /> <lib dir="C:/Program Files/Apache Software Foundation/Tomcat 7.0/dist/" regex="solr-dataimporthandler-\d.*\.jar" />
6.将dist文件夹下的![]() 这两个文件复制到与数据库驱动同一个文件夹下
这两个文件复制到与数据库驱动同一个文件夹下
以上配置的路径我是用绝对路径配置的,也可以用相对路径,
以上就是需要配置的内容了,下面我将结合前一节的内容,讲解如何配置连接数据库
首先是配置data-confing.xml文件,data-confing.xml文件就是连接数据库的配置文件(刚才新建的),将如下代码粘贴到该文件中
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://192.168.0.8;DatabaseName=test" user="sa" password="123"/> <document name="Info"> <entity name="zpxx" transformer="ClobTransformer" pk="id" query="select id, name from table" deltaImportQuery="select id, name from table" deltaQuery="SELECT id FROM table where adddate > '${dataimporter.last_index_time}'"> <field column=“id" name=“id" /> <field column=“name" name=“name" /> </entity> </document> </dataConfig>
我们来分析一下上面的代码
<dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://192.168.0.8;DatabaseName=test" user="sa" password="123"/>
这个显而易见,就是连接数据库的字符串了
<document name="Info"> <entity name="zpxx" transformer="ClobTransformer" pk="id" query="select id, name from table" deltaImportQuery="select id, name from table" deltaQuery="SELECT id FROM table where adddate > '${dataimporter.last_index_time}'"> <field column=“id" name=“solrid" /> <field column=“name" name=“name" /> </entity> </document>
这个就是从哪张表里取数据了的sql语句了
query是获取全部数据的SQL(solr从sql中获取那些数据)
deltaImportQuery是获取增量数据时使用的SQL(数据库新增数据是,追加到solr的数据)
deltaQuery是获取pk的SQL(数据库新增数据是,追加到solr的数据时的条件,根据id ,条件是最后一次获取的时间,${dataimporter.last_index_time,最后获取的时间})
<field column=“id" name=“id" /> <field column=“name" name=“solrname" />
这个就是数据库与solr的映射关系了,在上一节schema.xml中定义的field子节点对应,那么根据本届内容field就要这么定义
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="solrname" type=" string " indexed="true" stored="true" omitNorms="true"/>
其他的field就可以删掉了(初学者不要删,容易出问题),也可以多定义一些备用,这样table表中id下的数据就存储在了solr中id的位置,name就存储在solrname下了
<field name="_version_" type="long" indexed="true" stored="true"/> <!-- points to the root document of a block of nested documents. Required for nested document support, may be removed otherwise --> <field name="_root_" type="string" indexed="true" stored="false"/>
这个不要删,这是solr自已自己内部的字段,删掉会报错,这样solr就配置完成.
之前有朋友问到过多数据库多表的问题,很简单,先说多表的问题:
<entity> ….. </entity> 每一个 entiy就是一张表,有几张表就写几个,这里就要注意一个问题了,单核的solr是把所有的数据存储在在一个文件中,上文中结束的时候说道, schema.xml这个文件可以设置主键(一定要有主键),默认是id, data-confing.xml,文件定义每张表时也指定了主键,没写默认id,多张表示就要注意id的唯一行了,平时我们总是喜欢使用自增id,所以多张表的id肯定会重复,主键的重复solr是不会报错了,但是遵循相同主键后一条覆盖前一条,所以多张表时,就要考虑主键唯一的问题了,如果使用guid的形式那就没问题了,(solr从数据库获取数据是按<entity> ….. </entity>的顺序逐个表去取数据了),那如果非要主键重复存储怎么办,也可以,使用多核模式
多表实例:
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://192.168.0.8;DatabaseName="test" user="sa" password="123"/> <document name="Info"> <entity name="zpxx" transformer="ClobTransformer" query="select id, name from table" deltaImportQuery="select id, name from table" deltaQuery="SELECT id FROM table where adddate > '${dataimporter.last_index_time}'"> <field column=“id" name=“id" /> <field column=“name" name=“name" /> </entity> <entity name="zpxx2" transformer="ClobTransformer" query="select id, name from table2" deltaImportQuery="select id, name from table2" deltaQuery="SELECT id FROM table2 where adddate > '${dataimporter.last_index_time}'"> <field column=“id" name=“id" /> <field column=“name" name=“name" /> </entity> </document> </dataConfig>
现在再说一说多数据库的问题了,一个配置文件可以配置多个数据源。增加一个dataSource元素就可以增加一个数据源了。name属性可以区分不同的数据源。如果配置了多于一个的数据源,那么要注意将name配置成唯一的。
多数据库实例:
<dataSource type="JdbcDataSource" name="ds-1" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db1-host/dbname" user="db_username" password="db_password"/> <dataSource type="JdbcDataSource" name="ds-2" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db2-host/dbname" user="db_username" password="db_password"/> 然后这样使用 .. <entity name="one" dataSource="ds-1" ...> .. </entity> <entity name="two" dataSource="ds-2" ...> .. </entity> ..
如果存在多表链接怎么办,这个也可以解决, <entity> 中可以嵌套<entity>达到链接效果
例:
<entity name="item" query="select id name from item"> <entity name="feature" query="select description from feature where item_id='${item.ID}'"/> <entity name="item_category" query="select phone from item_category where category _id='${item.ID}'"> </entity> </entity>
这个相当于 select a.id ,a.name ,b. description ,c. phone from item as a left join feature as b on a.id=b. item_id left join item_category as c on a.id=c. category _id
这个链接也是有限制的:
子Entity的query必须引用父Entity的pk
子Entity的parentDeltaQuery必须引用自己的pk
子Entity的parentDeltaQuery必须返回父Entity的pk
deltaImportQuery引用的必须是自己的pk
那说了这么多 我们来简单的配置一个吧,现在有一张表tableA,有如下字段id ,name,address,phone,class,addtime 我想把这张表的数据存储到solr中, 怎配置,首先在schema.xml 的 fields 节点配置索引字段,(name可以随便起,type是类型,上文字提到过solr的类型,这里为了省事就都用string了)
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="solrname" type=" string " indexed="true" stored="true" omitNorms="true"/> <field name=" address " type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="phone" type=" string " indexed="true" stored="true" omitNorms="true"/> <field name="class" type=" string " indexed="true" stored="true" omitNorms="true"/> <field name="addtime" type=" date" indexed="true" stored="true" omitNorms="true"/>
上文中还提到过 copyfeild与DynamicField,这个可用可不用,怎样用上文已经解释了,solr中会自带一些定义,想删就删,不删也没事,然后我们配置data-confing.xml,如下,
<dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://192.168.0.8;DatabaseName=test" user="sa" password="123"/> <document name="Info"> <entity name=" test " transformer="ClobTransformer" pk="id" query="select id, name ,address,phone,class,addtime from tableA" deltaImportQuery=" select id, name ,address,phone,class,addtime from tableA" deltaQuery="SELECT id FROM tableA where addtime > '${dataimporter.last_index_time}'"> <field column="id" name="id" /> <field column="name" name="solrname" /> <field column="address " name=“address " /> <field column="phone " name="phone " /> <field column="class " name="class " /> <field column="addtime " name="addtime " /> </entity> </document> </dataConfig>
好了,这样就配置完成了,下面该开始执行了,执行有两种方式
先说第一种,浏览器执行方式:
终止跑索引 http://192.168.0.9:8080/solr/collection1/dataimport?command=abort
开始索引 http://192.168.0.9:8080/solr/collection1/dataimport?command=full-import
增量索引 http://192.168.0.9:8080/solr/collection1/dataimport?command=delta-import
直接在浏览器中输入 http://192.168.0.9:8080/solr/collection1/dataimport?command=full-import就可以了
我们看看效果
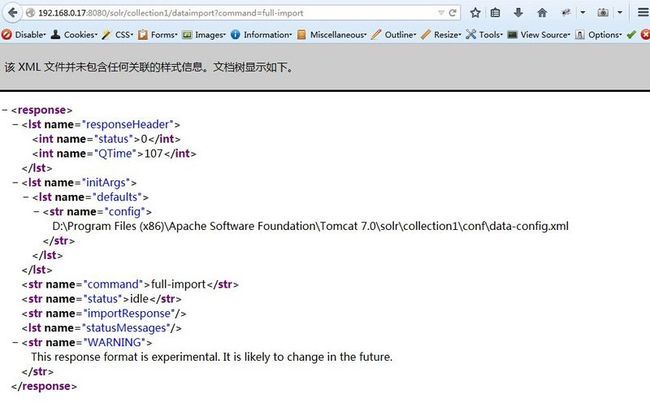
路径是D盘是因为我只在另一台电脑上执行的,那个配置在D盘了
这种方式我们看不到执行过程,执行时间
Solr还提供了图形化的执行方式,如下:
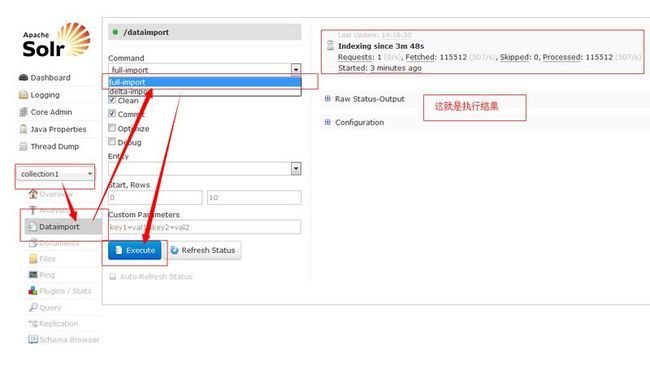
Full Import工作原理:
执行本Entity的Query,获取所有数据;
针对每个行数据Row,获取pk,组装子Entity的Query;
执行子Entity的Query,获取子Entity的数据。
Delta Import工作原理:
查找子Entity,直到没有为止;
执行Entity的deltaQuery,获取变化数据的pk;
合并子Entity parentDeltaQuery得到的pk;
针对每一个pk Row,组装父Entity的parentDeltaQuery;
执行parentDeltaQuery,获取父Entity的pk;
执行deltaImportQuery,获取自身的数据;
如果没有deltaImportQuery,就组装Query
小结,今天就讲这么多吧,本来还想给大家展示个实例的,但是发现今天写的有点多,大家应该先理解理解,那真实的案例就在下一节讲述吧,我将为大家装备一个300万数据左右的表,让大家看看实际效果,并为大家讲述如何查询,查询参数等等.
今天感觉写的有点乱,写完后面就忘了前面写的什么了,其实这里面还有好多细节没有讲述,如果大家在使用过程中有什么问题,可以直接给我留言,我会及时为大家解答的.
这里先给大家展示一下300万数据查询的效果:
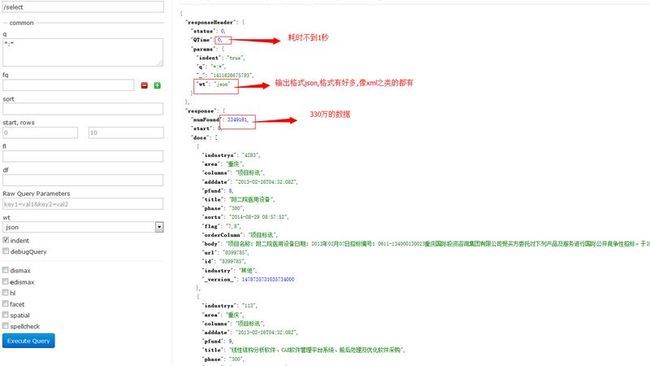
我们模糊查询一下看看 ,body字段里面存储的是文章,都是几千字以的,现在查询body中带有"信号灯"的数据
看效果
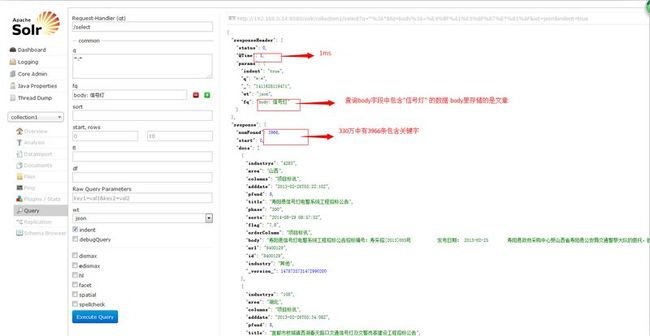
这里补充一点,执行索引后在更改xml配置,下次重新执行索引是需重启tomcat
qq群: 424259523
[B~1W])F0R8E]`[{N3K.jpg)